



📢 转载信息
原文链接:https://www.ithome.com/0/890/485.htm
原文作者:故渊
IT之家 10 月 18 日消息,据《南华早报》今日报道,在韩国首尔举办的第 31 届操作系统原理研讨会(SOSP)上,阿里云发布的“Aegaeon”计算池化解决方案研究成果成功入选,该方案旨在解决 AI 模型服务中普遍存在的 GPU 资源浪费问题。
IT之家查询公开资料了解到,SOSP 是计算机操作系统领域的顶尖会议,被誉为计算机操作系统界的“奥斯卡”,其录取率极为严格,每年收录的论文数量仅数十篇,入选论文代表了操作系统和软件领域最具代表性的研究成果。
报道指出,云服务商在提供 AI 模型服务时,正面临着严峻的资源效率低下问题。平台需要同时托管数千个 AI 模型以处理海量的并发 API 调用,但用户请求往往高度集中在少数几个热门模型上,例如阿里巴巴的 Qwen 系列模型。
研究人员发现,这种“长尾效应”导致了严重的资源闲置:在阿里云的模型市场中,竟有 17.7% 的 GPU 算力仅被用于处理 1.35% 的请求,造成了巨大的成本浪费。
为解决这一痛点,Aegaeon 系统应运而生。它通过创新的 GPU 资源池化技术,允许单个 GPU 动态服务于多个不同的 AI 模型,打破了以往 GPU 与特定模型绑定的低效模式。
在阿里云模型市场进行的为期超过三个月的 Beta 测试中,Aegaeon 系统展现了卓越的效能。测试数据显示,服务数十个参数量高达 720 亿的大模型时,所需的英伟达 H20 GPU 数量从 1192 个成功减少至 213 个,数量削减高达 82%。
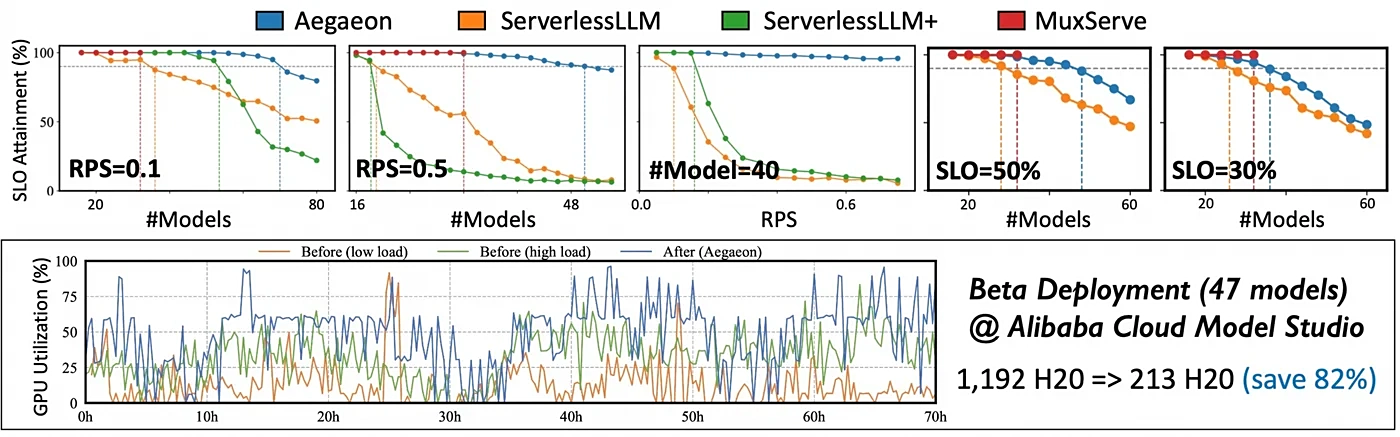
这项由北京大学与阿里云合作的研究成果,被认为是“首个揭示并解决市场上并发大语言模型服务存在过高成本”的公开工作,为行业提供了全新的优化思路。
值得一提的是,阿里云首席技术官周靖人也是该论文的作者之一。周靖人是国际电气与电子工程师协会会士(IEEE Fellow),国际计算机协会会士(ACM Fellow),阿里巴巴集团副总裁,阿里云智能 CTO、达摩院副院长。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区