



📢 转载信息
原文作者:Adam Fourney, Tyler Payne, Maya Murad, Saleema Amershi
工具空间干扰:在MCP时代为大规模智能体设计兼容性
发布于:2025年9月11日
今年我们见证了智能体AI的非凡进步,包括能够进行深度研究、操作计算机、完成大量软件工程任务以及解决各种复杂多步骤目标的系统。在每种情况下,行业都依赖于精心的垂直整合:工具和智能体被共同设计、共同训练和共同测试,以达到最佳性能。例如,OpenAI最近的模型默认了网络搜索和文档检索工具的可用性 (opens in new tab)。同样,Magentic-One的提示和操作被设置为便于交接——例如,允许WebSurfer智能体将下载的文件传递给Coder智能体。然而,随着智能体的激增,我们预计严重依赖垂直整合的策略将难以持续。来自不同开发者或公司的智能体将越来越多地相互遇到,并且必须协同工作以完成任务,这就是我们所说的“智能体社会”。这些系统在协调程度、目标一致性和信息共享方面可能有所不同。异构的智能体和工具在这种环境中能否协同工作,还是会相互阻碍并减缓进展?
意想不到的线索:模型上下文协议 (MCP) 的兴起
早期线索已从一个意想不到的来源浮现:即模型上下文协议 (MCP) (opens in new tab)。自2025年1月以来,MCP已从一个有前景的规范发展成为一个蓬勃发展的工具服务器市场。例如,Zapier拥有跨越7000个服务的30,000个工具目录 (opens in new tab)。Composio (opens in new tab)提供了100多个托管的MCP服务器,暴露了数百个工具。Hugging Face现在通过MCP为许多Spaces应用程序 (opens in new tab)提供服务,并且Shopify已为数百万个店面启用了MCP (opens in new tab)。一个工具社会已经到来,它有望通过跨提供商的水平集成来扩展智能体的能力。
那么,MCP对水平集成有何启示呢?随着目录的增长,我们预计会出现一些新的失败模式。本博客文章将这些模式引入为工具空间干扰,并概述了早期的观察结果以及一些务实的干预措施,以防止我们正在构建的社会绊倒自己。
工具空间干扰描述了本应合理的工具或智能体在共同存在时,导致端到端效率降低的情况。这可能表现为更长的操作序列、更高的Token成本、从错误中恢复的脆弱性,或者在某些情况下,任务失败。
一个框架示例
考虑将MCP作为扩展我们去年发布的通用多智能体系统Magentic-One的一种方式,以涵盖更多的软件工程任务。Magentic-One自带用于编写代码、与计算机终端交互、浏览网页和访问本地文件的智能体。为了帮助Magentic-One处理版本控制、查找要解决的问题和进行Pull Request,我们可以添加一个配备了GitHub MCP服务器的智能体。然而,现在每次团队遇到涉及GitHub的任务时,都必须在浏览器中访问github.com、在命令行执行git命令或与GitHub MCP服务器交互之间做出选择。随着任务的进展,智能体对状态的理解也可能出现分歧:在浏览器中更改分支不会改变终端中的分支,而且授权的MCP工具不意味着在浏览器中也已授权。因此,虽然任何单个智能体都可能高效地完成任务,但更大的智能体集合可能会相互误解或干扰,从而导致额外的调试轮次,甚至任务完全失败。

通过MCP视角审视工具空间干扰
为了更好地理解潜在的干扰模式和MCP生态系统的现状,我们对两个注册表中列出的MCP服务器进行了调查:smithery.ai (opens in new tab)和Docker MCP Hub (opens in new tab)。Smithery是一个MCP服务器注册表,包含超过7000个第一方和社区贡献的服务器,我们从Smithery API中抽取了样本。同样,Docker MCP Hub是一个将MCP服务器作为Docker镜像分发的注册表,我们手动收集了热门条目。然后,我们启动了每个服务器进行检查。在排除空置或启动失败的服务器并对具有相同功能的服务器进行去重后,我们的目录中剩余了1,470个服务器。
为了自动化检查正在运行的MCP服务器,我们开发了一个MCP 访谈工具(MCP Interviewer)。MCP 访谈工具首先编目服务器的工具、提示、资源、资源模板和能力。从这个目录中,我们可以计算描述性统计数据,例如工具的数量或参数模式的深度。然后,给定可用工具列表,访谈工具使用一个LLM(在我们的例子中是OpenAI的GPT-4.1)来构建一个功能测试计划,该计划至少调用每个工具一次,在此过程中收集输出、错误和统计数据。最后,访谈工具还可以通过使用LLM将专门构建的评分标准应用于工具模式和工具调用输出来评估更定性的标准。我们很高兴地将MCP 访谈工具作为开源CLI工具发布 (opens in new tab),以便服务器开发人员可以从代理可用性的角度自动评估其MCP服务器,用户也可以验证新服务器。
虽然我们的调查提供了信息丰富的初步结果,但它也面临着明显的局限性,最明显的是授权问题:许多最受欢迎的MCP服务器提供了对需要授权才能使用的服务的访问,阻碍了自动化分析。我们通常仍然可以从这些服务器收集静态特征,但在功能测试方面受到了限制。
一刀切(但有些更适合)
那么,我们对MCP服务器的调查告诉我们关于MCP生态系统的哪些信息呢?我们稍后会深入了解具体数字,但在思考统计数据时,有一个总体主题需要牢记:MCP服务器不知道它们正在与哪些客户端或模型合作,而是向所有人呈现一套通用的工具、提示和资源。然而,一些模型在处理长上下文和大工具空间方面比其他模型更好(具有不同的硬性限制),并且对常见的提示模式反应截然不同。例如,OpenAI关于函数调用的指南 (opens in new tab)建议开发人员:
“包含示例和边缘情况,特别是为了纠正任何经常出现的故障。(注意:添加示例可能会损害推理模型的性能)”
因此,这已经使MCP相对于优化了操作环境的垂直集成处于劣势。话不多说,让我们深入了解更多数字。
工具数量
虽然模型在工具调用方面通常表现不同,但总体趋势是工具数量增加时性能下降。例如,OpenAI将开发人员限制为128个工具,但建议 (opens in new tab)开发人员:
“保持函数数量较少以提高准确性。评估您在不同数量函数下的性能。目标是每次少于20个函数,但这只是一个软性建议。”
虽然我们预计随着每一代新模型的出现这种情况会有所改善,但目前,大型工具空间可能会使某些模型的性能下降高达85% (opens in new tab)。幸运的是,我们调查的大多数服务器包含四个或更少的工具。但也有例外:我们编目的最大MCP服务器添加了256个不同的工具,而接下来最大的10个服务器每个都添加了100多个工具。在列表的更下方,我们发现了像Playwright-MCP (opens in new tab)(截至撰写本文时有29个工具)和GitHub MCP(91个工具,在替代端点URL下有子集可用)这样流行的服务器,它们对某些模型来说可能过大。

响应长度
工具通常在智能体循环中被调用,其输出随后作为输入上下文反馈给模型。模型对输入上下文有硬性限制,但即使在这些限制内,大的上下文也会增加成本并降低性能,因此实际限制可能要低得多 (opens in new tab)。MCP对工具调用可以产生多少Token没有提供指导,并且某些响应的大小可能会带来惊喜。在我们的分析中,我们考虑了MCP 访谈工具在服务器检查的主动测试阶段能够成功调用的1,312个唯一工具的2,443次工具调用。虽然大多数工具产生的Token数量少于或等于98个 (opens in new tab),但有些工具的开销非常大:返回的第一个工具平均产生557,766个Token,这足以淹没许多流行模型的上下文窗口,例如GPT-5。再往下看,我们发现有16个工具产生的Token超过128,000个,淹没了GPT-4o和其他流行模型。即使响应适合上下文窗口长度,过长的响应也会显著降低性能(一项研究中最高达91% (opens in new tab)),并限制可以进行的未来调用次数。当然,智能体可以自由实现自己的上下文管理策略,但这种行为在MCP规范中是未定义的,服务器开发人员不能指望任何特定的客户端行为或策略。
| 在以下情况下会溢出上下文的工具数量 | |||||
| 模型 | 上下文窗口 | 1 次调用 | 2 次调用 | 3-5 次调用 | 6-10 次调用 |
| GPT 4.1 | 1,000,000 | 0 | 1 | 7 | 11 |
| GPT 5 | 400,000 | 1 | 7 | 15 | 25 |
| GPT-4o, Llama 3.1, | 128,000 | 16 | 15 | 33 | 40 |
| Qwen 3 | 32,000 | 56 | 37 | 86 | 90 |
| Phi-4 | 16,000 | 93 | 60 | 116 | 109 |

工具参数复杂度
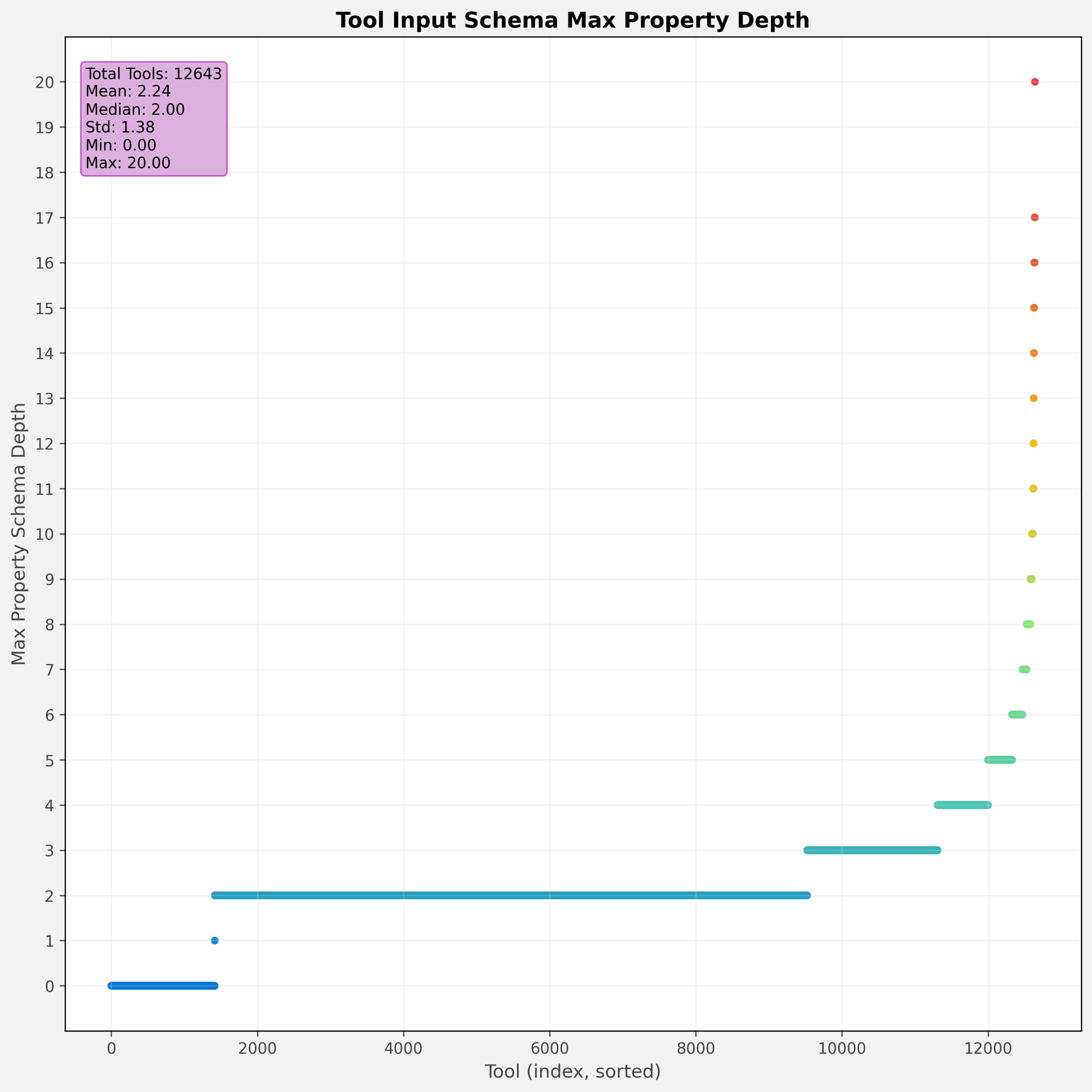
与增加工具数量带来的挑战类似,增加工具参数空间的复杂性也会导致性能下降。例如,虽然MCP工具可以接受复杂的对象类型和结构作为参数,但Composio (opens in new tab)发现,与基线性能相比,扁平化参数空间可以将工具调用性能提高47%。在我们的分析中,我们发现了大量深度嵌套结构的例子——在一种情况下,深度达到了20层。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区