



📢 转载信息
原文作者:Lauren Mullennex, Eric Saleh, Surya Kari
AI Agent 的核心价值在于其工具调用能力。正是通过调用工具,它们才能查询数据库、触发工作流、检索实时数据并代表用户执行操作。然而,基础模型经常会产生“幻觉”,调用并不存在的工具、传递错误的参数,或者在应当询问澄清问题时尝试执行操作。这些故障削弱了信任,阻碍了生产环境的部署。
现在,您可以使用 Amazon SageMaker AI 中的无服务器模型定制功能解决这些问题,而无需管理底层基础设施。通过带可验证奖励的强化学习(RLVR),模型能够生成候选响应,接收评估其质量的奖励信号,并更新其行为以倾向于表现更好的输出。您只需选择模型、配置技术、指定数据和奖励函数,SageMaker AI 即可处理后续所有工作。
在本文中,我们将探讨如何使用 RLVR 对 Qwen 2.5 7B Instruct 模型进行工具调用微调。通过本教程,您将掌握数据集准备、分级奖励函数设计、训练配置及评估方法。最终,我们的微调模型在未见过的工具场景中,工具调用奖励分数提升了 57%。
为什么工具调用适合 RLVR?
传统的有监督微调(SFT)需要针对每种行为准备大量标注示例。然而,工具调用不仅要求模型掌握调用格式,还要求其在调用、澄清和拒绝之间做出决策,而 SFT 在泛化此类决策时往往表现不佳。
RLVR 的工作方式完全不同。对于每个提示,模型会生成多个候选响应(本例中为 8 个)。奖励函数会验证哪些是正确的。随后,模型通过组相对策略优化(GRPO)更新策略,加强那些高于平均奖励水平的响应。随着时间的推移,模型能自动学会正确的工具调用格式,并识别何时应该调用、何时应该询问。
微调步骤概览
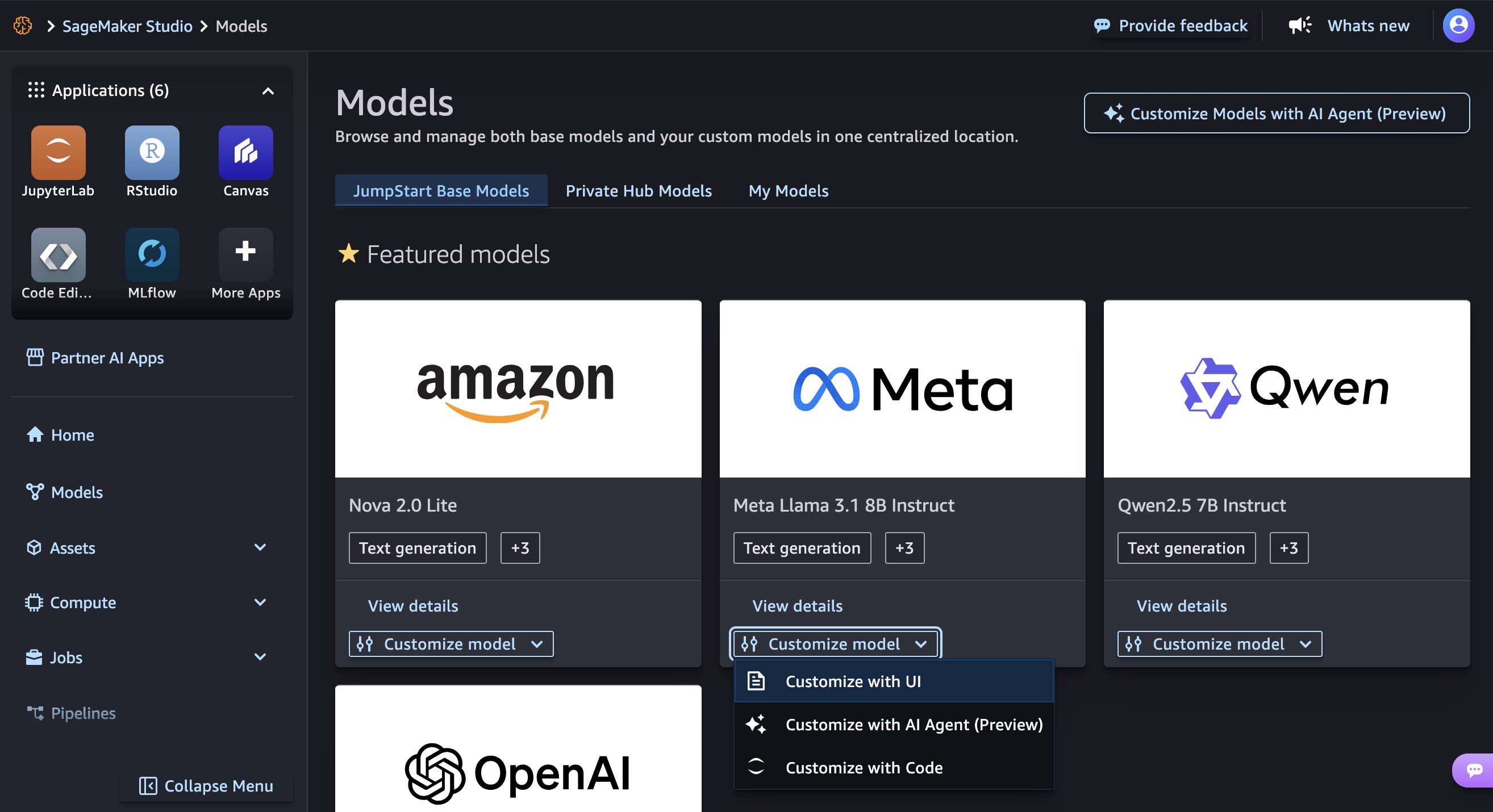
在 Amazon SageMaker AI Studio 中,您可以轻松浏览并选择支持的模型(如 Qwen 2.5 7B),在 Customize model(定制模型) 菜单中选择 Customize with UI(通过 UI 定制),并选择 Reinforcement Learning from Verifiable Rewards (RLVR) 技术进行配置。
准备训练数据
高质量的工具调用数据集需要涵盖三种核心情境:
- 执行(Execute):用户提供了所有必要信息,模型应直接调用工具。
- 澄清(Clarify):请求缺少必要参数,模型应询问用户以获取更多信息。
- 拒绝(Refuse):请求有害或超出范围,模型应予以礼貌拒绝。
我们使用 Amazon 的 AI 助手 Kiro 生成了 1,500 条合成数据,涵盖了天气查询、航班搜索、翻译等五种工具模式。这种方法对于缺乏生产日志的团队非常实用。
定义奖励函数
奖励函数是 RLVR 的核心。它接收模型的响应和参考答案,返回一个数值分数。我们采用了分级评分逻辑(1.0, 0.5, 0.0),这能为 GRPO 提供更丰富的反馈信号,帮助模型理解即便未能完全正确,只要方向正确(如函数调用对了但参数有误)也是有价值的。
训练与结果
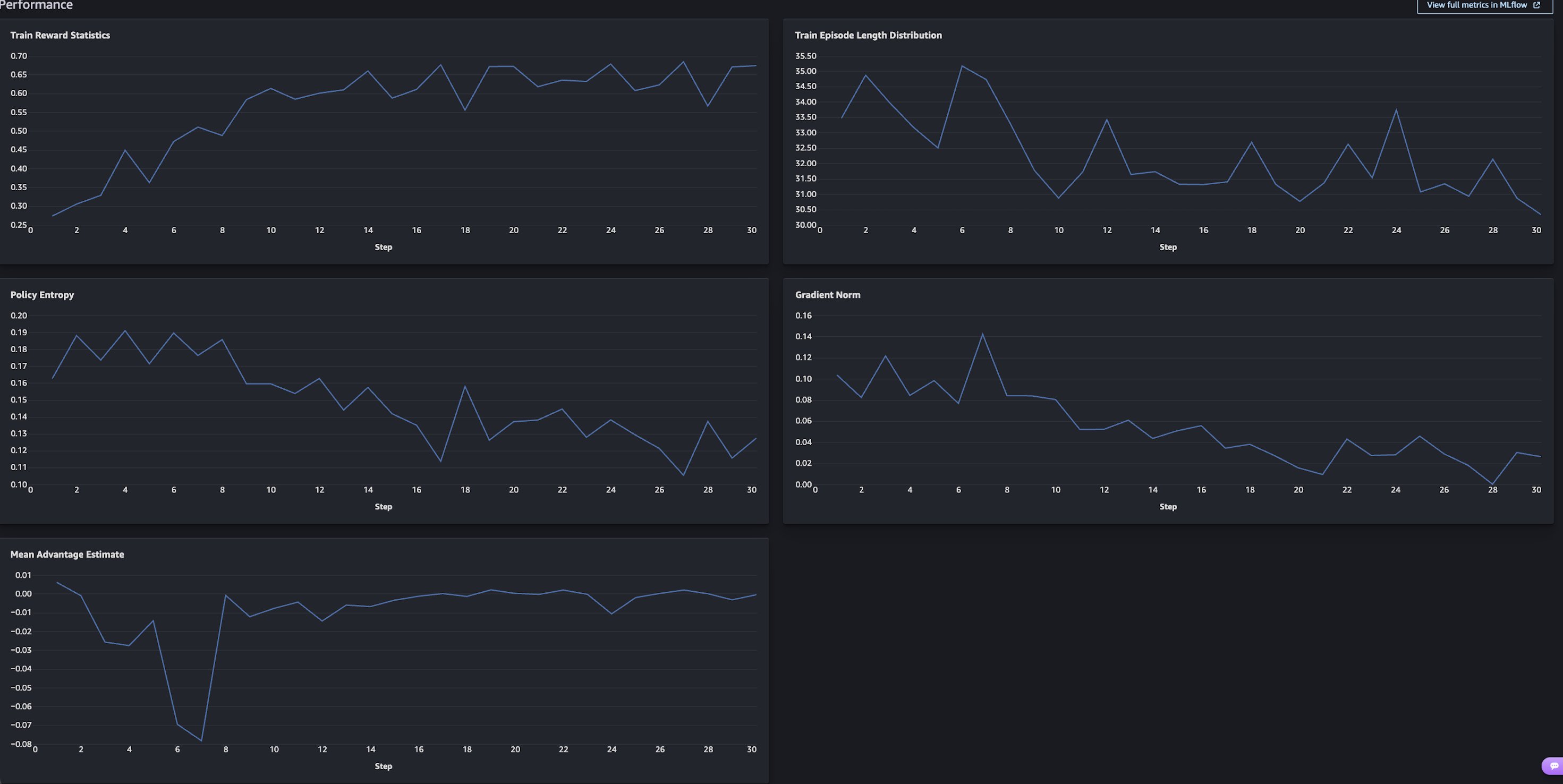
通过训练,平均奖励分数从 0.28 稳步攀升至 0.68。评估显示,在未见过的测试集上,工具调用奖励分数从 0.35 提升至 0.55,整体准确性显著增强,且模型表现出了强大的通用性。
结论
通过 Amazon SageMaker AI 的无服务器模型定制,您可以快速构建具备强大工具调用能力的 Agent。RLVR 不仅适用于工具调用,还可扩展至多步规划、结构化数据提取等逻辑推理任务。立即尝试,为您的大模型构建更聪明、更可靠的“行动力”。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区