



📢 转载信息
原文作者:Mahima Chaudhary, Anupam Dewan, and Swapneil Singh
借助各种 Nova 定制化服务,从平台迁移到定制化之旅传统上一直很复杂,需要技术专长、基础设施设置和大量时间投入。我们旨在解决的就是这种潜在应用与实际应用之间的脱节。Nova Forge SDK 使大规模语言模型(LLM)的定制化变得触手可及,让团队能够充分发挥语言模型的潜力,而无需应对依赖管理、镜像选择和配方配置等挑战。我们将定制化视为扩展阶梯中的一个连续体,因此,Nova Forge SDK 支持所有定制化选项,从基于 Amazon SageMaker AI 的适配到使用 Amazon Nova Forge 功能的深度定制化。
在上一篇文章中,我们介绍了 Nova Forge SDK 以及如何开始使用它,并附带了先决条件和设置说明。在这篇文章中,我们将引导您完成使用 Nova Forge SDK 通过 Amazon SageMaker AI Training Jobs 训练 Amazon Nova 模型的过程。我们将评估模型在 StackOverFlow 数据集上的基线性能,使用监督微调(SFT)来优化其性能,然后对定制化模型应用强化微调(RFT)以进一步提高响应质量。在每次微调后,我们都会评估模型,以展示其在整个定制化过程中的改进。最后,我们将定制化模型部署到 Amazon SageMaker AI 推理端点。
接下来,让我们通过一个自动将 Stack Overflow 问题分类到三个明确类别(HQ、LQ EDIT、LQ CLOSE)的实际场景来了解 Nova Forge SDK 的优势。
案例研究:将给定问题分类到正确的类别
Stack Overflow 有成千上万的问题,质量差异很大。自动对问题质量进行分类有助于版主优先处理他们的工作,并指导用户改进他们的帖子。此解决方案演示了如何使用 Amazon Nova Forge SDK 构建一个自动质量分类器,该分类器可以区分高质量帖子、需要编辑的低质量帖子以及应被关闭的帖子。我们使用Stack Overflow 问题质量数据集,其中包含 2016-2020 年的 60,000 个问题,分为三类:
HQ(高质量):编写良好且无需编辑的帖子LQ_EDIT(低质量 - 已编辑):得分较低且经过社区多次编辑的帖子,但仍保持开放状态LQ_CLOSE(低质量 - 已关闭):未经编辑就被社区关闭的帖子
在我们的实验中,我们随机抽取了 4700 个问题并进行了如下划分:
| 划分 | 样本数 | 百分比 | 目的 |
| 训练(SFT) | 3,500 | 约 75% | 监督微调 |
| 评估 | 500 | 约 10% | 基线和训练后评估 |
| RFT | 700 +(SFT 的 3,500) | 约 15% | 强化微调 |
对于 RFT,我们将 700 个 RFT 特定样本与所有 3,500 个 SFT 样本(总计:4,200 个样本)进行扩充,以防止在学习强化信号时灾难性遗忘监督能力。
实验包括四个主要阶段:基线评估以衡量开箱即用的性能,监督微调(SFT)以传授领域特定模式,以及在 SFT 检查点上进行强化微调(RFT)以优化特定质量指标,最后部署到 Amazon SageMaker AI。对于微调,每个阶段都建立在前一个阶段的基础上,每一步都有可衡量的改进。
我们为所有数据集使用了通用的系统提示:
This is a stack overflow question from 2016-2020 and it can be classified into three categories:
* HQ: High-quality posts without a single edit.
* LQ_EDIT: Low-quality posts with a negative score, and multiple community edits. However, they remain open after those changes.
* LQ_CLOSE: Low-quality posts that were closed by the community without a single edit.
You are a technical assistant who will classify the question from users into any of above three categories. Respond with only the category name: HQ, LQ_EDIT, or LQ_CLOSE.
**Do not add any explanation, just give the category as output.
第一阶段:建立基线性能
在微调之前,我们通过在评估集上评估预训练的 Nova 2.0 模型来建立基线。这为我们提供了衡量未来改进的具体基线。基线评估至关重要,因为它有助于您了解模型的开箱即用能力、识别性能差距、设定可衡量的改进目标以及验证微调的必要性。
安装 SDK
您可以使用简单的 pip 命令安装 SDK:
pip install amzn-nova-forge 导入关键模块:
rom amzn_nova_forge import ( NovaModelCustomizer, SMTJRuntimeManager, TrainingMethod, EvaluationTask, CSVDatasetLoader, Model, )准备评估数据
Amazon Nova Forge SDK 提供了强大的数据加载工具,可自动处理验证和转换。我们首先加载评估数据集并将其转换为 Nova 模型所需的格式:
CSVDatasetLoader 类负责数据验证和格式转换的繁重工作。query 参数映射到您的输入文本(Stack Overflow 问题),response 映射到地面真实标签,system 包含指导模型行为的分类说明。
# General Configuration
MODEL = Model.NOVA_LITE_2
INSTANCE_TYPE = 'ml.p5.48xlarge'
EXECUTION_ROLE = '<YOUR_EXECUTION_ROLE_ARN>'
TRAIN_INSTANCE_COUNT = 4
EVAL_INSTANCE_COUNT = 1
S3_BUCKET = '<YOUR_S3_BUCKET>'
S3_PREFIX = 'stack-overflow'
EVAL_DATA = './eval.csv'
# Load data
# Note: 'query' maps to the question, 'response' to the classification label
loader = CSVDatasetLoader(
query='Body',
# Question text column
response='Y',
# Classification label column (HQ, LQ_EDIT, LQ_CLOSE)
system='system'
# System prompt column
)
loader.load(EVAL_DATA)
接下来,我们使用 CSVDatasetLoader 将原始数据转换为 Nova 模型评估所需的格式:
# Transform to Nova format
loader.transform(method=TrainingMethod.EVALUATION, model=MODEL)
loader.show(n=3)
转换后的数据将具有以下格式:
{
"query": "<input data>",
"response": "<output data>",
"system": "<system prompt>"
}
在上传到 Amazon Simple Storage Service(Amazon S3)之前,请通过运行 loader.validate() 方法来验证转换后的数据。这有助于您及早发现任何格式问题,而不是等到它们中断实际评估时才发现。
# Validate data format
loader.validate(method=TrainingMethod.EVALUATION, model=MODEL)
最后,我们可以使用 loader.save_data() 方法将数据集保存到 Amazon S3,以便评估作业可以使用它。
# Save to S3
eval_s3_uri = loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/data/eval.jsonl"
)
运行基线评估
准备好数据后,我们初始化 SMTJRuntimeManager 来配置运行时基础设施。然后,我们初始化一个 NovaModelCustomizer 对象并调用 baseline_customizer.evaluate() 来启动基线评估作业:
# Configure runtime infrastructure
runtime_manager = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=EVAL_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create baseline evaluator
baseline_customizer = NovaModelCustomizer(
model=MODEL,
method=TrainingMethod.EVALUATION,
infra=runtime_manager,
data_s3_path=eval_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/baseline-eval"
)
# Run evaluation
# GEN_QA task provides metrics like ROUGE, BLEU, F1, and Exact Match
baseline_result = baseline_customizer.evaluate(
job_name="blogpost-baseline",
eval_task=EvaluationTask.GEN_QA
# Use GEN_QA for classification
)
对于分类任务,我们使用 GEN_QA 评估任务,它将分类视为生成任务,模型生成类标签。GEN_QA 中的 exact_match 指标直接对应于分类准确率,即预测与地面真实标签完全匹配的百分比。完整的基准任务列表可以从 EvaluationTask 枚举中检索,或者在 Amazon Nova 用户指南中找到。
理解基线结果
作业完成后,结果将保存在指定输出路径的 Amazon S3 中。该存档包含每样本的预测(带对数概率)、整个评估集的聚合指标以及原始模型预测,用于详细分析。
在下表中,我们从评估作业的输出中看到了所有评估样本的聚合指标(请注意 BLEU 的量表为 0-100):
| 指标 | 分数 |
| ROUGE-1 | 0.1580 (±0.0148) |
| ROUGE-2 | 0.0269 (±0.0066) |
| ROUGE-L | 0.1580 (±0.0148) |
| Exact Match (EM) | 0.1300 (±0.0151) |
| Quasi-EM (QEM) | 0.1300 (±0.0151) |
| F1 Score | 0.1380 (±0.0149) |
| F1 Score (Quasi) | 0.1455 (±0.0148) |
| BLEU | 0.4504 (±0.0209) |
基础模型在此 3 类分类任务上的精确匹配准确率仅为 13.0%,而随机猜测的准确率为 33.3%。这清楚地表明了微调的必要性,并为衡量改进建立了量化基线。
正如我们在下一节中所看到的,这很大程度上是由于模型忽略了问题的格式要求,其中包含解释和分析的详细响应被视为无效。我们可以通过解析模型输出文本中的三个标签来推导出与格式无关的分类准确率,使用以下 classification_accuracy 实用函数。
def classification_accuracy(samples):
"""Extract predicted class via substring match and compute accuracy."""
correct, total, no_pred = 0, 0, 0
for s in samples:
gold = s["gold"].strip().upper()
pred_raw = s["inference"][0] if isinstance(s["inference"], list) else s["inference"]
pred_cat = extract_category(pred_raw)
if pred_cat is None:
no_pred += 1
continue
total += 1
if pred_cat == gold:
correct += 1
acc = correct / total if total else 0
print(f"Classification Accuracy: {correct}/{total} ({acc*100:.1f}%)")
print(f" No valid prediction: {no_pred}/{total + no_pred}")
return acc
print("???? Baseline Classification Accuracy (extracted class labels):")
baseline_accuracy = classification_accuracy(baseline_samples)
然而,即使使用允许度量(忽略冗余性),我们也只能获得 52.2% 的分类准确率。这清楚地表明了需要进行微调来提高基础模型的性能。
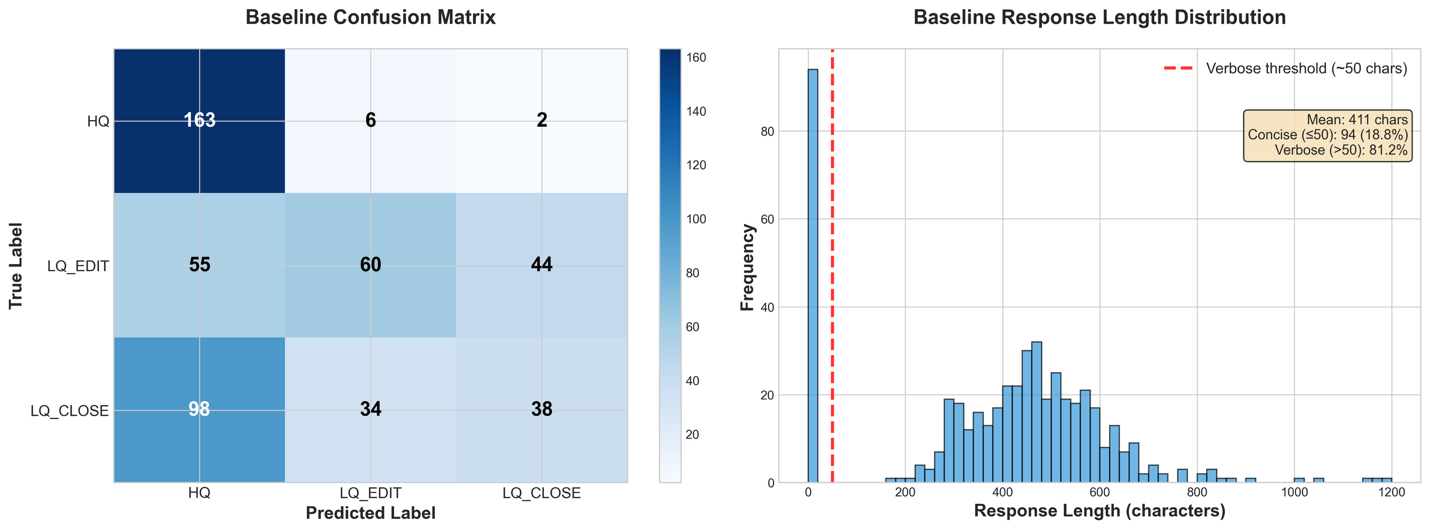
进行基线故障分析
下图显示了基线的故障分析。从响应长度分布来看,我们观察到所有响应都包含冗长的解释和推理,尽管系统提示只要求提供类别名称。此外,基线混淆矩阵比较了真实标签(y 轴)和生成的标签(x 轴);LLM 明显偏向于将消息分类为高质量,而不管其实际分类。
鉴于这些指令遵循失败和分类偏向 HQ 的基线结果,我们现在应用监督微调(SFT)来帮助模型理解任务结构和输出格式,然后进行具有惩罚不良行为的奖励函数的强化学习(RL)。
第二阶段:监督微调
现在我们已经完成了基线分析并进行了故障空间分析,我们可以使用监督微调来提高我们的性能。在本示例中,我们使用参数高效微调方法,因为它是一种能提供模型学习能力初步信号的技术。
监督微调数据准备
使用 Nova Forge SDK,我们可以导入数据集并使用 SDK 的数据准备辅助函数来整理 SFT 数据集,并进行内置数据验证。
与之前一样,我们使用 SDK 的 CSVDatasetLoader 来加载我们的训练 CSV 数据并将其转换为所需格式:
loader = CSVDatasetLoader(
question='Body',
# Stack Overflow question text
answer='Y',
# Classification label (HQ, LQ_EDIT, LQ_CLOSE)
system='system'
)
loader.load('sft.csv')
loader.transform(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
loader.show(n=3)
在此转换后,我们的数据集的每一行将以Converse API 格式进行结构化,如下所示:
{
"system": [ {"text": "<system prompt>"} ],
"messages": [
{ "role": "user", "content": [ {"text": "<input data>"} ] },
{ "role": "assistant", "content": [ {"text": "<output data>"} ] }
]
}
我们还验证数据集,以确认它符合所需的训练格式:
loader.validate(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
现在我们的数据格式正确且结构化,我们可以将其拆分为训练、验证和测试数据,并将这三者上传到 Amazon S3 以供我们的训练作业引用。
# Save to S3
train_path = loader.save_data(f"s3://{S3_BUCKET}/{S3_PREFIX}/data/train.jsonl")启动监督微调作业
在数据准备好并上传到 Amazon S3 后,我们启动监督微调(SFT)作业。
Nova Forge SDK 通过帮助我们指定训练基础设施(无论是 Amazon SageMaker Training Jobs 还是 Amazon SageMaker Hyperpod)来简化此过程。它还可以配置必要的实例并促进训练作业的启动,从而无需担心配方配置或 API 格式。
对于我们的 SFT 训练,我们继续使用 Amazon SageMaker Training Jobs,配备 4 个 ml.p5.48xlarge 实例。SDK 在尝试启动训练作业时,会根据所选模型的支持值验证您的环境和实例配置,从而防止在提交作业后出现错误。
runtime = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=TRAIN_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
接下来,我们设置训练本身的配置并运行作业。您可以使用 overrides 参数来修改训练配置的默认值以获得更好的性能。在此,我们将 max_steps 设置为相对较小的数字,以缩短此测试的持续时间。
customizer = NovaModelCustomizer(
model=MODEL,
method=TrainingMethod.SFT_LORA,
infra=runtime,
data_s3_path=train_path,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/sft-output"
)
training_config = {
"lr": 5e-6,
# Learning rate
"warmup_steps": 17,
# Gradual LR ramp-up
"max_steps": 100,
# Total training steps
"global_batch_size": 64,
# Samples per gradient update
"max_length": 8192,
# Maximum sequence length in tokens
}
result = customizer.train(
job_name="blogpost-sft",
overrides=training_config
)
您可以使用 Nova Forge SDK 以 dry_run 模式运行训练作业。此模式会执行 SDK 将执行的所有验证,同时实际运行作业,但如果所有验证都失败,则不会启动执行。这有助于您在尝试使用训练设置之前,提前了解该设置是否有效,例如在自动生成配置或探索可能的设置时:
result = customizer.train(
job_name="blogpost-sft",
overrides=training_config,
dry_run=True
)
现在我们已经确认 dry_run 成功,我们可以继续启动作业:
result = customizer.train(
job_name="blogpost-sft",
overrides=training_config
)
保存和加载作业
要保存您创建的作业数据,您可以将结果对象序列化到 JSON 文件,然后稍后检索它以继续进行:
# Save to a file
result.dump(file_path=".", file_name="training_result.json")
# Load from a file
result = TrainingResult.load("training_result.json")
SFT 启动后监控日志
启动 SFT 作业后,我们可以监控它发布到 Amazon CloudWatch 的日志。日志显示了每个步骤的指标,包括损失、学习率和吞吐量,让您可以实时跟踪收敛情况。
Nova Forge SDK 内置了便捷的实用程序,可直接在您的笔记本环境中的每个平台类型轻松提取和显示日志。
monitor = CloudWatchLogMonitor.from_job_result(result)
monitor.show_logs(limit=50)
您还可以直接从 customizer 对象请求日志,它会智能地为它创建的最新作业检索这些日志:
customizer.get_logs(limit=20)
此外,您可以实时跟踪作业状态,这对于跟踪作业何时成功或失败非常有用:
result.get_job_status()
# Returns (JobStatus.IN_PROGRESS, ...) or (JobStatus.COMPLETED, ...)
评估 SFT 模型
训练完成后,我们可以在与基线评估相同的数据集上评估微调后的模型,以了解与基线相比的改进程度。Nova Forge SDK 支持在训练作业生成模型上运行评估。以下示例演示了这一点:
# Configure runtime infrastructure
runtime_manager = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=EVAL_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create baseline evaluator
baseline_customizer = NovaModelCustomizer(
model=MODEL,
method=TrainingMethod.EVALUATION,
infra=runtime_manager,
data_s3_path=eval_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/sft-eval"
)
# Run evaluation
baseline_result = baseline_customizer.evaluate(
job_name="blogpost-eval",
eval_task=EvaluationTask.GEN_QA,
job_result=result,
# Automatically derives checkpoint path from training result
)
SFT 后评估结果
下表中,我们看到了应用 SFT 训练后,同一评估数据集的聚合指标:
| 指标 | 分数 | 增量 |
| ROUGE-1 | 0.8290 (±0.0157) | 0.671 |
| ROUGE-2 | 0.4860 (±0.0224) | 0.4591 |
| ROUGE-L | 0.8290 (±0.0157) | 0.671 |
| Exact Match (EM) | 0.7720 (±0.0188) | 0.642 |
| Quasi-EM (QEM) | 0.7900 (±0.0182) | 0.66 |
| F1 Score | 0.7720 (±0.0188) | 0.634 |
| F1 Score (Quasi) | 0.7900 (±0.0182) | 0.6445 |
| BLEU | 0.0000 (±0.1031) | -0.4504 |
即使在短暂的训练运行中,我们也看到了所有指标(BLEU 除外,BLEU 对极短的响应给出低分)的改进,精确匹配指标的准确率高达 77.2%。
print("Post-SFT Classification Accuracy (extracted class labels):")
sft_accuracy = classification_accuracy(sft_samples)
通过检查我们自己的分类准确率指标,我们可以看到 79.0% 的评估数据点获得了正确的分类。分类准确率和精确匹配分数之间的小差异表明模型已正确学习了所需的格式。
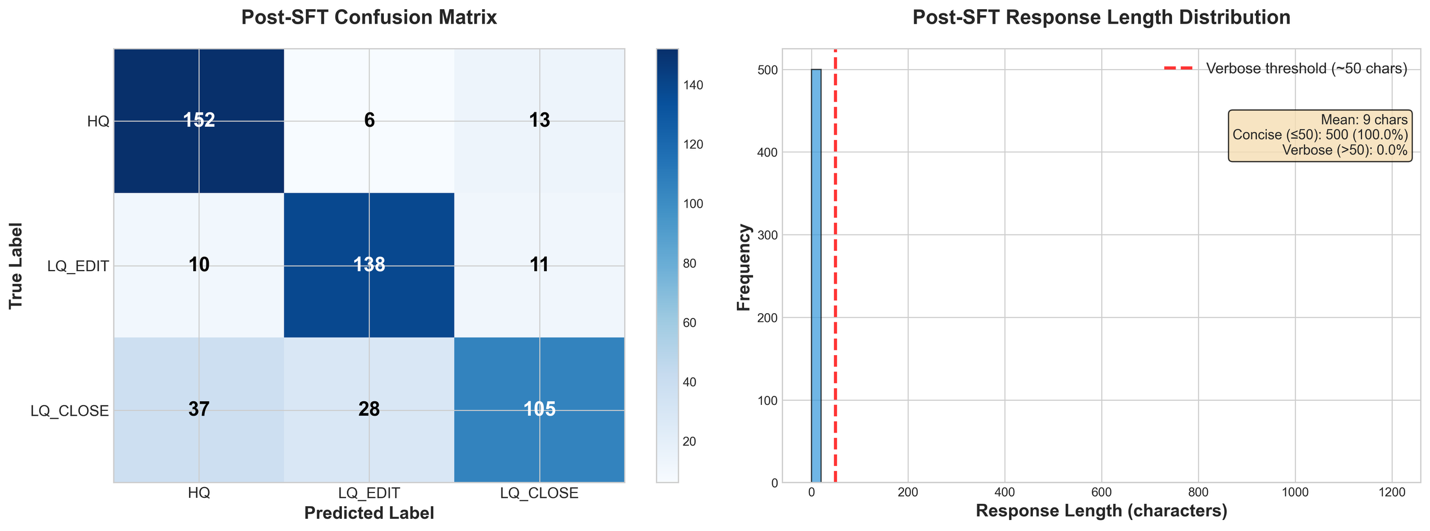
从详细的性能指标来看,我们可以看到响应长度分布已完全趋向于非冗余响应。在混淆矩阵中,我们还看到 LQ_EDIT 和 LQ_CLOSE 类别的分类准确率急剧提高,减少了模型对将行分类为 HQ 的偏见。
第三步:强化微调
根据之前的数据,SFT 在训练模型以适应所需格式方面做得很好,但在生成标签的准确性方面仍有改进空间。接下来,我们尝试在已训练的 SFT 检查点之上迭代地添加强化微调。这通常在尝试提高模型准确性时非常有用,尤其是在涉及比适应所需格式更复杂用例的情况下,并且任务可以被量化为可衡量的奖励。
构建奖励函数
对于分类,我们创建一个 AWS Lambda 函数,该函数通过正分数(+1)奖励正确预测,通过负分数(-1)奖励错误预测:
- 1.0:正确预测
- -1.0:错误预测
该函数处理三个质量类别(HQ、LQ_EDIT、LQ_CLOSE),并使用灵活的文本提取来处理模型输出中的细微格式差异(例如,“HQ”、“HQ.”、“答案是 HQ”)。这种强大的提取确保模型即使在生成略有冗余的响应时也能收到准确的奖励信号。二元奖励结构创建了强大、明确的梯度,有助于模型学会区分高质量和低质量内容类别。
"""Binary reward function for classification: +1 correct, -1 wrong.
Simple and clear signal:
- Correct prediction: +1.0
- Wrong prediction: -1.0
"""
def calculate_reward(prediction: str, ground_truth: str) -> float:
""" Calculates binary reward """
extracted = extract_category(prediction)
# Extracts category from prediction and normalize it
truth_norm = normalize_text(ground_truth)
# Normalize the groundtruth
# Correct prediction
if extracted and extracted == truth_norm:
return 1.0
# Wrong prediction
return -1.0
def lambda_handler(event, context):
""" Lambda handler with binary rewards. """
scores: List[RewardOutput] = []
for sample in event:
idx = sample.get("id", "no_id")
ground_truth = sample.get("reference_answer", "")
prediction = last_message.get("content", "")
# Calculate binary reward
reward = calculate_reward(prediction, ground_truth)
scores.append(RewardOutput(id=idx, aggregate_reward_score=reward))
return [asdict(score) for score in scores]
将此 Lambda 函数部署到 AWS,并记下 ARN 以在 RFT 训练配置中使用。
接下来,我们将 Lambda 函数部署到 AWS 账户,并获取已部署的 Lambda ARN,以便在启动 RFT 训练时使用。
确保将 Lambda Invoke 策略添加到您的定制化 IAM 角色,以便 Amazon SageMaker AI 可以在训练开始后调用 Lambda 策略。
RFT 数据准备
与 SFT 实验设置类似,我们可以使用 Nova Forge SDK 来整理数据集并对 RFT 架构执行验证。这有助于导入数据集并将其转换为适用于 RFT 的 OpenAI 架构。以下代码片段展示了如何将数据集转换为 RFT 数据集。
RFT_DATA = './rft.csv'
rft_loader = CSVDatasetLoader(
query='Body',
response='Y',
system='system'
)
rft_loader.load(RFT_DATA)
# Transform for RFT
rft_loader.transform(method=TrainingMethod.RFT_LORA, model=MODEL)
rft_loader.validate(method=TrainingMethod.RFT_LORA, model=MODEL)
# Save to S3
rft_s3_uri = rft_loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/data/rft.jsonl"
)
此转换后,您将获得以下OpenAI 格式的数据:
{
"system": [ { "text": "<system prompt>" } ],
"messages": [
{ "role": "user", "content": [ { "text": "<input data>" } ] }
],
"reference_answer": "<reference answer>"
#any other metadata field you use in data loader mapping
}
在 SFT 检查点上启动 RFT 和监控日志
接下来,我们将在 SFT 检查点之上初始化 RFT 作业本身。在此步骤中,Nova Forge SDK 通过提供格式化数据集和要使用的奖励函数来帮助您启动 RFT 作业。以下代码片段展示了如何在 SFT 检查点之上运行 RFT,使用 RFT 数据和奖励函数。
REWARD_LAMBDA_ARN = "arn:aws:lambda:us-east-1:ACCOUNT:function:classification-reward"
# Configure RFT infrastructure
RFT_INSTANCE_COUNT = 2
rft_runtime = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=RFT_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create RFT customizer
rft_customizer = NovaModelCustomizer(
model=MODEL,
method=TrainingMethod.RFT_LORA,
infra=rft_runtime,
data_s3_path=rft_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/rft-output",
model_path=sft_checkpoint
# Start from SFT checkpoint
)
我们使用以下超参数 f... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区