




📢 转载信息
原文链接:https://www.qbitai.com/2025/10/339267.html
原文作者:量子位
多模态大模型(MLLM)的应用场景正在不断扩展,已经从最初的文生图,扩展到了**像素级任务**,例如图像分割。
然而,现有的方法(如OMG-LLaVA、LISA)在执行这些任务时,仍然面临两大痛点:**分割结果不够精确**和**理解过程中出现幻觉**。这主要是由于模型在物体属性理解和细粒度感知能力上的不足。
为了解决这些问题,来自**华中科技大学团队**与**金山办公团队**合作,推出了一个创新的多模态大模型框架——**LIRA**。
LIRA框架:两大核心模块实现SOTA
LIRA框架的核心在于引入了两个关键模块:
- **语义增强特征提取器(SEFE)**:该模块融合了语义特征与像素级特征,有效提升了模型对物体属性的推理能力,从而生成更精确的分割结果。
- **交错局部视觉耦合模块(ILVC)**:该模块基于分割掩码提取局部特征,并自回归生成局部描述,为模型提供细粒度监督,显著减少理解幻觉。
通过这两个模块的协同作用,LIRA在**图像分割**和**多模态理解**两项任务上均取得了当前的最佳性能(SOTA)。

与InternVL2相比,LIRA在保持理解性能的同时,额外支持图像分割任务;与OMG-LLaVA相比,LIRA在图像分割任务上平均提升了8.5%,在MMBench基准测试中提升了33.2%。该研究成果已被ICCV 2025接收。
现有方法的局限性分析
多模态大模型通过结合分割模块,已经将能力拓展到了像素级分割。LISA提出了“embedding-as-mask”范式,而OMG-LLaVA则采用通用分割模型作为视觉编码器。
然而,在复杂场景下,这些方法仍常常无法准确分割目标。研究发现,现有模型在生成的Token Embedding中可能包含了与原始图像无关的语义信息,例如,可能错误地偏向于“左侧”的描述,即使目标在右侧。
此外,传统方法依赖位置查询来指示目标,但往往无法在**局部图像特征**与**对应文本描述**之间建立明确的联系,容易导致幻觉。
LIRA:精确的“推理分割”
LIRA的设计思路是直接将局部图像特征输入文本大模型,让模型基于该区域生成描述,从而建立更明确的视觉特征与语义映射。

LIRA能够准确地将复杂的查询(如“离白色汽车最近的红色巴士”)解释为指向正确的对象,并实现精确分割。研究团队称之为“Inferring Segmentation”(推理分割)。
SEFE:增强模型属性理解
语义增强特征提取器(SEFE)融合了来自预训练MLLM的语义编码器和分割模型的像素编码器。通过MLP将特征统一维度后,利用多头交叉注意力机制融合语义与像素特征,最终拼接成全局特征输入LLM。



ILVC:实现局部区域与描述的耦合
交错局部视觉耦合模块(ILVC)受人类感知的启发:先关注区域,再进行描述。LIRA利用Token生成分割掩码,裁剪出对应区域,通过SEFE提取局部特征,再将这些特征输入LLM以生成该区域的描述。

这种交错的训练范式,成功建立了局部图像区域与文本描述的显式联系,为局部特征提供了细粒度监督,有效缓解了幻觉问题。
实验结果:全面超越
实验结果表明,LIRA在理解和分割任务上均表现出色:

- **SEFE的有效性**:在InternLM2-1.8B骨干网络上,整合SEFE使理解任务平均提升5.7%,分割任务提升3.8%。
- **ILVC的贡献**:整合ILVC后,在ChairS数据集上,1.8B和7B模型的幻觉率分别降低了3.0%和4.8%。
- **联合训练优势**:LIRA同时使用理解和分割数据联合训练时,性能仅比单独使用理解数据训练下降0.2%,但优于OMG-LLaVA在五个理解数据集上近15%的性能下降。


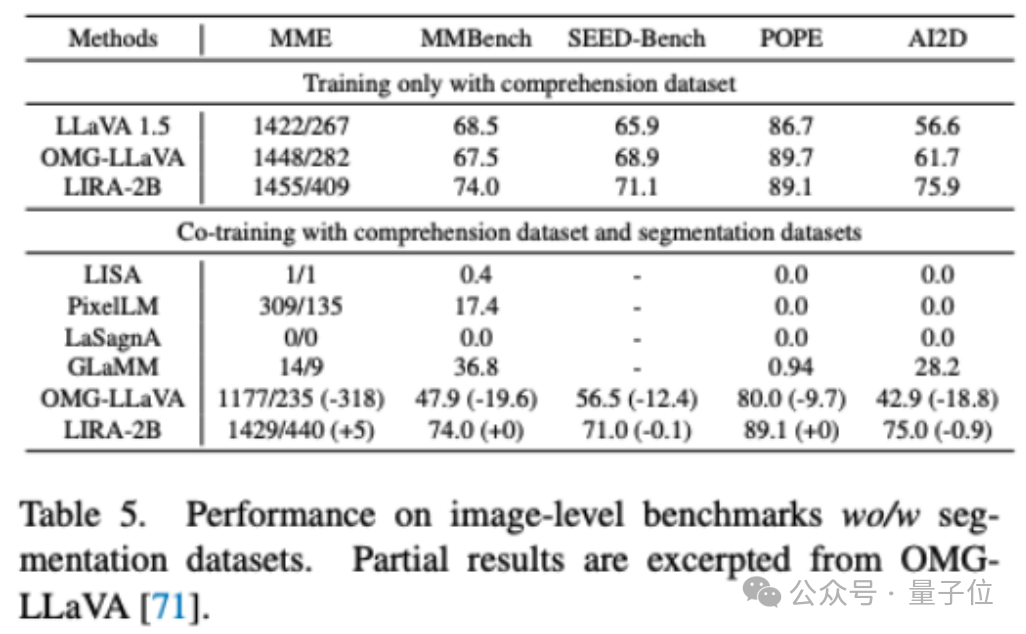
总而言之,LIRA通过SEFE和ILVC两大模块,成功实现了多模态大模型在理解与分割任务上的性能协同提升,并开创了缓解细粒度多模态大模型幻觉的新视角,为未来的研究提供了重要启示。
项目链接:
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
评论区