



📢 转载信息
原文作者:Dani Mitchell, Jean-Pierre Dodel, and Pallavi Nargund
我们很高兴地宣布,Amazon Bedrock 知识库的多模态检索功能现已全面可用。这项新功能在文本和图像的基础上,新增了对视频和音频内容的本地支持。借助它,您可以在一个完全托管的服务中构建能够跨文本、图像、音频和视频搜索和检索信息的检索增强生成 (RAG) 应用程序。
现代企业将有价值的信息存储在多种格式中。产品文档包含图表和屏幕截图,培训材料包含教学视频,客户见解则记录在录制的会议中。直到现在,构建能够有效搜索这些内容类型的人工智能 (AI) 应用程序都需要复杂的定制基础设施和大量的工程工作。
以前,Bedrock 知识库使用基于文本的嵌入模型进行检索。虽然它支持文本文档和图像,但图像必须使用基础模型 (FM) 或 Bedrock 数据自动化来生成文本描述——这是一种“文本优先”的方法,会丢失视觉上下文并阻止视觉搜索功能。视频和音频则需要定制的外部预处理管道。现在,借助多模态嵌入,检索器可以在单个嵌入模型中原生支持文本、图像、音频和视频。
通过 Bedrock 知识库中的多模态检索,您现在可以使用单一的统一工作流程,从文本、图像、视频和音频中摄取、索引和检索信息。内容使用多模态嵌入进行编码,从而保留视觉和音频上下文,使您的应用程序能够在不同媒体类型中查找相关信息。您甚至可以仅使用图像进行搜索,以查找视觉上相似的内容或在视频中定位特定场景。
在本文中,我们将指导您完成构建多模态 RAG 应用程序的过程。您将了解多模态知识库的工作原理、如何根据内容类型选择正确的处理策略,以及如何使用控制台和代码示例来配置和实现多模态检索。
理解多模态知识库
Amazon Bedrock 知识库自动化了整个 RAG 工作流程:从您的数据源摄取内容、将其解析和分块成可搜索的片段、将片段转换为向量嵌入,并将它们存储在向量数据库中。在检索期间,用户查询被嵌入并与存储的向量进行匹配,以查找语义上相似的内容,从而增强发送到基础模型的提示。
通过多模态检索,此工作流程现在通过两种处理方法来处理图像、视频和音频,以及文本。Amazon Nova 多模态嵌入将内容原生编码到一个统一的向量空间中,用于跨模态检索,您可以查询文本并检索视频,或者使用图像搜索以查找视觉内容。
或者,Bedrock 数据自动化在嵌入之前将多媒体内容转换为丰富的文本描述和转录,从而在口头内容上实现高准确度的检索。您的选择取决于视觉上下文还是语音精度对您的用例最重要。
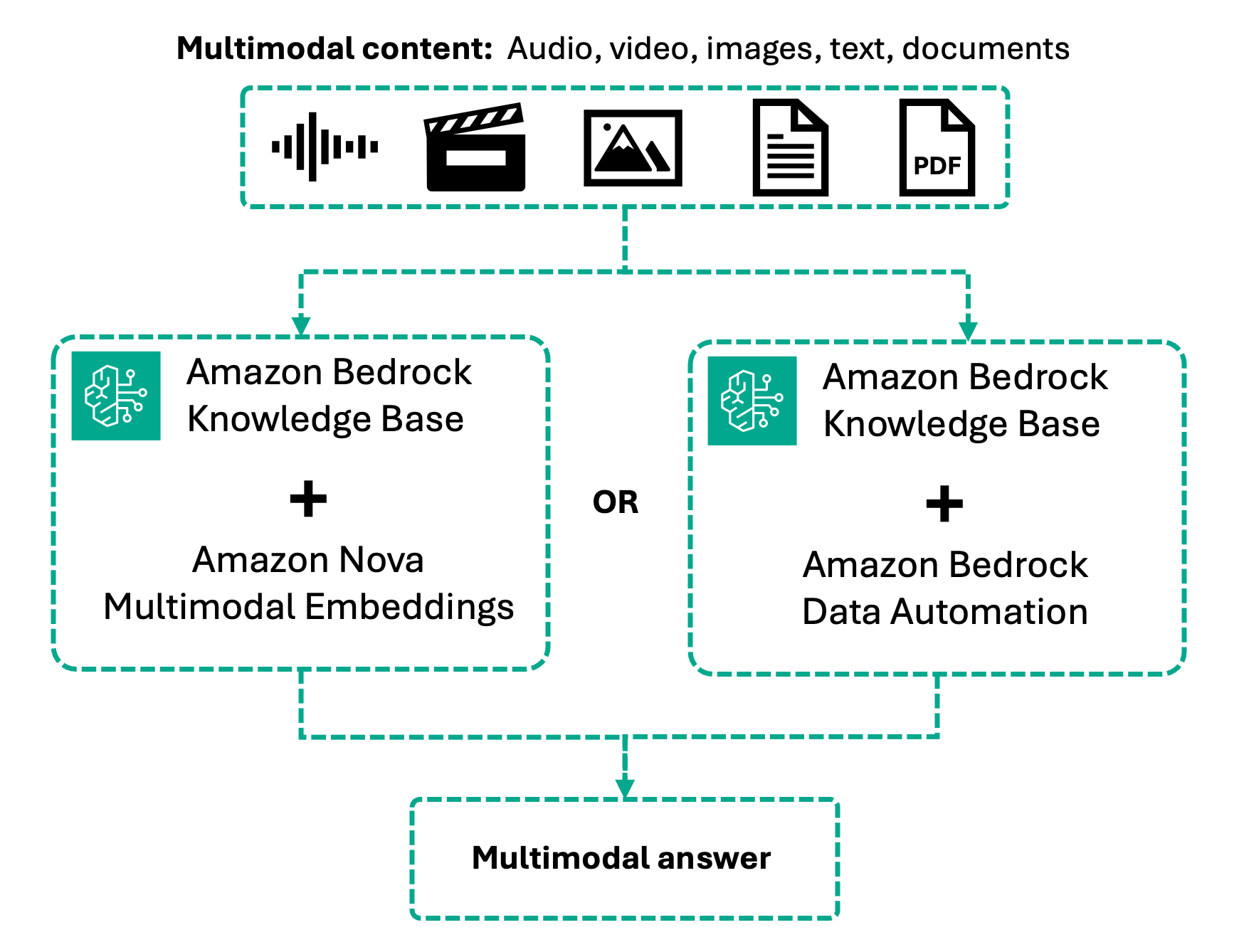
我们在本文中探讨了每种方法。
Amazon Nova 多模态嵌入
Amazon Nova 多模态嵌入是第一个统一的嵌入模型,它将文本、文档、图像、视频和音频编码到单个共享的向量空间中。内容在不进行文本转换的情况下被原生处理。该模型支持高达 8,172 个文本 token 和 30 秒的视频/音频片段,支持超过 200 种语言,并提供四种嵌入维度(默认 3072 维,还有 1,024、384、256)以平衡准确性和效率。Bedrock 知识库会自动将视频和音频分块(5-30 秒),每个片段独立嵌入。
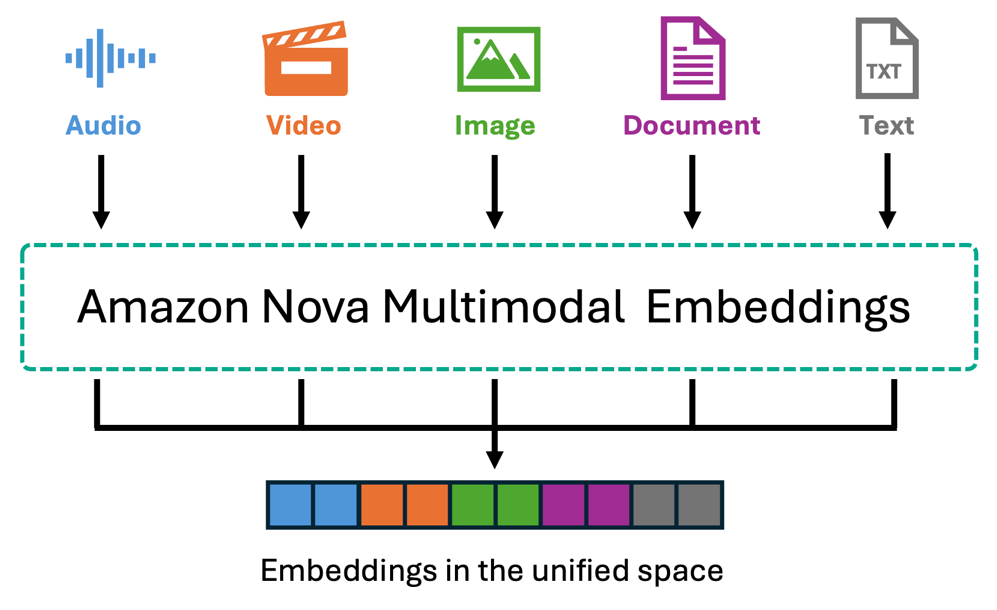
对于视频内容,Nova 嵌入会捕获视觉元素——场景、对象、运动和动作——以及音乐、声音和环境噪音等音频特征。对于口语对话对您的用例很重要的视频,您可以使用 Bedrock 数据自动化来提取视觉描述以及转录。对于独立的音频文件,Nova 会处理音乐、环境声音和音频模式等声学特征。跨模态功能支持多种用例,例如:用文本描述一个视觉场景来检索匹配的视频、上传参考图像以查找相似产品,或在素材中定位特定动作——所有这些都无需预先存在的文本描述。
最适合:产品目录、视觉搜索、制造视频、体育赛事素材、安防摄像头以及视觉内容驱动用例的场景。
Amazon Bedrock 数据自动化
Bedrock 数据自动化采取了不同的方法,它将多媒体内容转换为丰富的文本表示,然后再进行嵌入。对于图像,它会生成详细的描述,包括对象、场景、图像中的文本和空间关系。对于视频,它会生成逐场景的摘要,识别关键视觉元素,并提取屏幕上的文本。对于包含语音的音频和视频,Bedrock 数据自动化提供带有时间戳和说话人识别的准确转录,以及捕获讨论要点的片段摘要。
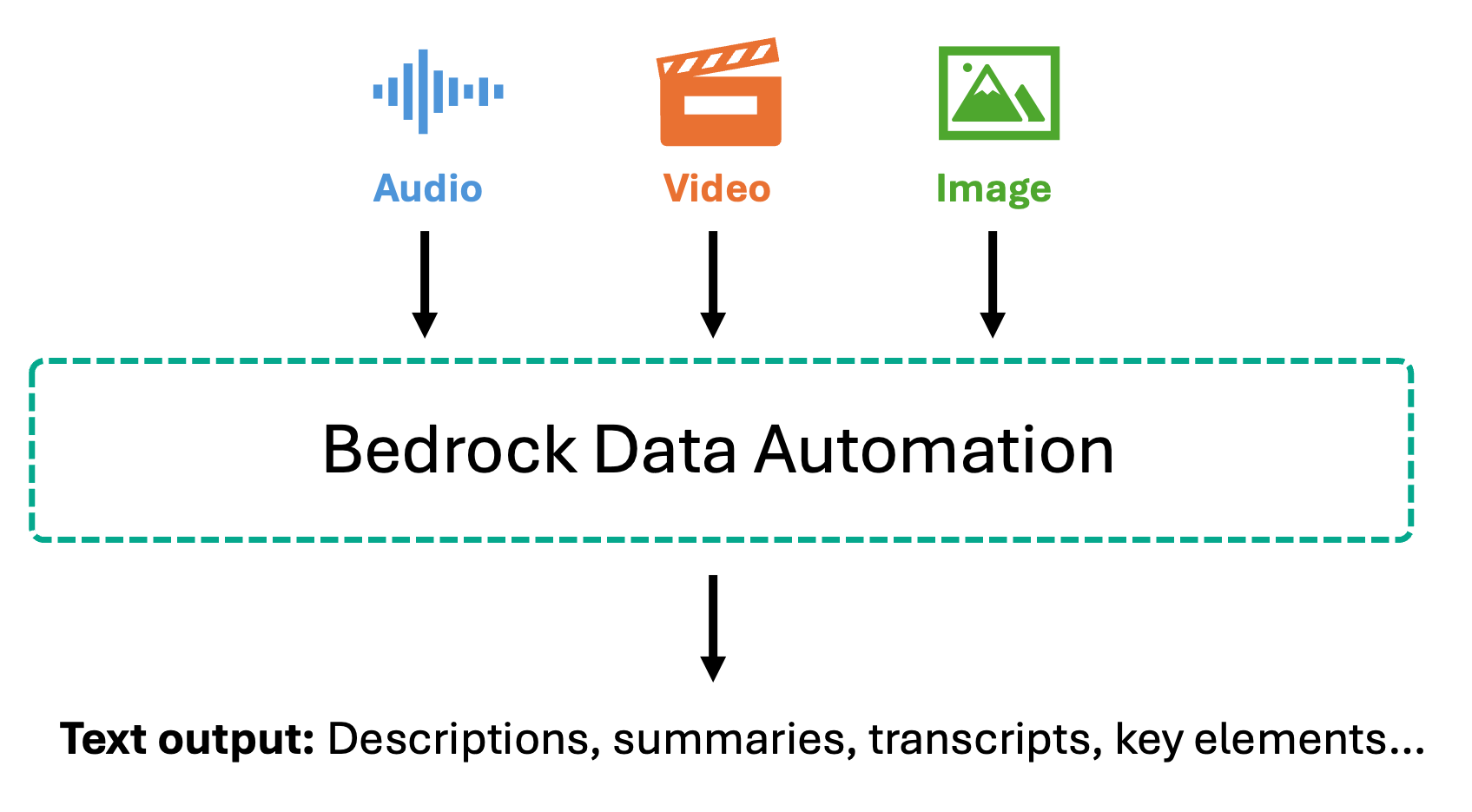
一旦转换为文本,这些内容就会使用文本嵌入模型(如 Amazon Titan 文本嵌入或 Amazon Nova 多模态嵌入)进行分块和嵌入。这种文本优先的方法使得对口头内容的提问回答非常准确——当用户询问会议中发表的具体言论或播客中讨论的主题时,系统会搜索精确的转录本,而不是音频嵌入。这对于需要确切引文和逐字记录以用于审计跟踪、会议分析、客户支持电话挖掘以及需要检索和验证特定口头信息的合规性场景特别有价值。
最适合:会议、网络研讨会、访谈、播客、培训视频、支持电话,以及需要精确检索特定陈述或讨论的场景。
用例场景:电子商务的视觉产品搜索
多模态知识库可用于从增强的客户体验和员工培训到维护操作和法律分析等各种应用。传统的电子商务搜索依赖于文本查询,要求客户使用正确的关键词来阐述他们正在寻找的内容。当他们在别处看到了一个产品,有一张他们喜欢的物品的照片,或者想找到与视频中出现的内容相似的物品时,这种方法就会失效。现在,客户可以通过文本描述搜索您的产品目录,上传他们拍摄的物品的图片,或引用视频中的场景来查找匹配的产品。系统通过将其查询的嵌入表示(无论是文本、图像还是视频)与您的产品库存的多模态嵌入进行比较,来检索视觉上相似的项目。对于这种情况,Amazon Nova 多模态嵌入是理想的选择。产品发现本质上是视觉化的——客户关心颜色、款式、形状和视觉细节。通过将您的产品图像和视频编码到 Nova 统一向量空间中,系统可以根据视觉相似性进行匹配,而无需依赖可能遗漏细微视觉特征的文本描述。虽然完整的推荐系统会纳入客户偏好、购买历史和库存可用性,但多模态知识库的检索提供了基础能力:无论客户选择何种搜索方式,都能找到视觉上相关的产品。
控制台演练
在接下来的部分中,我们将指导您完成为电子商务产品搜索示例设置和测试多模态知识库的高级步骤。我们将创建一个包含智能手机产品图像和视频的知识库,然后演示客户如何使用文本描述、上传的图像或视频参考进行搜索。 GitHub 仓库提供了一个指导性 Notebook,您可以按照该 Notebook 在您自己的账户中部署此示例。
先决条件
在开始之前,请确保您具备以下先决条件:
- 一个具有适当服务访问权限的 AWS 账户
- 一个具有适当权限来访问 Amazon Bedrock 和 Amazon Simple Storage Service (Amazon S3) 的 AWS 身份和访问管理 (IAM) 角色
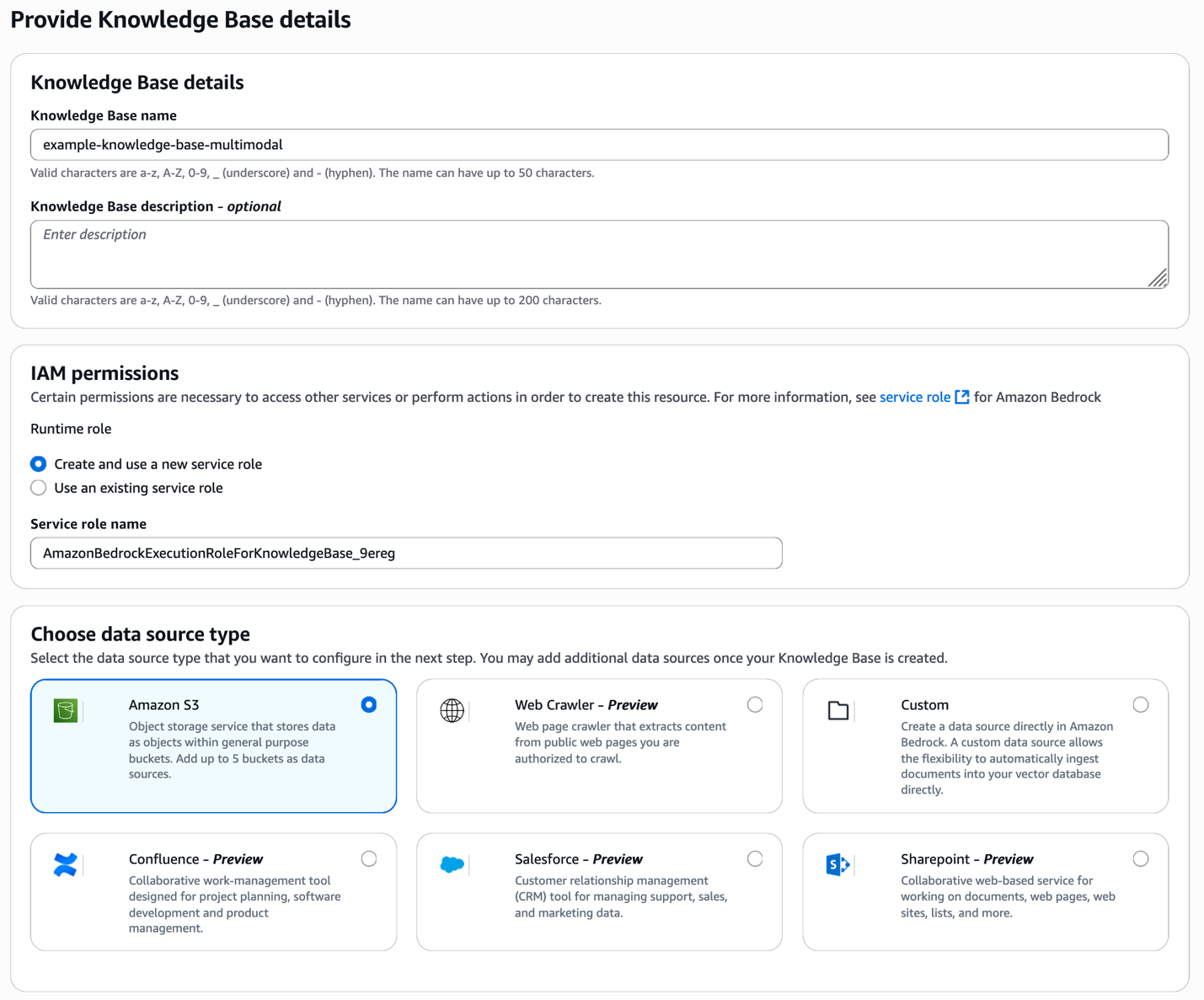
提供知识库详细信息和数据源类型
首先,打开 Amazon Bedrock 控制台并创建新的知识库。提供知识库的描述性名称,并选择您的数据源类型——在这种情况下,是存储产品图像和视频的 Amazon S3。
配置数据源
连接包含产品图像和视频的 S3 存储桶。对于解析策略,选择 Amazon Bedrock 默认解析器。由于我们使用的是 Nova 多模态嵌入,图像和视频会被原生处理并直接嵌入到统一的向量空间中,从而在不转换为文本的情况下保留其视觉特性。
配置数据存储和处理
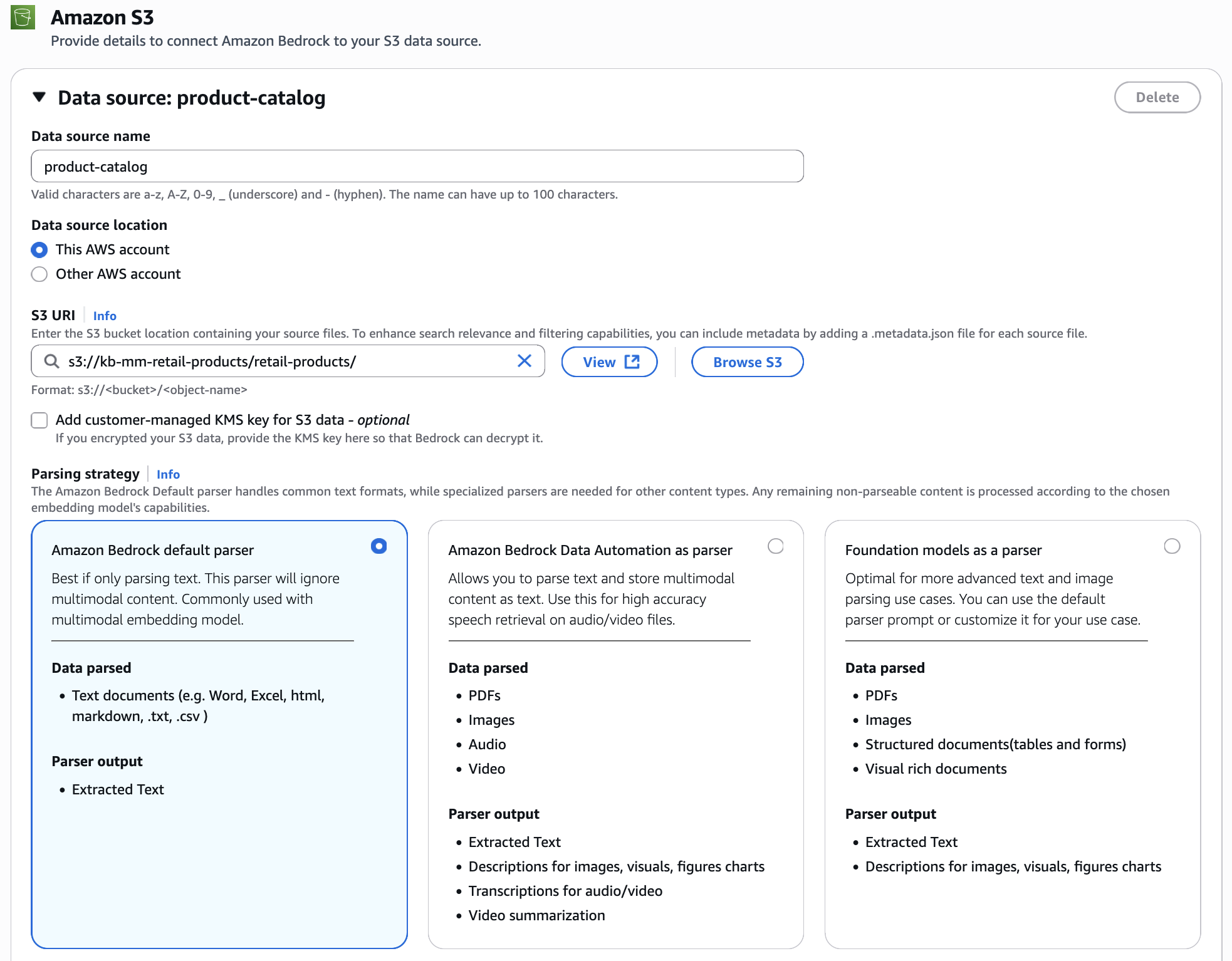
选择 Amazon Nova 多模态嵌入作为您的嵌入模型。这个统一的嵌入模型将您的产品图像和客户查询编码到同一个向量空间中,从而实现跨模态检索,文本查询可以检索图像,图像查询可以查找视觉相似的产品。对于此示例,我们使用 Amazon S3 向量作为向量存储(您也可以选择使用其他可用的向量存储),它提供经济高效且持久的存储,针对大规模向量数据集进行了优化,同时保持了亚秒级的查询性能。您还需要通过指定 S3 位置来配置多模态存储目的地。知识库使用此位置来存储从您的数据源中提取的图像和其他媒体。当用户查询知识库时,相关媒体会从该存储中检索。
审查和创建
审查您的配置设置,包括知识库详细信息、数据源配置、嵌入模型选择——我们使用的是 Amazon Nova 多模态嵌入 v1,带有 3072 向量维度(更高维度提供更丰富的表示;您可以使用较低维度如 1,024、384 或 256 来优化存储和成本)——以及向量存储设置(Amazon S3 向量)。一切看起来正确后,创建您的知识库。
创建摄取作业
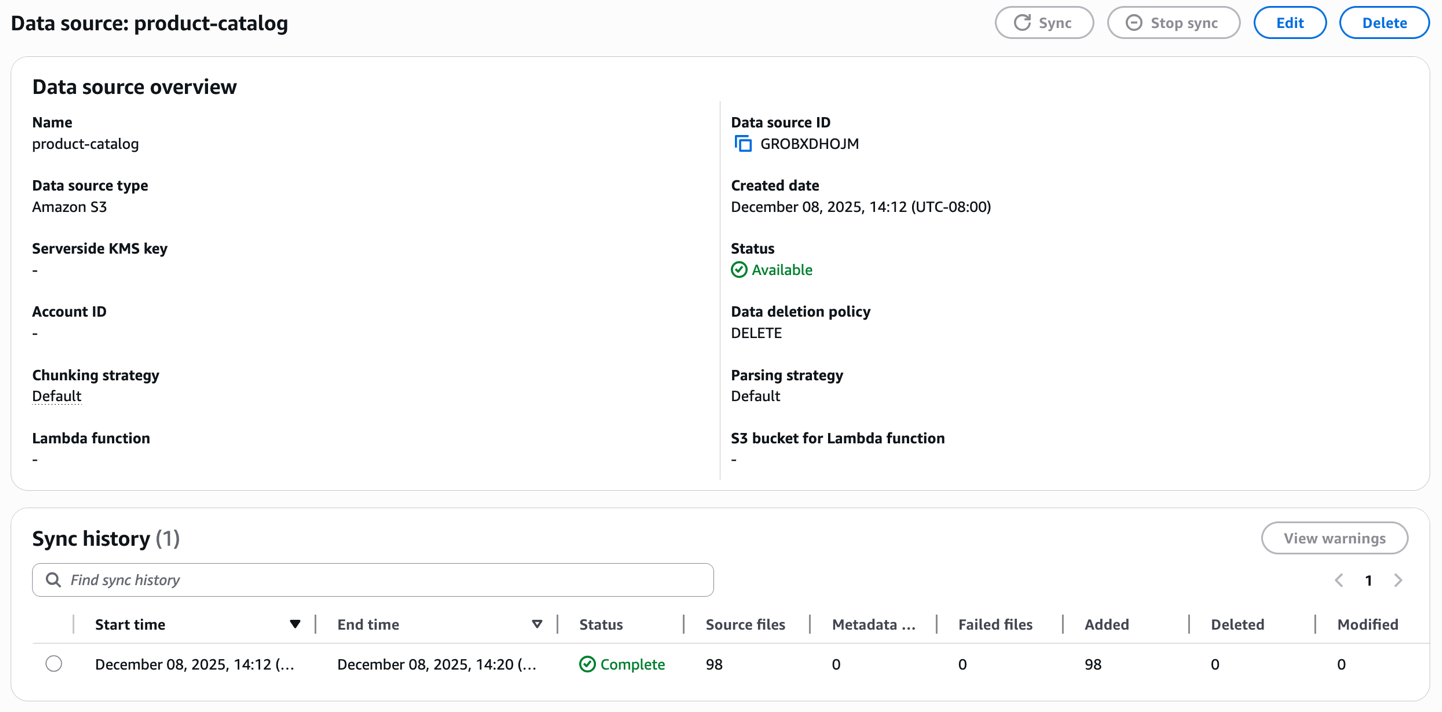
创建后,启动同步过程以摄取您的产品目录。知识库处理每个图像和视频,生成嵌入并将它们存储在托管的向量数据库中。监控同步状态以确认文档已成功索引。
使用提示中的文本作为输入来测试知识库
知识库准备就绪后,请在控制台中尝试使用文本查询对其进行测试。使用“金属手机壳”(或任何可能与您的产品媒体相关的等效描述)进行搜索,以验证基于文本的检索是否在您的目录中正确工作。

使用参考图像测试知识库并检索不同模态
现在是强大的部分——视觉搜索。上传您想要查找的产品的参考图像。例如,想象您在另一个网站上看到了一个手机壳,并想在您的目录中查找相似的商品。只需上传图像,无需额外的文本提示。
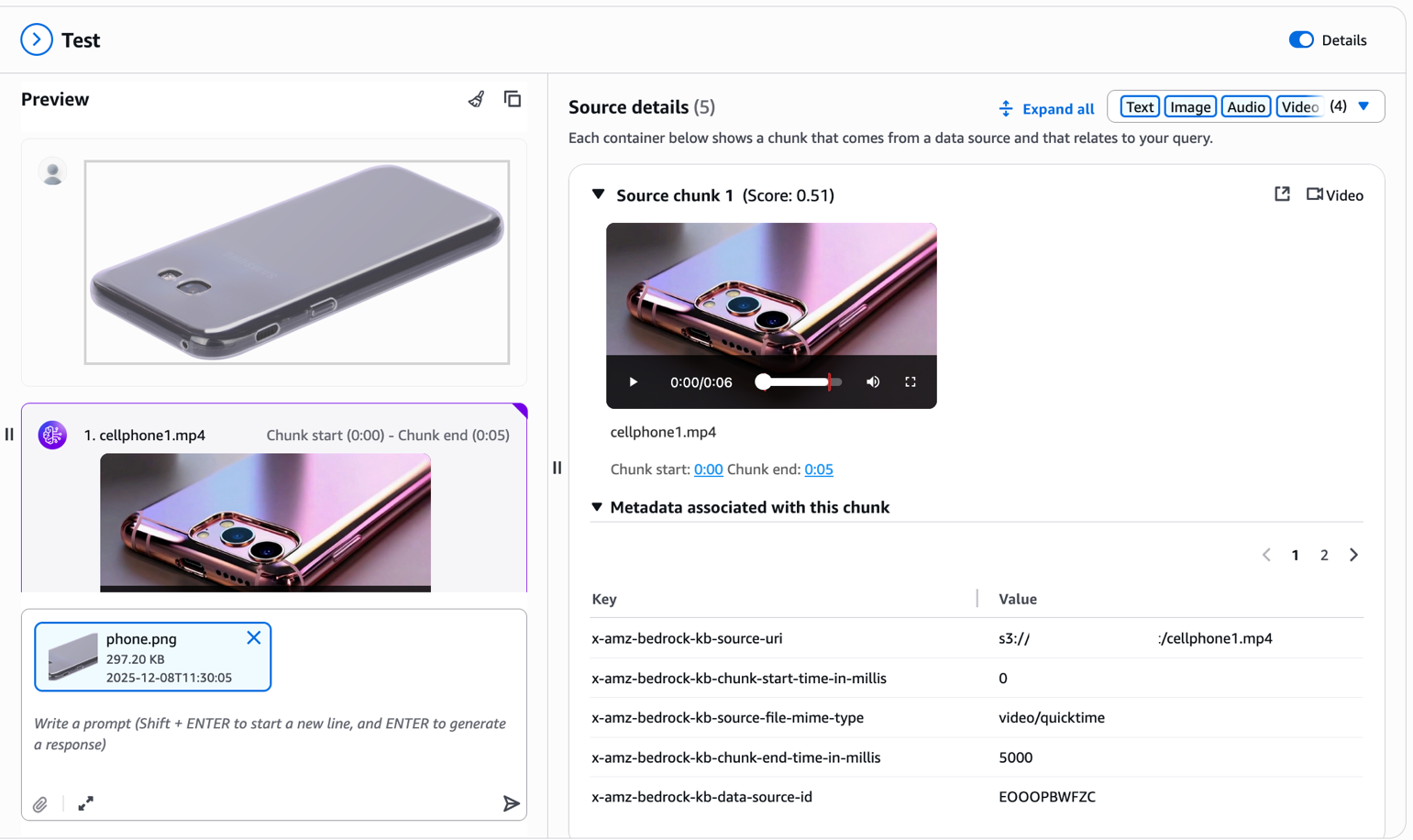
多模态知识库会从您上传的图像中提取视觉特征,并从您的目录中检索视觉上相似的产品。正如您在结果中看到的,系统会返回具有相似设计图案、颜色或视觉特征的手机壳。请注意源详细信息面板中每个片段关联的元数据。x-amz-bedrock-kb-chunk-start-time-in-millis 和 x-amz-bedrock-kb-chunk-end-time-in-millis 字段指示了该片段在源视频中的确切时间位置。在以编程方式构建应用程序时,您可以使用这些时间戳来提取和显示匹配的特定视频片段,从而实现“跳转到相关时刻”或直接从源视频生成剪辑等功能。这种跨模态能力改变了购物体验——客户不再需要用语言来描述他们正在寻找的东西;他们可以“展示”给你看。
使用参考图像测试知识库并使用 Bedrock 数据自动化检索不同模态
现在我们来看看如果配置了 Bedrock 数据自动化解析,数据源设置时结果会是什么样子。在下面的截图中,请注意源详细信息面板中的转录部分。
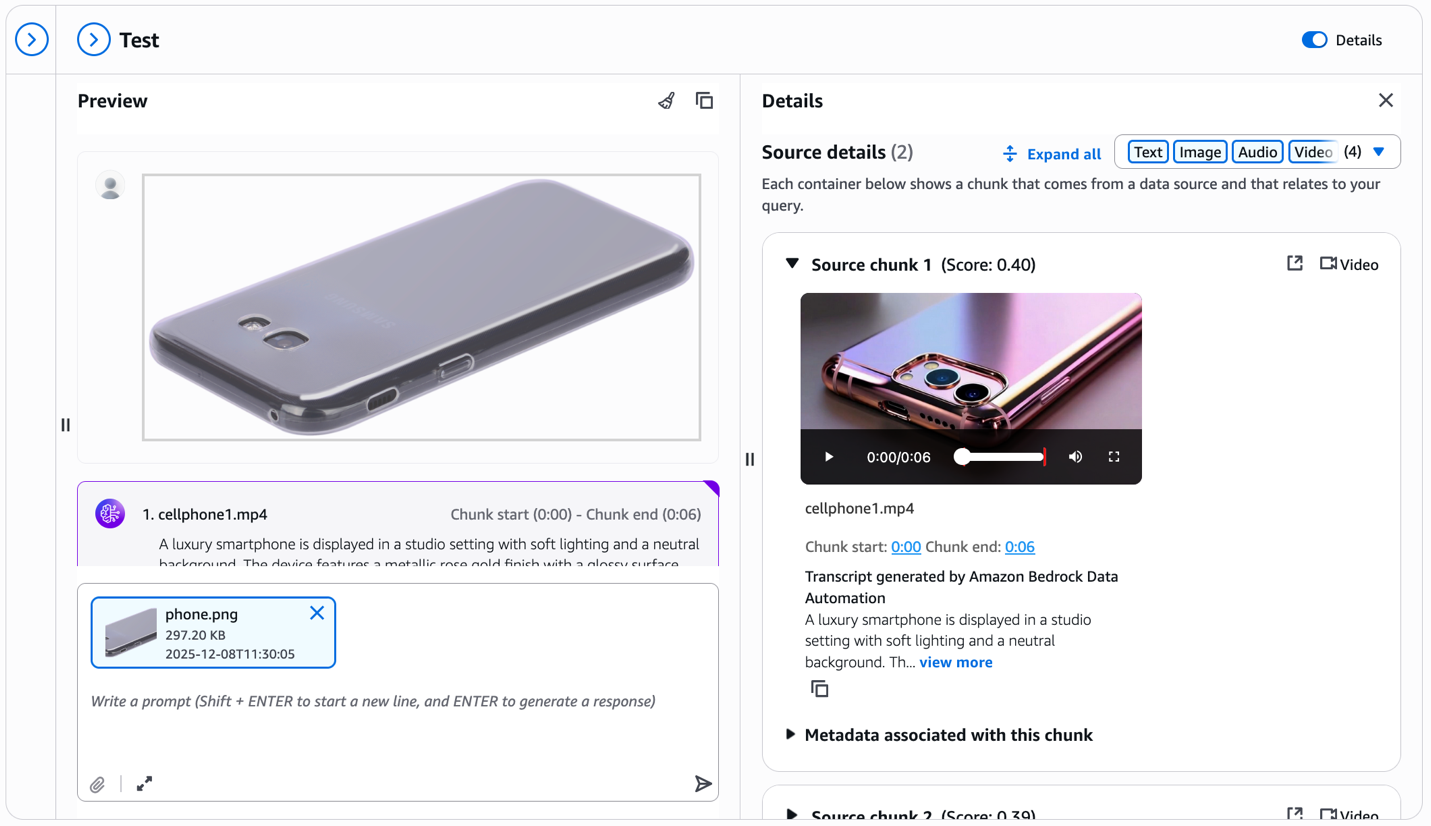
对于每个检索到的视频片段,Bedrock 数据自动化会自动生成详细的文本描述——在这个例子中,描述了智能手机的金属玫瑰金饰面、工作室灯光和视觉特征。此转录与视频一起直接显示在测试窗口中,提供了丰富的文本上下文。您将获得来自多模态嵌入的视觉相似性匹配,以及详细的产品描述,这些描述可以回答有关视频中可见的特定功能、颜色、材料和其他属性的问题。
清理
要清理您的资源,请按照以下步骤操作,首先删除知识库:
- 在 Amazon Bedrock 控制台上,选择 Knowledge Bases
- 选择您的知识库,并记下 IAM 服务角色名称和 S3 向量索引 ARN
- 选择 Delete 并确认
要删除 S3 向量作为向量存储,请使用以下 AWS 命令行界面 (AWS CLI) 命令:
aws s3vectors delete-index --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --index-name YOUR_INDEX_NAME --region YOUR_REGION
aws s3vectors delete-vector-bucket --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --region YOUR_REGION- 在 IAM 控制台上,找到前面记下的角色
- 选择并删除该角色
要删除示例数据集:
- 在 Amazon S3 控制台上,找到您的 S3 存储桶
- 选择并删除您为本教程上传的文件
结论
Amazon Bedrock 知识库的多模态检索消除了构建跨文本、图像、视频和音频的 RAG 应用程序的复杂性。通过对视频和音频内容的原生支持,您现在可以构建全面的知识库,从您的企业数据中(而不仅仅是文本文档中)解锁见解。
在 Amazon Nova 多模态嵌入和 Bedrock 数据自动化之间的选择,让您可以灵活地针对特定内容进行优化。Nova 统一向量空间支持以视觉驱动的用例的跨模态检索,而 Bedrock 数据自动化的文本优先方法则为基于语音的内容提供精确的转录检索。这两种方法都无缝集成到同一个完全托管的工作流程中,无需定制的预处理管道。
可用性
区域可用性取决于为多模态支持选择的功能,请参阅 文档 了解详细信息。
后续步骤
立即开始使用多模态检索:
- 探索文档:查阅 Amazon Bedrock 知识库文档 和 Amazon Nova 用户指南以获取更多技术细节。
- 试验代码示例:查看 Amazon Bedrock 示例存储库,其中包含演示多模态检索的实践 Notebook。
- 了解更多关于 Nova 的信息:阅读 Amazon Nova 多模态嵌入发布公告,以获得更深入的技术见解。
关于作者
 Dani Mitchell 是亚马逊云科技 (AWS) 的一名生成式 AI 专家解决方案架构师。他专注于利用 Amazon Bedrock 和 Bedrock AgentCore 帮助全球企业加速其生成式 AI 之旅。
Dani Mitchell 是亚马逊云科技 (AWS) 的一名生成式 AI 专家解决方案架构师。他专注于利用 Amazon Bedrock 和 Bedrock AgentCore 帮助全球企业加速其生成式 AI 之旅。
 Pallavi Nargund 是 AWS 的一名首席解决方案架构师。她是美国绿色地带 (US Greenfield) 的生成式 AI 负责人,并领导 AWS 法律科技团队。她热衷于技术领域的女性,并且是亚马逊女性 AI/ML 核心成员。她曾在 AWS re:Invent、AWS Summit 和网络研讨会等内部和外部会议上发表演讲。Pallavi 拥有印度浦那大学的工程学学士学位。她与丈夫、两个女儿和两条小狗一起居住在新泽西州的爱迪生。
Pallavi Nargund 是 AWS 的一名首席解决方案架构师。她是美国绿色地带 (US Greenfield) 的生成式 AI 负责人,并领导 AWS 法律科技团队。她热衷于技术领域的女性,并且是亚马逊女性 AI/ML 核心成员。她曾在 AWS re:Invent、AWS Summit 和网络研讨会等内部和外部会议上发表演讲。Pallavi 拥有印度浦那大学的工程学学士学位。她与丈夫、两个女儿和两条小狗一起居住在新泽西州的爱迪生。
 Jean-Pierre Dodel 是 Amazon Bedrock、Amazon Kendra 和 Amazon Quick Index 的一名首席产品经理。他将 15 年的企业搜索和 AI/ML 经验带到团队,此前曾在 Autonomy、惠普和几家搜索初创公司工作,八年前加入亚马逊。JP 目前专注于多模态 RAG、智能体检索和结构化 RAG 的创新。
Jean-Pierre Dodel 是 Amazon Bedrock、Amazon Kendra 和 Amazon Quick Index 的一名首席产品经理。他将 15 年的企业搜索和 AI/ML 经验带到团队,此前曾在 Autonomy、惠普和几家搜索初创公司工作,八年前加入亚马逊。JP 目前专注于多模态 RAG、智能体检索和结构化 RAG 的创新。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区