



📢 转载信息
原文作者:Ishan Singh, Akarsha Sehwag, Jonathan Buck, Po-Shin Chen, and Smeet Dhakecha
将AI代理从原型推向生产环境,面临着传统测试方法难以解决的挑战。AI代理的设计本身就具有灵活性、适应性和情境感知能力,但正是这些使其强大的特质,也给系统化评估带来了困难。
传统的软件测试依赖于确定性输出:相同的输入,每次都产生相同的预期输出。AI代理打破了这一假设。它们生成自然语言,做出依赖于情境的决策,即使输入相同,也会产生多种多样的输出。如何系统地评估一个非确定性的事物呢?
在本篇文章中,我们将展示如何使用 Strands Evals 来系统地评估AI代理。我们将深入探讨其核心概念、内置评估器、多轮模拟能力以及实际的应用方法和集成模式。Strands Evals 为使用 Strands Agents SDK 构建的AI代理提供了一个结构化的评估框架,包括评估器、模拟工具和报告功能。无论您是需要验证代理是否使用了正确的工具、是否产生了有用的响应,还是是否将用户引导至其目标,该框架都提供了基础设施来系统地衡量和跟踪这些质量。
为什么评估AI代理如此不同
当您向代理提问“东京的天气怎么样?”时,可能存在许多有效的回答,没有一个答案是绝对正确的。代理可能以摄氏度或华氏度报告温度,包含湿度和风力信息,或者只关注温度。这些变化都可能是正确且有用的,这正是传统断言式测试失效的原因。除了文本生成,代理还会采取行动。一个设计良好的代理会在对话中调用工具、检索信息和做出决策。仅仅评估最终的响应,会忽略代理为达成该响应所采取的适当步骤。
即使是正确的响应也可能不够好。一个响应可能在事实上准确,但无益;或者有用,但与源材料不符。没有单一的指标能够捕捉到这些不同的质量维度。对话增加了另一层复杂性,因为它们是随时间展开的。在多轮交互中,早期的响应会影响后期的响应。代理可能单独处理每个查询都很好,但在整个对话中无法保持连贯的上下文。孤立地测试单轮交互会忽略这些交互模式。
这些特性要求评估需要判断力,而非简单的关键词比较。大型语言模型 (LLM) 驱动的评估满足了这一需求。通过使用语言模型作为评估器,我们可以评估诸如有用性、连贯性和忠实性等难以机械检查的质量。Strands Evals 拥抱这种灵活性,同时仍提供严谨、可重复的质量评估。
Strands Evals 的核心概念
Strands Evals 遵循一种模式,对于编写过单元测试的人来说应该很熟悉,但它适用于AI代理所需的基于判断的评估。该框架引入了三个协同工作的基本概念:案例 (Cases)、实验 (Experiments) 和评估器 (Evaluators)。
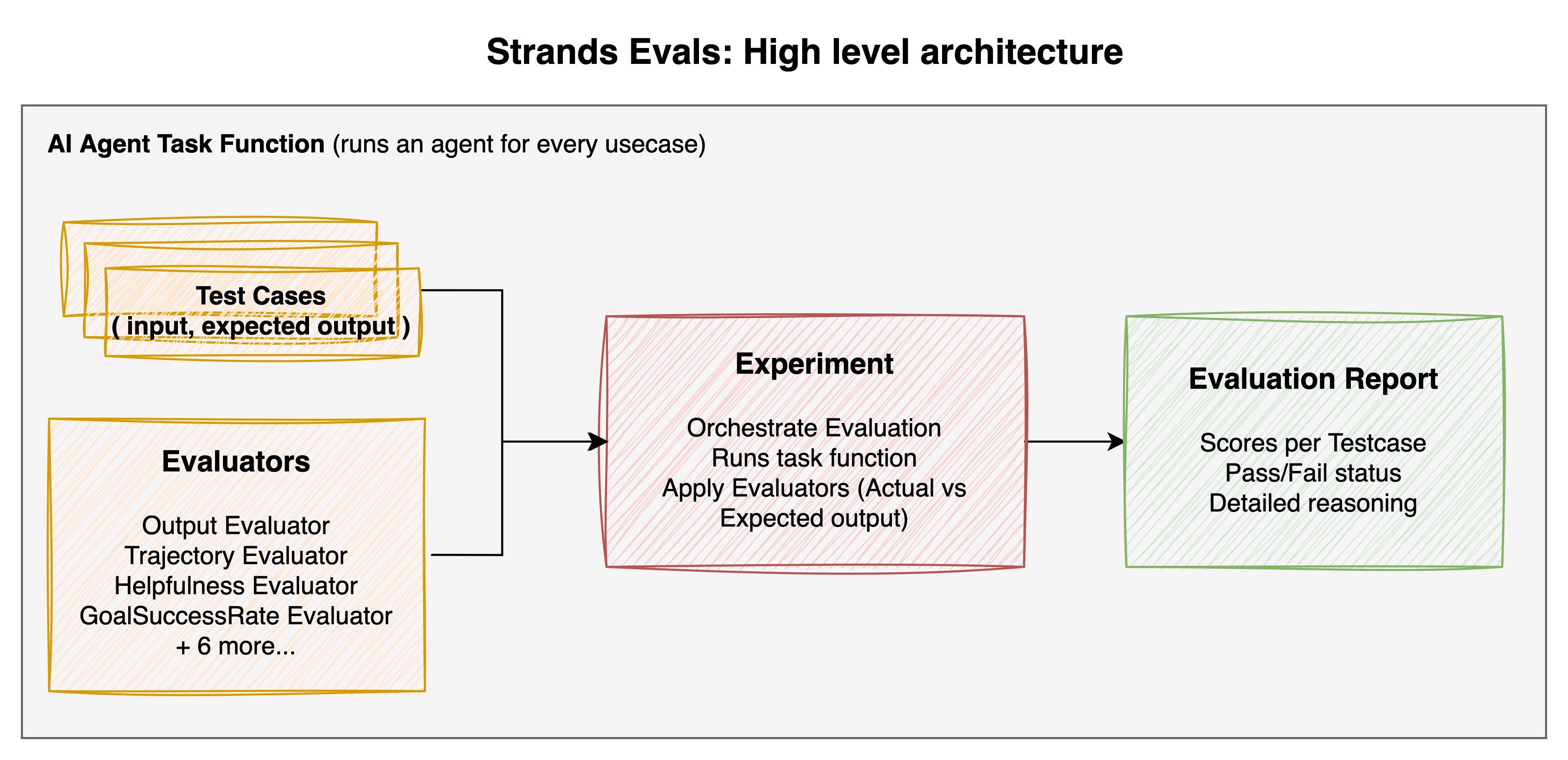
图:高层架构
一个案例 (Case) 代表一个单一的测试场景。它包含您想要测试的输入,可能是一个用户查询,如“巴黎的天气怎么样?”,以及可选的预期输出、称为轨迹 (trajectories) 的预期工具序列和元数据。案例是评估的基本单元。每个案例定义了一个您希望代理能够正确处理的场景。
from strands_evals import Case
case = Case(
name="Weather Query",
input="What is the weather like in Tokyo?",
expected_output="Should include temperature and conditions",
expected_trajectory=["weather_api"]
)
一个实验 (Experiment) 将多个案例与一个或多个评估器捆绑在一起。可以将其视为传统测试中的测试套件。实验协调评估过程。它处理每个案例,用它来运行您的代理,并应用配置好的评估器来评分结果。
评估器 (Evaluators) 是裁判。它们检查代理产生的输出(实际输出和轨迹)并与预期进行比较。与简单的断言检查不同,Strands Evals 中的评估器主要是基于 LLM 的。它们使用语言模型对质量、相关性、有用性以及其他无法简化为字符串比较的质量进行细致的判断。
将这些关注点分开有助于保持框架的灵活性。您可以使用案例来定义要测试的内容,使用评估器来定义如何测试,而框架则通过实验来处理协调和报告。每个部分都可以独立配置,以便您可以构建定制化的评估套件以满足您的特定需求。
任务函数:连接代理到评估系统
案例定义了您的场景,评估器提供了判断。但您的代理如何实际连接到这个评估系统呢?这就是任务函数 (Task Function) 的作用。
任务函数是一个您提供给实验的可调用对象。它接收一个案例,并返回通过该案例运行您的系统所得到的结果。这个接口支持两种根本不同的评估模式。
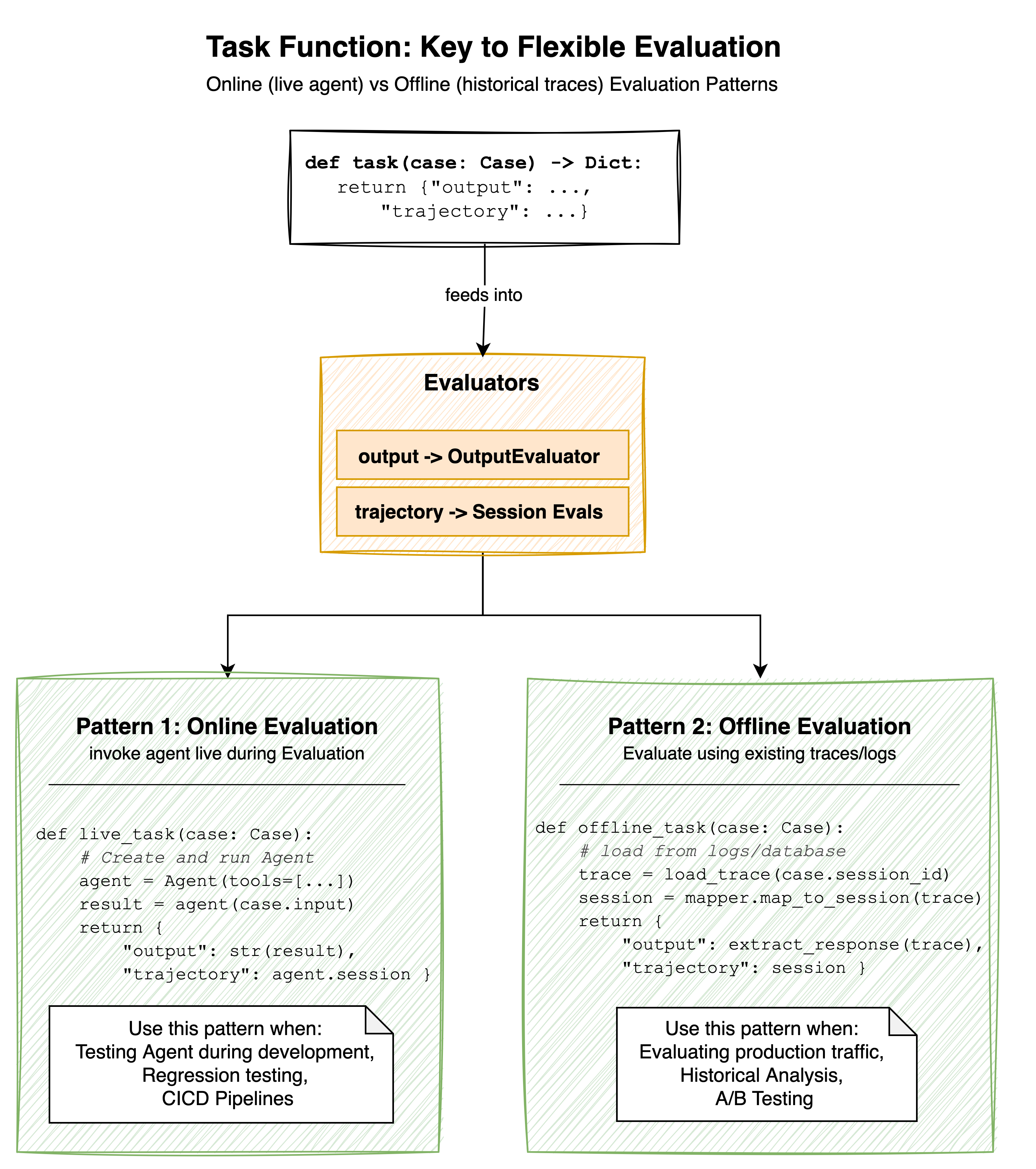
图:任务函数模式
在线评估 (Online evaluation) 涉及在评估运行期间调用您的代理。您的任务函数创建一个代理,将其输入发送给代理,捕获响应和执行跟踪,然后将其返回以供评估。在开发过程中,当您想立即测试更改时,或者在持续集成和交付 (CI/CD) 管道中,在部署前需要验证代理行为时,建议使用此模式。
from strands import Agent
def online_task(case):
agent = Agent(tools=[search_tool, calculator_tool])
result = agent(case.input)
return {
"output": str(result),
"trajectory": agent.session
}
离线评估 (Offline evaluation) 使用历史数据进行工作。您的任务函数不是调用代理,而是从日志、数据库或可观测性系统中检索先前记录的跟踪。它将这些跟踪解析为评估器所需的格式,并返回以供判断。当您需要评估生产流量、执行历史分析或将代理版本与同一组真实用户交互进行比较时,此模式非常有效。
def offline_task(case):
trace = load_trace_from_database(case.session_id)
session = session_mapper.map_to_session(trace)
return {
"output": extract_final_response(trace),
"trajectory": session
}
无论您是测试新的代理实现还是分析数月的生产数据,都可以使用相同的评估器和报告基础设施。任务函数将您的数据源适配到评估系统。
内置评估器,实现全面评估
通过您的任务函数将代理输出连接到评估系统,现在您可以决定要衡量哪些质量方面。Strands Evals 提供了十个内置评估器,每个评估器都旨在评估代理质量的不同维度。
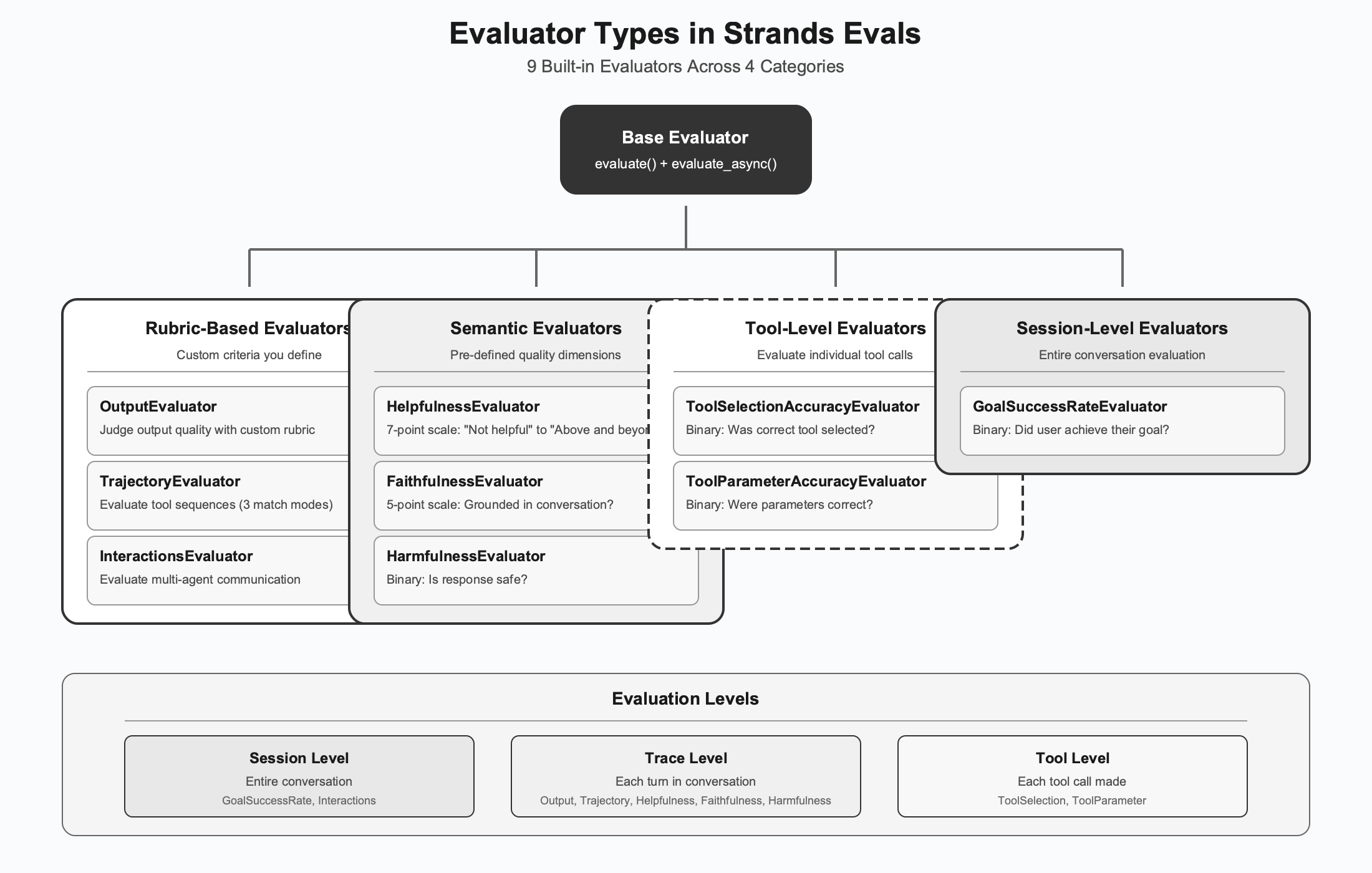
图:评估器类型
基于评分标准 (Rubric-based) 的评估器
最灵活的评估器允许您通过自然语言评分标准来定义自定义标准。
- OutputEvaluator 评估您的代理生成的最终响应。您提供一个评分标准,描述什么是好的,评估器使用 LLM 根据该标准对输出进行评分。这对于您想要为用例定义特定标准的通用质量检查非常有效。
from strands_evals.evaluators import OutputEvaluator
output_evaluator =
OutputEvaluator(
rubric="Score 1.0 if the response correctly answers the question and is well-structured. "
"Score 0.5 if partially correct. Score 0.0 if incorrect or irrelevant."
)
- TrajectoryEvaluator 将此扩展到检查代理采取的行动序列(通常是工具调用)。除了查看最终答案,您还可以验证代理是否以合乎逻辑的顺序使用了适当的工具。评估器包含三个内置的评分函数,用于比较实际轨迹与预期轨迹:精确匹配、顺序匹配和任意顺序匹配。这些评分器作为工具提供给评估 LLM,LLM 根据您的评分标准选择最合适的。
- InteractionsEvaluator 处理涉及多个组件通信的多代理系统。它评估代理或系统组件之间交互的序列。当您的架构涉及编排器、子代理或复杂的工具链时,这非常有用。
语义 (Semantic) 评估器
一些质量维度非常常见,以至于 Strands Evals 提供了预先构建的评估器,具有精心设计的提示和评分量表。
- HelpfulnessEvaluator 从用户的角度评估响应,使用七点量表,从“一点也不有用”到“超出预期”。它评估响应是否真正满足用户的需求,而不仅仅是技术上是否正确。
- FaithfulnessEvaluator 检查响应是否基于对话历史。这对于检索增强生成 (RAG) 系统尤其重要,您需要确保代理不会产生幻觉。五点量表范围从“完全不”忠实到“完全是”。
- HarmfulnessEvaluator 执行安全检查,帮助确定响应是否包含有害、不当或危险内容。它提供二元的是/否判断,以便清晰决策。
工具级 (Tool-level) 评估器
当您的代理使用工具时,您通常需要评估的不仅是最终结果,还有单个工具调用的质量。
- ToolSelectionAccuracyEvaluator 在上下文中检查每个工具调用,并判断给定对话状态,选择该特定工具是否合理。它回答:“在对话的这个阶段,调用此工具是否合理?”
- ToolParameterAccuracyEvaluator 更深入地检查传递给每个工具的参数是否正确和适当。这有助于捕获细微的错误,即选择了正确的工具但参数不正确或不完整。
会话级 (Session-level) 评估器
- GoalSuccessRateEvaluator 采取最广泛的视角,评估整个对话会话,以确定用户是否最终实现了其目标。对于面向任务的代理,成功由结果定义,而不是单个响应。
选择正确的评估器
选择取决于对您的应用程序而言最重要的是什么。客户服务代理可能优先考虑有用性和目标成功率。研究助理可能强调忠实度。从一小组评估器开始,涵盖您核心的质量维度,然后随着您了解代理如何失败而添加更多评估器。
模拟用户以进行多轮测试
前面提到的评估器对于单轮交互效果很好,您提供输入、获得输出并进行评估。多轮对话提出了更严峻的挑战。真实用户不会遵循脚本。他们会提出后续问题,改变方向,并表达困惑。您如何测试这一点?Strands Evals 包含一个 ActorSimulator,它可以创建由 AI 驱动的模拟用户来驱动与您的代理进行多轮对话。
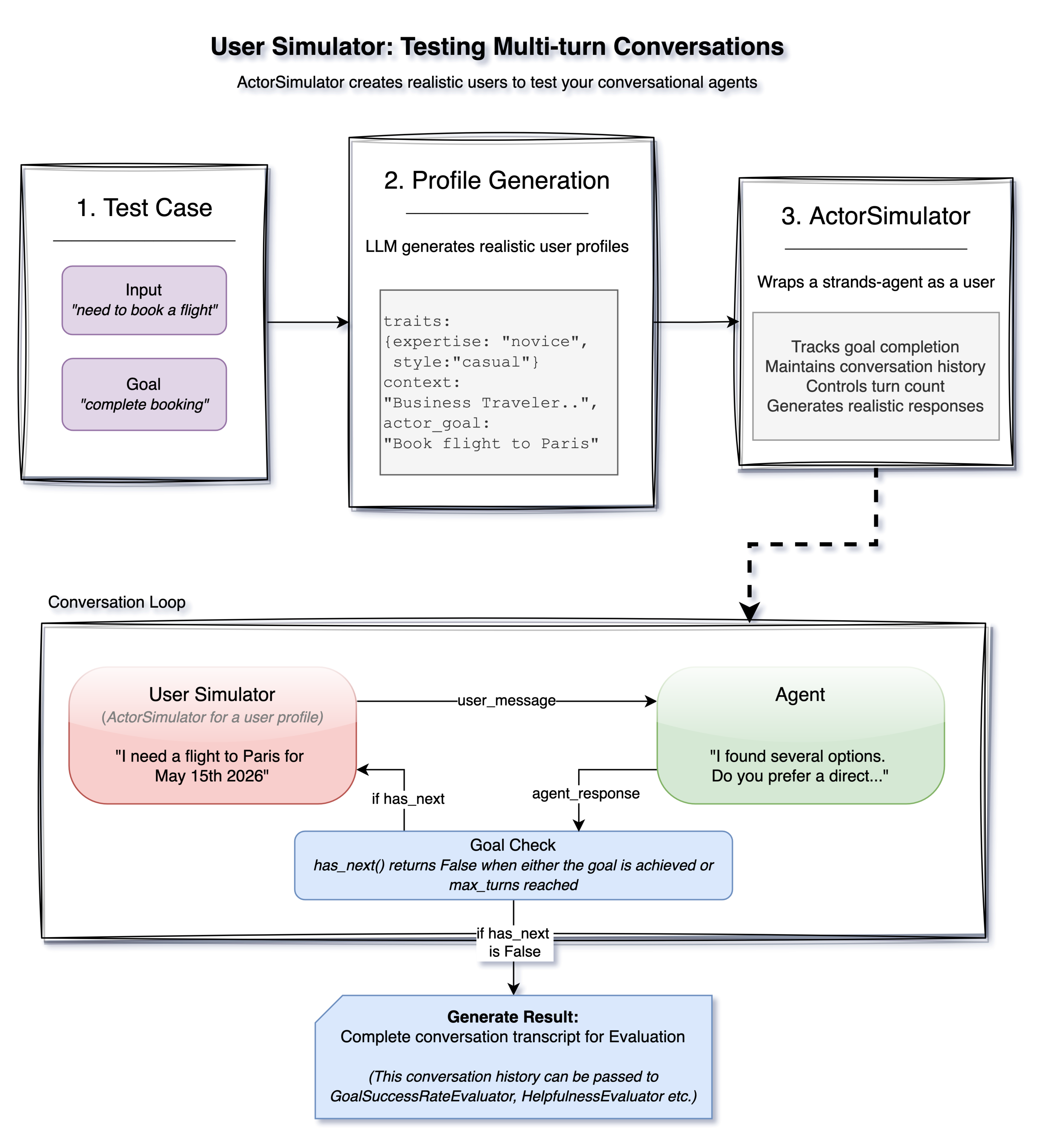
图:用户模拟器流程
ActorSimulator 从一个定义用户想要实现的目标的测试案例开始。基于此,它会使用 LLM 生成一个真实的模拟用户画像,包括个性特征、专业水平、沟通风格和特定目标。此画像会影响模拟用户在整个对话中的行为。
from strands_evals import Case, ActorSimulator
from strands import Agent
case = Case(
input="I need help setting up a new bank account",
metadata={"task_description": "Successfully open a checking account"}
)
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=10
)
在交互过程中,模拟用户向您的代理发送消息,接收响应,并决定下一步说什么。此循环将持续进行,直到目标实现(通过发出特殊停止标记表示),或者达到最大轮次计数。
agent = Agent(system_prompt="You are a helpful banking assistant.")
user_message = case.input
while user_sim.has_next():
agent_response = agent(user_message)
user_result = user_sim.act(str(agent_response))
user_message = str(user_result.structured_output.message)
然后,您可以将生成的对话记录传递给会话级评估器,如 GoalSuccessRateEvaluator,以评估您的代理是否成功帮助模拟用户实现了目标。您无需手动编写多轮脚本,只需定义目标,然后让模拟器创建真实的交互模式。它可能会提出意想不到的后续问题,表达困惑,或者将对话引向您未预料到的方向,从而捕获脚本化测试可能遗漏的边缘情况。
评估级别:理解层次结构
无论使用模拟对话还是真实对话,不同的评估器都在不同的粒度上运行。Strands Evals 使用 TraceExtractor 将会话数据解析为每个评估器所需的格式。
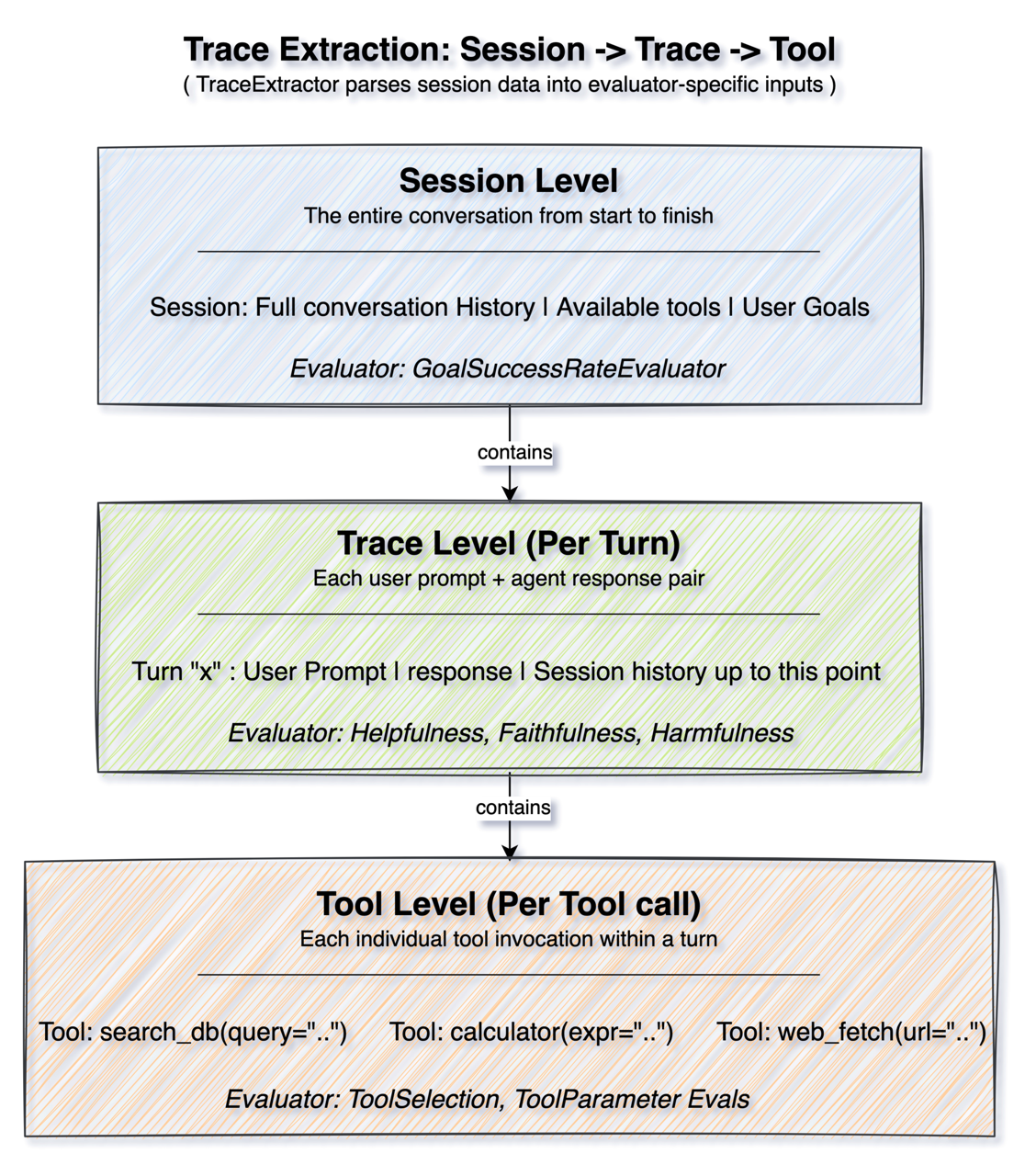
会话级 (Session level) 评估关注从开始到结束的完整对话。评估器接收完整的历史记录、工具执行情况,并理解整个上下文。GoalSuccessRateEvaluator 在此级别上工作,因为确定目标实现需要理解整个交互。
跟踪级 (Trace level) 评估侧重于单个回合,每次用户提示和代理响应对。此级别的评估器接收到该点为止的对话历史,并评估特定响应。有用性、忠实性和有害性评估器在此级别工作,因为这些质量可以逐回合进行评估。
工具级 (Tool level) 评估深入到单个工具调用。在上下文中评估每个工具调用,可以访问可用工具、到目前为止的对话以及传递的特定参数。工具选择和工具参数评估器在此粒度上运行。
您可以使用这种分层设计来组合评估套件,同时在多个级别上检查质量。在单次评估运行中,您可以验证单个工具调用是否合理,响应是否有用,以及总体目标是否实现。
地面真实 (Ground truth) 和预期行为
在许多不同的评估级别上,评估器都可以从参考点进行比较中受益。Strands Evals 通过案例上的三个预期字段为地面真实提供了头等支持。
expected_output 字段指定了代理应该说什么。当存在正确答案或标准响应格式时,这很有用。expected_trajectory 字段定义了代理应该采取的工具或行动序列。您可能要求客户服务代理在进行更改之前检查账户状态,或者研究助理在综合信息之前查询多个来源。并非每个案例都需要所有字段。您可以根据对评估目标的重要性来定义期望。当提供预期值时,评估器将同时接收预期和实际结果,从而能够进行基于比较的评分以及独立的质量评估。
整合一切
让我们通过一个典型的评估工作流程来了解这些概念是如何结合在一起的。
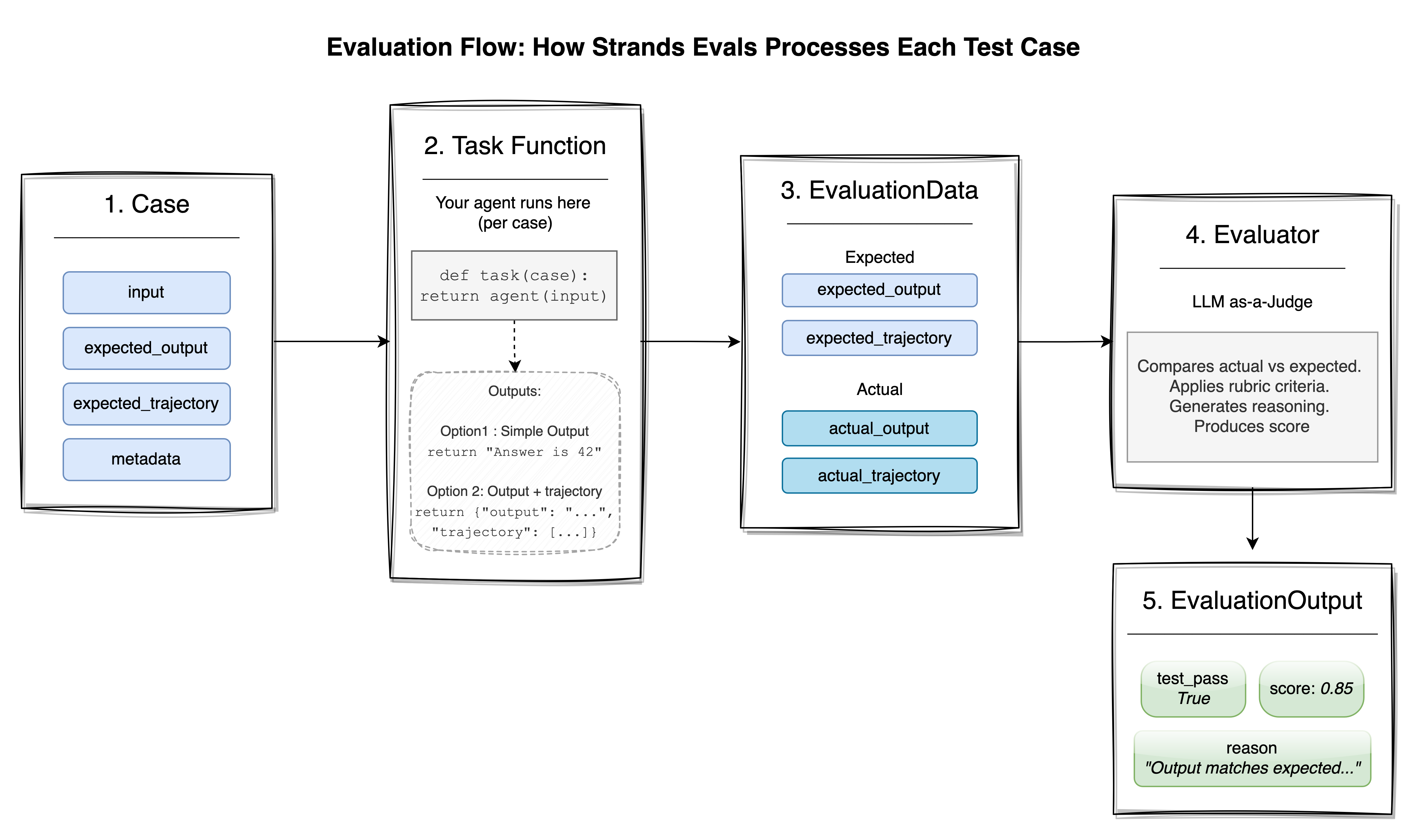
图:评估流程
首先,您定义测试案例,即您希望代理能够很好处理的场景。它们可能来自真实用户查询、合成生成或您已识别出的边缘情况。
from strands_evals import Experiment, Case
from strands_evals.evaluators import OutputEvaluator, TrajectoryEvaluator
from strands_evals.extractors import tools_use_extractor
cases = [
Case(
name="Weather Query",
input="What is the weather like in Tokyo?",
expected_output="Should include temperature and conditions",
expected_trajectory=["weather_api"]
),
Case(
name="Calculator Usage",
input="What is 15% of 847?",
expected_output="127.05",
expected_trajectory=["calculator"]
)
]
接下来,您配置具有适当评分标准或设置的评估器。
output_evaluator =
OutputEvaluator(
rubric="Score 1.0 if the response is accurate and directly answers the question. "
"Score 0.5 if partially correct. Score 0.0 if incorrect or irrelevant."
)
trajectory_evaluator =
TrajectoryEvaluator(
rubric="Verify the agent used appropriate tools for the task."
)
然后,您创建一个包含案例和评估器的实验。
experiment = Experiment(
cases=cases,
evaluators=[output_evaluator, trajectory_evaluator]
)
最后,您使用您的任务函数运行评估并检查结果。
def my_task(case):
agent = Agent(tools=[weather_tool, calculator_tool])
result = agent(case.input)
return {
"output": str(result),
"trajectory": tools_use_extractor.extract_agent_tools_used(agent.messages)
}
reports = experiment.run_evaluations(my_task)
for report in reports:
report.display()
EvaluationReport 提供总体分数、每个案例的明细、通过/失败状态以及每个评估器的详细原因。您可以在控制台中以交互方式显示结果,导出为 JSON 进行进一步分析,或集成到 CI/CD 管道中。对于较大的测试套件,Strands Evals 支持异步评估和可配置的并行处理:
reports = await experiment.run_evaluations_async(my_task, max_workers=10)
大规模生成测试案例
前面的工作流程假设您已经准备好了测试案例。随着您的代理功能不断增长,手动创建全面的测试套件既繁琐。Strands Evals 包含一个 ExperimentGenerator,它使用 LLM 从高级描述中创建测试案例和评估评分标准。
from strands_evals.generators import ExperimentGenerator
from strands_evals.evaluators import OutputEvaluator
generator =
ExperimentGenerator(
input_type=str,
output_type=str,
include_expected_output=True
)
experiment = await generator.from_context_async(
context="A customer service agent for an e-commerce platform",
task_description="Handle customer inquiries about orders, returns, and products",
num_cases=20,
evaluator=OutputEvaluator
)
生成器会创建涵盖指定上下文不同方面的多样化测试案例,并具有适当的难度级别。它还可以生成针对任务量身定制的评估评分标准。生成的案例在早期开发中尤其有价值,此时您想要广泛的覆盖范围,但尚未识别出特定的失败模式。随着评估实践的成熟,用手工制作的案例来针对已知的边缘情况来补充。
将评估集成到您的工作流程中
作为常规开发工作流程的一部分,评估可以发挥最大的价值。在开发过程中,随着您进行更改,频繁运行评估。快速反馈有助于您及早发现回归问题,并了解更改如何影响不同的质量维度。
在 CI/CD 管道中,将评估作为部署前的质量门。设置必须满足才能通过构建的分数阈值。这有助于防止质量回归进入生产环境。对于生产监控,定期使用离线评估来评估真实用户交互。这会揭示开发测试可能遗漏的模式:不寻常的查询、您未预料到的边缘情况,或者代理行为的逐渐漂移。跟踪评估结果随时间的变化。趋势指标有助于您了解质量是正在改善还是在下降。
代理评估最佳实践
- 从小处着手,迭代改进:从少数代表您最关键用户场景的测试案例开始。随着您在实践中观察到代理的失败方式,添加针对这些特定失败模式的定向案例。一个能够捕捉到真实问题的专注测试套件比一个覆盖率差的大型套件更有价值。
- 将评估器与您的质量目标相匹配:选择直接衡量您的用例最重要的指标的评估器。面向客户的代理可能优先考虑
HelpfulnessEvaluator和GoalSuccessRateEvaluator,而研究助理可能更看重FaithfulnessEvaluator。避免添加所有可用评估器的诱惑,因为这会增加成本并可能分散注意力。 - 编写清晰、具体的评分标准:基于评分标准的评估器的好坏取决于您提供的评分标准。避免使用“好的响应”等模糊的标准,而应使用具体、可衡量的标准。包含构成高、中、低分数的示例。在运行完整评估之前,先在示例输出上测试您的评分标准。
- 结合在线和离线评估:在开发过程中使用在线评估来快速反馈代码更改。通过对生产跟踪进行离线评估来补充这一点,以捕获仅在真实用户行为中出现的潜在问题。这两种方法揭示不同类型的难题。
- 设置有意义的阈值:根据您实际的质量要求设置通过/失败阈值,而不是任意数字。如果您的用户需要 0.95 的准确率,0.8 的阈值就没有意义。分析评估结果以了解哪些分数与良好的用户成果相关,然后相应地设置阈值。
- 跟踪趋势:单独的评估运行提供快照,但趋势揭示了发展轨迹。存储评估结果并跨版本跟踪关键指标。渐进式退化可能比突然的失败更难注意到,但同样具有破坏性。
- 投资于测试案例的多样性:涵盖您的代理将遇到的所有输入范围:常见查询、边缘情况、对抗性输入和多轮对话。使用
ExperimentGenerator进行广泛覆盖,然后用手工制作的案例来针对已知弱点进行补充。 - 在多个级别上进行评估:会话级别的成功可能会掩盖工具级别的缺陷,反之亦然。代理可能通过效率低下或不正确的中间步骤来实现用户目标。组合评估套件,在会话、跟踪和工具级别检查质量,以获得完整的图景。
结论
构建可靠的AI代理不仅仅需要直觉和抽查。它需要系统性的评估,能够随着时间的推移跨多个维度跟踪质量。Strands Evals 通过一个专门为代理评估的独特挑战而设计的框架,提供了这一基础。
任务函数将代理调用与评估逻辑分开,从而能够进行开发过程中的在线测试和生产跟踪的离线分析。基于 LLM 的评估器提供了质量评估所需的判断力。分层的评估级别允许在多个粒度上进行评估,从单个工具调用到完整的对话会话。用户模拟器将多轮测试从脚本练习转变为真实的模拟用户行为。
这些功能可以帮助您通过证据而不是假设来建立对AI代理的信心。您可以衡量更改是提高了还是降低了质量,在生产环境部署之前捕获回归问题,并向利益相关者证明您的代理满足定义的质量标准。
我们鼓励您探索 Strands Evals 以满足您的代理评估需求。 示例存储库 包含您可以适应自己用例的实用示例。从代表您最重要用户场景的几个测试案例开始,添加符合您质量标准的评估器,并将评估作为开发工作流程的一部分运行。随着时间的推移,扩展您的测试套件以涵盖更多场景。系统评估是帮助您自信地发布AI代理的基础。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区