



📢 转载信息
原文作者:Shashank Jain, Jeff Li, and Ranjith Kurumbaru Kandiyil
企业面临着日益严峻的挑战:客户需要快速获得答案,但支持团队不堪重负。产品手册和知识库文章等支持文档通常要求用户搜索数百页的内容,而支持人员每天需要处理 20 到 30 个客户查询才能找到特定信息。
本文将演示如何使用 Amazon Bedrock 和 Amazon Bedrock Knowledge Bases 构建一个 AI 驱动的网站助手来解决这一挑战。此解决方案旨在使内部团队和外部客户都受益,并可提供以下优势:
- 为客户提供即时、相关的答案,从而无需搜索文档
- 为支持人员提供强大的知识检索系统,缩短解决时间
- 全天候的自动化支持
解决方案概述
该解决方案利用检索增强生成(RAG)从知识库中检索相关信息,并根据用户的访问权限将其返回给用户。它由以下关键组件构成:
- Amazon Bedrock Knowledge Bases – 爬取公司网站的内容并将其存储在知识库中。从 Amazon Simple Storage Service (Amazon S3) 存储桶上传的文档(包括手册和故障排除指南)也会被索引并存储在知识库中。通过 Amazon Bedrock Knowledge Bases,您可以配置多个数据源,并使用筛选配置来区分内部和外部信息。这有助于通过高级安全控制来保护内部数据。
- Amazon Bedrock托管的LLM – 来自 Amazon Bedrock 的大型语言模型 (LLM) 会生成 AI 驱动的响应来回答用户问题。
- 可扩展的无服务器架构 – 该解决方案使用 Amazon Elastic Container Service (Amazon ECS) 托管用户界面 (UI),并使用 AWS Lambda 函数来处理用户请求。
- 自动化 CI/CD 部署 – 该解决方案使用 AWS Cloud Development Kit (AWS CDK) 来处理持续集成和交付 (CI/CD) 部署。
下图说明了该解决方案的架构。
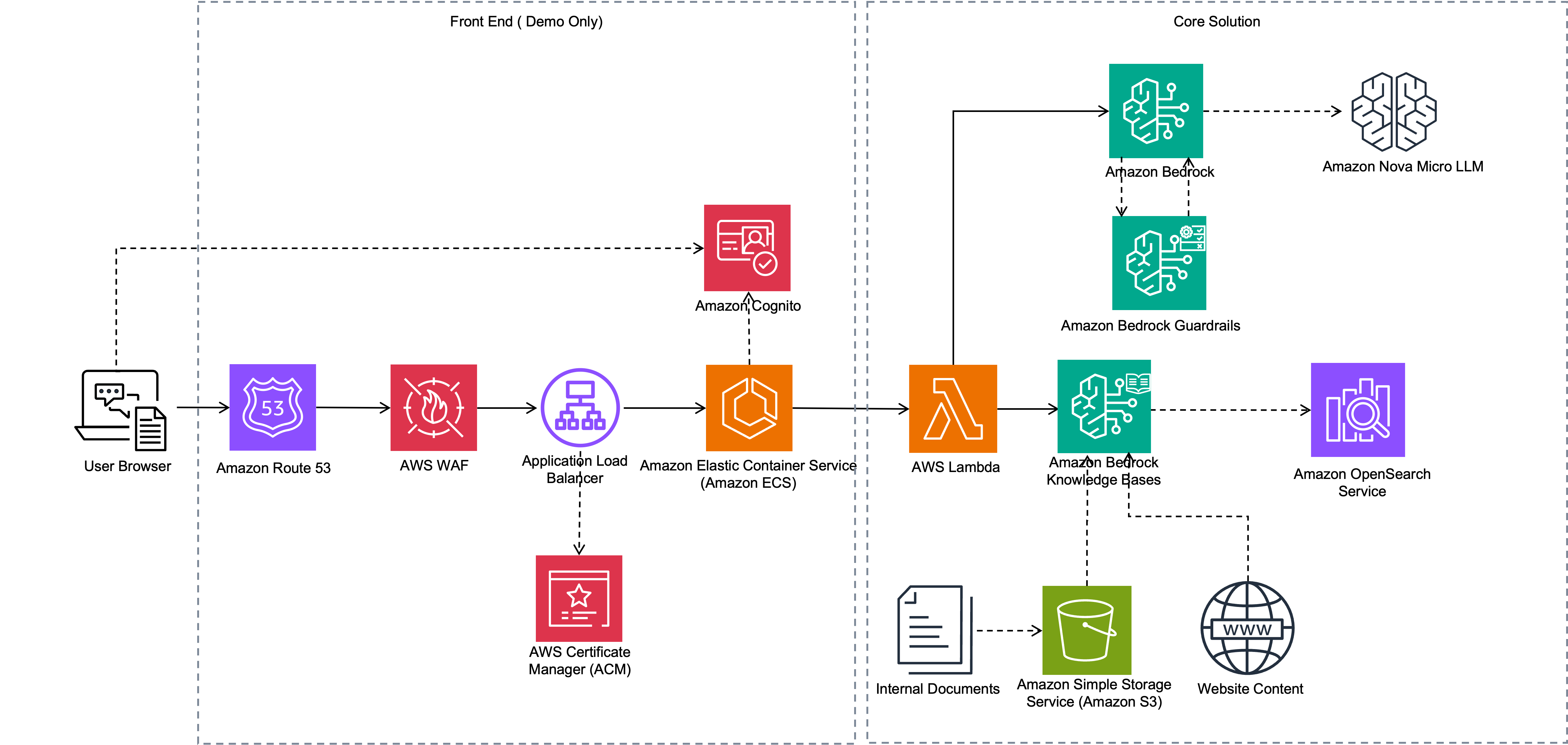
工作流程包括以下步骤:
- Amazon Bedrock Knowledge Bases 通过分块和生成嵌入来处理上传到 Amazon S3 的文档。此外,Amazon Bedrock Web Crawler 会访问选定的网站以提取和摄取其内容。
- Web 应用程序作为 ECS 应用程序运行。内部和外部用户通过 Elastic Load Balancing (ELB) 访问应用程序。用户使用在 Amazon Cognito 用户池中注册的登录凭据登录应用程序。
- 当用户提交问题时,应用程序会调用一个 Lambda 函数,该函数使用 Amazon Bedrock API 从知识库中检索相关信息。它还会根据用户类型(外部或内部)向 Amazon Bedrock 提供相关的数据源 ID,以便知识库仅检索该用户类型可用的信息。
- 然后,Lambda 函数调用 Amazon Nova Lite LLM 来生成响应。LLM 会结合知识库中的信息,生成对用户查询的响应,该响应从 Lambda 函数返回并显示给用户。
在接下来的部分中,我们将演示如何爬取和配置外部网站作为知识库,以及如何上传内部文档。
先决条件
要在本博文中部署此解决方案,您必须具备以下条件:
- 一个 AWS 账户。
- Amazon Bedrock 中对 Amazon Titan 和 Amazon Nova Lite 的模型访问权限。请在模型访问中使用的 AWS 区域与您部署解决方案的区域保持一致。
- 一个位于相同区域的 S3 存储桶,用于存储内部数据。
创建知识库并摄取网站数据
第一步是构建一个知识库,用于摄取来自网站和 S3 存储桶的运营文档数据。请完成以下步骤来创建知识库:
- 在 Amazon Bedrock 控制台中,在导航窗格的“构建工具”下,选择“知识库”。
- 在“创建”下拉菜单中,选择“带向量存储的知识库”。
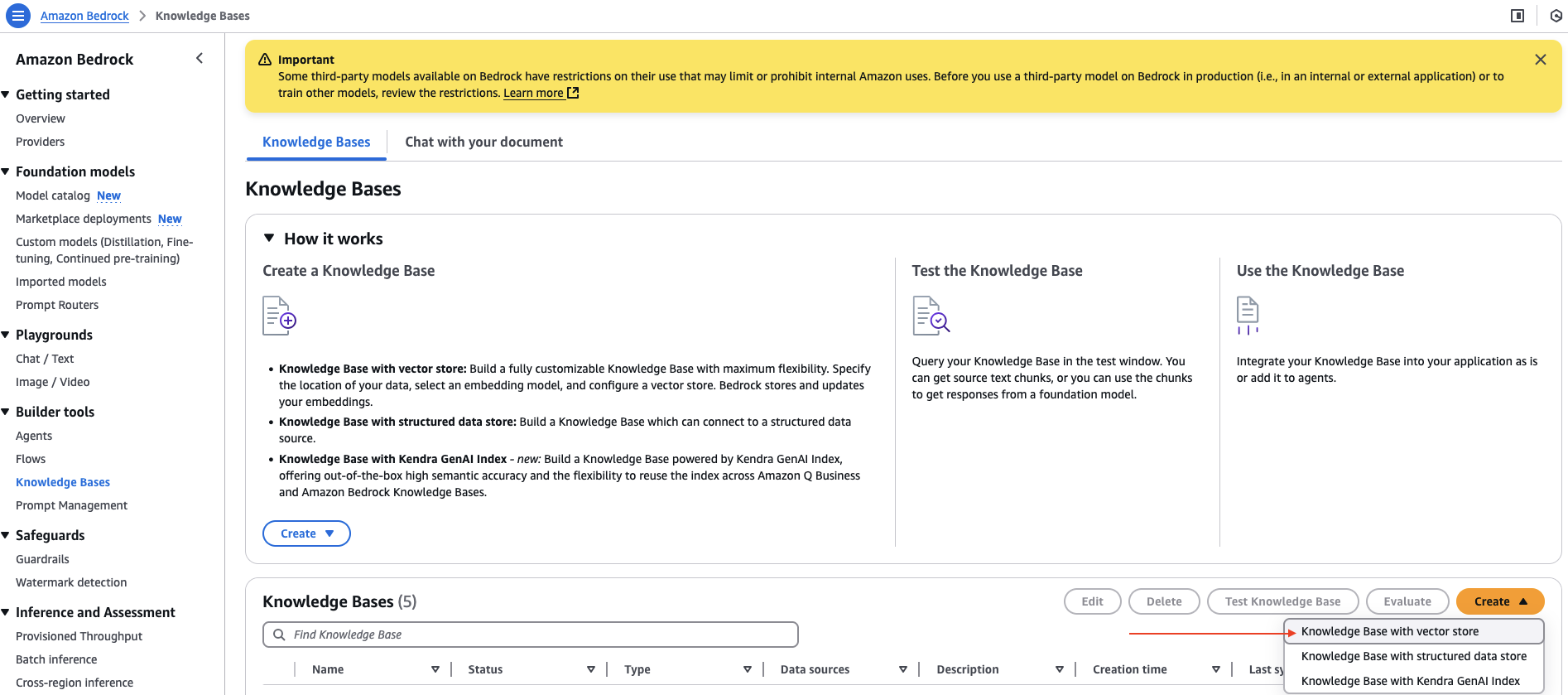
- 对于“知识库名称”,输入一个名称。
- 对于“选择数据源”,选择“Web Crawler”。
- 选择“下一步”。
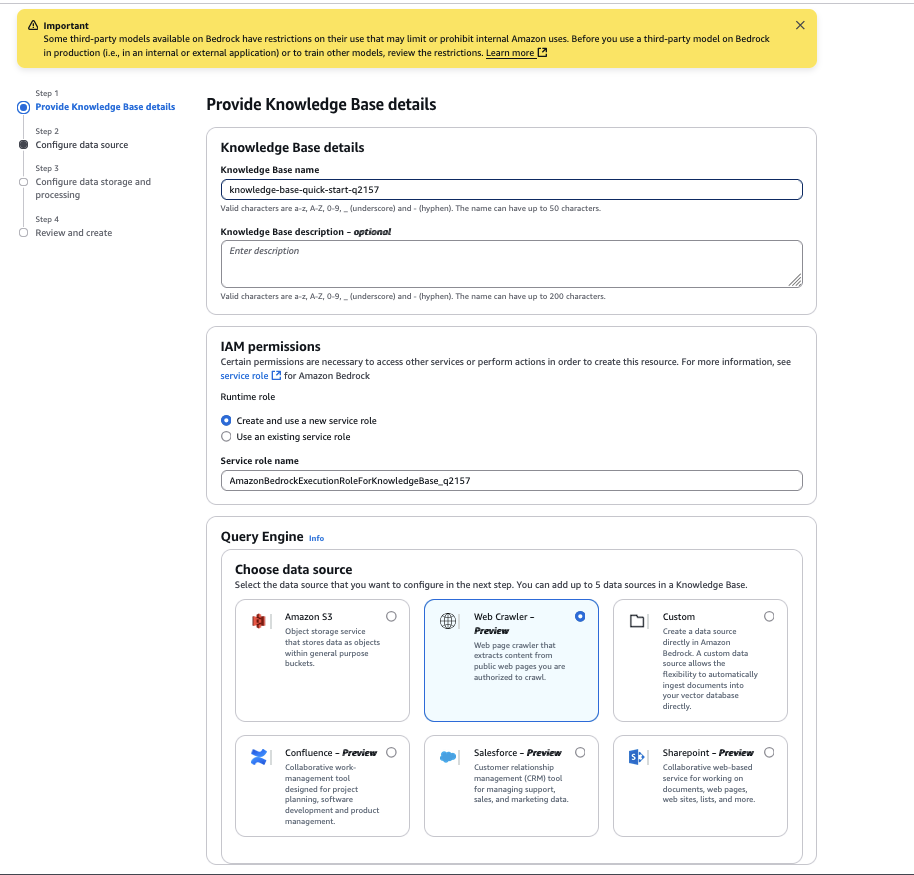
- 对于“数据源名称”,输入数据源的名称。
- 对于“源 URL”,输入要爬取的目标网站 HTML 页面。例如,我们使用
https://docs.aws.amazon.com/AmazonS3/latest/userguide/GetStartedWithS3.html。 - 对于“网站域名范围”,选择“默认”作为爬取范围。如果您想将爬取限制在特定域或子域,也可以配置它。
- 对于“URL 正则表达式筛选器”,您可以配置要包含或排除特定 URL 的 URL 模式。在此示例中,我们留空。
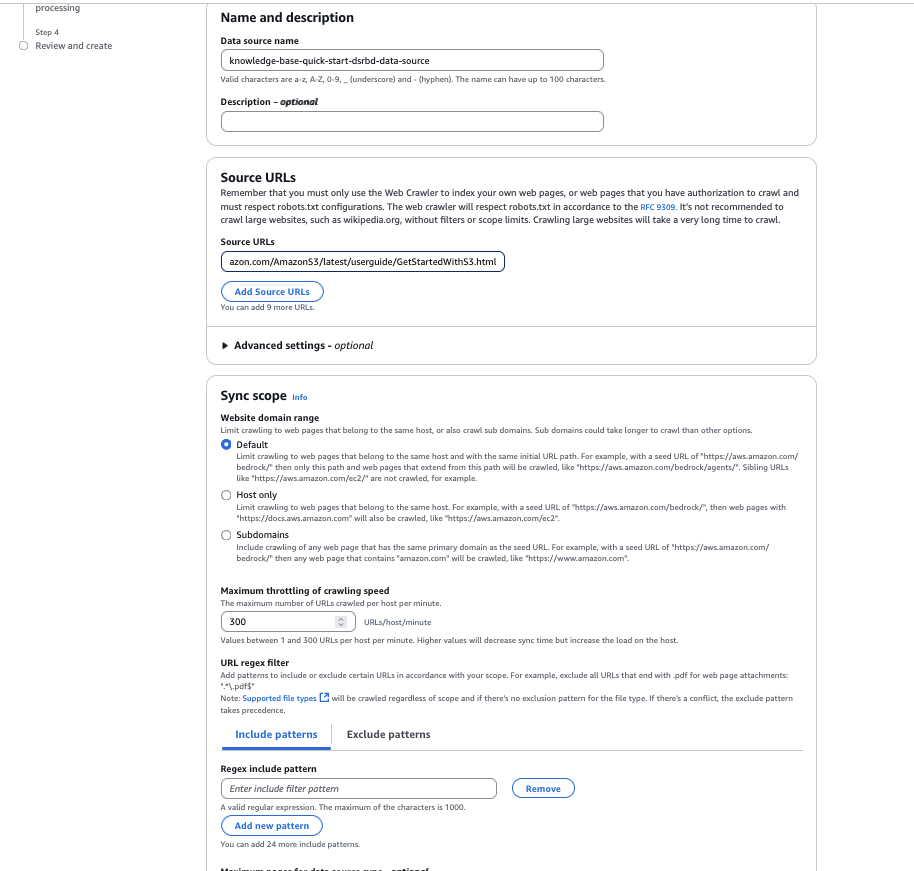
- 对于“分块策略”,您可以配置内容解析选项,以自定义数据分块策略。在此示例中,我们保持为“默认分块”。
- 选择“下一步”。
- 选择 Amazon Titan Text Embeddings V2 模型,然后选择“应用”。
- 对于“向量存储类型”,选择“Amazon OpenSearch Serverless”,然后选择“下一步”。
- 查看配置,然后选择“创建知识库”。
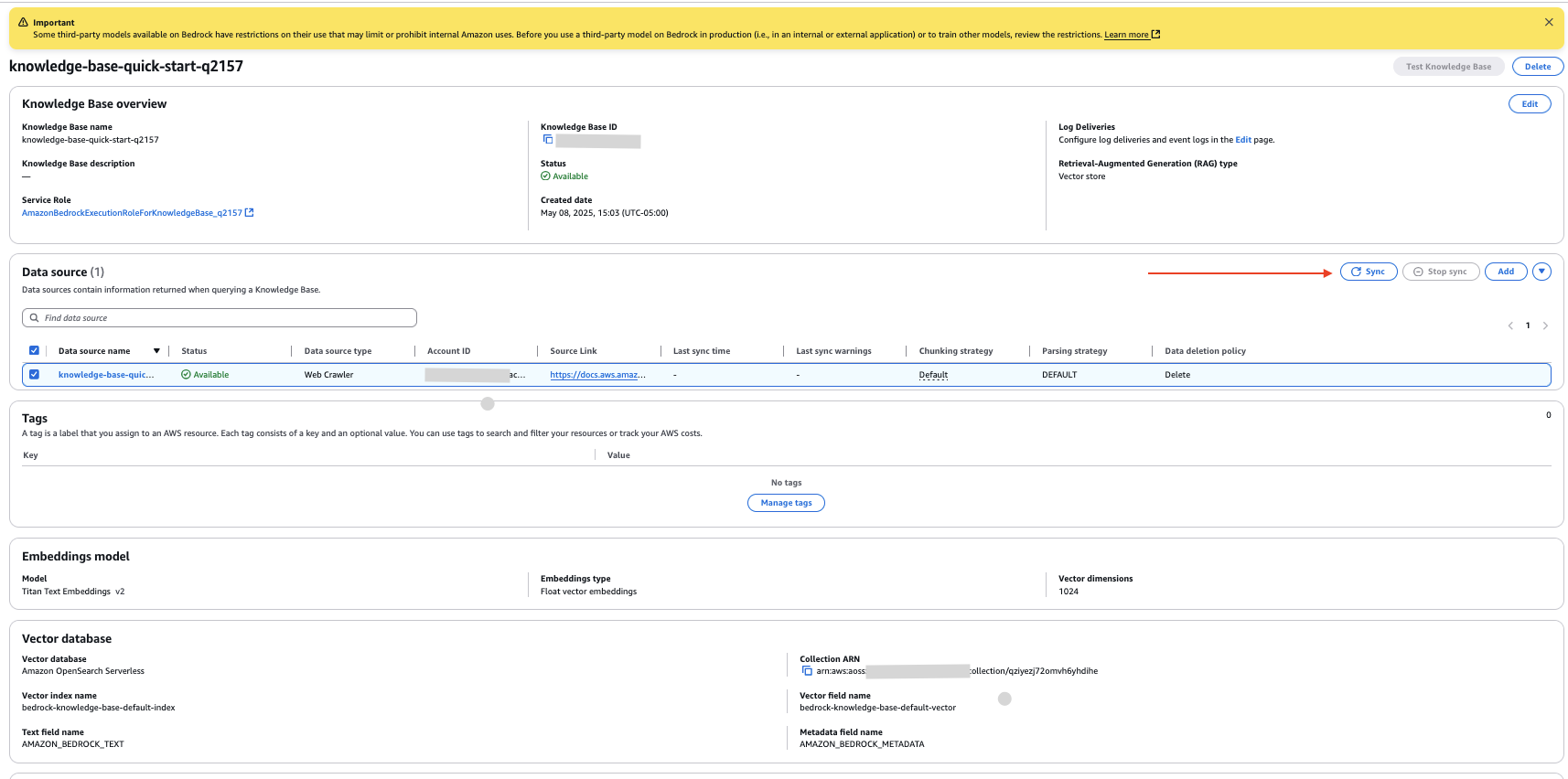
您现在已创建了一个知识库,并将您提供的网站链接配置为数据源。
- 在知识库详细信息页面上,选择新的数据源,然后选择“同步”以爬取网站并摄取数据。
配置 Amazon S3 数据源
完成以下步骤,将 S3 存储桶中的文档配置为内部数据源:
- 在知识库详细信息页面上,在“数据源”部分,选择“添加”。
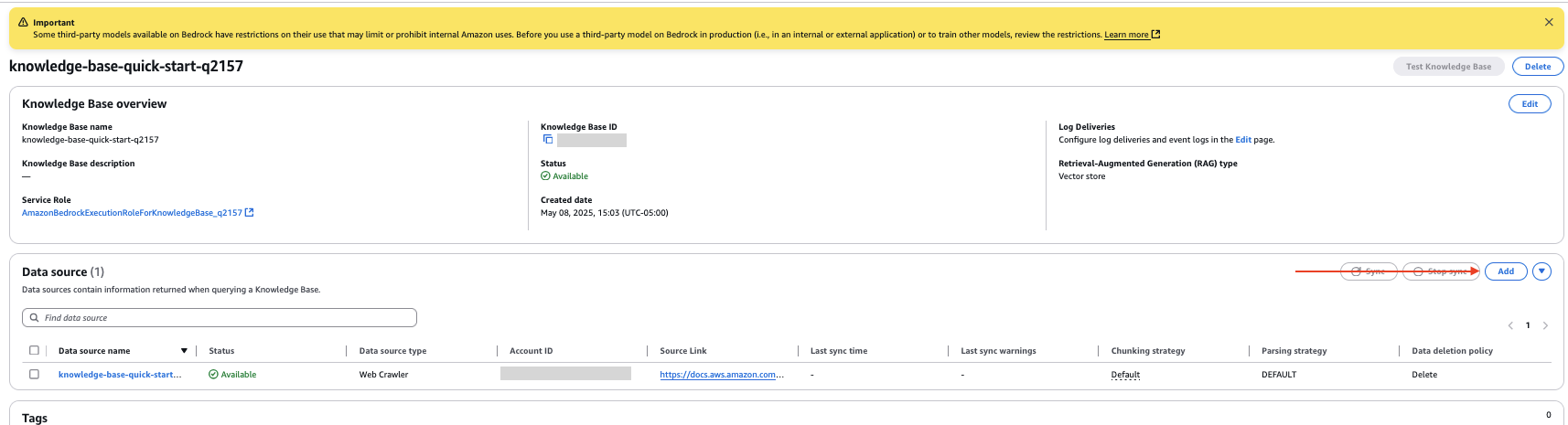
- 将数据源指定为 Amazon S3。
- 选择您的 S3 存储桶。
- 将解析策略保留为默认设置。
- 选择“下一步”。
- 查看配置,然后选择“添加数据源”。
- 在知识库详细信息页面的“数据源”部分,选择新的数据源,然后选择“同步”,以索引 S3 存储桶中文档中的数据。
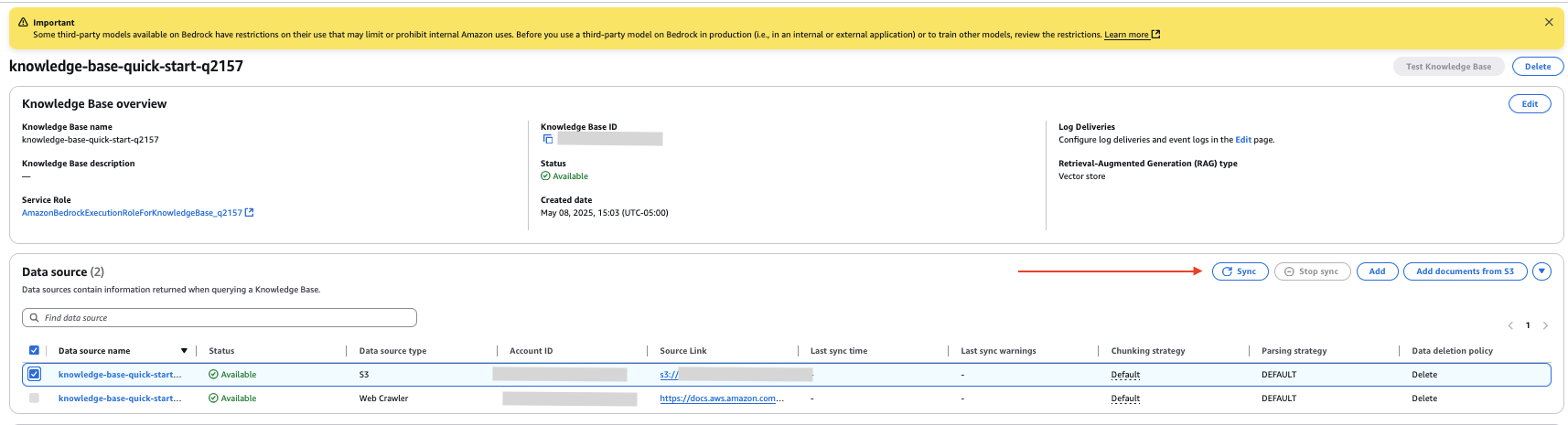
上传内部文档
在此示例中,我们在新的 S3 存储桶数据源中上传一个文档。以下屏幕截图显示了我们的文档示例。

完成以下步骤以上传文档:
- 在 Amazon S3 控制台中,在导航窗格中选择“存储桶”。
- 选择您创建的存储桶,然后选择“上传”以上传文档。
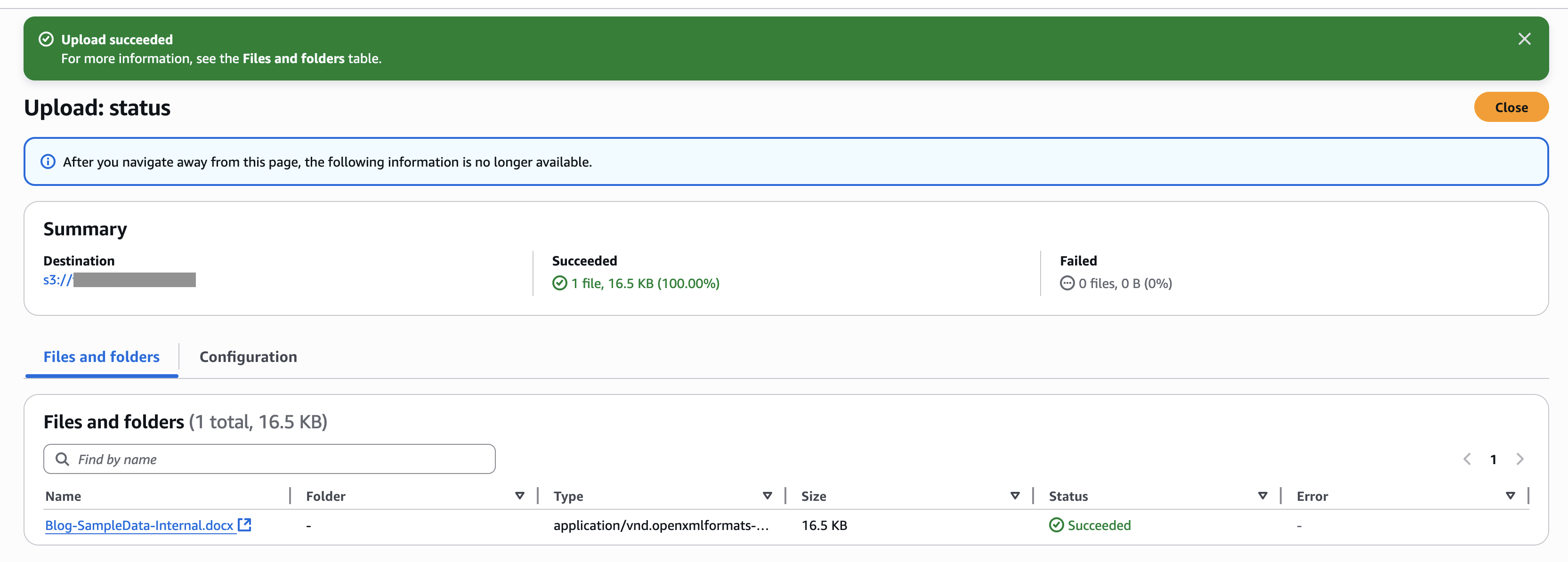
- 在 Amazon Bedrock 控制台中,转到您创建的知识库。
- 选择您创建的内部数据源,然后选择“同步”,以将上传的文档与向量存储同步。
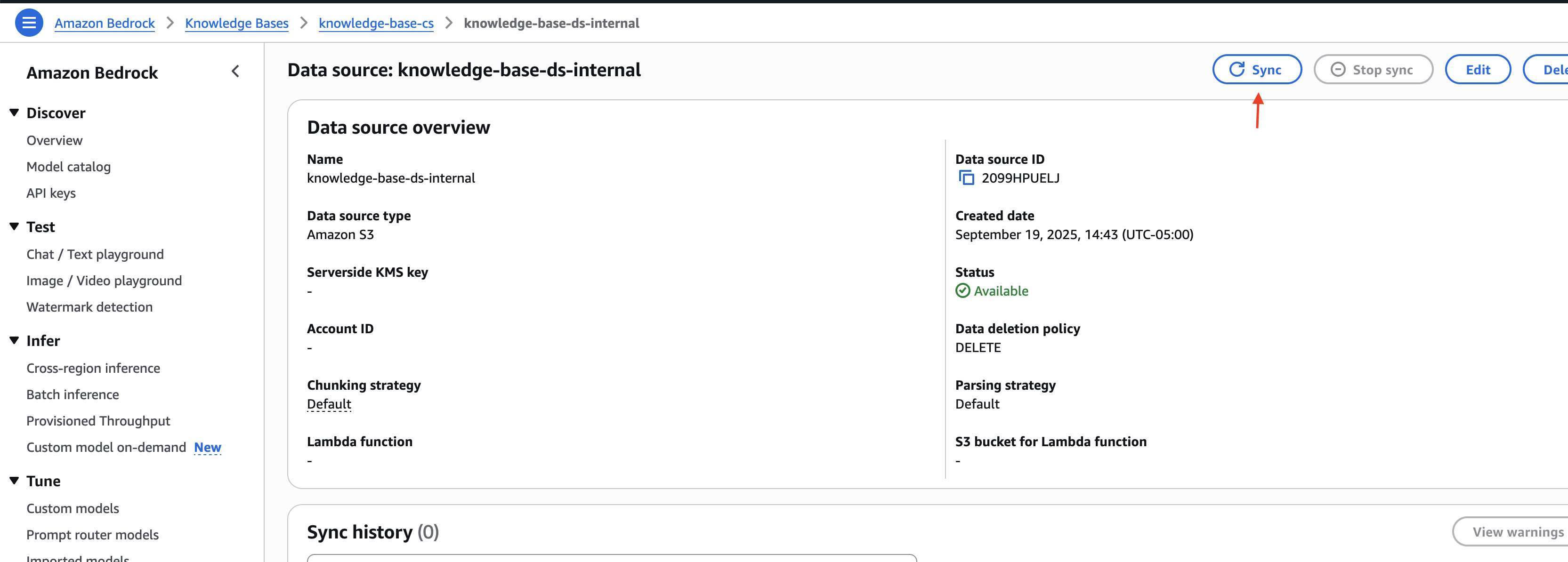
记下知识库 ID 和外部与内部数据源的数据源 ID。您将在下一步部署解决方案基础架构时使用此信息。
部署解决方案基础架构
要使用 AWS CDK 部署解决方案基础架构,请完成以下步骤:
- 从代码存储库下载代码。
- 进入下载项目中
iac目录:
cd ./customer-support-ai/iac
- 打开
parameters.json文件,并使用上一节捕获的值更新知识库和数据源 ID:
"external_source_id": "Set this to value from Amazon Bedrock Knowledge Base datasource",
"internal_source_id": "Set this to value from Amazon Bedrock Knowledge Base datasource",
"knowledge_base_id": "Set this to value from Amazon Bedrock Knowledge Base",- 按照
customer-support-ai/README.md文件中定义的部署说明设置解决方案基础架构。
部署完成后,您可以在脚本执行输出中找到应用程序负载均衡器 (ALB) URL 和演示用户详细信息。
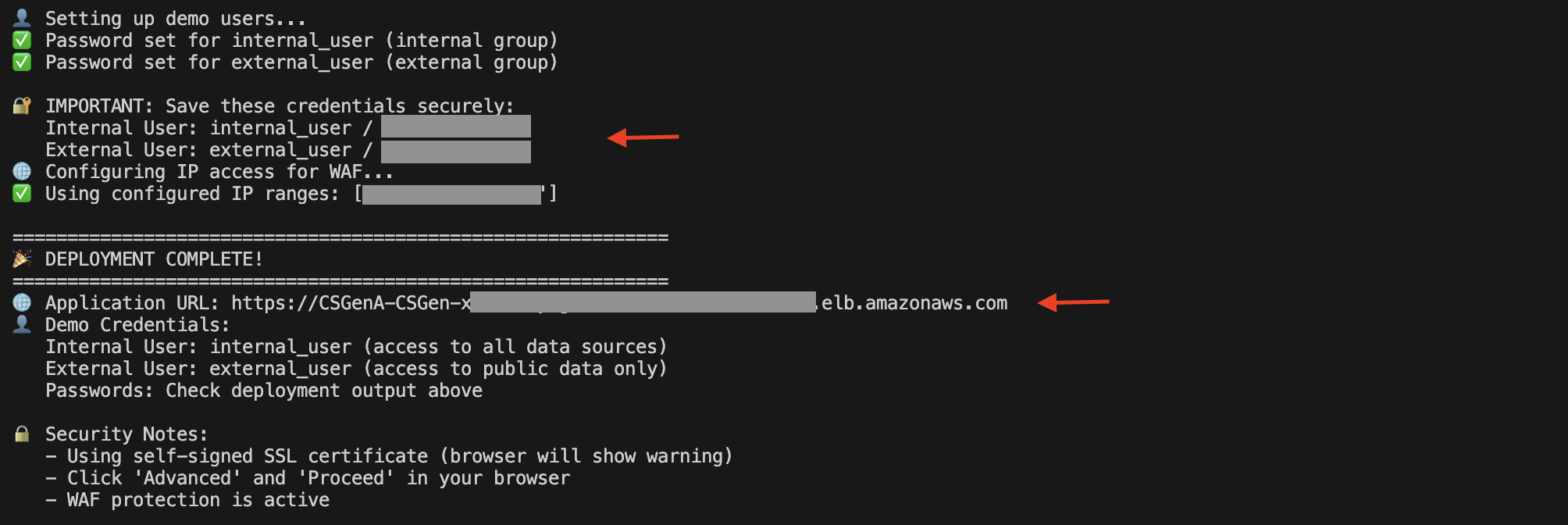
您也可以打开 Amazon EC2 控制台,在导航窗格中选择“负载均衡器”以查看 ALB。

在 ALB 详细信息页面上,复制 DNS 名称。您可以使用它来访问 UI 以试用此解决方案。

提交问题
让我们以 Amazon S3 服务支持为例进行探讨。该解决方案支持不同类别的用户来帮助解决他们的问题,同时利用 Amazon Bedrock Knowledge Bases 通过内置筛选控件管理特定数据源(如网站内容、文档和支持票证),以区分内部操作文档和可公开访问的信息。例如,内部用户可以访问公司特定的操作指南和公共文档,而外部用户只能访问公开可用的内容。
在浏览器中打开 DNS URL。输入外部用户凭据,然后选择“登录”。

成功通过身份验证后,您将被重定向到主页。
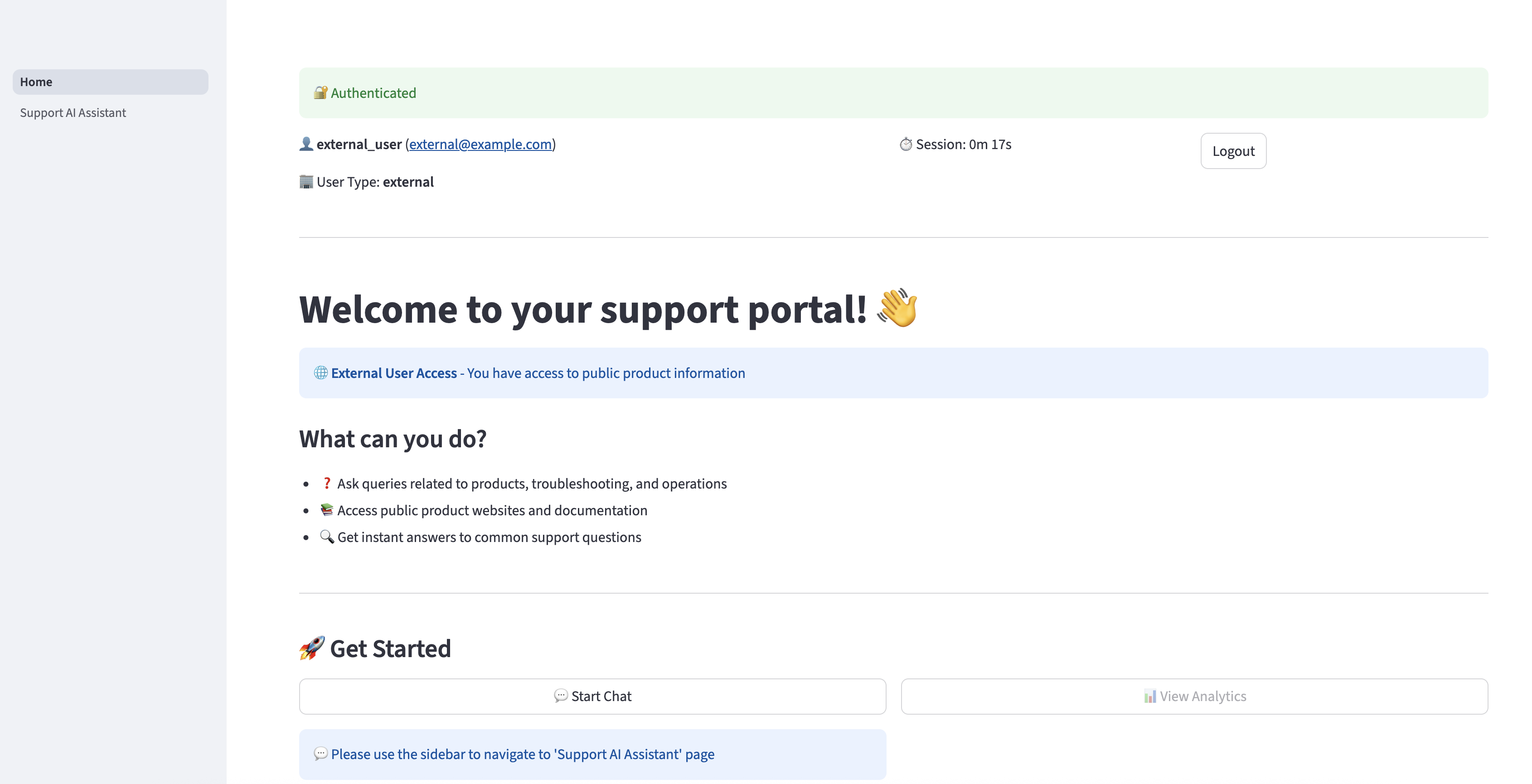
在导航窗格中选择“支持 AI 助手”以询问有关 Amazon S3 的问题。助手可以根据Amazon S3 用户指南中可用的信息提供相关响应。但是,如果外部用户提出的问题与仅供内部用户使用的数据相关,AI 助手将不会向该用户提供内部信息,并且只会使用外部用户可用的信息进行响应。
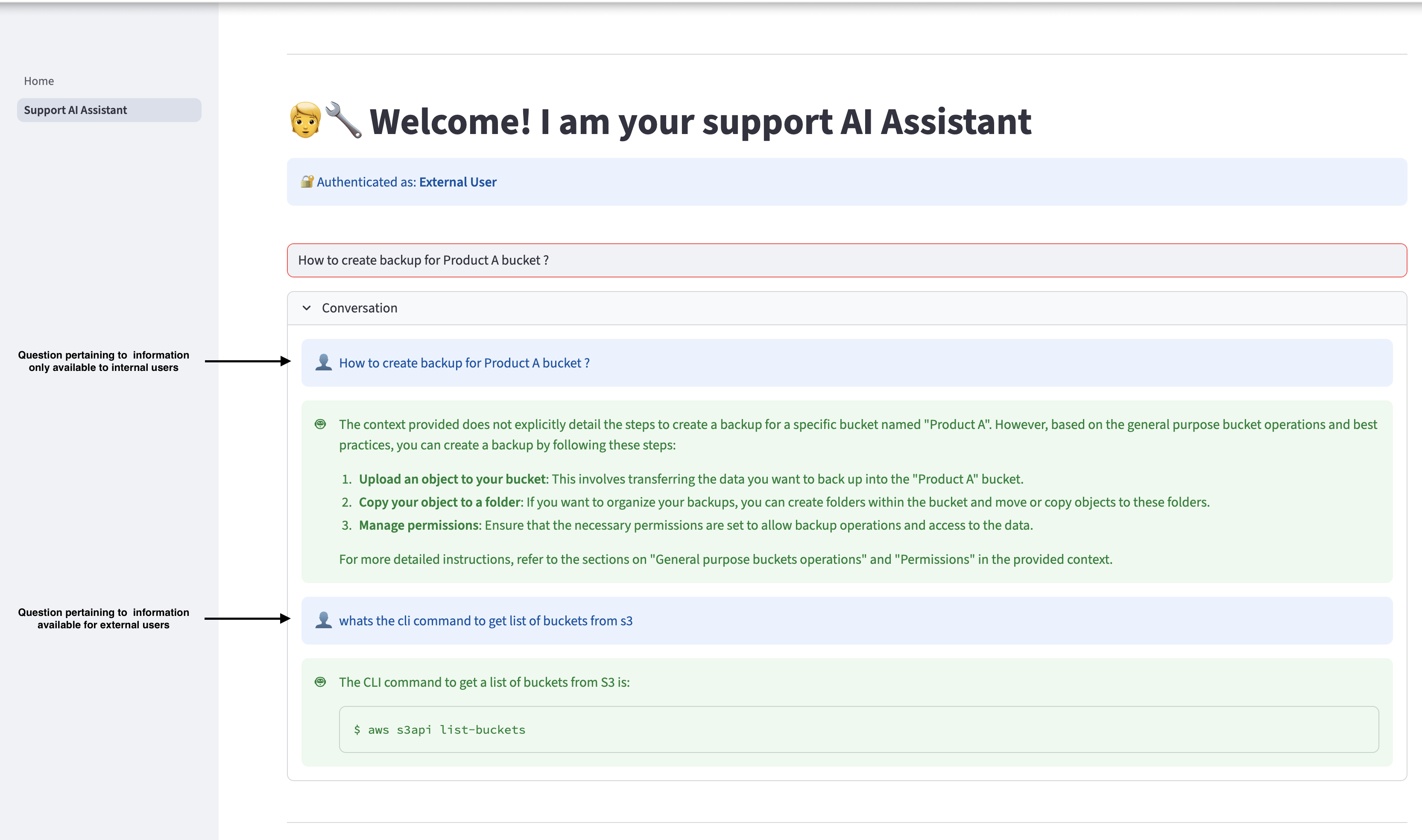
注销并以内部用户身份重新登录,并提出相同的查询。内部用户可以访问内部文档中可用的相关信息。

清理
如果您决定停止使用此解决方案,请完成以下步骤以删除其关联的资源:
- 转到项目代码中的
iac目录,然后在终端中运行以下命令:- 要运行清理脚本,请使用以下命令:
cd iac ./cleanup.sh - 要手动执行此操作,请使用以下命令:
cd iac cdk destroy --all
- 要运行清理脚本,请使用以下命令:
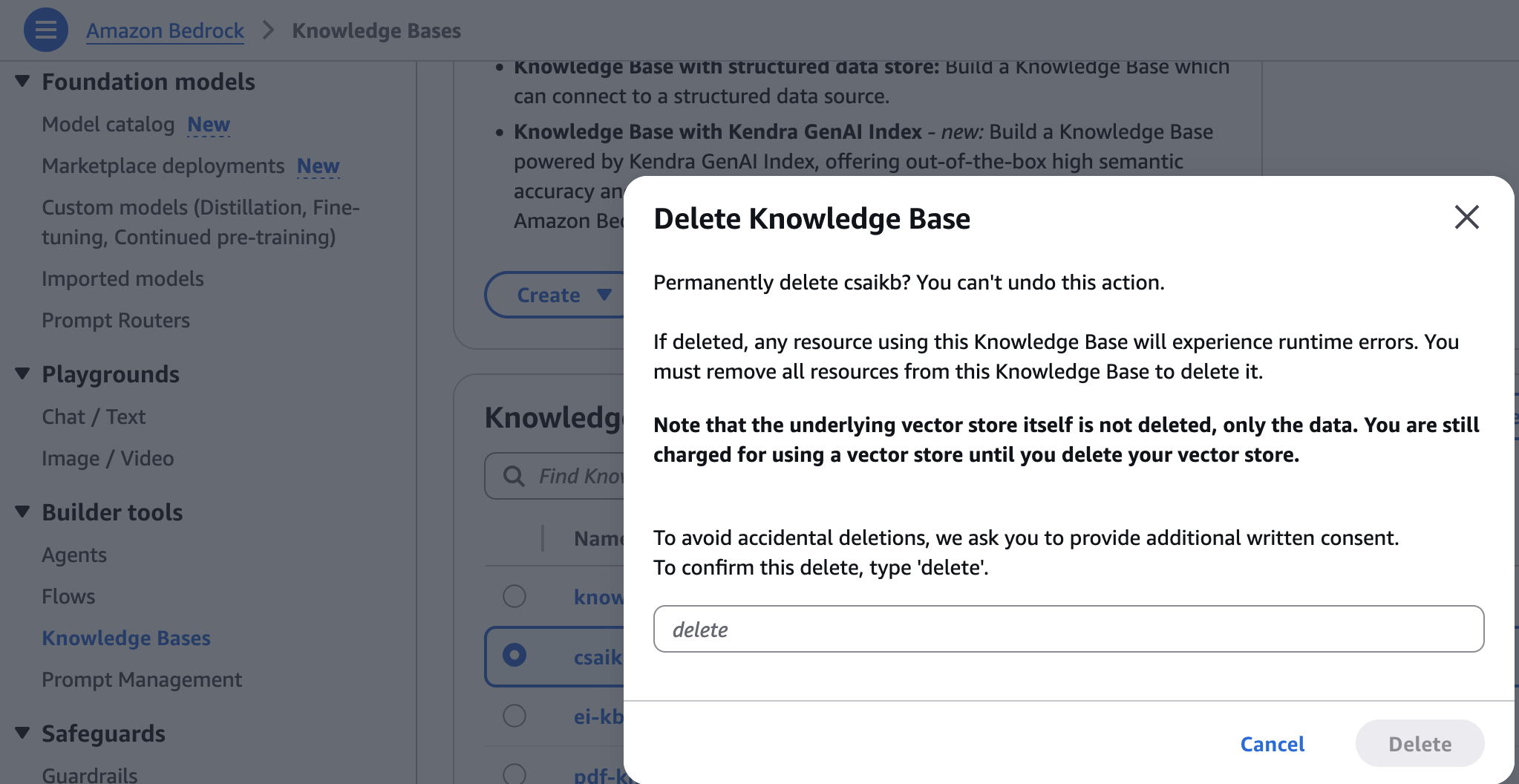
- 在 Amazon Bedrock 控制台中,在导航窗格的“构建工具”下,选择“知识库”。
- 选择您创建的知识库,然后选择“删除”。
- 输入
delete,然后选择“删除”以确认。
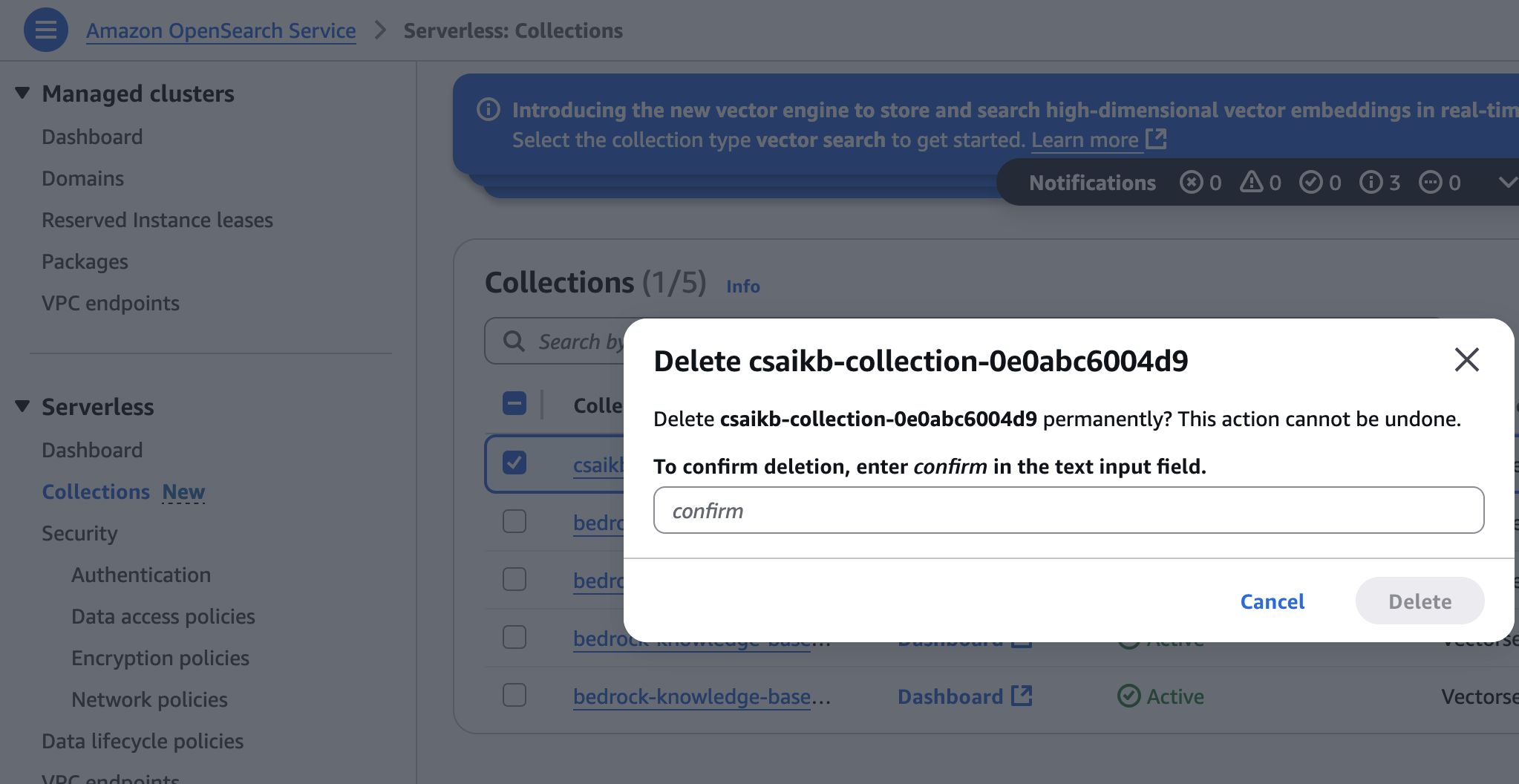
- 在 OpenSearch Service 控制台中,在“无服务器”下,在导航窗格中选择“集合”。
- 选择基础架构预配期间创建的集合,然后选择“删除”。
- 输入
confirm,然后选择“删除”以确认。
结论
本文演示了如何通过网络爬取和上传文档来构建知识库,从而创建一个AI 驱动的网站助手,以快速检索信息。您可以使用相同的方法来开发其他生成式 AI 原型和应用程序。
如果您有兴趣了解生成式 AI 的基础知识以及如何使用 FM(包括高级提示技术),请查看“使用 LLM 进行生成式 AI”实践课程。这门为期 3 周的按需课程面向希望学习如何使用 LLM 构建生成式 AI 应用程序的数据科学家和工程师。它是开始使用 Amazon Bedrock 构建的良好基础。请注册以了解有关 Amazon Bedrock 的更多信息。
关于作者
 Shashank Jain 是亚马逊云科技 (AWS) 的云应用程序架构师,专注于生成式 AI 解决方案、云原生应用程序架构和可持续性。他与客户合作,利用无服务器技术、现代 DevSecOps 实践、基础设施即代码和事件驱动架构来设计和实施安全、可扩展的 AI 驱动应用程序,从而实现可衡量的业务价值。
Shashank Jain 是亚马逊云科技 (AWS) 的云应用程序架构师,专注于生成式 AI 解决方案、云原生应用程序架构和可持续性。他与客户合作,利用无服务器技术、现代 DevSecOps 实践、基础设施即代码和事件驱动架构来设计和实施安全、可扩展的 AI 驱动应用程序,从而实现可衡量的业务价值。
 Jeff Li 是 AWS 专业服务团队的高级云应用程序架构师。他热衷于与客户深入合作,创建支持业务创新的解决方案和现代化应用程序。在业余时间,他喜欢打网球、听音乐和阅读。
Jeff Li 是 AWS 专业服务团队的高级云应用程序架构师。他热衷于与客户深入合作,创建支持业务创新的解决方案和现代化应用程序。在业余时间,他喜欢打网球、听音乐和阅读。
 Ranjith Kurumbaru Kandiyil 是位于多伦多的亚马逊云科技 (AWS) 数据和 AI/ML 架构师。他专注于与客户合作设计和实施最前沿的 AI/ML 解决方案。他目前的重点是利用最先进的人工智能技术来解决复杂的业务挑战。
Ranjith Kurumbaru Kandiyil 是位于多伦多的亚马逊云科技 (AWS) 数据和 AI/ML 架构师。他专注于与客户合作设计和实施最前沿的 AI/ML 解决方案。他目前的重点是利用最先进的人工智能技术来解决复杂的业务挑战。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区