



📢 转载信息
原文作者:Amazon Web Services
当您分析长达数百万字的内容时,往往会触及模型的上下文窗口上限,甚至最强大的模型也会因信息丢失或超长输入而表现欠佳。面对那些无法一次性放入窗口的文档,我们该如何进行推理?
在本文中,您将学习如何利用 Amazon Bedrock AgentCore 代码解释器和 Strands Agents SDK 来实现递归语言模型 (RLM)。读完本文,您将掌握:
- 处理任意长度文档,不再受限于上下文大小。
- 将 Bedrock AgentCore 代码解释器作为持久化工作内存,用于迭代分析。
- 在沙箱 Python 环境中编排子模型(sub-LLM)调用,以分析特定文档片段。
为什么上下文窗口是不够的?
想象一个典型的财务分析任务:比较某公司两年的年度报告,每份报告都有 300–500 页。如果再加上分析师报告、SEC 文件和补充材料,总量将达到数百万字符。
直接将这些文档发给模型,要么因超出限制导致请求失败,要么模型因“中间丢失”(lost in the middle)问题无法有效聚焦关键信息。上下文窗口的硬限制无法单纯通过提示词工程解决,我们需要一种将文档大小与模型窗口脱钩的方法。
RLM:将上下文视为环境
由 Zhang 等人提出的 RLM 重新定义了这个问题:不再将整个文档塞入模型,而是将输入视为一个模型可以进行程序化交互的外部环境。
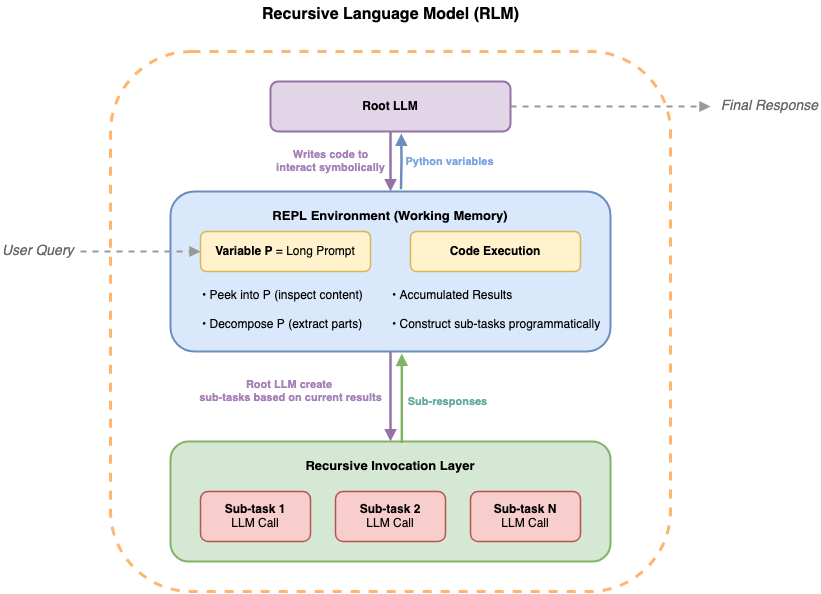
图 1. 递归语言模型像一个迭代循环:根 LLM 生成代码来探索文档环境,将语义分析委托给子 LLM,并在工作内存中积累结果。
实现架构
我们使用 Amazon Bedrock AgentCore 代码解释器提供沙箱化 Python 运行环境。架构包含三个核心组件:根 LLM 负责逻辑编排,代码解释器存储完整文档作为 Python 变量,并通过 llm_query() 函数调用子模型,确保详细结果保持在沙箱内存中。

核心价值
RLM 的优势显而易见:
- 彻底解决超长文本失效: 测试显示,RLM 在长文本推理任务中可实现 100% 的成功率,而传统方法常因内存超限而崩溃。
- 提升推理准确度: 相比单一长上下文调用,RLM 将复杂任务拆解,使模型能更专注于特定片段的语义理解。
- 灵活性与成本控制: 通过将根模型设为高性能模型(如 Sonnet),子模型设为高性价比模型(如 Haiku),可在保证准确度的前提下显著降低延迟和费用。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区