



📢 转载信息
原文作者:Kareem Syed-Mohammed, Chaoneng Quan, and Dan Ferguson
部署大型语言模型 (LLM) 进行推理需要可靠的 GPU 容量,尤其是在关键的评估期、有限的生产测试期或突发工作负载期间。容量限制可能会延迟部署并影响应用程序性能。客户可以使用 Amazon SageMaker AI 训练计划来预留指定时间段的计算容量。训练计划最初是为训练工作负载设计的,现在也支持推理端点,为有时限的推理工作负载提供可预测的 GPU 可用性。
考虑一个常见场景:您在一个数据科学团队中,需要在两周内评估几个经过微调的语言模型,然后选择一个用于生产。他们需要不间断地访问 ml.p5.48xlarge 实例来运行比较基准测试,但高峰时段在其 AWS 区域的按需容量是不可预测的。通过训练计划预留容量,他们可以不受干扰地进行评估,并控制成本和可预测的可用性。
Amazon SageMaker AI 训练计划提供了一种灵活的方式来确保容量,以便您可以搜索可用产品,选择满足您需求的实例类型、数量和时长。客户可以选择未来固定天数或月数的预留,或一次性预留一定天数。创建后,训练计划会提供一个固定的容量,在部署 SageMaker AI 推理端点时可以引用该容量。
在本文中,我们将介绍如何搜索可用的 p 系列 GPU 容量,创建训练计划预留以用于推理,并在该预留容量上部署 SageMaker AI 推理端点。我们将跟随一位数据科学家,介绍他如何预留容量以进行模型评估,并在整个预留生命周期中管理端点。
解决方案概述
SageMaker AI 训练计划 提供了一种为特定时间窗口预留计算容量的机制。创建训练计划时,客户会指定目标资源类型。通过将目标资源的值设置为“endpoint”,您可以专门为推理工作负载预留 p 系列 GPU 实例。预留的容量将通过端点配置中的 Amazon 资源名称 (ARN) 进行引用,以便端点部署预留的实例。
训练计划的创建和使用工作流程包含四个关键阶段:
- 确定您的容量需求 – 确定推理工作负载所需的实例类型、实例数量和时长。
- 搜索可用的训练计划产品 – 查询符合您需求和期望时间窗口的可用容量。
- 创建训练计划预留 – 选择合适的产品并创建预留,这将生成一个 ARN。
- 部署和管理您的端点 – 配置您的 SageMaker AI 端点以使用预留的容量,并在预留期间管理其生命周期。
让我们通过详细示例来逐步介绍每个阶段。
先决条件
开始之前,请确保您拥有以下内容:
- 具有 SageMaker AI 访问权限的 IAM 执行角色
- 已训练模型并 上传 至 Amazon Simple Storage Service (Amazon S3)
- 已安装并配置 AWS Command Line Interface (AWS CLI),或可以访问 SageMaker AI 控制台
- 一个 已创建的 SageMaker AI 训练计划
步骤 1:搜索可用容量产品并创建预留计划
我们的数据科学家首先确定符合其评估需求的可用 p 系列 GPU 容量。他们需要一个 ml.p5.48xlarge 实例,用于为期一周的评估,从一月底开始。使用 search-training-plan-offerings API,他们指定了实例类型、实例数量、时长和时间窗口。将目标资源设置为“endpoint”会将容量配置为专门用于推理,而不是训练作业。
# 列出具有实例类型、实例数量、
# 时长(小时)、开始时间晚于、结束时间早于的训练计划产品。
aws sagemaker search-training-plan-offerings \
--target-resources "endpoint" \
--instance-type "ml.p5.48xlarge" \
--instance-count 1 \
--duration-hours 168 \
--start-time-after "2025-01-27T15:48:14-04:00" \
--end-time-before "2025-01-31T14:48:14-05:00"示例输出
{
"TrainingPlanOfferings": [
{
"TrainingPlanOfferingId": "tpo-SHA-256-hash-value",
"TargetResources": ["endpoint"],
"RequestedStartTimeAfter": "2025-01-21T12:48:14.704000-08:00",
"DurationHours": 168,
"DurationMinutes": 10080,
"UpfrontFee": "xxxx.xx",
"CurrencyCode": "USD",
"ReservedCapacityOfferings": [
{
"InstanceType": "ml.p5.48xlarge",
"InstanceCount": 1,
"AvailabilityZone": "us-west-2a",
"DurationHours": 168,
"DurationMinutes": 10080,
"StartTime": "2025-01-27T15:48:14-04:00",
"EndTime": "2025-01-31T14:48:14-05:00"
}
]
}
]
}
响应提供了有关每个可用容量块的详细信息,包括实例类型、数量、时长、可用区和定价。每个产品都包含特定的开始和结束时间,因此您可以选择与部署计划一致的预留。在本例中,团队在 us-west-2a 找到了一个 168 小时(7 天)的预留,符合其时间表。
在确定合适的产品后,团队创建训练计划预留以确保容量:
aws sagemaker create-training-plan \
--training-plan-offering-id "tpo-SHA-256-hash-value" \
--training-plan-name "p4-for-inference-endpoint"示例输出:
{
"TrainingPlanArn": "arn:aws:sagemaker:us-east-1:123456789123:training-plan/p4-for-inference-endpoint"
}
TrainingPlanArn 唯一标识了预留的容量。请保存此 ARN,它是将端点连接到固定的 p 系列 GPU 容量的关键。预留确认并付款后,他们就可以配置推理端点了。
使用 SageMaker AI 控制台
您也可以通过 SageMaker AI 控制台创建训练计划。这提供了一个可视化界面来搜索容量并完成预留。控制台工作流程包含三个步骤:搜索产品,添加计划详情,以及审阅和购买。
导航到训练计划:
- 在 SageMaker AI 控制台中,在左侧导航窗格中导航至 模型训练与自定义。
- 选择 训练计划。
- 选择 创建训练计划(右上角的橙色按钮)。
下图显示了训练计划着陆页,您可以在此启动创建工作流程。
图 1:带有创建训练计划按钮的训练计划着陆页
步骤 A – 搜索训练计划产品:
- 在 目标 下,选择 推理端点。
- 在 计算类型 下,选择 实例。
- 选择您的 实例类型(例如,
ml.p5.48xlarge)和 实例数量。 - 在 日期和时长 下,指定开始日期和时长。
- 选择 查找训练计划。
下图显示了已选择“推理端点”作为目标的搜索界面,并已填写了条件:
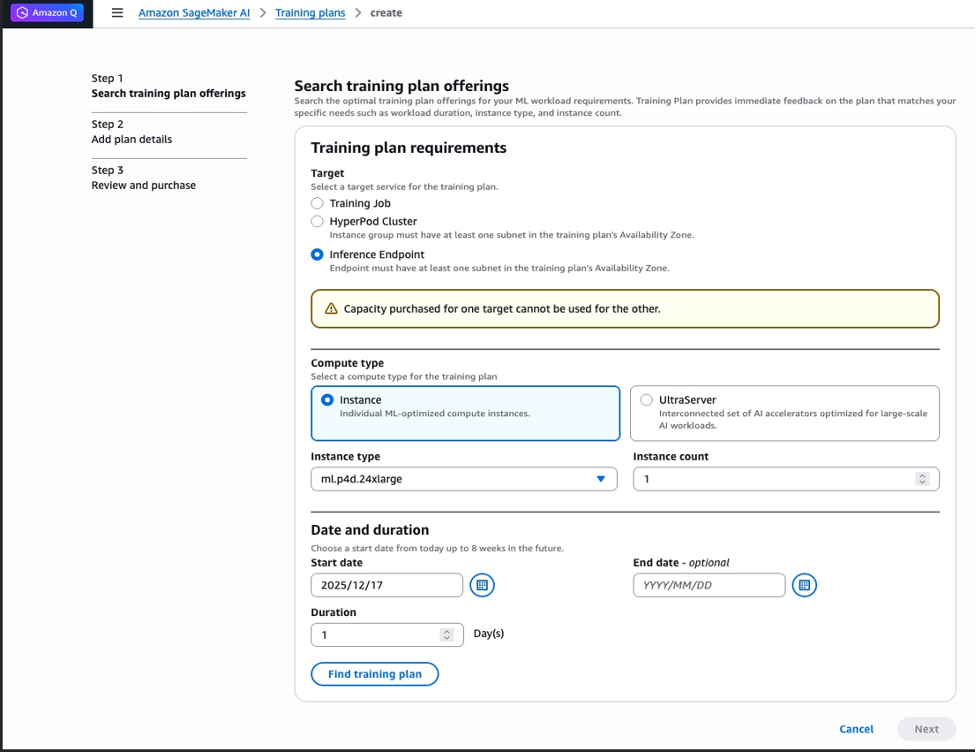
图 2:步骤 A – 搜索训练计划产品,目标为推理端点
选择 查找训练计划 后,“可用计划”部分将显示匹配的产品:
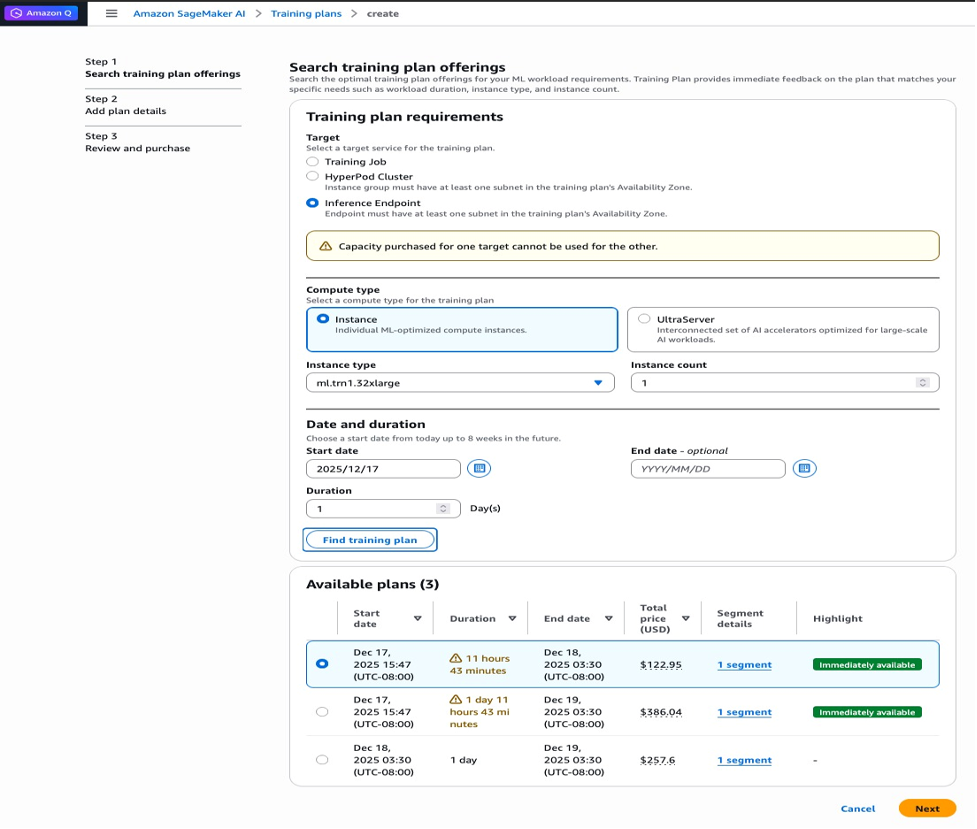
图 3:显示定价和可用性详细信息的可用训练计划产品
完成预留:
- 通过选择首选产品旁边的单选按钮来选择一个计划。
- 选择 下一步 以进入 步骤 B:添加计划详情。
- 审阅详细信息并选择 下一步 以进入 步骤 3:审阅和购买。
- 审阅最终摘要,接受条款,然后选择 购买 以完成预留。
创建预留后,您将收到一个训练计划 ARN。预留确认并付款后,您就可以使用此 ARN 配置推理端点了。端点仅在训练计划中指定的预留窗口期间运行。
步骤 2:创建包含训练计划预留的端点配置
在预留就绪后,团队会创建一个端点配置,将他们的推理端点绑定到预留的容量。这里的关键步骤是在 ProductionVariants 部分包含 CapacityReservationConfig 对象,并将 MlReservationArn 设置为之前收到的训练计划 ARN:
--endpoint-config-name "ftp-ep-config" \
--production-variants '[{
"VariantName": "AllTraffic",
"ModelName": "my-model",
"InitialInstanceCount": 1,
"InstanceType": "ml.p5.48xlarge",
"InitialVariantWeight": 1.0,
"CapacityReservationConfig": {
"CapacityReservationPreference": "capacity-reservations-only",
"MlReservationArn": "arn:aws:sagemaker:us-east-1:123456789123:training-plan/p4-for-inference-endpoint"
}
}]'
当 SageMaker AI 收到此请求时,它会验证 ARN 是否指向一个具有“endpoint”目标资源类型的活动训练计划预留。如果验证成功,则会创建端点配置,并使其可以进行部署。CapacityReservationPreference 设置尤为重要。将其设置为 capacity-reservations-only,团队将端点限制在其预留的容量内,因此当预留结束时,端点将停止提供流量,从而防止意外收费。
步骤 3:在预留的容量上部署端点
端点配置就绪后,团队即可部署其评估端点:
aws sagemaker create-endpoint \
--endpoint-name "my-endpoint" \
--endpoint-config-name "ftp-ep-config"端点现在完全在预留的训练计划容量内运行。SageMaker AI 将在 us-west-2a 中预配 ml.p5.48xlarge 实例并加载模型,此过程可能需要几分钟。在端点达到 InService 状态后,团队就可以开始其评估工作负载了。
步骤 4:在训练计划活动期间调用端点
端点已投入使用后,您可以开始运行评估工作负载。他们调用端点进行实时推理,发送测试提示并测量响应质量、延迟和吞吐量:
aws sagemaker-runtime invoke-endpoint \
--endpoint-name "my-endpoint" \
--body fileb://input.json \
--content-type "application/json"
Output.json在活动预留窗口期间,端点将使用固定的容量正常运行。所有调用都使用预留的资源进行处理,有助于实现可预测的性能和可用性。团队可以运行其基准测试,而无需担心容量限制或共享基础设施的性能差异。
步骤 5:在训练计划过期时调用端点
了解训练计划预留过期但端点仍部署时会发生什么情况很有价值。
当预留过期时,端点的行为取决于 CapacityReservationPreference 设置。由于团队将其设置为 capacity-reservations-only,因此端点将停止提供流量,并且调用将因容量错误而失败:
aws sagemaker-runtime invoke-endpoint \
--endpoint-name "my-endpoint" \
--body fileb://input.json \
--content-type "application/json"
output.json预期错误响应:
Expected error response:
{
"Error": {
"Code": "ModelError",
"Message": "Endpoint capacity reservation has expired. Please update endpoint configuration."
}
}
要恢复服务,您必须创建一个新的训练计划预留并更新端点配置,或更新端点以使用按需或 ODCR 容量。在团队的案例中,由于他们完成了评估,因此删除端点而不是延长预留。
步骤 6:更新端点
在评估期间,您可能出于各种原因需要更新端点。SageMaker AI 支持多种更新场景,同时保持与预留容量的连接。
更新到新的模型版本
在评估中期,团队希望测试一个包含额外微调的新模型版本。他们可以在保留相同预留容量的同时更新到新模型版本:
# 首先,创建一个包含更新模型的新端点配置
aws sagemaker create-endpoint-config \
--endpoint-config-name "ftp-ep-config-v2" \
--production-variants '[{
"VariantName": "AllTraffic",
"ModelName": "my-model-v2",
"InitialInstanceCount": 1,
"InstanceType": "ml.p5.48xlarge", "InitialVariantWeight": 1.0, "CapacityReservationConfig": { "CapacityReservationPreference": "capacity-reservations-only", "MlReservationArn": "arn:aws:sagemaker:us-east-1:123456789123:training-plan/p4-for-inference-endpoint" }
}]'
# 然后更新端点
aws sagemaker update-endpoint \
--endpoint-name "my-endpoint" \
--endpoint-config-name "ftp-ep-config-v2"从训练计划迁移到按需容量
如果团队的评估运行时间超出了预期,或者他们希望在预留期结束后将端点过渡到生产用途,他们可以迁移到按需容量:
# 创建不包含训练计划预留的端点配置
aws sagemaker create-endpoint-config \
--endpoint-config-name "ondemand-ep-config" \
--production-variants '[{
"VariantName": "AllTraffic",
"ModelName": "my-model",
"InitialInstanceCount": 1,
"InstanceType": "ml.p5.48xlarge", "InitialVariantWeight": 1.0 }]
'
# 更新端点以使用按需容量
aws sagemaker update-endpoint \
--endpoint-name "my-endpoint" \
--endpoint-config-name "ondemand-ep-config"步骤 7:扩展端点
在某些情况下,团队可以预留比最初部署更多的容量,这使他们能够在需要时灵活地扩展。例如,如果团队预留了两个实例但最初只部署了一个,他们可以在评估期间进行扩展以测试更高的吞吐量场景。
在预留限制范围内扩展
假设团队最初预留了两个 ml.p5.48xlarge 实例,但只用一个实例部署了他们的端点。之后,他们想测试模型在更高并发负载下的性能:
# 创建具有增加实例数量的新配置(在预留范围内)
aws sagemaker create-endpoint-config \
--endpoint-config-name "ftp-ep-config-scaled" \
--production-variants '[{
"VariantName": "AllTraffic",
"ModelName": "my-model",
"InitialInstanceCount": 2,
"InstanceType": "ml.p5.48xlarge", "InitialVariantWeight": 1.0, "CapacityReservationConfig": { "CapacityReservationPreference": "capacity-reservations-only", "MlReservationArn": "arn:aws:sagemaker:us-east-1:123456789123:training-plan/p4-for-inference-endpoint" }
}]
aws sagemaker update-endpoint \
--endpoint-name "my-endpoint" \
--endpoint-config-name "ftp-ep-config-scaled"尝试超出预留范围的扩展
如果客户尝试超出预留的容量进行扩展,更新将失败:
# 如果预留只有 2 个实例,这将失败
aws sagemaker create-endpoint-config \
--endpoint-config-name "ftp-ep-config-over-limit" \
--production-variants '[{
"VariantName": "AllTraffic",
"ModelName": "my-model",
"InitialInstanceCount": 3,
"InstanceType": "ml.p5.48xlarge", "InitialVariantWeight": 1.0, "CapacityReservationConfig": { "CapacityReservationPreference": "capacity-reservations-only", "MlReservationArn": "arn:aws:sagemaker:us-east-1:123456789123:training-plan/p4-for-inference-endpoint" }
}]
预期错误:
{
"Error": {
"Code": "ValidationException",
"Message": "Requested instance count (3) exceeds reserved capacity (2) for training plan."
}
}
步骤 8:删除端点
在完成为期一周的评估后,团队收集了所有所需的性能指标,并选择了表现最佳的模型。他们准备清理推理端点。训练计划预留会在预留窗口结束时自动过期。无论您何时删除端点,都会按整个预留期收费。
重要注意事项:
请注意,删除端点不会退款或取消训练计划预留。预留的容量将一直分配,直到训练计划预留窗口过期,无论端点是否仍在运行。但是,如果预留仍然有效且容量可用,您可以使用相同的训练计划预留 ARN 创建一个新端点。要完全清理,请删除端点配置:
aws sagemaker delete-endpoint-config \
--endpoint-config-name "ftp-ep-config"在设置训练计划预留时,请记住,您将承诺一个固定的时间窗口,并预先支付整个期间的费用,无论您实际使用多长时间。购买前,请确保您估算的时间表与您选择的预留时长相符。如果您认为评估可能提前完成,成本也不会改变。
例如,如果您购买了为期 7 天的预留,即使您在五天内完成工作,您也需要支付全部七天的费用。好处是这种可预测的、预先确定的成本结构有助于您准确地为项目进行预算。在开始之前,您将确切地知道自己的花费。
注意:删除端点不会取消或退款训练计划预留。预留的容量会一直分配,直到预留窗口过期。如果您提前完成并希望使用剩余时间,并且预留仍然有效且容量可用,您可以重新部署一个使用相同训练计划预留 ARN 的新端点。
结论
SageMaker AI 训练计划提供了一种简单的方法来预留 p 系列 GPU 容量,并部署具有固定可用性的 SageMaker AI 推理端点。这种方法推荐用于有时间限制的工作负载,如模型评估、有限生产测试和需要可预测容量的突发场景。
正如我们在数据科学团队的旅程中所见,该过程包括确定容量需求、搜索可用产品、创建预留,并在端点配置中引用该预留以在预留窗口期间部署端点。该团队在固定的容量下完成了为期一周的模型评估,避免了高峰时段按需可用性的不可预测性。他们可以专注于评估指标,而不必担心基础设施限制。
通过支持端点更新、在预留限制范围内进行扩展以及无缝迁移到按需容量,训练计划使您能够在保持对 GPU 可用性和成本的控制的同时管理推理工作负载。无论您是运行竞争性模型基准测试、执行有限时间的 A/B 测试,还是处理可预测的流量高峰,用于推理端点的训练计划都能以透明、预先确定的价格提供您所需的容量。
致谢
特别感谢 Alwin (Qiyun) Zhao、Piyush Kandpal、Jeff Poegel、Qiushi Wuye、Jatin Kulkarni、Shambhavi Sudarsan 和 Karan Jain 的贡献。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区