



📢 转载信息
原文作者:Srikanta Prasad, Utkarsh Arora, Raghav Tanaji, Nitin Surya, Gokulakrishnan Gopalakrishnan, Akhilesh Deepak Gotmare, and Hrushikesh Gangur
Amazon Bedrock自定义模型导入:Salesforce实现大型语言模型(LLM)部署的优化之道
本文由Salesforce的AI平台团队成员Srikanta Prasad、Utkarsh Arora、Raghav Tanaji、Nitin Surya、Gokulakrishnan Gopalakrishnan、Akhilesh Deepak Gotmare以及Hrushikesh Gangur共同撰写。
Salesforce的人工智能(AI)平台团队为像Agentforce这样的代理式AI应用,运行着定制化的大型语言模型(LLMs)——这些模型是Llama、Qwen和Mistral等模型的微调版本。部署这些模型带来了巨大的运维开销:团队需要花费数月时间优化实例类型、服务引擎和配置。这个过程耗时且难以维护(尤其在频繁发布时),同时,为应对峰值使用而预留GPU容量也带来了高昂的成本。
Salesforce通过采用Amazon Bedrock自定义模型导入(Custom Model Import)解决了这一问题。借助此功能,团队可以通过统一的API导入和部署定制模型,从而最小化基础设施管理工作,同时无缝集成Amazon Bedrock的各项特性,如Amazon Bedrock知识库、Amazon Bedrock护栏和Amazon Bedrock智能体。这次转变使Salesforce能够专注于模型和业务逻辑本身,而非基础设施的运维。
本文将展示Salesforce如何将Amazon Bedrock自定义模型导入集成到其机器学习运维(MLOps)工作流中,如何在不修改应用的情况下复用现有端点,以及如何进行可扩展性基准测试。我们将分享在运维效率和成本优化方面取得的关键指标,并为简化部署策略提供实践见解。
集成策略:无缝桥接现有流程
Salesforce从Amazon SageMaker推理迁移到Amazon Bedrock自定义模型导入,需要仔细地与现有MLOps流水线集成,以避免中断生产工作负载。团队的首要目标是保持现有的API端点和模型服务接口,实现零停机,并且下游应用无需任何更改。通过这种方式,他们可以在利用Amazon Bedrock无服务器能力的同时,保留对现有基础设施和工具的投资。集成策略的核心是为现有部署工作流与Amazon Bedrock托管服务之间创建一个无缝的桥梁,从而实现在不增加额外运维风险的情况下逐步迁移。
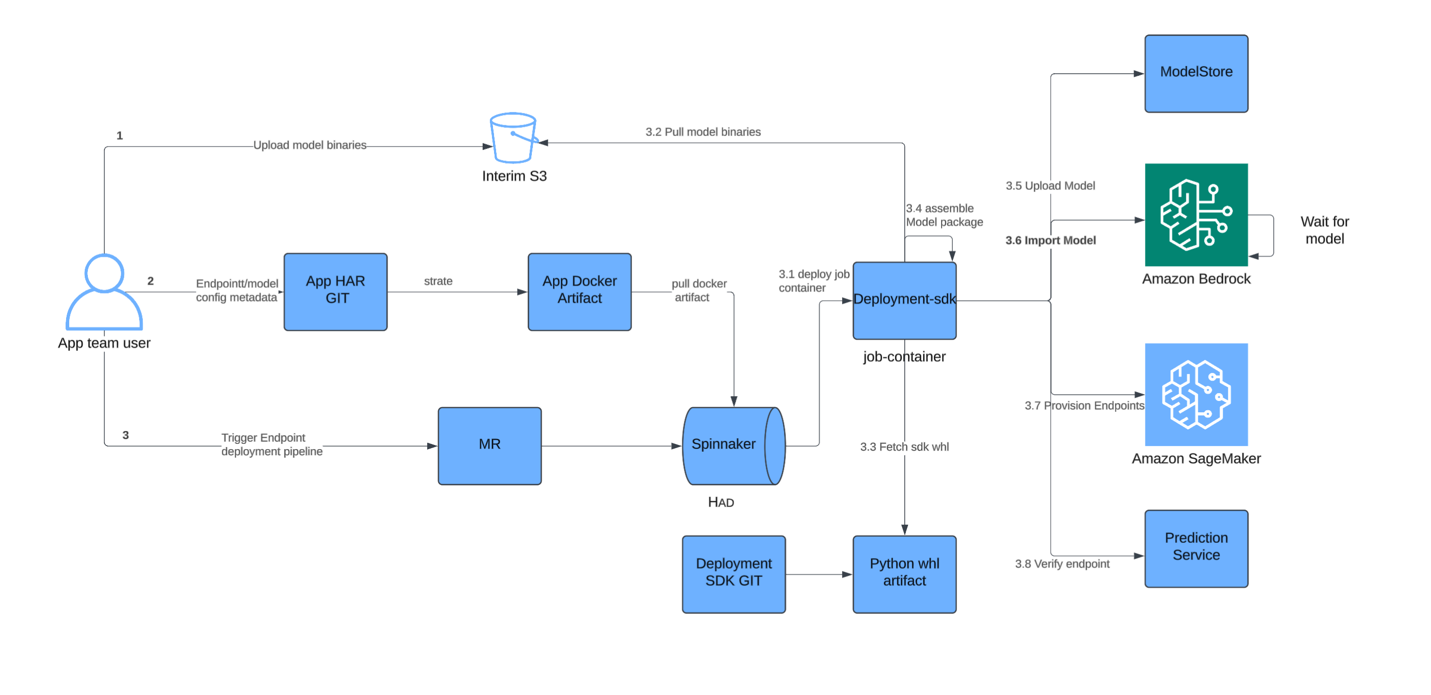
如下图所示的部署流程图,Salesforce仅在现有模型交付流水线中增加了一个步骤,即可使用Amazon Bedrock自定义模型导入。他们的持续集成和持续交付(CI/CD)流程将模型工件保存到模型存储(一个Amazon Simple Storage Service (Amazon S3) 存储桶)后,会调用Amazon Bedrock自定义模型导入API来注册模型。这是一个轻量级的控制平面操作,因为Amazon Bedrock直接从Amazon S3拉取模型,仅为部署时间线增加极少的开销(取决于模型大小,约为5-7分钟)——整个模型发布流程仍保持在约1小时内完成。这次集成带来了即时的性能优势:SageMaker在容器启动时不再需要下载权重,因为Amazon Bedrock已预加载了模型。主要的配置更改包括授予Amazon Bedrock权限,以允许跨账户访问其S3模型存储桶,并更新AWS身份和访问管理(IAM)策略,以便推理客户端可以调用Amazon Bedrock端点。
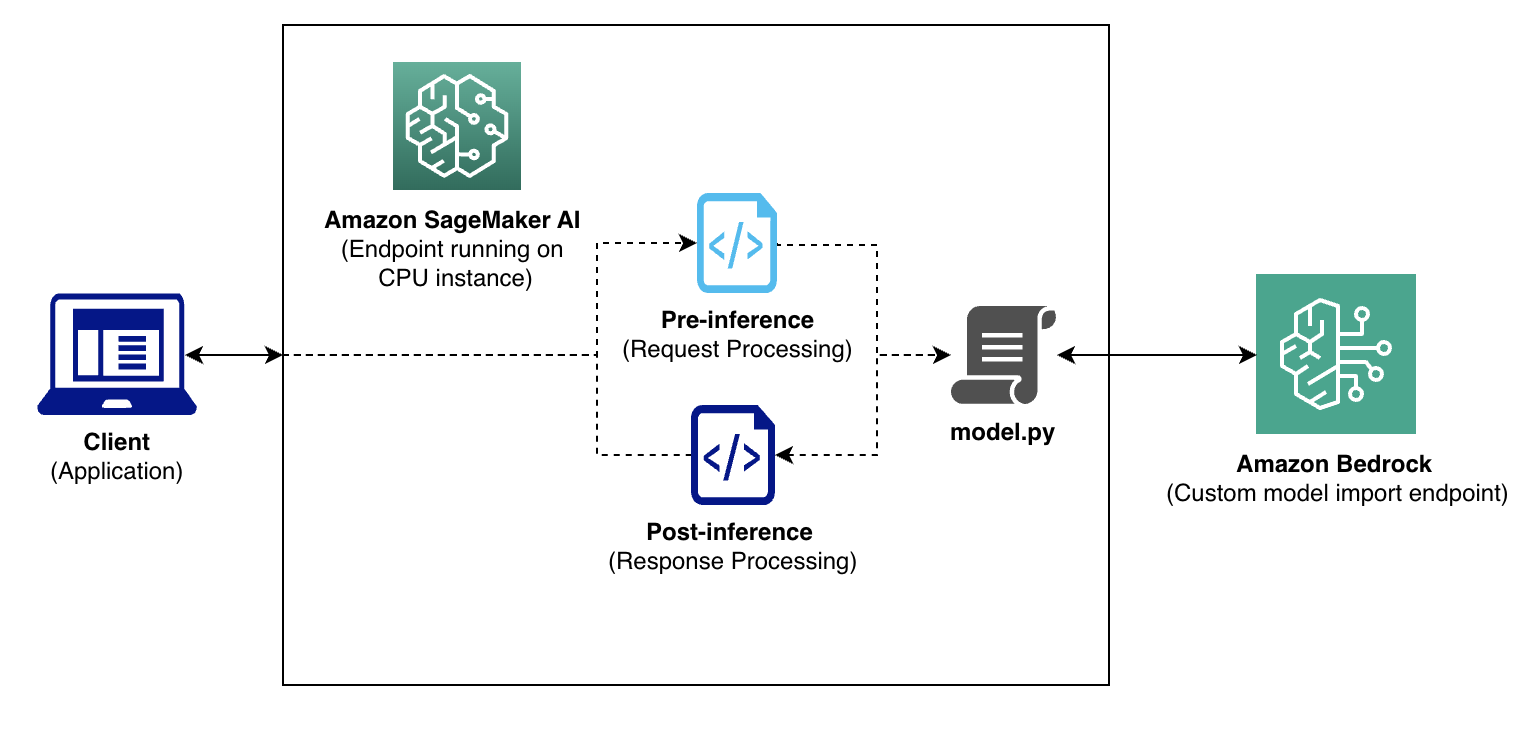
以下推理流程图展示了Salesforce如何在利用Amazon Bedrock无服务器功能的同时,保持现有的应用程序接口。客户端请求通过他们既有的预处理层(用于处理如提示词格式化等业务逻辑)流向Amazon Bedrock,模型输出经过后处理。为了处理复杂的处理需求,他们部署了轻量级的SageMaker CPU容器,作为智能代理——这些容器运行自定义的model.py逻辑,并将实际推理转发给Amazon Bedrock端点。这种混合架构保留了他们现有的工具框架:预测服务继续调用SageMaker端点而无需路由更改,并且他们保留了成熟的SageMaker监控和日志记录用于预处理和后处理逻辑。这种方法的权衡是增加了额外的网络跳跃,导致5-10毫秒的延迟,以及需要持续运行的CPU实例成本。但这种方案实现了对现有集成的向后兼容性,同时通过Amazon Bedrock将GPU密集型推理完全转为无服务器化。
可扩展性基准测试:无缝应对负载
为了验证Amazon Bedrock自定义模型导入的性能潜力,Salesforce在各种并发场景下进行了全面的负载测试。测试方法着重于衡量Amazon Bedrock透明的自动扩展行为——该服务在需求下自动启动模型副本并在重负载下扩展——对实际性能的影响。每个测试都通过其代理容器向Amazon Bedrock端点发送标准化的负载(包含模型ID和输入数据),并测量在不同负载模式下的延迟和吞吐量。结果(见下表)显示,在低并发情况下,Amazon Bedrock的延迟比ml.g6e.xlarge基线(bf16精度)低了44%。在较高负载下,Amazon Bedrock自定义模型导入在可接受的延迟(低于10毫秒)下保持了稳定的吞吐量,证明了其无服务器架构能够处理生产工作负载而无需手动扩展。
| 并发数 (Count) | P95 延迟 (秒) | 吞吐量 (每分钟请求数) |
| 1 | 7.2 | 11 |
| 4 | 7.96 | 41 |
| 16 | 9.35 | 133 |
| 32 | 10.44 | 232 |
结果显示了ApexGuru模型(微调的QWEN-2.5 13B)在不同并发级别下的P95延迟和吞吐量性能。随着并发量达到32,Amazon Bedrock自定义模型导入自动从1个副本扩展到3个副本。每个模型副本使用了1个模型单元。
成果与关键指标:效率与成本双重飞跃
除了可扩展性改进,Salesforce还从运维效率和成本优化两个关键业务维度评估了Amazon Bedrock自定义模型导入。运维效率的提升是显著的——团队将模型迭代和部署到生产环境的时间缩短了30%。这种改进源于减轻了在实例选择、参数调优以及在vLLM与TensorRT-LLM等服务引擎之间做选择等复杂决策上的负担。简化的部署流程使开发人员能够专注于模型性能而非基础设施配置。
成本优化带来了更惊人的效果,Salesforce通过Amazon Bedrock实现了高达40%的成本削减。节省成本的主要原因是其生成式AI应用流量模式的多样性——从低到高的生产流量都有。过去,他们必须为峰值工作负载预留GPU容量。而现在,按需付费的模式对开发、性能测试和预发布环境特别有利,这些环境仅在活跃开发周期内需要GPU资源,从而避免了全天候预留容量却经常处于闲置状态的情况。
经验教训:部署的关键洞察
Salesforce在使用Amazon Bedrock自定义模型导入的实践中,发现了几个可以指导其他组织考虑类似方法的关键见解。首先,尽管Amazon Bedrock自定义模型导入支持流行的开源模型架构(Qwen、Mistral、Llama),并会根据需求频繁扩展其组合,但处理尖端架构的团队可能需要等待官方支持。因此,正在使用最新模型架构进行微调的组织,应在确定部署时间表之前验证兼容性。
关于预处理和后处理,Salesforce评估了使用Amazon API Gateway和AWS Lambda函数的替代方案,这些方案提供了完全的无服务器扩展和精确到毫秒级的按需付费定价。然而,他们发现这种方法与现有集成相比,向后兼容性较差,并且在使用较大处理逻辑库时,会受到冷启动的影响。
冷启动延迟是一个关键考虑因素,尤其是对于大型模型(超过7B参数)。Salesforce观察到,对于26B参数的模型,冷启动延迟可达几分钟,延迟会根据模型大小而变化。对于无法容忍此类延迟的敏感型应用,他们建议通过每14分钟调用一次健康检查来保持至少一个模型副本处于活动状态,以保持端点“热启动”。这种方法平衡了成本效益与生产工作负载的性能要求。
结论
Salesforce采用Amazon Bedrock自定义模型导入的案例表明,如何在不牺牲可扩展性或性能的情况下简化LLM部署。他们实现了部署速度提升30%、成本节省40%,同时通过使用SageMaker代理容器与Amazon Bedrock无服务器推理的混合架构,保持了向后兼容性。对于高度定制化或不受支持的架构模型,Salesforce会继续使用SageMaker AI作为托管ML解决方案。
他们的成功源于有条不紊的执行:彻底的负载测试,以及从非关键工作负载开始的逐步迁移。结果证明,无服务器AI部署适用于生产环境,尤其是在流量模式多变的情况下。ApexGuru现在已成功部署到其生产环境中。
对于需要大规模管理LLM的团队来说,这个案例研究提供了一个清晰的蓝图:检查模型架构兼容性,为大型模型的冷启动做好计划,并保留现有接口。Amazon Bedrock自定义模型导入提供了一条经过验证的、通往无服务器AI的途径,可以在满足性能要求的同时,减少开销、加速部署并降低成本。
要了解有关Amazon Bedrock定价的更多信息,请参阅使用Amazon Bedrock优化基础模型成本和Amazon Bedrock定价。
如需在Amazon Bedrock和SageMaker AI之间进行选择的帮助,请参阅Amazon Bedrock还是Amazon SageMaker AI?
有关Amazon Bedrock自定义模型导入的更多信息,请参阅如何使用Amazon Bedrock自定义模型导入配置跨账户模型部署。
有关ApexGuru的更多详细信息,请参阅使用ApexGuru为您的Apex代码获取AI驱动的洞察。
作者简介
 Srikanta Prasad 是Salesforce生成式AI解决方案的产品管理高级经理。他领导模型托管和推理工作,重点关注LLM推理服务、LLMOps和可扩展的AI部署。
Srikanta Prasad 是Salesforce生成式AI解决方案的产品管理高级经理。他领导模型托管和推理工作,重点关注LLM推理服务、LLMOps和可扩展的AI部署。
 Utkarsh Arora 是Salesforce的技术助理成员,他将来自IIIT Delhi的坚实学术基础与早期在机器学习工程和研究方面的贡献相结合。
Utkarsh Arora 是Salesforce的技术助理成员,他将来自IIIT Delhi的坚实学术基础与早期在机器学习工程和研究方面的贡献相结合。
 Raghav Tanaji 是Salesforce的技术负责人成员,专注于机器学习、模式识别和统计学习。他拥有IISc Bangalore的硕士学位。
Raghav Tanaji 是Salesforce的技术负责人成员,专注于机器学习、模式识别和统计学习。他拥有IISc Bangalore的硕士学位。
 Akhilesh Deepak Gotmare 是基于新加坡的Salesforce研究高级研究员,专注于深度学习、自然语言处理和代码相关应用。
Akhilesh Deepak Gotmare 是基于新加坡的Salesforce研究高级研究员,专注于深度学习、自然语言处理和代码相关应用。
 Gokulakrishnan Gopalakrishnan 是Salesforce的首席软件工程师,领导ApexGuru的工程工作。拥有超过15年的经验,曾在微软工作,专注于构建可扩展的软件系统。
Gokulakrishnan Gopalakrishnan 是Salesforce的首席软件工程师,领导ApexGuru的工程工作。拥有超过15年的经验,曾在微软工作,专注于构建可扩展的软件系统。
 Nitin Surya 是Salesforce的技术负责人成员,拥有8年以上的软件/ML工程经验。他拥有VIT大学的计算机学士学位和伊利诺伊大学芝加哥分校的计算机硕士学位(专注于AI/ML)。
Nitin Surya 是Salesforce的技术负责人成员,拥有8年以上的软件/ML工程经验。他拥有VIT大学的计算机学士学位和伊利诺伊大学芝加哥分校的计算机硕士学位(专注于AI/ML)。
 Hrushikesh Gangur 是位于旧金山的AWS首席解决方案架构师。他专注于生成式AI和代理式AI,帮助初创企业和ISV构建和部署AI应用程序。
Hrushikesh Gangur 是位于旧金山的AWS首席解决方案架构师。他专注于生成式AI和代理式AI,帮助初创企业和ISV构建和部署AI应用程序。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,小白也可以简单操作。
青云聚合API官网https://api.qingyuntop.top
支持全球最新300+模型:https://api.qingyuntop.top/pricing
详细的调用教程及文档:https://api.qingyuntop.top/about
评论区