




📢 转载信息
原文链接:https://www.qbitai.com/2025/10/339932.html
原文作者:时令
推理、数学、编程,样样精通!
量子位 | 公众号 QbitAI
又一个万亿参数级国产模型开源了!
就在刚刚,蚂蚁正式发布百灵大模型的第一款旗舰模型——
拥有万亿参数的通用语言模型Ling-1T。
刚一登场,不仅超越开源模型DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905,还超越了闭源模型GPT-5-main、Gemini-2.5-Pro。
在有限输出token的条件下,于代码生成、软件开发、竞赛数学、专业数学、逻辑推理等多项复杂推理基准中取得SOTA表现。
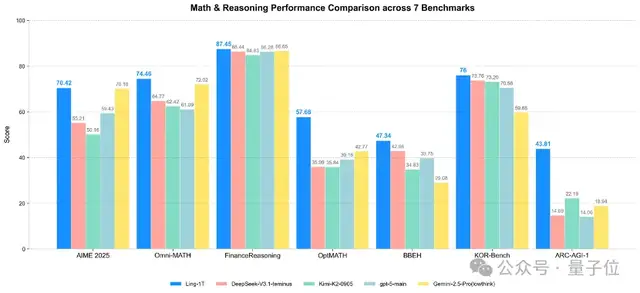
不仅如此,Ling-1T还展现出高效思考与精准推理的优势。例如,在竞赛数学榜单AIME 25上,Ling-1T就超越了一众模型获得最优表现。
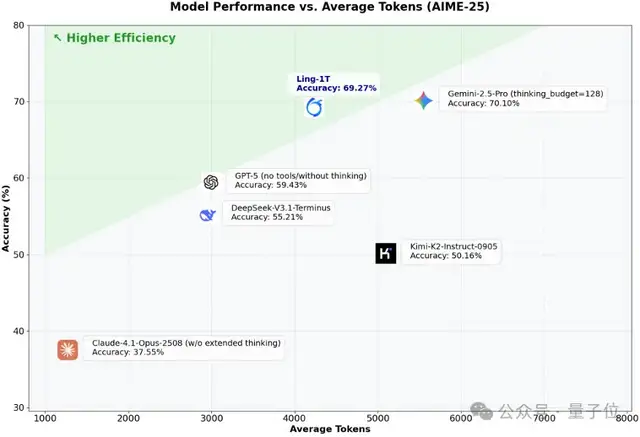
更重要的是,Ling-1T在推理速度上的表现堪称惊艳,输入刚落下,模型立刻就启动思考进程。无论是复杂的逻辑推演,还是生成多轮长文本,它都能快速响应保持流畅输出。
Ling-1T参数够多,但它到底有多强、有多快?还是得通过实测才能见真章。
推理高效,前端有惊喜
不妨先用经典推理题目来小试一下身手。
让7米长的甘蔗通过2米高1米宽的门。
只见Ling-1T先将其判断为一个典型的空间几何优化问题,并进行了关键障碍分析。

随后,共提出了4种解决方案,每种方案都有具体的操作步骤和适用场景说明。

更关键的是,Ling-1T还能严谨地对每种方法进行物理可行性验证,详细分析其所需条件和潜在风险。
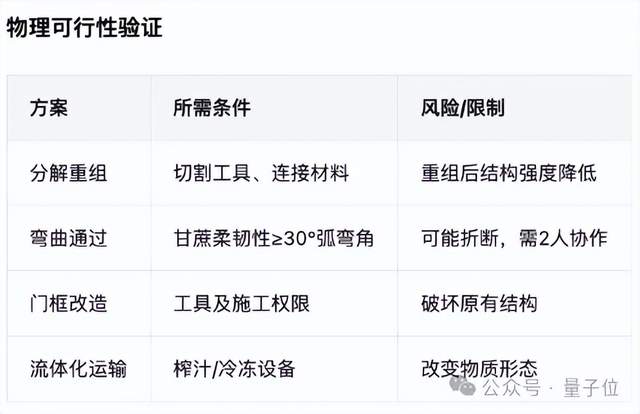
可以说是有理有据了(doge)。
既然如此,咱可就给Ling-1T上难度了,用一道“外星人分裂”问题测试一下其数学能力。
一个外星人来到地球后等可能选择以下四件事中的一件完成:
1、自我毁灭;
2、分裂成两个外星人;
3、分裂成三个外星人;
4、什么都不做。
此后每天,每个外星人均会做一次选择,且彼此之间相互独立。
求地球上最终没有外星人的概率。

Ling-1T反应非常快,几乎是一看到问题就迅速开始分析与推理。
它首先确定了题目的类型,并对题目进行了建模,接着一步步求解最后得到正确答案:√2-1。
推理能力测试完毕,接下来轮到代码能力上场了。
正值诺贝尔奖揭晓之际,咱用它生成一个介绍诺贝尔奖的网站如何?

新模型kuku就是干啊,效果如下所示:

很直观,无需特意提醒,Ling-1T就将内容分成概览、奖项类别、历史时间线等模块,让用户可以快速定位感兴趣的信息。
无论是想了解整体概况、深入某个奖项类别,还是回顾诺贝尔物理学奖的历史演变,都能获得清晰、系统的呈现,使用体验更加直观高效。
双节假期刚结束,旅游攻略是不是做得头都大了。尝试用Ling-1T规划出行路线,它不仅把景点按特色分类,还贴心规划好一日游的时间安排和费用,连适合的交通工具、地道美食都一并推荐。所有选项都打上了清晰标签,让你轻松选择。

值得一提的是,基于Ling-1T强大的推理能力,研究团队还进一步提出了“语法–功能–美学”混合奖励机制,这意味着其生成的代码不仅正确、功能完整,还兼顾了界面和视觉美感。
例如,在ArtifactsBench前端能力基准上,Ling-1T就以明显优势成为开源模型中的第一名。
“中训练+后训练”,让模型真正“学会思考”
模型开源之外,这一次蚂蚁也完整公布了Ling-1T背后的技术思考。
总结起来,最值得关注的就是研究团队在扩展模型尺寸和强化推理能力两方面的探索。
参数数量决定了模型能存储和表达的信息量,就像大脑的神经元越多,记忆和思考的能力越强。
参数不足时,模型可能只能记住简单规律,面对复杂或长下文问题时容易出错。
当参数充足时,模型可以在更大数据量和更复杂任务中实现更准确的推理和更好的泛化能力。
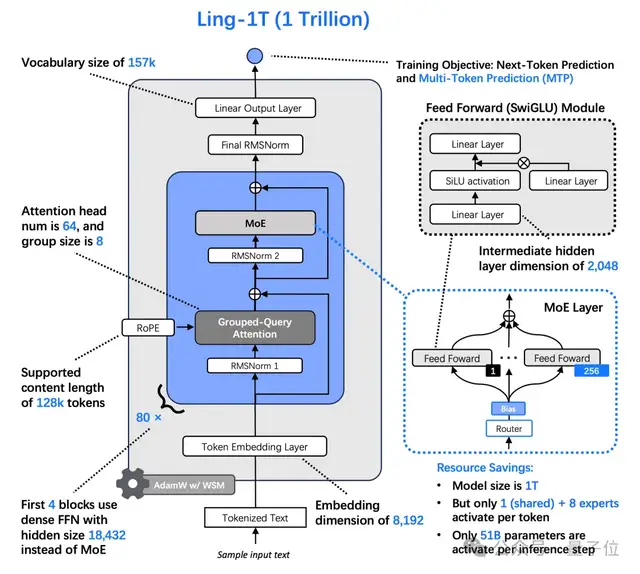
基于上述原因,Ling-1T沿用了Ling 2.0的架构设计,并在此基础上将总参数量扩展至1万亿,其中每个token激活约50B参数。
其基础版本(Ling-1T-base)首先在超过20T token的高质量、强推理语料上完成了预训练,并支持最长128K的上下文窗口。
随后,团队通过采用“中训练+后训练”相结合的演进式思维链(Evo-CoT)方法,这一改进让模型不仅拥有海量知识,更能像人一样逐步推理,极大提升了模型的高效思考和精准推理能力。

在研发Ling-1T万亿级模型的过程中,研究团队发现,扩展模型规模和强化推理能力会带来一定的性能提升。
在预训练阶段,他们先搭建了一个统一的数据管理系统,这套系统能追踪每一条数据的来源和流向。
然后,他们整理了超过40万亿token的高质量语料,并挑选出最优部分,用于Ling-flash-2.0的20万亿token预训练计划。
毕竟模型的推理能力就像大脑思考问题,先打基础知识,再训练逻辑推理,基础打得扎实,思考才能快而准确。
为了让模型既能积累丰富知识,又能提高推理能力,团队将预训练分成3个阶段:
第一阶段先用10T token高知识密度语料训练,让模型先全面掌握事实、概念和常识,为后续推理打下坚实基础。
第二阶段用10T token高推理密度语料训练,让模型学会逻辑推理、多步思考和问题解决技巧,让模型不仅知道答案,还能分析思路,提高解决复杂问题的能力。
中间训练阶段(Midtrain)则扩展上下文窗口到32K token,同时提高推理类语料的质量和比例,并加入思维链推理内容,为模型进入后训练做好热身准备,保证逻辑连贯性和推理效率。
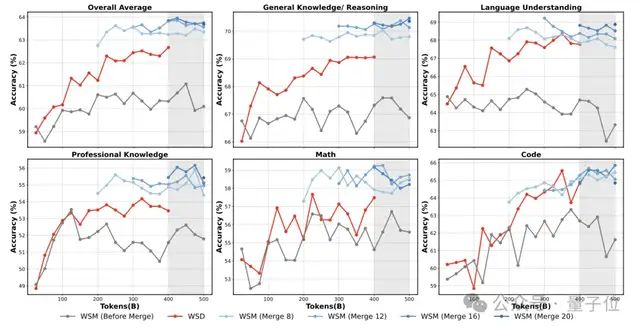
整个训练过程中,团队根据Ling Scaling Laws设置学习率和批量大小,并用自研的WSM(Warmup-Stable and Merge)替代传统的WSD(Warmup-Stable-Decay)学习率策略。
要知道,在训练大模型时需要控制学习率(学习速度),就像学习弹琴或开车一样,速度太快容易出错,太慢又不够高效。
为此,WSM框架可实现无衰减学习率却能提升模型性能,核心思路可以概括为以下3步:
Warmup(预热):训练一开始慢慢来,让模型稳定起来,不出大错。
Stable(稳定):训练中期保持稳定的学习速度,让模型慢慢学到规律。
Merge(合并):把训练过程中不同阶段保存下来的模型“融合”在一起,相当于把每一阶段的优点结合起来,既保留早期探索的优势,又强化后期收敛的效果,让模型最终表现更好。
Ling-1T通过中训练检查点合并技术表明,即使不采用传统的学习率衰减策略,模型仍能在绝大多数下游任务中取得更优性能。
实验结果显示,影响模型表现最关键的不是合并次数,而是合并时的训练窗口,即何时进行合并以及合并持续的时间长度,对性能的影响远超其他因素。
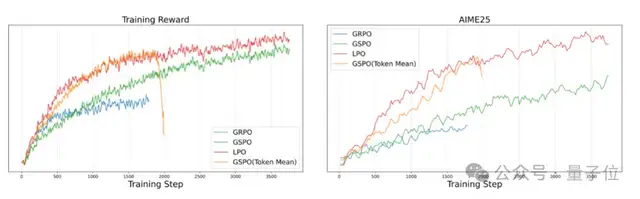
在后训练阶段,由于当前主流的强化学习算法(如GRPO和GSPO)各有局限。
- GRPO:将每个词元(token)视为独立动作进行优化,虽精细,但容易导致语义的过度碎片化。
- GSPO:将整个生成序列视为单一动作进行优化,在全局序列级别执行策略更新,虽稳定,但又可能造成奖励信号的过度平滑。
蚂蚁发现,对于推理任务来说,句子比单个词元或整个序列更符合语义逻辑,它不仅能保持语义完整,又能让模型在局部逻辑上进行有效训练,从而更精准地捕捉语言中的推理和逻辑关系,因此更适合作为策略优化的基本单位。
于是,研究团队创新性地提出了LPO方法(Linguistics-Unit Policy Optimization,LingPO),首次将句子作为中间粒度进行策略优化,在语义与逻辑之间找到最佳平衡,并在这一层面上执行重要性采样和裁剪,从而帮助万亿参数模型更稳健地训练。
这种设计既避免了词元级别的碎片化问题,又克服了序列级别过于笼统的局限,使奖励信号与模型行为在语义层面上更加精准地对齐。
实验结果显示,与GRPO和GSPO相比,LPO在训练稳定性和模型泛化能力方面都具有明显优势。
中国大模型“王炸”连发
今年以来,中国开源力量不断给予大模型圈惊喜。从DeepSeek这尾鲶鱼搅乱基础大模型格局,到Qwen家族以全面覆盖、快速迭代的姿态撼动Llama系列王座……国产开源模型不仅在全球榜单上站到C位,更重要的是,每一次“开源大礼包”,都能从不同的角度给模型研究、应用带来新的思考。
此番蚂蚁开源Ling-1T,亦是如此。
在技术范式上,Ling-1T在架构设计和训练方法上实现了多重创新,以演进式思维链的新方法,使得模型在每一阶段中生成的思路或结论,都可以被复查、修正或扩展,从而不断迭代优化。
同时,前一阶段的推理成果会被累积并传递至后续阶段,形成知识的持续演进。这种渐进式的推理机制,不仅增强了思维过程的稳定性和结果准确性,也使得推理路径清晰可循,显著提升了复杂任务的可解释性。
在效果体验上,Ling-1T展现出令人印象深刻的快速响应能力,即刻可完成复杂任务的推理与生成。
无论是面对抽象的数学问题、多步骤的逻辑推演,还是编程任务与科学背景的深度解析,该模型均能迅速构建出条理清晰、逻辑严谨的解答。
总结起来,一方面,Ling-1T让蚂蚁正式加入 “万亿参数开源俱乐部”,与Qwen、Kimi并肩站在开源生态的第一梯队;另一方面,其创新的非思考模型架构与高效推理优化设计,为业界探索高性能思维模型提供了新的技术范式。
更加值得关注的是,尽管2025年只剩下最后的83天,但蚂蚁的最新开源动作,也意味着中国大模型厂商们的开源节奏并没有放缓。
就在国庆节前,Qwen接连推出多模态模型Qwen3-Next、Qwen3-VL以及图像编辑模型Qwen-Image-Edit-2509;DeepSeek也在短期内连续开源DeepSeek-V3.1-Terminus和DeepSeek-V3.2-Exp两个重要版本,还被爆料年底会有更重磅模型进展……现在,假期刚结束,蚂蚁再次把这种开源势头续住了。
可以预见的是,大模型领域的精彩还将继续。而下一个惊喜,大概率还是来自中国。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区