



📢 转载信息
原文作者:Sangmin Woo, Haibo Ding, Sungyeon Kim, and Vinayak Arannil
如果您正在开发视觉购物、图像或文档理解、甚至是图表分析应用,您一定需要一种方法来验证模型响应是否真正基于原始图像。仅凭文本的评估器无法判断标题是否忠实地描述了图像、提取的发票总额是否与文档匹配,或者屏幕摘要是否产生了页面上从未存在的按钮的“幻觉”。Gartner 预测,到 2030 年,80% 的企业软件将具备多模态能力。在缺乏自动化多模态评估的情况下,开发者往往只能在昂贵的人工审核和不可靠的文本评估代理之间做出妥协。
今天,我们宣布在 Strands Evals 软件开发工具包 (SDK) 中推出四种全新的多模态大语言模型(MLLM)评估器,专用于图像到文本任务:总体质量(Overall Quality)、正确性(Correctness)、忠实度(Faithfulness) 和 指令遵循(Instruction Following)。
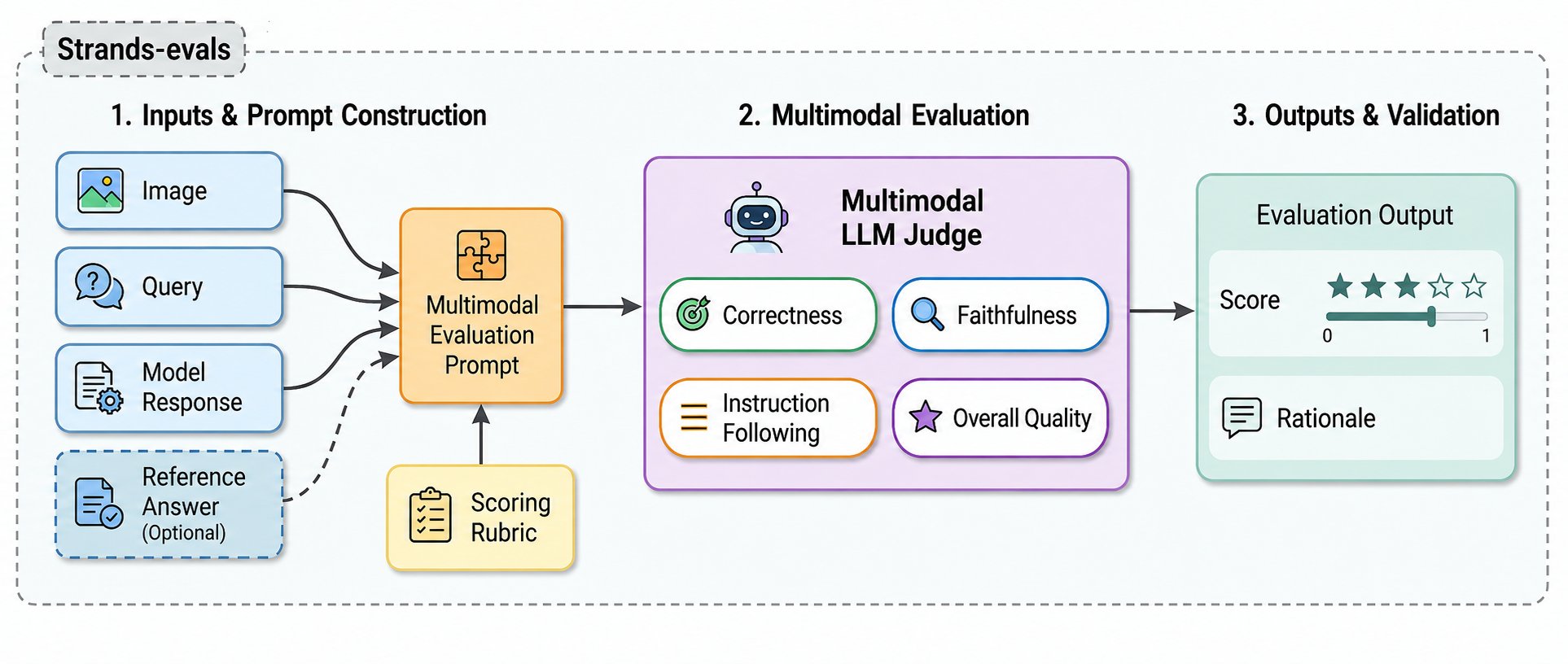
这些评估器将图像直接发送给多模态裁判模型,结合查询内容、模型响应以及可选的参考答案进行打分。裁判模型会给出基于图像的评分,并提供用于调试的推理字符串。
为什么文本评估器无法捕获图像关联的错误?
假设您发布了一个用于阅读发票、总结仪表板或叙述截图的模型。运行仅限文本的“LLM 即裁判(LLM-as-a-Judge)”虽然能提供一定的信号(如文笔流畅度、结构清晰度),但它无法察觉真正关键的问题:
- 模型自信地指出图表中并不存在的趋势。
- 模型“幻觉”出了图片中不存在的产品、标签或人物。
- 模型回答了错误的问题,或者以错误的格式回答了正确的问题。
文本评估器在不检查图像的情况下审批输出,而“真理”本身存在于图像中。
四种图像到文本评估器
我们推出的四个评估器针对最广泛的多模态类别,涵盖图像描述、视觉问答、图表与信息图表解释、文档字段提取等任务。
- 总体质量:评估响应的综合表现(Likert 1-5分)。
- 正确性:判断响应的事实准确性和完整性(二分类)。
- 忠实度:评估响应是否完全基于图像,是否有幻觉(二分类)。
- 指令遵循:验证响应是否遵守了查询中的约束(二分类)。
每个评估器都支持基于参考(Reference-based)模式(与标准答案对比)和无参考(Reference-free)模式(仅从图像判断),满足不同的应用场景。
最佳实践与总结
基于我们的实验,我们建议:
- 从总体质量评估器开始进行快速验证,随后添加针对性的二进制评估器以定位特定失败模式。
- 推荐默认使用 Amazon Bedrock 上的 Claude Sonnet 4.6,它在准确性与成本之间取得了最佳平衡。
- 保留“推理 + 评分”的输出格式,虽然仅输出评分成本更低,但其与人类判断的一致性明显下降。
通过这些工具,开发者可以将繁琐的人工审核转化为自动化的、以图像为基础的精准评分,从而推动多模态智能体在生产环境中的可靠落地。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区