



📢 转载信息
原文作者:Kanwal Mehreen
在本文中,您将学习如何使用FastAPI,从训练到本地测试和基本的生产加固,将一个已训练的机器学习模型打包到一个干净、经过良好验证的HTTP API后面。
我们将涵盖的主题包括:
- 训练、保存和加载scikit-learn管道以进行推理
- 使用Pydantic通过严格的输入验证来构建FastAPI应用
- 暴露、测试和使用健康检查加固预测端点
让我们来探讨这些技术。
面向机器学习从业者的FastAPI模型部署指南
图片来源:作者
如果您已经训练了一个机器学习模型,一个常见的问题就会出现:“我们到底该如何使用它?” 许多机器学习从业者都卡在了这一步。不是因为部署很难,而是因为部署的解释常常很糟糕。部署不是上传一个.pkl文件然后希望它能工作。它只是意味着允许另一个系统向您的模型发送数据并获取预测结果。最简单的方法是将模型置于API之后。FastAPI使这个过程变得简单。它以一种干净的方式连接了机器学习和后端开发。它速度快,提供带有Swagger UI的自动API文档,为您验证输入数据,并使代码易于阅读和维护。如果您已经在使用Python,那么使用FastAPI会感觉很自然。
在本文中,您将学习如何分步使用FastAPI部署机器学习模型。特别是,您将学习:
- 如何训练、保存和加载机器学习模型
- 如何构建FastAPI应用并定义有效输入
- 如何创建和本地测试预测端点
- 如何添加基本生产功能,如健康检查和依赖项
让我们开始吧!
Step 1: 训练与保存模型
第一步是训练您的机器学习模型。我正在训练一个模型来学习不同的房屋特征如何影响最终价格。您可以使用任何模型。创建一个名为train_model.py的文件:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import joblib
# Sample training data
data = pd.DataFrame({
"rooms": [2, 3, 4, 5, 3, 4],
"age": [20, 15, 10, 5, 12, 7],
"distance": [10, 8, 5, 3, 6, 4],
"price": [100, 150, 200, 280, 180, 250]
})
X = data[["rooms", "age", "distance"]]
y = data["price"]
# Pipeline = preprocessing + model
pipeline = Pipeline([
("scaler", StandardScaler()),
("model", LinearRegression())
])
pipeline.fit(X, y)训练后,您必须保存模型。
# Save the entire pipeline
joblib.dump(pipeline, "house_price_model.joblib")现在,在终端中运行以下命令:
python train_model.py您现在有了一个经过训练的模型以及预处理管道,已安全存储。
Step 2: 创建一个FastAPI应用
这比您想象的要容易。创建一个名为main.py的文件:
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
app = FastAPI(title="House Price Prediction API")
# Load model once at startup
model = joblib.load("house_price_model.joblib")您的模型现在已:
- 在启动时加载一次
- 保留在内存中
- 准备好提供预测
这已经比大多数初级部署要好。
Step 3: 定义模型期望的输入
这是许多部署失败的地方。您的模型不接受“JSON”。它接受特定结构中的数字。FastAPI使用Pydantic来干净地强制执行这一点。
您可能想知道Pydantic是什么:Pydantic是一个数据验证库,FastAPI用它来确保您的API接收的输入与模型期望的完全匹配。在请求到达模型之前,它会自动检查数据类型、必需的字段和格式。
class HouseInput(BaseModel):
rooms: int
age: float
distance: float这对您有两方面的好处:
- 验证传入数据
- 自动记录您的API
这样可以确保不再出现“为什么我的模型崩溃了?”的意外情况。
Step 4: 创建预测端点
现在您需要通过创建一个预测端点来使您的模型可用。
@app.post("/predict")
def predict_price(data: HouseInput):
features = [[
data.rooms,
data.age,
data.distance
]]
prediction = model.predict(features)
return {
"predicted_price": round(prediction[0], 2)
}这就是您部署的模型。您现在可以发送一个POST请求并获取预测结果。
Step 5: 在本地运行您的API
在终端中运行此命令:
uvicorn main:app --reload在浏览器中打开并转到:
http://127.0.0.1:8000/docs您将看到:
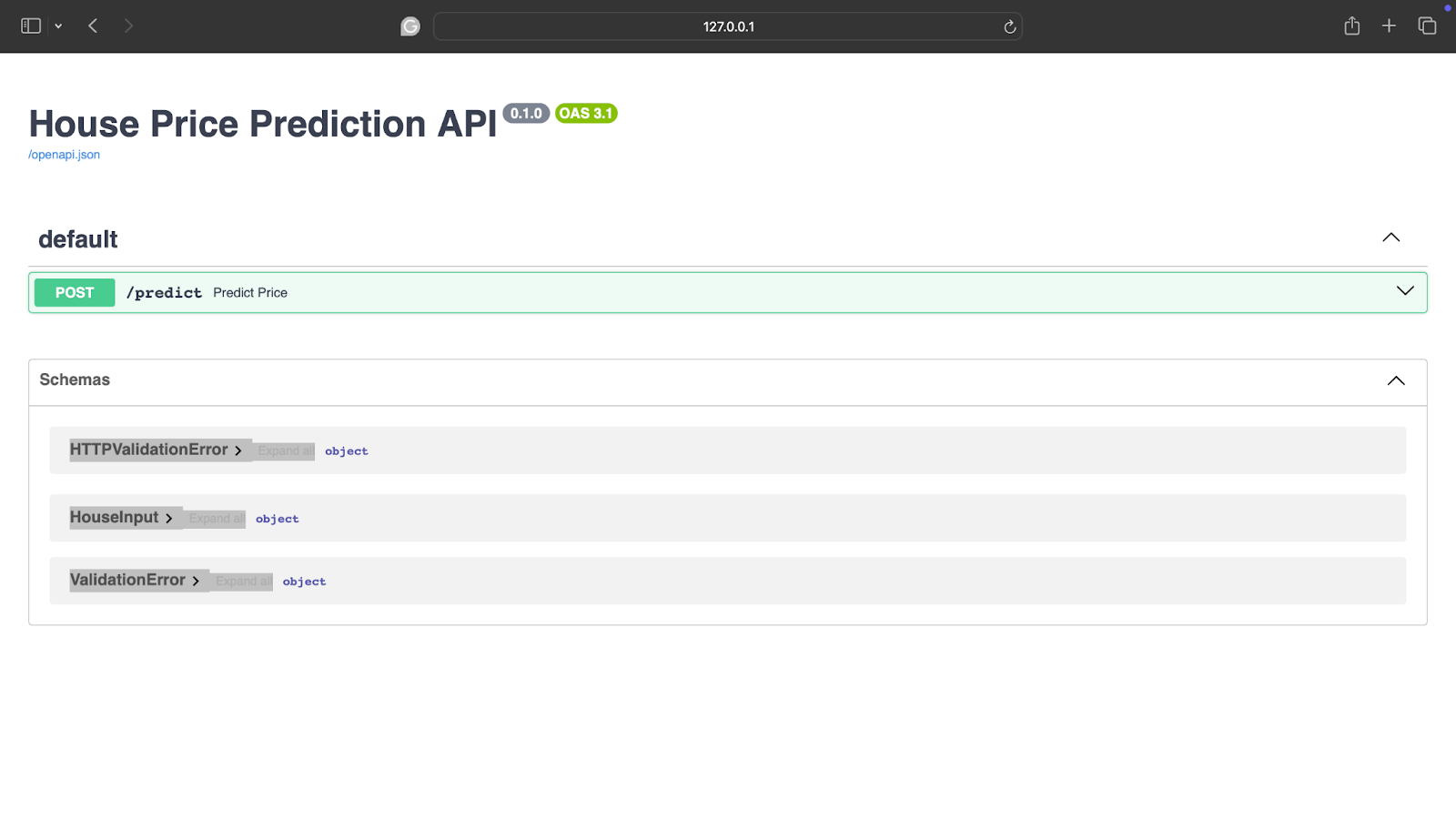
如果您不明白这意味着什么,您实际上看到的是:
- 交互式API文档
- 一个用于测试模型的表单
- 实时验证
Step 6: 使用真实输入进行测试
要进行测试,请点击以下箭头:
![]()
在此之后,点击“Try it out”。
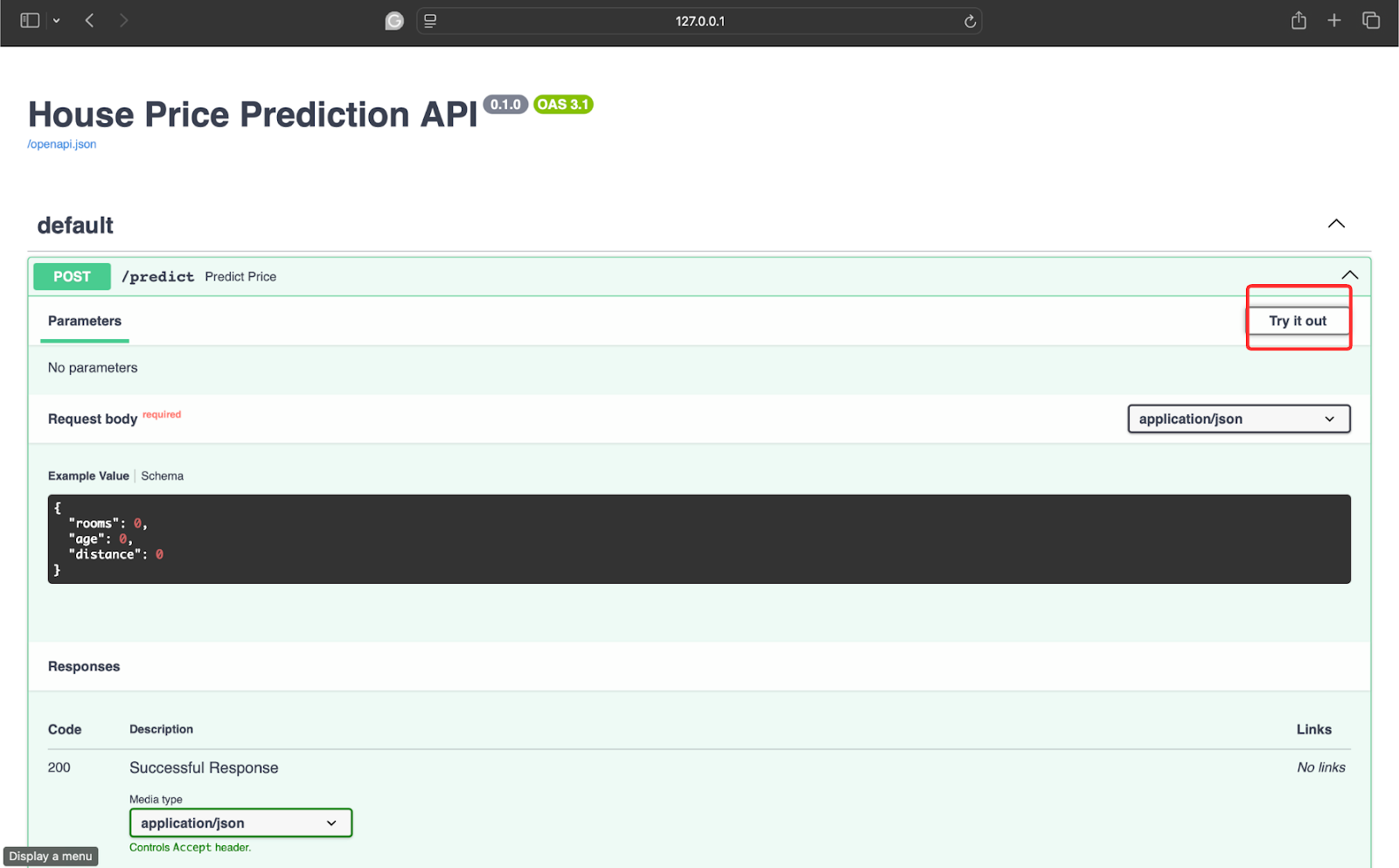
现在使用一些数据进行测试。我使用的是以下值:
{
"rooms": 4,
"age": 8,
"distance": 5
}现在,点击“Execute”以获取响应。
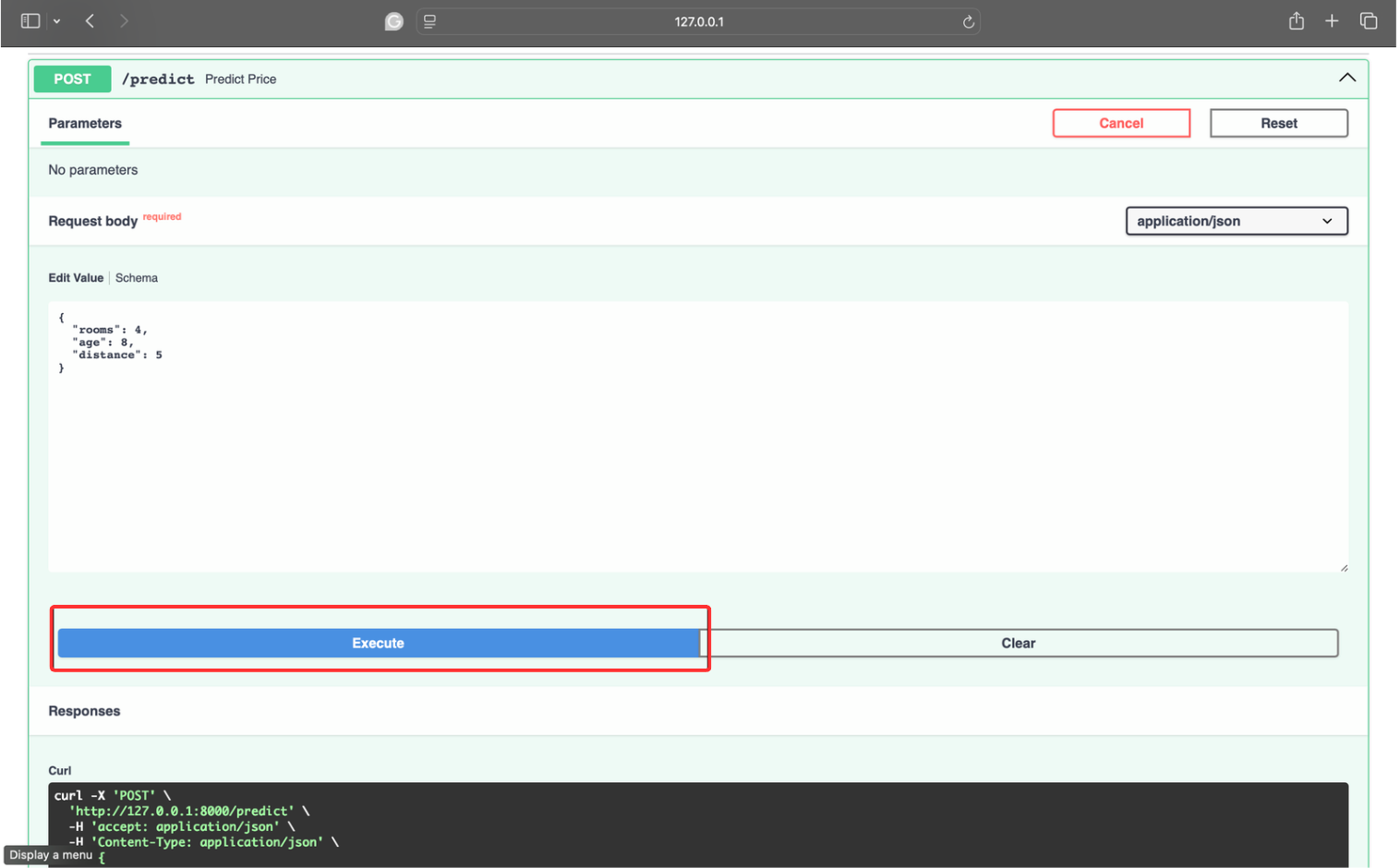
响应是:
{
"predicted_price": 246.67
}您的模型现在正在接受真实数据、返回预测结果,并准备好与应用程序、网站或其他服务集成。
Step 7: 添加健康检查
您不需要从第一天就开始使用Kubernetes,但请考虑:
- 错误处理(错误的输入是会发生的)
- 记录预测
- 模型版本控制(/v1/predict)
- 健康检查端点
例如:
@app.get("/health")
def health():
return {"status": "ok"}像这样的简单事情比花哨的基础设施更重要。
Step 8: 添加一个Requirements.txt文件
这一步看起来很小,但它是那些日后会悄悄为您节省数小时的步骤之一。您的FastAPI应用可能在您的机器上完美运行,但部署环境不知道您使用了哪些库,除非您告诉它们。这正是requirements.txt的用途。它是一个简单的列表,列出了项目运行所需的依赖项。创建一个名为requirements.txt的文件并添加:
fastapi
uvicorn
scikit-learn
pandas
joblib现在,每当有人需要设置这个项目时,他们只需运行以下命令:
pip install -r requirements.txt这确保了项目可以顺利运行而不会丢失任何包。整体项目结构如下所示:
project/
│
├── train_model.py
├── main.py
├── house_price_model.joblib
└── requirements.txt结论
在有人能使用它之前,您的模型就没有价值。FastAPI不会将您变成一个后端工程师——它只是消除了模型与现实世界之间的摩擦。一旦您部署了第一个模型,您就会停止像“模型训练者”一样思考,开始像一个交付解决方案的“从业者”一样思考。请不要忘记查阅FastAPI文档。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区