



📢 转载信息
原文作者:Paul Burchard, Igor Halperin, Amin Dashti, and Mona Mona
本文由 Artificial Genius 的 Paul Burchard 和 Igor Halperin 联合撰写。
大型语言模型(LLM)的普及给金融服务和医疗保健等高度监管的行业带来了巨大的悖论。这些模型处理复杂、非结构化信息的能力为分析、合规和风险管理提供了变革性的潜力。然而,它们固有的概率性会导致幻觉,即看似合理但事实上不正确的信息。
在对审计性和准确性有严格要求的行业中,标准生成式 AI 的非确定性行为阻碍了其在任务关键型系统中的应用。对于银行或医院而言,确定性不仅仅是一个目标;结果必须是准确、相关且可重现的。
在本篇文章中,我们很高兴展示 AWS ISV 合作伙伴 Artificial Genius 如何利用 Amazon SageMaker AI 和 Amazon Nova 来解决这一挑战。通过引入第三代语言模型,它们提供了一种输入具有概率性但输出具有确定性的解决方案,从而能够安全地进行企业级应用。
为了理解这个解决方案,让我们回顾一下 AI 的演变:
- 第一代(20 世纪 50 年代):研究人员使用符号逻辑构建确定性的、基于规则的模型。虽然安全,但这些模型缺乏流畅性且无法扩展。
- 第二代(20 世纪 80 年代至今):转向概率模型(最终发展为 Transformer 架构)释放了惊人的流畅性。然而,由于这些模型是根据概率预测下一个 token,因此它们会产生难以消除的、无界限的故障模式(幻觉)。
- 第三代(Artificial Genius 的方法):我们并非引入一个取代旧代的新一代模型,而是从符号逻辑的僵化和概率模型的不确定性,转向一种混合架构。这种方法利用 Amazon Nova 的生成能力来理解上下文,但应用了一个确定性层来验证和产生输出。这是流畅性和事实性的融合。
解决方案:一种矛盾的生成方法
从数学上讲,要阻止标准生成模型产生幻觉是困难的,因为外推和生成过程本身就会导致错误。Artificial Genius 通过严格地非生成性地使用模型来解决这个问题。在这种范式中,模型学到的海量概率信息仅用于输入的插值。这使得模型能够理解信息或问题表达的无数种方式,而无需依赖概率来生成答案。为了实现这种第三代能力,Artificial Genius 使用 SageMaker AI 对 Amazon Nova 基础模型进行特定形式的指令微调。
这种专利方法有效地消除了输出的概率。虽然标准解决方案试图通过将温度降至零来确保确定性(但这通常无法解决核心的幻觉问题),但 Artificial Genius 对模型进行了后期训练,将下一个 token 预测的对数概率推向绝对值或零。这种微调迫使模型遵循一个单一的系统指令:不要编造不存在的答案。
这创造了一个数学上的“漏洞”,使得模型在保留其天才般的数据理解能力的同时,又能以金融和医疗领域所需的安全配置文件运行。
超越 RAG
检索增强生成(RAG)经常被认为是解决准确性问题的方案,但它仍然是一个生成过程,并且会创建可能与后续查询无关的固定向量嵌入。第三代方法通过有效地将输入文本和用户查询嵌入到统一的嵌入中,从而改进了 RAG。这有助于确保数据处理与所提出的特定问题本质上相关,从而提供比标准向量检索方法更高的保真度和相关性。
通过代理工作流实现价值
为了帮助企业最大化其非结构化数据的价值,Artificial Genius 将此模型打包成一个行业标准的代理客户端-服务器平台,可在 AWS Marketplace 上获得。
与第二代代理不同,后者在工作流中串联时有复合错误的风险,这种第三代模型固有的可靠性允许进行复杂、高保真的自动化。用于创建这些工作流的提示遵循产品需求文档(PRD)的结构。通过这种结构,领域专家(可能不是 AI 工程师)可以以自然语言制定查询,同时保持对输出的严格控制。
该产品还提供工作流规范的自由格式提示。为此,使用了 Amazon Nova Premier 模型,该模型特别擅长将自由格式提示转换为 PRD 格式。尽管 Nova Premier 是一个生成模型,需要人工介入检查其输出,但这仍然是代理工作流中唯一的人工检查点。
定义非生成性查询
这里采用的核心数学“漏洞”是将生成模型严格地用于非生成性目的。这意味着模型不使用概率来猜测答案的下一个 token,而是完全基于输入上下文来提取或验证信息。虽然简短的答案(如日期或名称)显然是非生成性的,但也可以确定性地输出长序列。例如,要求引用文档中的直接引述来证明之前的答案是一个非生成性任务。以下是 Artificial Genius 构建这些交互的示例(包含抗幻觉指令的系统提示未在此类 JSON 对话中显示):
可回答的、非生成性的简短答案:
[
{
"role": "user",
"content": [{"text": "Document: Financial performance remained strong through the third quarter. Our revenue grew by 15% year-over-year... Question: What was the annual revenue growth? Answer:"}],
},
{
"role": "assistant",
"content": [{"text": "15%"}]
}
]
可回答的、非生成性的、长答案的后续问题
[
{
“role”: “user”,
“content”: [{"text": "Document: Financial performance remained strong through the third quarter. Our revenue grew by 15% year-over-year, driven by robust sales in the enterprise segment. Question: Provide a quote from the document showing that the annual revenue growth was 15%. Answer:”}],
},
{
“role”: “assistant”,
“content: [{"text": ‘”Our revenue grew by 15% year-over-year, driven by robust sales in the enterprise segment.’’}],
}
]
JSON
// Example of an unanswerable, short-answer question
[
{
“role”: “user”,
“content”: [{"text": "Document: Financial performance remained strong through the third quarter. Our revenue grew by 15% year-over-year, driven by robust sales in the enterprise segment. Question: What was the CEO’s bonus this year? Answer:”}],
},
{
“role”: “assistant”,
“content: [{"text": “Unknown”}],
}
]
这些只是示例性的说明。第三代语言模型产品将附带“食谱”,以帮助理解如何构建非生成性查询,以满足所有实际的自然语言处理需求。有了这些理解,让我们来探讨使用 Amazon Nova 在 SageMaker AI 上构建非生成性微调管道的技术实现。
AWS 参考架构
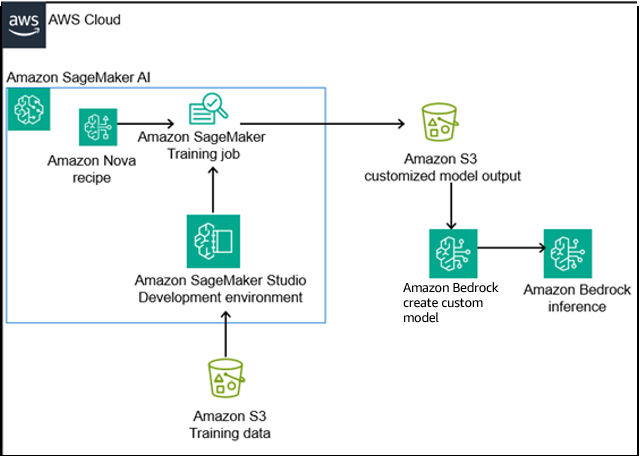
上述图示的架构使用一种简化的方法来定制基础模型。它使用 SageMaker Training jobs 进行模型训练,并使用 Amazon Bedrock 进行部署。
- 数据存储:训练数据(合成问答)存储在 Amazon Simple Storage Service (Amazon S3) 中。
- 训练:SageMaker Training jobs 预配计算资源,使用监督微调(SFT)方法的指令微调 Nova 基础模型。
- 部署:通过 create custom model feature 将微调后的模型导入 Amazon Bedrock。
- 推理:应用程序通过 Amazon Bedrock 端点与模型交互,利用 Amazon Bedrock 的按需推理功能创建自定义模型,有助于确保安全、可扩展的循环。
此设计将开发关注点与生产推理分开,同时保持清晰的数据谱系——这对于金融服务的审计追踪至关重要。
技术实现:非生成性微调的分步指南
如前所述,构建第三代语言模型涉及以下步骤:
- 从第二代基础模型开始。第一个任务是选择一个好的基础模型。正如您将看到的,Amazon Nova 系列包含作为此基础的理想候选模型。
- 基础模型必须经过后期训练,以遵循单一系统指令:不要编造答案。当然,很多人以前都尝试过,但现在我们从数学上理解,这仅对非生成性问题是可能的。因此,在实践层面上理解哪些类型的问题是生成性的,哪些是非生成性的,这一点很重要。
- 由于后期训练赋予了语言模型通用能力,其成功在很大程度上取决于构建高质量、高度多样化的数据集,以充分发挥这种通用能力。Artificial Genius 生产了一种专有的合成、非生成性问答生成器,它将成为企业客户定制任何第三代语言模型的基石。
- 最后,SageMaker AI 提供了一个成本效益高且功能强大的后期训练平台,能够高效地生产最终模型,这一点将在后面详细探讨。
选择合适的 foundation model
在构建第三代语言模型时,我们希望关注可靠性和安全性。一些为不同用例构建的基础模型具有分散注意力且不适合非生成性用途的其他功能。
一个重要的例子是,一些基础模型被优化为用作聊天助手,这使得说服它们提供简洁而不是冗长和 discursive 的答案变得困难。纠正这种倾向可能需要额外的后期训练,而不仅仅是遵循非幻觉指令。Amazon Nova 系列模型在性能、成本效益和速度方面取得了良好平衡,是企业应用的理想选择,而在 Nova 系列中,Nova Lite 模型自然倾向于提供清晰简洁的答案。因此,Nova Lite 是此目的的理想基础模型。
另一个相关的最新进展是为第二代语言模型添加了推理后功能,通常基于思维链(CoT)或强化学习方法。这些功能虽然有用,但会干扰创建非生成性第三代模型的过程。例如,在将此方法应用于 DeepSeek/Llama3 模型(包括思维链)时,有必要通过在训练数据中直接包含模型的内部</think> token 来进行提示注入,以关闭这些额外功能。幸运的是,Amazon Nova Lite 没有任何推理后功能。
设计后期训练指令遵循任务
然后可以对基础模型应用后期训练(如 SFT),以训练它遵循包含在系统提示中的抗幻觉指令。例如,此指令可以是:如果文档无法回答问题,则回答“未知”。
如果这听起来很明显——它已经被尝试了很多次——请记住,这个看似显而易见的想法只有在与非直观、反直觉的数学原理相结合时才有效,即以严格非生成性的方式使用生成模型。
构建高质量、抗幻觉的后期训练数据
Artificial Genius 创建了一个专有的合成、非生成性问答生成器,旨在训练模型正确回答或拒绝回答各种非生成性问题的能力。Artificial Genius 的合成问答生成器建立在先前关于为金融领域合成生成问答的研究之上,但它侧重于生成最多样化的纯粹非生成性问答,并成倍地扩展了输入文本、问题和答案的多样性维度。为这项任务构建合适的合成问答生成器是一项重大的工程任务。但是,以 Artificial Genius 的合成问答生成器为基础,可以将特定于客户的后期训练任务与其相结合,以创建定制的第三代语言模型。
克服推理后的 CoT
思维链(CoT)是一种提示技术,通过鼓励模型在得出最终答案之前生成中间的、逐步的推理过程来提高 LLM 在复杂推理任务上的性能。虽然通常有益,但我们发现初始 deepseek-ai/DeepSeek-R1-Distill-Llama-8B 模型中固有的 CoT 行为适得其反。它产生了冗长、非确定性的推理步骤,而不是所需的简洁、事实性的输出,并且导致模型尝试冗长的推理来回答每个问题,即使是那些无法回答的问题。为了解决这个问题,团队开发了一种新颖的提示元注入技术。该方法涉及重新格式化训练数据,以抢先终止模型的 CoT 过程。使用与前面示例相同的 JSON 格式,数据结构如下:
// Example of prompt injection to circumvent CoT
[ { "role": "user", "content": [{"text": "Document: Financial performance remained strong through the third quarter. Our revenue grew by 15% year-over-year, driven by robust sales in the enterprise segment. Question: What was the annual revenue growth? Answer: </think>"}], }, { "role": "assistant", "content: [{"text": "15%"}], }
]
通过在每个训练示例的地面真相答案之前注入仅供模型内部使用的</think> token,模型学会了将内部过程的完成与最终正确输出的开始关联起来。这有效地绕过了推理时不需要的冗长推理,迫使模型只产生所需的确定性答案。
这项技术是利用数据格式作为控制和塑造模型内在行为的工具的一个强大示例。
对 Amazon Nova 进行微调以实现最佳性能
为非幻觉任务选择的 SFT 技术是低秩自适应(LoRA),因为它最忠实地保留了基础模型的语言理解能力,只是在其之上放置了一个参数化适配器。其他微调方法直接更改基础模型的参数,有损害此能力的风险。正如 SFT 的研究文献中所广为人知,要克服的最大障碍是避免过拟合。有许多技术可以避免 LoRA 的 SFT 过拟合,这些技术得到了 SageMaker AI 中提供的微调“食谱”的支持:
- 正则化:这是防止过拟合最通用的方法。SageMaker 的 LoRA SFT“食谱”支持一种正则化方法:LoRA dropout。研究文献表明,最佳值为 50% dropout,实验证实了该值的最优性。
- 参数减少:这是一种避免过拟合的粗暴方法,但有冒着欠拟合的风险。SageMaker 的 LoRA SFT“食谱”支持一种参数减少方法,通过减少 LoRA
alpha参数来减少 LoRA rank。在这种情况下,减少此参数没有帮助,因为它会导致更多欠拟合而不是减少过拟合。因为我们的目标是创建一个通用能力,所以最好尽可能保持原始参数数量,而不是减少它。 - 提前停止:通常,训练最初会改善验证错误,但在某些步骤后,它会开始过拟合,训练错误会下降,但验证错误会再次上升。尽管 SageMaker AI 不支持自动提前停止,但您可以通过在较长的、过拟合的训练运行中检查验证错误的进程,然后手动将 epoch 数量限制在验证错误最小化的点来手动执行此操作。这可以使用 SageMaker AI 返回的每个 epoch 的验证错误时间序列来完成。
- 增加训练数据的数量和多样性:因为目标是训练一种通用能力,即避免幻觉,所以训练数据的数量和多样性越大,模型过拟合其所训练的特定数据的机会就越小。因为训练数据是合成生成的,所以可以根据需要生成组合的(即指数级的)不同的训练示例。对于这个通用任务,这是最有效的方法,但需要仔细构建合成数据生成器,以帮助确保能够扩展到足够的数量和多样性的训练数据。
将所有这些技术结合起来——50% LoRA dropout 正则化,最大化而不是最小化 LoRA 参数数量以避免无意欠拟合,基于较长运行的验证指标跟踪进行手动提前停止,以及将合成训练数据集增加到 30,000 个示例——我们可以获得 Artificial Genius 定制的 Nova Lite 版本 0.03% 的幻觉率。
为了帮助您了解各种超参数选择的影响,这可能对其他使用 SageMaker 进行微调的客户有所帮助,下表显示了在此任务中探索超参数空间时的一些定量结果。在每种情况下,重要的超参数选择都以粗体突出显示。在其他情况(因停止过晚而导致过拟合)下,仅显示验证错误检查点。其余情况使用与训练示例数量无关的相同 10,000 个示例测试数据集来衡量实际最终幻觉率。
| LoRA dropout | LoRA alpha | Training epochs (or validation checkpoints) | Training examples | LoRA learning rate | Hallucination rate (or validation errors) |
| 50% | 128 | 3 | 10,000 | 32 | 7.5% |
| 50% | 192 | 2–4 | 10,000 | 28 | 1.0%–3.9% |
| 50% | 32 | 2–4 | 10,000 | 24 | 1.5%–2.6% |
| 1% | 32 | 2–4 | 10,000 | 24 | 1.6%–4.0% |
| 50% | 192 | 2 | 2,500 | 28 | 3.3% |
| 50% | 192 | 2 | 10,000 | 28 | 0.17% |
| 50% | 192 | 2 | 30,000 | 16 | 0.03% |
从这些经验结果可以看出,训练数据的数量和多样性是克服过拟合最重要因素,再加上提前停止。
如何在 SageMaker 上设置和运行微调作业
AWS 提供了有关如何利用 SageMaker 进行微调的资源,例如技术博客文章 Advanced fine-tuning methods on Amazon SageMaker AI。
对于有兴趣将其领域特定微调与 Artificial Genius 的抗幻觉技术相结合的企业,可以与 AWS 和 Artificial Genius 合作,通过咨询提供定制微调服务。
性能和可验证性的定量分析
非生成性微调方法论的成功通过了一个严格的评估框架得到了验证,该框架产生了清晰的定量结果。
评估框架
建立了一个多方面评估框架来衡量性能是否达到项目核心目标:
- 幻觉减少:这是主要指标,通过在模型对一组无法回答的问题进行测试时,衡量包含虚假信息的响应百分比来量化。
- 复杂推理能力:评估模型在正确回答或拒绝回答各种非生成性问题方面的性能,包括需要理解和组合输入文本中多个、遥远部分的信息的复杂问题。
- 受监管环境指标:幻觉率清晰明了,易于计算——它是被回答为非指令性答案以外的内容的不可回答问题的百分比。如果需要,此幻觉率可以解释为 F1 或 ROUGE 分数。
经验教训与见解
以下是为在受监管环境中实施可信 AI 而提供的几项关键见解和最佳实践:
- 数据工程至关重要:高度专业化的微调的成功在很大程度上取决于训练数据的质量和智能设计,以防止过拟合。战略性地包含负面示例(不可回答的问题)是减轻幻觉的关键且非常有效的方法。
- 平衡能力与控制:对于企业 AI,主要目标通常是智能地约束模型的巨大能力,以确保可靠性,而不是释放其全部生成潜力。确定性和可审计性是需要工程实现的特性,而不是理所当然的。
- 采用迭代方法:应用机器学习开发是一个迭代过程。团队从一个模型开始,识别出一个行为缺陷(不需要的 CoT),设计了一个以数据为中心的解决方案(元注入),并最终基准测试并选择了一个更好的基础模型(Amazon Nova)。这突显了在开发每个阶段保持灵活性和进行经验验证的必要性。
结论:金融领域可信 AI 的前进之路
本文详细介绍的方法代表了一种可行、数据高效的框架,用于为关键的企业任务创建确定性的、非幻觉的 LLM。通过在 Amazon SageMaker Training Jobs 中使用强大的基础模型(如 Amazon Nova)进行非生成性微调,组织可以构建满足准确性、可审计性和可靠性严格要求的 AI 系统。这项工作不仅为金融服务提供了解决方案;它为任何受监管的行业(包括法律、医疗保健和保险)提供了一个可转移的蓝图,在这些行业中,AI 驱动的见解必须是可验证的真实且完全可追溯的。前进的道路包括将此解决方案扩展到更广泛的用例,探索更复杂的非生成性任务类型,并研究模型蒸馏等技术,以创建高度优化的、成本效益高的工作模型,作为代理工作负载的大脑。通过优先考虑工程化的信任而不是不受约束的生成,这种方法为 AI 在全球最关键部门的负责任和有影响力的应用铺平了道路。
贡献:特别感谢 Ilan Gleiser,他是 AWS WWSO Frameworks 团队的首席 GenAI 专家,帮助我们完成了这个用例。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区