



📢 转载信息
原文链接:https://www.kdnuggets.com/5-time-series-foundation-models-you-are-missing-out-on
原文作者:Abid Ali Awan
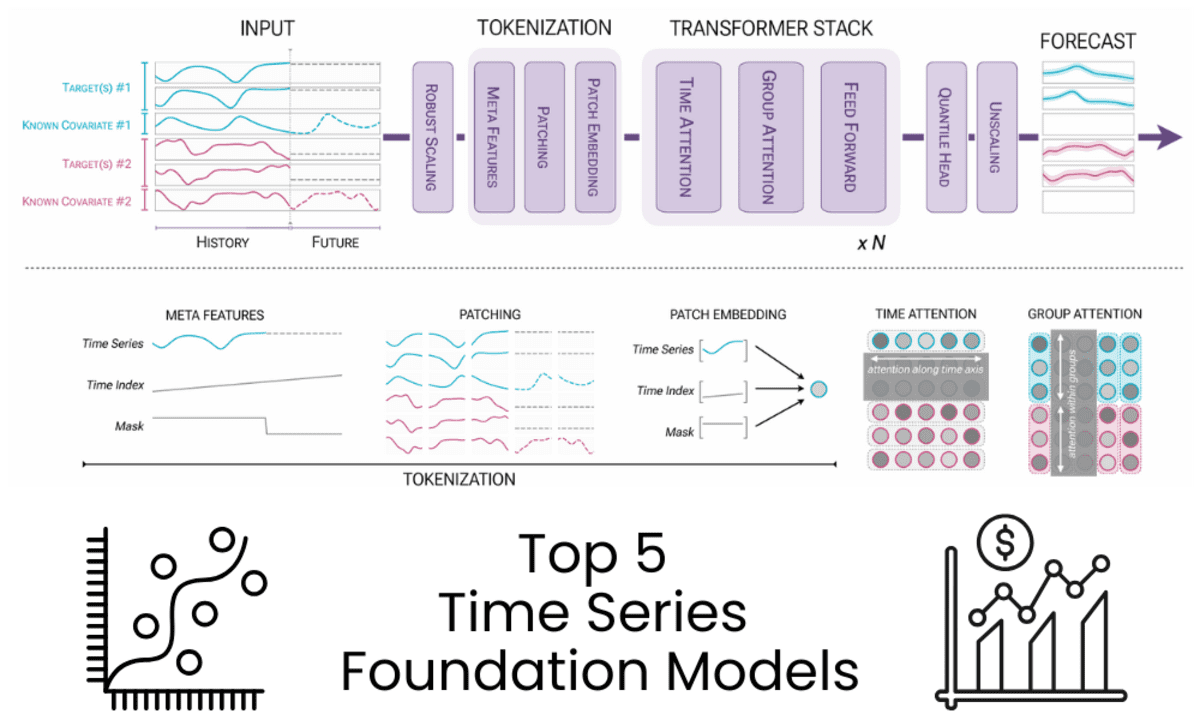
作者:Abid Ali Awan | 图表来源:Chronos-2: From Univariate to Universal Forecasting
# 引言
基础模型并非始于ChatGPT。早在大型语言模型流行之前,预训练模型就已经在计算机视觉和自然语言处理领域推动了进展,包括图像分割、分类和文本理解。
同样的方法现在正在重塑时间序列预测。时间序列基础模型不再需要为每个数据集构建和调优一个单独的模型,而是基于大型且多样化的时间数据集合进行预训练。它们能够在不同领域、不同频率和不同时间范围内提供强大的零样本预测性能,其表现往往可以与那些仅使用历史数据作为输入就需要数小时训练的深度学习模型相媲美。
如果你仍然主要依赖经典的统计方法或单数据集深度学习模型,那么你可能正在错过构建预测系统的重大转变。
在本教程中,我们将回顾五种时间序列基础模型,这些模型是根据性能、Hugging Face下载量衡量的流行度以及实际可用性挑选出来的。
# 1. Chronos-2
Chronos-2是一个拥有1.2亿参数的、仅编码器(encoder-only)的时间序列基础模型,专为零样本预测而构建。它在一个单一架构中支持单变量、多变量和协变量信息预测,无需特定任务训练即可提供准确的多步概率预测。
关键特性:
- 受T5启发的仅编码器架构
- 带有分位数输出的零样本预测
- 对过去和已知未来协变量的原生支持
- 长上下文长度最高可达8,192,预测时间跨度最高可达1,024
- 高效的CPU和GPU推理,高吞吐量
用例:
- 跨多个相关时间序列的大规模预测
- 面向需求的预测,如需求、能源和定价
- 无需模型训练即可快速原型设计和生产部署
最佳用例:
- 生产预测系统
- 研究和基准测试
- 带有协变量的复杂多变量预测
# 2. TiRex
TiRex是一个拥有3500万参数的预训练时间序列预测模型,基于xLSTM构建,旨在实现长短期预测的零样本预测。它无需在特定任务数据上进行任何训练即可生成准确的预测,并能即时提供点预测和概率预测。
关键特性:
- 预训练的xLSTM架构
- 无需数据集特定训练的零样本预测
- 点预测和基于分位数的(probabilistic)不确定性估计
- 在长短期基准测试中表现强劲
- 可选的CUDA加速,用于高性能GPU推理
用例:
- 针对新时间序列数据集的零样本预测
- 金融、能源和运营领域的长期和短期预测
- 无需模型训练的快速基准测试和部署
# 3. TimesFM
TimesFM是Google Research开发的一个预训练时间序列基础模型,用于零样本预测。其开源检查点timesfm-2.0-500m是一个仅解码器(decoder-only)模型,专为单变量预测设计,支持长历史上下文和灵活的预测时间跨度,无需特定任务训练。
关键特性:
- 拥有5亿参数的仅解码器基础模型
- 零样本单变量时间序列预测
- 上下文长度最长可达2,048个时间点,并支持超出训练限制的范围
- 灵活的预测时间跨度,并带有可选的频率指示器
- 优化用于大规模的快速点预测
用例:
- 跨多样化数据集的大规模单变量预测
- 用于运营和基础设施数据的长期预测
- 无需模型训练的快速实验和基准测试
# 4. IBM Granite TTM R2
Granite-TimeSeries-TTM-R2是IBM Research在TinyTimeMixers (TTM)框架下开发的一系列紧凑型预训练时间序列基础模型。这些模型专为多变量预测而设计,尽管模型大小小至100万参数,但仍能实现强大的零样本和少样本性能,使其适用于研究和资源受限的环境。
关键特性:
- 参数量从100万起步的微型预训练模型
- 强大的零样本和少样本多变量预测性能
- 针对特定上下文和预测长度定制的模型
- 在单个GPU或CPU上实现快速推理和微调
- 支持外生变量和静态分类特征
用例:
- 低资源或边缘环境下的多变量预测
- 带有可选轻量级微调的零样本基线
- 有限数据下的快速部署以进行操作预测
# 5. Toto Open Base 1
Toto-Open-Base-1.0是一个仅解码器的(decoder-only)时间序列基础模型,专为可观测性和监控场景中的多变量预测而设计。它针对高维、稀疏和非平稳数据进行了优化,并在GIFT-Eval和BOOM等大规模基准测试中展现出强大的零样本性能。
关键特性:
- 用于灵活的上下文和预测长度的仅解码器Transformer
- 无需微调的零样本预测
- 高效处理高维多变量数据
- 使用Student-T混合模型进行概率预测
- 在超过2万亿个时间序列数据点上进行了预训练
用例:
- 可观测性和监控指标预测
- 高维系统和基础设施遥测
- 大规模、非平稳时间序列的零样本预测
总结
下表比较了所讨论的时间序列基础模型的核心特征,重点关注模型大小、架构和预测能力。
| 模型 | 参数量 | 架构 | 预测类型 | 关键优势 |
|---|---|---|---|---|
| Chronos-2 | 120M | 仅编码器 | 单变量、多变量、概率性 | 强大的零样本准确性,长上下文和时间跨度,高推理吞吐量 |
| TiRex | 35M | 基于xLSTM | 单变量、概率性 | 轻量级模型,在短、长期预测中表现强劲 |
| TimesFM | 500M | 仅解码器 | 单变量、点预测 | 可大规模处理长上下文和灵活的时间跨度 |
| Granite TimeSeries TTM-R2 | 1M–小型 | 定制化预训练模型 | 多变量、点预测 | 极其紧凑,推理速度快,零样本和少样本结果强劲 |
| Toto Open Base 1 | 151M | 仅解码器 | 多变量、概率性 | 针对高维、非平稳的可观测性数据进行了优化 |
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学家专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为在心理健康方面遇到困难的学生构建一个AI产品。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区