




📢 转载信息
原文链接:https://www.qbitai.com/2025/10/339545.html
原文作者:时令
效率革命:Meta提出元认知复用,将重复推理化繁为简,推理Token暴降46%!
大模型在处理复杂任务时,往往会陷入“思维链”的重复推导陷阱,导致Token消耗激增、延迟增加,并占用宝贵的上下文窗口。为了解决这一低效问题,Meta联合Mila-Quebec AI Institute、蒙特利尔大学和普林斯顿大学的研究团队,提出了一种创新的元认知复用(Metacognitive Reuse)机制。
该机制的核心思想是:让模型像人类一样,在解决问题的过程中回顾、总结并提炼出可复用的通用推理步骤,将其固化为简洁的“行为”,并存储在“行为手册(Behavior Handbook)”中。当模型遇到类似问题时,可以直接调用手册中的行为,避免了不必要的重复计算。
实验证明,在MATH、AIME等数学基准测试中,该方法在保持模型准确率不变的前提下,推理Token的使用量最多可减少46%。

告别冗余:为何需要“行为手册”?
当前,大型语言模型(LLM)在进行数学、编程等复杂推理时,依赖思维链(CoT)来分解步骤。然而,这带来了两大弊端:一是Token膨胀和延迟增加;二是上下文空间被大量占用,限制了模型探索新思路的能力。
现有的知识检索增强(RAG)系统主要处理“事实性知识”(是什么),而缺乏处理“程序性知识”(如何思考)的复用机制,这正是重复推理低效的根源。
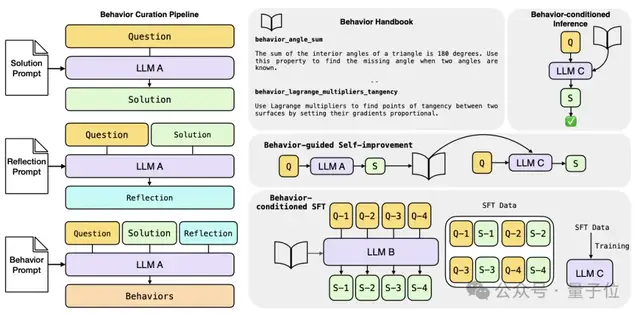
元认知复用机制正是为了弥补这一空白。它允许模型:
- 解决问题并记录轨迹: 生成完整的推理过程。
- 自我反思与提炼: 回顾轨迹,识别可复用的推理步骤。
- 标准化为“行为”: 将这些步骤转化为带有规范名称的简短、可执行指令。
- 存储与调用: 将“行为”收录到可检索的“行为手册”中,供测试或微调时调用。

“行为”构建的三重角色扮演
该框架涉及LLM扮演三种角色协同工作:
- 元认知策略器(LLM A): 负责从自身的推理轨迹中自动提取和定义“行为”。
- 教师(LLM B): 负责生成用于监督微调(SFT)的训练数据。
- 学生(LLM C): 其推理过程通过调用或微调这些“行为”而得到增强。
提取流程包括:生成解决方案 $ ightarrow$ 输入问题与解答生成反思(评估逻辑、检查可简化部分) $ ightarrow$ 将问题、解答和反思转化为规范的“行为条目”,并存入手册。
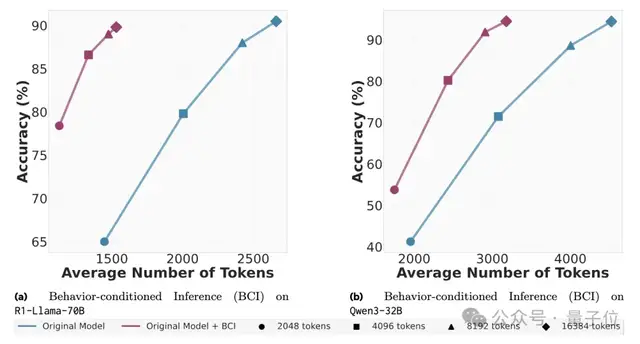
实战效果:更少Token,更高精度
研究团队在三种不同的应用场景下验证了“元认知复用”机制的有效性。
1. 行为条件推理(BCI)
在MATH和AIME等数据集上,使用BCI方法,模型(如R1-Llama-70B和Qwen3-32B)能够在消耗更少Token的情况下,达到甚至超越基线模型的性能。
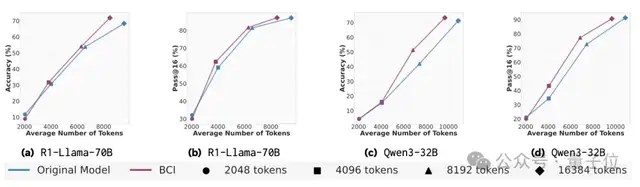
2. 行为引导的自我改进
让模型(R1-Llama-70B)扮演元认知策略器和学生,直接对自己生成的推理轨迹进行批判和修正。这种“自改作业”的策略,即使不进行参数更新,也能借助提炼出的行为模式优化后续推理效果,准确率相比朴素的批判-修正基线最高提升了10%。

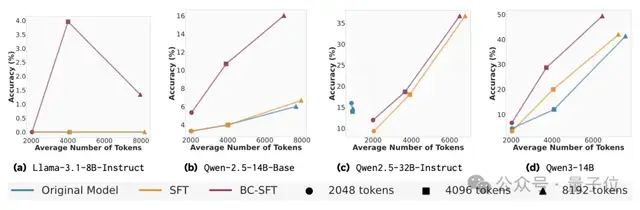
3. 行为条件监督微调(BC-SFT)
BC-SFT旨在将高质量行为直接内化到模型参数中。与常规SFT相比,BC-SFT能更高效地将缺乏推理能力的基础模型转化为具备推理能力的模型,并且几乎在所有测试场景下,其准确率均优于基线模型。
参考链接:
[1]https://x.com/connordavis_ai/status/1971937767975498160
[2]https://arxiv.org/abs/2509.13237
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区