



📢 转载信息
原文链接:https://www.kdnuggets.com/7-python-eda-tricks-to-find-and-fix-data-issues
原文作者:Iván Palomares Carrascosa

Image by Editor
h2># 引言
数据探索性分析(EDA)是在进行更深入的数据分析流程或构建数据驱动的AI系统(如基于机器学习模型的系统)之前的关键阶段。虽然修复常见、现实世界中的数据质量问题和不一致性通常被推迟到数据管道的后续阶段,但EDA也是一个绝佳的机会,可以在数据静默地影响结果、降低模型性能或损害下游决策制定之前,主动检测到这些问题。
下面,我们整理了一份清单,其中包含7个可应用于早期EDA流程的Python技巧,旨在有效识别和修复各种数据质量问题。
为了说明这些技巧,我们将使用一个合成生成的员工数据集,其中我们故意注入了各种数据质量问题,以举例说明如何检测和处理它们。在尝试这些技巧之前,请确保您首先将以下前导代码复制并粘贴到您的编码环境中:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # PREAMBLE CODE THAT RANDOMLY CREATES A DATASET AND INTRODUCES QUALITY ISSUES IN IT np.random.seed(42) n = 1000 df = pd.DataFrame({ "age": np.random.normal(40, 12, n).round(), "income": np.random.normal(60000, 15000, n), "experience_years": np.random.normal(10, 5, n), "department": np.random.choice( ["Sales", "Engineering", "HR", "sales", "Eng", "HR "], n ), "performance_score": np.random.normal(3, 0.7, n) }) # Randomly injecting data issues to the dataset # 1. Missing values df.loc[np.random.choice(n, 80, replace=False), "income"] = np.nan df.loc[np.random.choice(n, 50, replace=False), "department"] = np.nan # 2. Outliers df.loc[np.random.choice(n, 10), "income"] *= 5 df.loc[np.random.choice(n, 10), "age"] = -5 # 3. Invalid values df.loc[np.random.choice(n, 15), "performance_score"] = 7 # 4. Skewness df["bonus"] = np.random.exponential(2000, n) # 5. Highly correlated features df["income_copy"] = df["income"] * 1.02 # 6. Duplicated entries df = pd.concat([df, df.iloc[:20]], ignore_index=True) df.head()
h2># 1. 通过热力图检测缺失值
虽然像Pandas这样的Python库中有函数可以计算数据集中每个属性的缺失值数量,但一个快速了解数据集中所有缺失值以及哪些列或属性包含缺失值的吸引人方法是可视化由isnull()函数辅助的热力图。该图会为数据集中每一个缺失值绘制白色的条形线,这些条形线按属性水平排列。
plt.figure(figsize=(10, 5)) sns.heatmap(df.isnull(), cbar=False) plt.title("Missing Value Heatmap") plt.show() df.isnull().sum().sort_values(ascending=False)
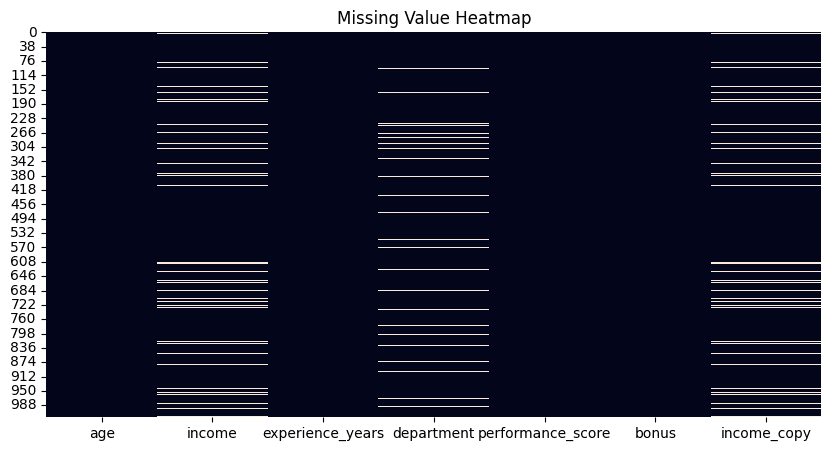
用于检测缺失值的热力图 | 图片来源:作者
h2># 2. 删除重复项
这个技巧很经典:简单却非常有效,用于计算数据集中重复实例(行)的数量,之后您可以应用drop_duplicates()将其删除。默认情况下,此函数会保留每个重复行的第一个出现,并删除其余的。然而,此行为可以通过使用keep="last"选项来保留最后一个出现而不是第一个,或使用keep=False来完全删除所有重复的行来修改。选择哪种行为取决于您的具体问题需求。
duplicate_count = df.duplicated().sum() print(f"Number of duplicate rows: {duplicate_count}") # Remove duplicates df = df.drop_duplicates()
h2># 3. 使用四分位距(IQR)方法识别异常值
四分位距(IQR)方法是一种基于统计的方法,用于识别可能被视为异常值或极端值的数据点,因为它们与其余数据点相距甚远。此技巧提供了一个IQR方法的实现,可以对不同的数值属性(如“income”)进行复制应用:
def detect_outliers_iqr(data, column): Q1 = data[column].quantile(0.25) Q3 = data[column].quantile(0.75) IQR = Q3 - Q1 lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR return data[(data[column] < lower) | (data[column] > upper)] outliers_income = detect_outliers_iqr(df, "income") print(f"Income outliers: {len(outliers_income)}") # Optional: cap them Q1 = df["income"].quantile(0.25) Q3 = df["income"].quantile(0.75) IQR = Q3 - Q1 lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR df["income"] = df["income"].clip(lower, upper)
h2># 4. 管理不一致的类别
与通常与数值特征相关的异常值不同,分类变量中不一致的类别可能源于各种因素,例如手动不一致,如名称中首字母的大小写或特定领域的变体。因此,处理它们的方法可能部分涉及领域专业知识,以决定哪些类别的集合被认为是有效的。此示例应用于指代同一部门的部门名称中的类别不一致性管理。
print("Before cleaning:") print(df["department"].value_counts(dropna=False)) df["department"] = ( df["department"] .str.strip() .str.lower() .replace({ "eng": "engineering", "sales": "sales", "hr": "hr" }) ) print("\nAfter cleaning:") print(df["department"].value_counts(dropna=False))
h2># 5. 检查和验证范围
虽然异常值是统计上遥远的值,但无效值取决于特定于域的约束,例如“age”属性的值不能为负数。此示例识别了“age”属性中的负值并将其替换为NaN——请注意,这些无效值被转换为缺失值,因此可能还需要一个下游策略来处理它们。
invalid_age = df[df["age"] < 0] print(f"Invalid ages: {len(invalid_age)}") # Fix by setting to NaN df.loc[df["age"] < 0, "age"] = np.nan
h2># 6. 对偏斜数据应用对数变换
像我们示例数据集中“bonus”这样的偏斜数据属性通常最好转换为更接近正态分布的形态,因为这有利于大多数下游机器学习分析。此技巧应用了对数变换,展示了我们的数据特征转换前后的情况。
skewness = df["bonus"].skew() print(f"Bonus skewness: {skewness:.2f}") plt.hist(df["bonus"], bins=40) plt.title("Bonus Distribution (Original)") plt.show() # Log transform df["bonus_log"] = np.log1p(df["bonus"]) plt.hist(df["bonus_log"], bins=40) plt.title("Bonus Distribution (Log Transformed)") plt.show()
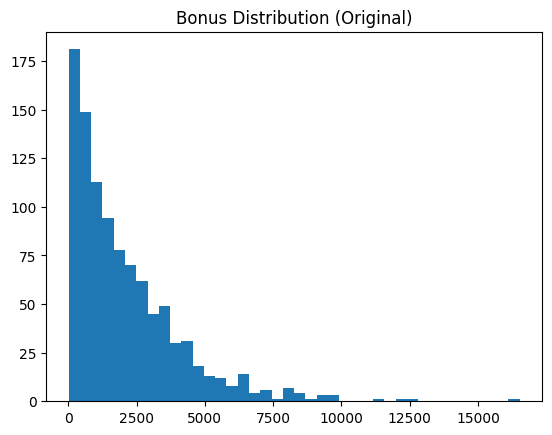
对数转换前 | 图片来源:作者
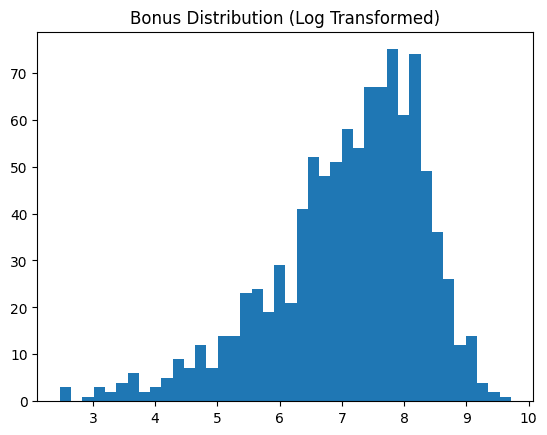
对数转换后 | 图片来源:作者
h2># 7. 通过相关性矩阵检测冗余特征
我们以一个视觉化的方式结束这个清单,就像我们开始时一样。以热力图形式显示的相关性矩阵有助于快速识别出高度相关的特征对——这强烈表明它们可能包含在后续分析中最好最小化的冗余信息。此示例还打印了相关性最高的5对属性,以供进一步解释:
corr_matrix = df.corr(numeric_only=True) plt.figure(figsize=(10, 6)) sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap="coolwarm") plt.title("Correlation Matrix") plt.show() # Find high correlations high_corr = ( corr_matrix .abs() .unstack() .sort_values(ascending=False) ) high_corr = high_corr[high_corr < 1] print(high_corr.head(5))
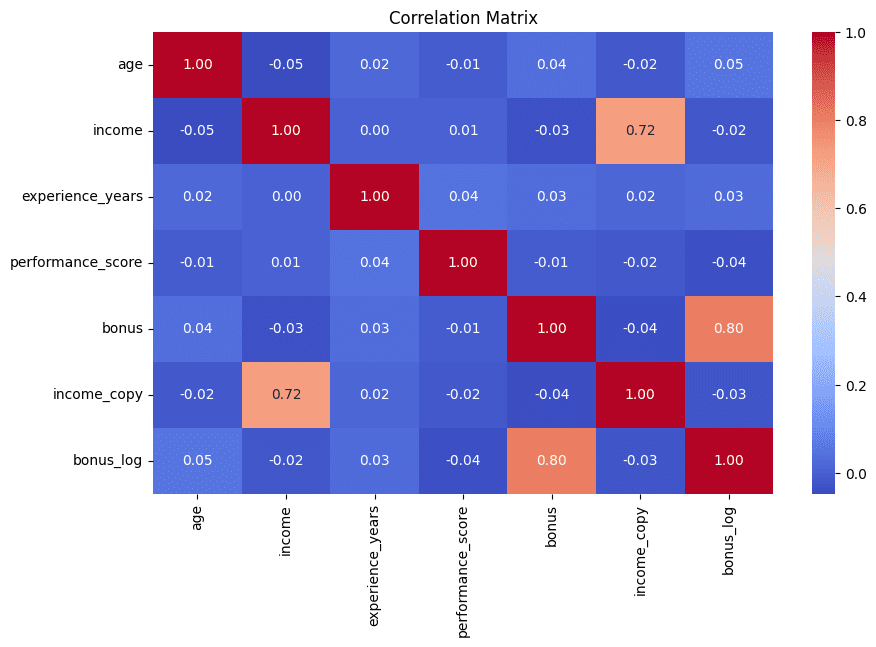
相关性矩阵用于检测冗余特征 | 图片来源:作者
h2># 总结
通过上述清单,您已经学会了7个可用于充分利用数据探索性分析的有用技巧,这些技巧有助于有效直观地揭示和处理不同类型的数据质量问题和不一致性。
Iván Palomares Carrascosa是AI、机器学习、深度学习和LLMs领域的领导者、作家、演说家和顾问。他培训和指导他人如何在现实世界中利用AI。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区