



📢 转载信息
原文链接:https://www.nature.com/articles/s41586-026-10179-2
原文作者:Ahmed A. Metwally, A. Ali Heydari, Daniel McDuff, Alexandru Solot, Zeinab Esmaeilpour, Anthony Z. Faranesh, Menglian Zhou, Girish Narayanswamy, Maxwell A. Xu, Xin Liu, Yuzhe Yang, David B. Savage, Mark Malhotra, Conor Heneghan, Shwetak Patel, Cathy Speed, Javier L. Prieto
摘要
胰岛素抵抗(IR)是2型糖尿病的主要前期病变,其特征是组织对胰岛素的作用受损1。然而,诊断方法仍然昂贵且不易获得,这阻碍了早期干预2,3。我们在此介绍了WEAR-ME研究,这是一项大型、远程进行的IR研究(n = 1,165名参与者;中位体重指数(BMI)= 28 kg m−2,中位年龄= 45岁,中位血红蛋白A1c(HbA1c)= 5.4%),该研究利用来自可穿戴设备和常规血检指标的时间序列数据,训练深度神经网络来对抗IR的地面真实测量值(稳态模型评估IR;HOMA-IR)。使用HOMA-IR截止值2.9,我们的多模态模型在可穿戴设备数据以及人口统计学和常规血检指标数据的支持下,取得了稳健的表现(接受者操作特征曲线下面积(AUROC)= 0.80,敏感性= 76%,特异性= 84%)。为了增强可穿戴设备时间序列数据的利用,我们对一个在4000万小时传感器数据上预训练的可穿戴设备基础模型(WFM)进行了微调。在一个独立的验证队列(n = 72)中,整合了WFM衍生的表征与人口统计学数据vi的模型,超越了仅使用人口统计学数据的基线模型(AUROC = 0.75 vs 0.66)。此外,与不使用可穿戴设备数据的相同模型相比,将WFM衍生的表征添加到包含人口统计学、空腹血糖和血脂谱的模型中,极大地提高了性能(AUROC = 0.88 vs 0.76)。我们将IR预测整合到一个大型语言模型中,以对结果进行情境化并促进个性化建议。这项工作建立了一个可扩展、易于访问的代谢风险早期检测框架,从而能够及时进行生活方式干预,以防止进展为2型糖尿病。
主要内容
目前,全球有5.37亿成年人患有糖尿病,预计到2030年将增至6.43亿。约10%的糖尿病患者患有1型糖尿病(T1D),约90%患有2型糖尿病(T2D)4。T2D的上升主要是由生活方式因素驱动的5。在健康的个体中,胰岛素——一种由胰腺β细胞分泌的激素——通过促进葡萄糖从血液进入细胞(包括肌肉、脂肪和肝脏)来帮助调节血糖水平。此外,肠促胰岛素激素,如胰高血糖素样肽-1(GLP1)和胃抑制多肽(GIP),可以增加胰腺β细胞的胰岛素分泌,从而改善血糖控制6。糖尿病的基本问题是身体由于绝对或相对胰岛素缺乏而无法正确调节血糖。在T1D中,身体的免疫系统错误地攻击并摧毁胰腺β细胞,导致绝对胰岛素缺乏和高血糖7。相比之下,在大多数T2D病例中,身体会产生胰岛素抵抗,这意味着胰腺β细胞需要产生更高剂量的胰岛素才能达到相同的降糖效果。随着时间的推移,胰腺β细胞可能无法产生足够的胰岛素来补偿IR,导致相对胰岛素缺乏和血糖水平升高。 图1a说明了T2D的复杂性质以及导致疾病发生的生活方式选择、遗传因素以及各种代谢亚型和生理过程之间的复杂关系。糖尿病的长期并发症包括随着时间的推移对各种器官和组织的损伤,如糖尿病视网膜病变、肾病和神经病变8。
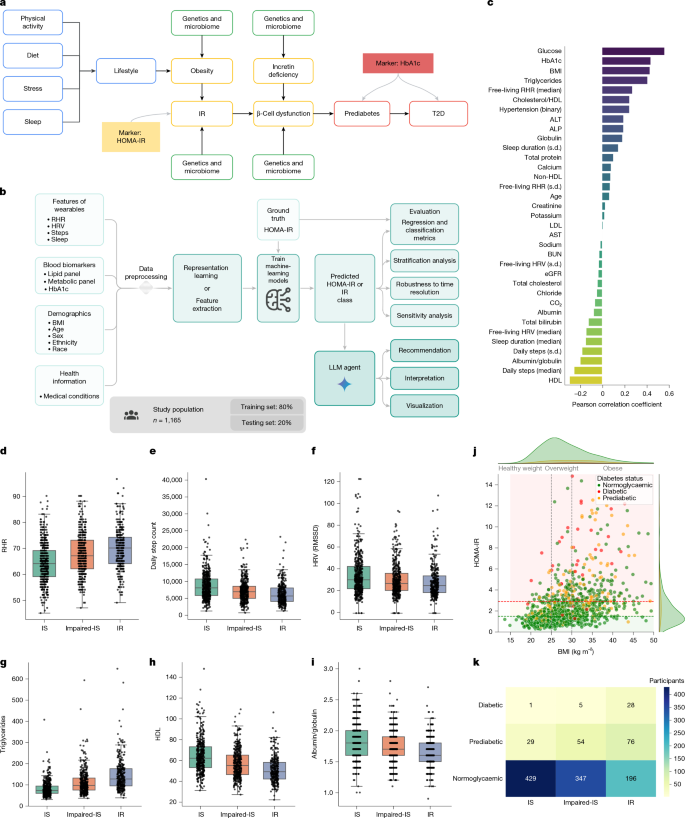
a,导致IR、糖尿病前期和糖尿病的生理因素及相关生活方式因素的概述。b,我们提出的用于预测HOMA-IR和利用胰岛素抵抗知识与理解代理(IR代理)解释结果的建模流程。c,血检指标和生活方式特征(连续值)与HOMA-IR的相关性。d–f,与HOMA-IR高度相关的可穿戴设备前三个特征(RHR(d)、每日步数(e)和HRV(f))在不同胰岛素敏感性组(IS、impaired-IS和IR)中的分布。RMSSD,连续差值均方根。g–i,在不同胰岛素敏感性组中,高度相关的血检指标前三名(甘油三酯(g)、HDL胆固醇(h)和白蛋白/球蛋白比率(i))的分布。在d–i的箱线图中,中心线表示中位数,箱的边界表示25%和75%百分位数,须延伸至四分位距的1.5倍。j,BMI和HOMA-IR值的散点图,显示了较高的BMI值与IR(通过HOMA-IR测量)之间的关系。k,混淆矩阵,显示了IR状态和糖尿病状态组合中的参与者数量。
据估计,普通人群的IR患病率为20%至40%,在不同种族、年龄组、生活方式和合并症的存在下存在差异1。T2D的IR患病率为83.9%(参考文献9)。导致IR的因素包括体重过重(特别是内脏脂肪)、体力活动不足和遗传易感性。长期IR使个体面临患代谢功能障碍相关脂肪肝病(MASLD)和心血管疾病(CVD)的相当大的风险。
早期识别IR可以指导多种集中的生活方式干预,例如减肥、定期锻炼和健康的饮食模式,这些干预可以显著改善甚至逆转IR。尽管大多数人肯定可以从各种类型的体育活动和健康饮食中获益,但特定的干预已被科学证明可以预防和治疗IR。在生活方式干预方面,抗阻训练10,11、有氧训练10、热量限制饮食12和低脂饮食13在降低IR方面都很有价值。在治疗方面,噻唑烷二酮类和二甲双胍等药物已被证明可以减少IR14,15。研究表明,肠促胰岛素激素激动剂,如GLP1和GIP,可以作为增敏剂并改善IR16,17。
有几种方法可用于评估IR,但尚未常规实施,这意味着早期干预的机会常常被错过。相反,关注血糖快照、空腹血糖、HbA1c或口服葡萄糖耐量试验(OGTT)两小时后的血糖水平,代表了典型的筛查方法,并且可能对IR早期阶段的个体不敏感。IR的金标准测试是高胰岛素血症 euglycaemic 钳夹试验2,该试验仅在研究机构进行,且昂贵且耗时。稳态模型评估IR(HOMA-IR)是一种更经济、更快速的替代方法,但需要临床实验室访问3。葡萄糖分型,一种分析连续葡萄糖监测(CGM)数据的葡萄糖时间序列的框架,是检测IR的一种新方法,可以在家进行,但需要进一步的验证研究18,19。从智能手表派生的生理信号可以设想有助于预测IR,因为已有研究表明,较高的静息心率(RHR)和较低的心率变异性(HRV)与IR相关20,21,22,23。
在本研究中,我们提出了一种使用消费者智能手表、人口统计学和常规测量血检指标派生的信号来预测IR的方法。该方法有潜力扩展到数百万人,并实现IR的广泛识别。我们组建了一个大型队列(n = 1,165),其中包含来自可穿戴设备、人口统计学和血检指标的联合数据集,以及IR的地面真实测量值(HOMA-IR)。我们对模型进行了全面的分析,包括互操作性、分层和稳健性分析,以量化其可推广性和可扩展性。此外,我们开发了一个大型语言模型(LLM)代理,该代理使用IR模型的输出,以及参与者的生活方式和血检指标数据,提供安全、全面的个人代谢健康和糖尿病风险洞察,并提供个性化建议和解释性说明。
研究设计和队列特征
我们设计了代谢健康可穿戴设备(WEAR-ME)研究,并招募了来自美国的成年人参与。参与者提供了知情同意,该研究获得了Advarra(机构审查委员会(IRB)编号:Pro00074093)的批准。该研究使用Google Health Studies(GHS)应用程序远程进行(方法)。在此实例中,GHS被配置为能够收集来自Fitbit和Google Pixel手表设备(统称为可穿戴设备)的数据,完成问卷调查,并通过Quest Diagnostics进行血液检测。
我们将HOMA-IR,计算方法为 HOMA-IR = (空腹胰岛素 (µU ml−1) × 空腹血糖 (mg dl−1))/405,作为量化IR的地面真实值(方法)。用于定义IR的HOMA-IR阈值在文献中差异很大,从2.5到3.5(显著IR)和1到1.5(胰岛素敏感性)1,24,25,26。阈值的差异主要归因于研究人群(种族、年龄和性别)以及用于定义阈值的特定因素(最大化代谢综合征预测的敏感性或使用研究人群的第90百分位数)的差异。在本研究中,参与者被分类为IR(HOMA-IR > 2.9)、胰岛素敏感(IS)(HOMA-IR < 1.5)或具有受损胰岛素敏感(impaired-IS)(1.5 ≤ HOMA-IR ≤ 2.9)。扩展数据表 1 总结了我们队列的特征。总共有1,165名具有高质量数据(补充图1)的个体(459名IS,406名impaired-IS,300名IR)被纳入IR模型的开发中。补充图2 显示了WEAR-ME队列中七种不同智能手表和四种追踪器的分布。IR的参与者患有糖尿病、心血管疾病、高脂血症和高血压的发生率更高。补充表1 总结了三组之间的所有数字和血液生物标志物。
图1b 说明了我们用于预测IR的深度学习框架的设计。它将可穿戴设备、血检指标、人口统计学和健康信息等各种数据组合作为输入。时间序列数据经过预处理和汇总,并通过掩码自编码器(MAE)(方法)提取嵌入式表示。该表示被输入到多个基于树的模型中,以预测连续的HOMA-IR值。通过在预测的HOMA-IR上使用HOMA-IR阈值2.9进行阈值处理,获得预测的IR类别(IR或非IR)。我们测试了25种输入特征组合(可穿戴设备特征、人口统计学、空腹血糖、血脂谱、HbA1c、代谢谱和高血压状况)。使用五折交叉验证进行直接回归模型的训练和测试。进行了可解释性分析,以评估特征对学习到的表示和模型性能的贡献(补充信息)。我们对预测的HOMA-IR和IR类别进行了全面的评估,以评估所训练模型的可推广性和可扩展性。此外,我们进行了稳健性和稳定性分析,以评估基于可穿戴设备数据变化时间间隔(一周、两周和长达三个月)的每个个体输出的可变性(补充信息)。
IR与生活方式和血检指标的关联
我们计算了HOMA-IR与主要生活方式因素(RHR、HRV、步数和睡眠时长)、人口统计学、血脂、血糖、肾功能和肝功能标志物以及关键电解质之间的Pearson相关系数(补充表2)。图1c显示了HOMA-IR与空腹血糖(r = 0.57, P < 0.001)、BMI(r = 0.43, P < 0.001;补充图4)、HbA1c(r = 0.45, P < 0.001)、甘油三酯(r = 0.40, P = < 0.001;图1g)和RHR(r = 0.27, P = < 0.001;图1d)之间存在显著的正相关。此外,HOMA-IR与高密度脂蛋白(HDL)胆固醇(r = −0.30, P < 0.001;图1h)、每日步数(r = −0.25, P = < 0.001;图1e)、白蛋白/球蛋白比率(r = −0.18, P = < 0.001;图1i)和HRV(r = −0.14, P < 0.001;图1f)之间存在显著的负相关。这表明HOMA-IR可以通过可穿戴设备或血检指标中的易于获取的测量值来推断。年龄、肾功能指标(例如,肌酐、估算肾小球滤过率(eGFR)和血尿素氮(BUN))以及电解质(例如,钠、钾和氯)与HOMA-IR的相关性较低(|r| < 0.1)。C反应蛋白(CRP)水平在IR组中高于IS组(2.8 mg dl−1 vs 0.6 mg dl−1, P < 0.001)。标准全血细胞计数(例如,白细胞、红细胞、血红蛋白、红细胞压积等)中的分析物在IR和IS组之间的效应大小没有显著差异(补充表1)。图1j说明了肥胖(通过BMI测量)与IR(通过HOMA-IR评估)之间的关系。在BMI > 30的458名肥胖个体中,有205名(45%)患有胰岛素抵抗(HOMA-IR > 2.9)。在体重正常的319名参与者(18.5 < BMI < 25)中,只有22名(6.9%)患有胰岛素抵抗。图1k突出了IR与糖尿病之间的关系。在WEAR-ME研究队列中,34名糖尿病患者(HbA1c > 6.5%)中有33名(97%)被归类为患有IR或impaired-IS,而只有一名参与者患有IS。值得注意的是,个体可能患有IR而没有HbA1c水平的明显升高。在972名血糖正常的参与者中,有196名(20%)患有IR,代表着发展糖尿病的高风险个体。这突显了早期识别这些个体的重要性,以便进行个性化的生活方式干预,从而可能逆转T2D的发展进程。补充图4 显示了HOMA-IR、可穿戴设备特征、人口统计学和血检指标之间的成对相关性。
使用可穿戴设备和血检指标进行IR预测
我们使用各种可穿戴设备特征、人口统计学和血检指标的组合来训练多模态模型以预测IR。具体来说,我们训练了回归模型来预测连续的HOMA-IR值,然后应用分类阈值来确定IR状态。图2 阐述了使用七天汇总窗口的可穿戴设备特征在所选特征集上的回归性能。图2a 显示了直接回归(XGBoost,线性(L1–L2)和非线性(树)学习器)和表征学习(MAE + XGBoost,线性学习器(L1–L2))的R2值(方法)。我们的结果表明,将来自可穿戴设备的数据以及人口统计信息和易于获取的血检指标纳入模型,可显著提高预测准确性。此外,我们的分析显示真阳性(浅绿色阴影)增加,以及后果严重的假阳性(被预测为IR但实际上是IS的参与者;图2b–e 中的浅棕色阴影区域)减少。最值得注意的是,仅添加空腹血糖就使R2值翻倍,从0.212增至0.435(图2d),使正确识别的IR参与者数量增加了17%(从184名增至216名),并将后果严重的假阳性(被识别为IR但实际上是IS的参与者)减少了46%(从48名减少至26名)。与此同时,我们的实验表明,仅使用空腹血糖是不够的(R2 = 0.31),这突显了其他生活方式因素在估计HOMA-IR中的重要性。预测HOMA-IR的最佳模型结合了来自可穿戴设备、人口统计学和易于获取的血检指标(空腹血糖、血脂谱和代谢谱)的数据(R2 = 0.50;图2e)。
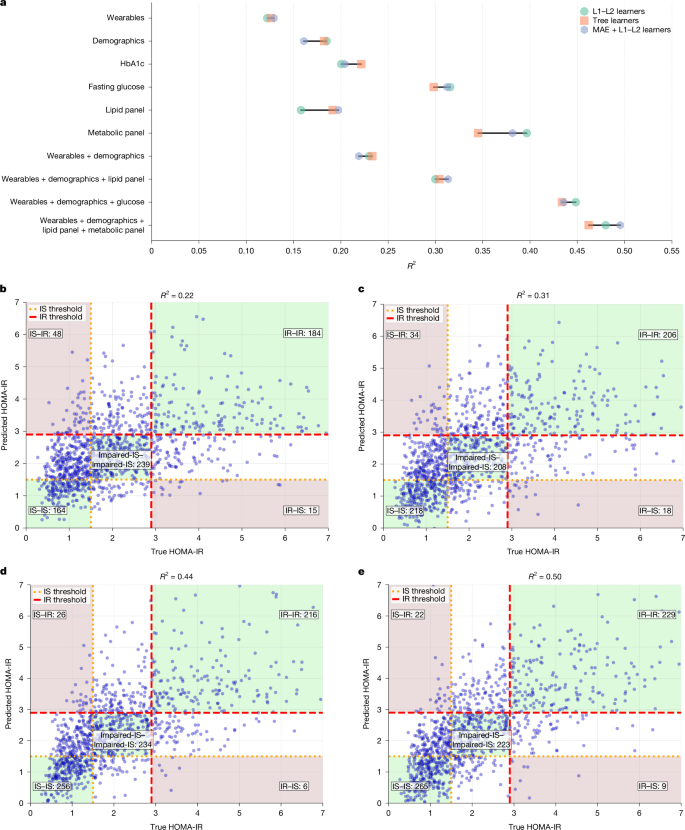
a,不同输入特征集和模型的HOMA-IR回归比较。b–e,预测HOMA-IR值与真实HOMA-IR模型在选定特征集上的散点图:可穿戴设备和人口统计学(b),可穿戴设备、人口统计学和血脂谱(c),可穿戴设备、人口统计学和空腹血糖(d),以及可穿戴设备、人口统计学、血脂谱和代谢谱(e)。真实阳性和假阴性的担忧区域分别以浅绿色和浅棕色突出显示。
随后,我们使用HOMA-IR阈值2.9对模型准确分类IR的能力进行了严格评估。扩展数据图1a显示,仅基于可穿戴设备和人口统计学的模型可以以AUROC = 0.70,敏感性= 0.60和特异性= 0.80预测IR。将空腹血糖水平纳入此模型导致性能显著提高(AUROC = 0.78,敏感性= 0.73,特异性= 0.84)。包含可穿戴设备、人口统计学、易于获取的血检指标(血脂谱和代谢谱)的模型产生的AUROC值为0.80,敏感性= 0.76,特异性= 0.84。至关重要的是要强调,仅依赖人口统计学、可穿戴设备、空腹血糖或血脂谱不足以获得IR的充分预测能力(扩展数据图1a和补充信息)。在补充表3–6 中提供了实验设置、性能基准和消融分析的全面总结。补充表7 和 8 分别报告了通过Wilcoxon秩和检验和McNemar检验确定的每对实验之间AUROC差异的统计显著性。为了进一步阐明模型在各种预测HOMA-IR阈值下的性能,扩展数据图1b,c 分别展示了可从可用数据中实际实现的四个特征集的ROC曲线和精确率-召回率曲线。我们的研究结果表明,与单独依赖每种数据源相比,整合来自可穿戴设备、人口统计学和易于获取的血检指标的数据显著增强了我们预测IR的能力。模型学到的表示和预测模型的可解释性在扩展数据图2、补充表9 和补充信息 中有所展示,以及基于BMI和体力活动的IR预测的分层性能分析。
使用可穿戴设备基础模型进行IR预测
随后,我们采用整体方法对可穿戴设备数据进行建模,使用基础模型来学习复杂数据的稳健高维特征表示。基础模型已成为科学分析的关键工具,因为它们提供了一种方法,可以通过预训练的预文本任务,从无标签示例中学习复杂数据的稳健高维特征表示27,28。我们研究了在大量可穿戴设备数据上训练的基础模型是否能提高IR预测能力。我们预训练的WFM从每分钟分辨率的可穿戴设备输入数据中提取表示。输入窗口大小为一天(1,440分钟)×26个信号(方法)。鉴于每位参与者都有数天的可穿戴设备数据,我们使用中位数池化为每位参与者生成一个单一嵌入。这些嵌入的维度为384。为了降低维度,在训练集上拟合了主成分分析,并将映射应用于测试集。使用来自中位数池化、冻结的可穿戴信号嵌入的前五个主成分用于IR预测的下游任务。然后,我们在基础模型的可穿戴设备信号嵌入的前五个主成分上微调了一个非线性分类头(图3a)。
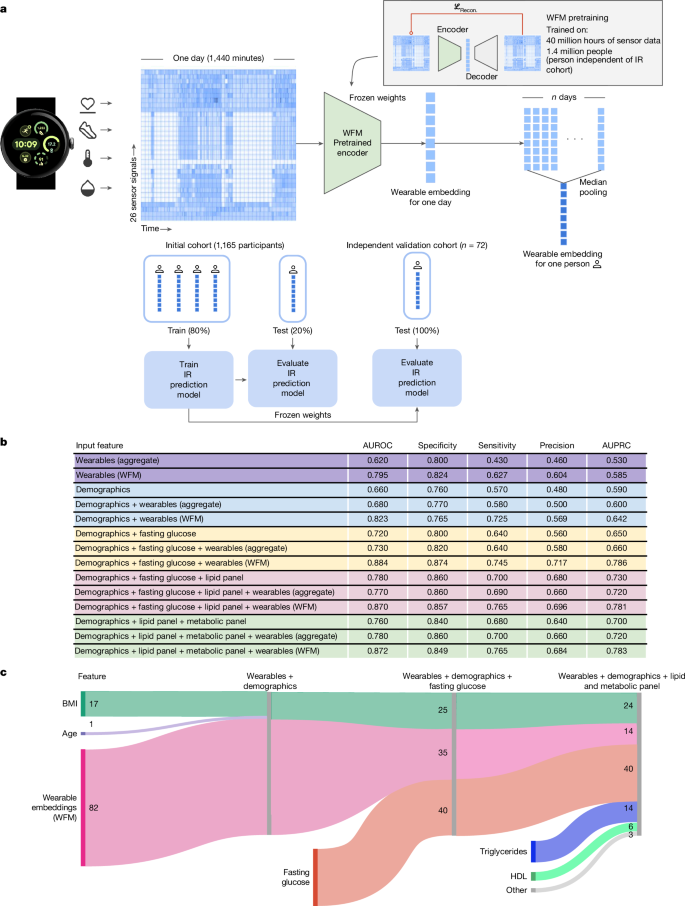
a,WFM预训练和推理组件的示意图。L Recon.,重构损失。b,量化WFM在改进IR预测中的附加值的性能指标。AUPRC,精确率-召回率曲线下面积。c,SHAP分析量化了WFM的可穿戴设备嵌入对各种实验设置预测性能的相对贡献。
使用t... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区