




📢 转载信息
原文链接:https://www.qbitai.com/2025/10/339267.html
原文作者:量子位
多模态模型迈入像素级任务:分割与理解的挑战与机遇
多模态大模型的能力边界正在不断拓展,已从最初的文本到图像生成,延伸至更精细的像素级任务,如图像分割。
然而,现有方法,如OMG-LLaVA或基于“embedding-as-mask”范式的LISA(CVPR 2024),在实际应用中暴露出两大核心痛点:**分割结果不够精确**和**理解过程中出现幻觉**。这主要归因于模型在物体属性理解上的不足和细粒度感知能力的局限。

为解决这些挑战,华中科技大学团队联合金山办公团队,提出了创新的多模态大模型 **LIRA**,它在分割和理解两项任务上均达到了当前最佳(SOTA)水平。
LIRA模型:两大核心模块加持
LIRA框架构建在两个关键模块之上:
- 语义增强特征提取器(SEFE): 该模块巧妙地融合了高层的语义特征和细粒度的像素级特征,极大地提升了模型对物体属性的推理能力,从而生成更精确的分割结果。
- 交错局部视觉耦合(ILVC): 该机制基于分割掩码提取局部特征,并自回归生成局部描述。它为模型提供了细粒度的监督信号,有效减少了理解过程中的“幻觉”现象。
与InternVL2相比,LIRA在保持优秀理解性能的同时,还支持了图像分割任务;与OMG-LLaVA相比,LIRA在图像分割任务上平均提升了8.5%,在MMBench基准测试中提升了33.2%。该研究成果已获得ICCV 2025的录用。
现有分割方法的局限性分析
多模态大模型通过集成分割模块,能力已拓展至像素级分割。但复杂场景下的分割错误依然常见。

研究人员分析发现,现有模型(如OMG-LLaVA)在处理如“最靠近白色汽车的红色公交车”这类查询时,可能会出现分割错误。通过分析生成的token embedding,团队发现这些token可能携带了与原图无关的语义信息,例如高估了与“left”相关的logits,导致错误地分割了左侧公交车。
这表明现有模型在token中未能有效编码准确的位置信息,视觉理解能力存在局限。此外,依赖位置查询进行目标指示的方法,难以在局部图像特征与对应文本描述之间建立明确的联系,更容易引发理解幻觉。
LIRA如何实现精确分割与理解的统一?
LIRA模型试图解决“是否应该将局部图像特征直接输入文本大模型,让模型基于该区域生成描述”这一问题,从而在视觉特征与语义之间建立更明确的映射。

LIRA通过“Inferring Segmentation”过程,能够准确理解诸如“离白色汽车最近的红色巴士”这类查询,并指向正确的区域进行分割。这得益于SEFE增强了属性理解,以及ILVC通过显式绑定局部区域与文本描述,提供了更细粒度的监督。
深入剖析核心模块
1. 语义增强特征提取器(SEFE)
SEFE模块整合了来自预训练多模态大模型的语义编码器和分割模型的像素编码器。通过MLP将两者特征转换到相同维度后,利用多头交叉注意力机制进行特征融合。



2. 交错局部视觉耦合模块(ILVC)
ILVC模块受到人类先关注区域再描述的启发,旨在明确关联局部图像区域与其对应的文本描述。

具体操作是:利用token生成分割掩码,裁剪出对应图像区域,送入SEFE提取局部特征。这些特征随后被送回文本大模型,用于生成该区域的描述。这种交错的训练范式建立了局部视觉特征与文本描述的显式联系,有效引入了细粒度监督,缓解了幻觉。
实验验证:性能全面超越
实验结果表明,LIRA在多个理解和分割数据集上展现出优异的综合性能。

SEFE的有效性验证: 基于InternLM2-1.8B骨干网络时,整合SEFE使理解任务平均提升5.7%,分割任务提升3.8%。

ILVC的缓解幻觉效果: 在SEFE基础上整合ILVC后,ChairS数据集上的幻觉率,1.8B和7B模型分别降低了3.0%和4.8%。

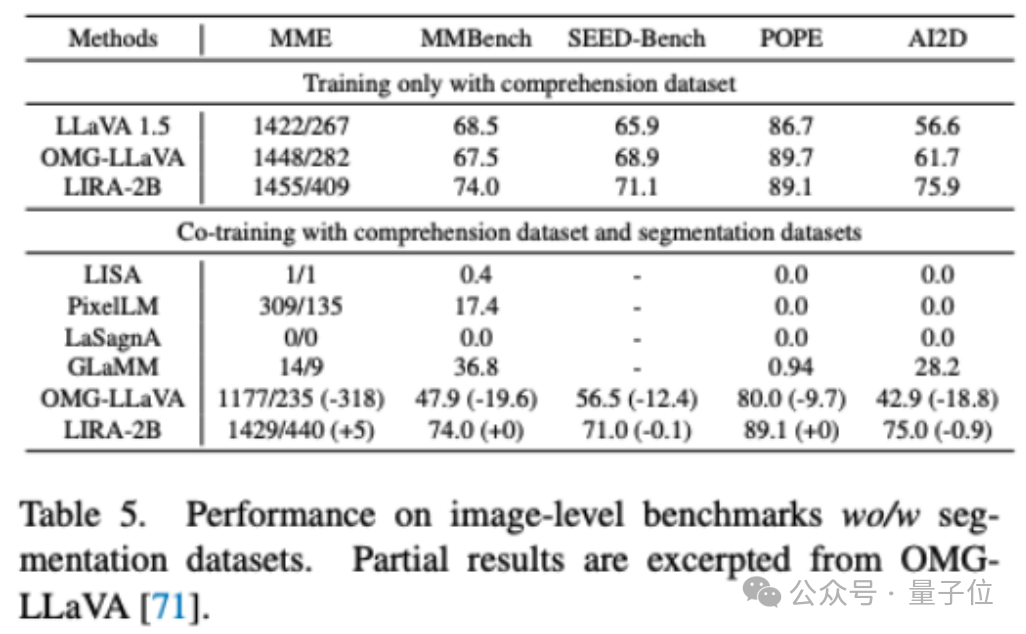
LIRA在理解数据和分割数据上进行联合训练时,性能仅略微下降0.2%,远优于OMG-LLaVA在五个理解数据集上近15%的性能下降。
总结与展望
LIRA通过SEFE和ILVC两大模块,成功实现了多模态大模型在理解和分割任务上的协同性能提升,并开辟了在细粒度多模态大模型中缓解幻觉的新视角。
研究人员还发现,分割任务中的token logits能准确反映被分割物体的属性,暗示其蕴含更丰富的语义信息。未来,深入挖掘文本与视觉token间的关联,有望为下一代多模态模型的发展提供新的研究方向。
相关资源:
- arXiv: https://arxiv.org/abs/2507.06272
- GitHub: https://github.com/echo840/LIRA
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
评论区