



📢 转载信息
原文作者:ND Ngoka, Alex Fabisiak, Jim Fratantoni, Samhita Alla, Kristy Cook, and Theo Rashid
随着人工智能和机器学习(AI/ML)工作流的规模和复杂性不断增长,从业人员组织和部署模型变得越来越困难。AI项目通常难以从试点阶段过渡到生产阶段。AI项目失败的原因往往不在于模型不好,而在于基础设施和流程是碎片化且脆弱的,并且最初的试点代码库常常因为这些额外的要求而不得不臃肿化。这使得数据科学家和工程师难以快速地从笔记本电脑迁移到集群(本地开发到生产部署),并重现他们在试点期间看到的精确结果。
在本文中,我们将解释如何使用Flyte Python SDK来编排和扩展AI/ML工作流。我们将探讨Union.ai 2.0系统如何实现在Amazon Elastic Kubernetes Service (Amazon EKS) 上部署Flyte,并与Amazon Simple Storage Service (Amazon S3)、Amazon Aurora、AWS Identity and Access Management (IAM) 和 Amazon CloudWatch等AWS服务无缝集成。我们将通过一个AI工作流示例来探索该解决方案,该示例使用了新的Amazon S3 Vectors服务。
在Kubernetes上运行AI/ML工作流的常见挑战
在Kubernetes上运行的AI/ML工作流带来了几个编排方面的挑战:
- 基础设施复杂性 – 在Kubernetes集群中动态配置正确的计算资源(CPU、GPU、内存)
- 实验到生产的鸿沟 – 从实验到生产的迁移通常需要在不同环境中重建管道
- 可复现性 – 跟踪数据血缘、模型版本和实验参数,以促进可靠的结果
- 成本管理 – 高效利用竞价实例(spot instances),自动扩展,避免过度配置
- 可靠性 – 通过自动重试、检查点和恢复机制优雅地处理故障
专用的AI/ML工具对于编排复杂工作流至关重要,它提供智能缓存、自动版本控制和动态资源分配等专业功能,从而简化开发和部署周期。
为什么选择Flyte/Union for Amazon EKS
Amazon EKS 上的 Flyte Python 工作流通过动态执行、可复现性和面向计算的编排,实现了从笔记本电脑到集群的扩展。这些工作流与Union.ai 的托管部署相结合,促进了无缝、防崩溃的操作,充分利用Amazon EKS,而无需基础设施开销。Flyte改变了您在Amazon EKS上编排AI/ML工作负载的方式,使工作流的构建变得简单。一些关键因素包括:
- 纯Python工作流 – 使用比传统编排器少66%的代码在Python中编写编排逻辑,减轻了学习领域特定语言的需要,并消除了ML工程师和AI开发人员迁移现有代码的障碍
- 动态执行 – 在运行时使用灵活的分支、循环和条件逻辑进行实时决策,这对于代理式AI系统至关重要
- 默认可复现性 – 每次执行都会被版本化、缓存,并带有完整的数据血缘进行跟踪
- 面向计算的编排 – 为每个任务动态配置正确的计算资源,从数据处理的CPU到模型训练的GPU
- 鲁棒性 – 管道可以快速从故障中恢复、隔离错误,并在没有手动干预的情况下管理检查点
Union.ai 2.0 构建在Flyte之上,Flyte是一个开源的、基于Kubernetes的工作流编排系统,最初在Lyft开发,用于支持ETA预测、定价和地图绘制等任务关键型ML系统。Flyte于2020年开源并成为Linux Foundation AI & Data项目后,核心工程团队创建了Union.ai 2.0,为在Amazon EKS上运行AI/ML工作负载的团队提供企业级服务。Union.ai 2.0 通过托管操作、多云控制平面和抽象的基础设施管理,减少了管理Kubernetes基础设施的复杂性,同时提供基于ML的功能,帮助数据科学家和工程师专注于以增强的规模、速度、安全性和可靠性构建模型。
使用Union.ai 2.0的其他好处包括:
- 增强的可扩展性 – 工作流可以通过灵活的分支、任务扇出和实时基础设施扩展在运行时响应。
- 防崩溃可靠性 – 自动重试、检查点和故障恢复使工作流能够在没有手动干预的情况下保持弹性。
- 代理式AI运行时 – Union.ai 专为长期运行的代理式AI系统设计,支持有状态代理和真正的持久化编排。
- 合规性 – 对于受监管的行业,内置的血缘、可审计性和安全执行(SOC2、RBAC、SSO)至关重要。在Amazon EKS和Union.ai上进行编排有助于实现合规性。
- 资源感知 – 它对计算配置、竞价实例和自动扩展提供一流的支持。
Flyte和Union.ai 2.0的优势将现代编排提升到了一个一流的要求:动态执行、容错能力和资源感知现已内置,与1.0版本相比,提供了对开发人员更友好的体验。
Amazon EKS 提供了您的计算、存储和网络骨干。Flyte(开源项目)负责工作流编排。Union.ai 使用基础设施感知的编排、企业级安全和一键式可扩展性扩展了Flyte,为您提供了生产就绪的Flyte,而无需自己动手设置。Flyte和Union.ai 2.0都在Amazon EKS上运行,但服务于不同的需求,如下表所示。
| 特性 | 开源 Flyte | Union.ai 2.0 |
| 部署 | 在您的EKS集群上自托管 | 完全托管或BYOC选项 |
| 最适合 | 具有Kubernetes专业知识的团队 | 希望进行托管操作的团队 |
| 性能 | 标准规模 | 规模、速度、任务扇出和并行度提高10-100倍 |
| 基础设施 | 您管理升级、扩展 | 白手套式托管基础设施 |
| 企业特性 | 无基于角色的访问控制 | 细粒度的基于角色的访问控制、单点登录、托管密钥、成本仪表板 |
| 支持 | 社区驱动 | Union.ai团队的企业SLA |
| 实时服务 | 自己构建 | 内置的实时推理和近实时推理,带有可重用容器 |
Woven Toyota、Lockheed Martin、Spotify和Artera等企业每年使用Flyte和Union编排数百万美元的计算资源,将实验加速提高了25倍,并将迭代周期缩短了96%。
这两种选择(开源Flyte和Union.ai 2.0)都与开源社区集成,有利于快速部署新功能和持续改进。
解决方案概述
尽管开源Flyte提供了强大的编排能力,但Union.ai 2.0以企业级管理交付了相同的核心技术,消除了操作开销,使您的团队能够专注于构建AI应用程序,而不是管理基础设施。这是通过一种混合架构实现的,该架构将托管的简易性与完整的数据控制相结合。区域控制平面处理工作流元数据和协调,而Union Operator 直接部署到您的EKS集群中——将您的数据、代码和密钥完全保留在您的AWS边界内。
下图说明了Union控制平面和数据平面之间的操作流程。Union托管的控制平面(左侧)通过Elastic Load Balancing (ELB) 编排工作流,将任务数据存储在Amazon S3中,并将执行元数据存储在Aurora中。在您的Amazon EKS环境中(右侧),数据平面执行工作流,这些工作流从您的容器注册表中拉取客户代码,从AWS Secrets Manager中访问密钥,并向您的S3存储桶中读写数据——执行日志同时流向CloudWatch和Union控制平面,以实现可观测性。
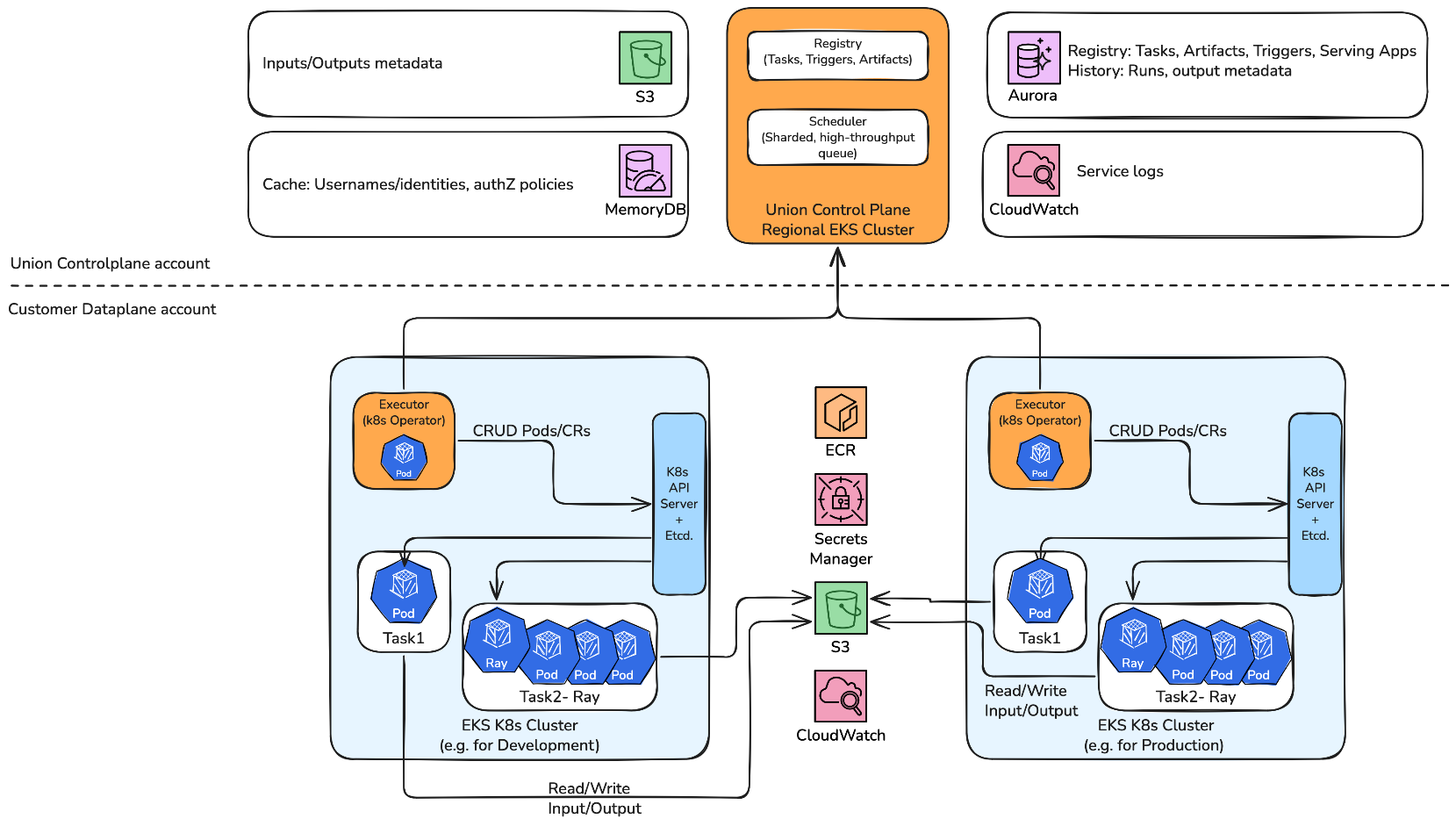
Union.ai 2.0的AWS集成架构建立在六个关键服务组件之上,这些组件提供端到端的*工作流管理*:
- 控制平面和数据平面 – 控制平面在Union.ai AWS账户内运行,作为中央管理界面,为用户提供身份验证和授权功能、观察和监控功能以及系统管理工具。它还负责在数据平面集群上编排执行放置,并处理集群控制和管理操作。Union.ai 2.0为每个AWS区域维护一个控制平面,管理区域数据平面。数据平面部署的可用区域包括
us-west、us-east、eu-west和eu-central,并正在扩展到其他区域。 - 数据平面对象存储 – 此组件存储由文件、目录、数据帧、模型和Python-pickled类型组成的数据,这些数据作为引用传递并由控制平面读取。
- 容器注册表 – 此组件包含注册表数据,包括工作流、任务、启动计划和工件的名称;工作流和任务的输入和输出类型;工作流和任务的执行状态、开始时间、结束时间和持续时间;工作流、任务、启动计划和工件的版本信息;以及工件定义。使用Union.ai 2.0架构,您可以保留对数据和计算资源的完全所有权,同时它管理基础设施操作。Union.ai 2.0 Operator 驻留在数据平面中,并以最小权限处理管理任务。它支持集群生命周期操作,并为支持工程师提供系统级日志访问和变更实施能力——而不会暴露密钥或数据。安全性通过单向通信得到进一步加强:数据平面 Operator 发起与控制平面的连接,而不是反之。
- 日志记录和监控 – CloudWatch 通过与Flyte的深度集成提供集中式日志记录和监控。系统会自动为每次执行构建日志链接,并在控制台中显示,其中链接直接指向AWS管理控制台和该执行的特定日志流——此功能大大加快了故障排除速度。
- 安全性 – 安全性通过IAM角色与服务账户 (IRSA) 来处理,该角色将Kubernetes资源与它们所依赖的AWS服务之间的身份进行映射。这些配置为后端提供了更安全、更细粒度的访问控制,Union.ai 2.0在此AWS安全功能之上增加了用于用户访问控制的企业级基于角色的访问控制 (RBAC)。
- 存储层 – Amazon S3 作为工作流和数据的持久存储层。当您使用Flyte注册工作流时,您的代码会被编译成一种与语言无关的表示形式,该形式捕获工作流定义、输入和输出类型。此表示形式被打包并存储在Amazon S3中,FlytePropeller(Flyte的执行引擎)从中检索信息,以指示相应的计算框架(如Kubernetes或Spark)来运行工作流并报告状态。用于训练和验证模型的原始输入数据也存储在Amazon S3中。Union.ai 2.0现在包括对Amazon S3 Vectors的新集成,支持用于检索增强生成 (RAG)、语义搜索和代理式AI工作流的向量存储。
在建立如此强大的基础设施后,Amazon EKS 上的 Union.ai 2.0 在编排各种AI/ML工作负载方面表现出色。它通过跨GPU集群编排分布式训练管道来处理大规模模型训练,并支持自动资源配置和竞价实例。对于数据处理,它可以处理PB级数据集,具有动态并行性和高效的任务扇出,在Union.ai 2.0中可扩展到100,000个任务扇出和50,000个并发操作。通过在Amazon EKS上使用Union.ai 2.0和Flyte,您可以构建和部署代理式AI系统——长期运行的有状态AI代理,它们在运行时自主决策。对于生产部署,它支持实时推理,具有低延迟模型服务,使用可重用容器实现低于100毫秒的任务启动时间。在整个过程中,Union.ai 2.0 提供全面的MLOps和模型生命周期管理,自动化从实验到生产部署的一切,并具有内置的版本控制和回滚功能。
这些功能在专门的实现中得到了体现,例如在AWS Trainium实例上进行分布式训练,其中Flyte在Amazon EKS上编排大规模训练工作负载。
Union.ai 2.0 在 Amazon EKS 上的部署选项
Union.ai 2.0 和 Flyte 为 Amazon EKS 提供了三种灵活的部署模型,每种模型都在托管便利性和操作控制之间取得了平衡。选择最适合您团队的专业知识、合规性要求和开发速度的方法:
- Union BYOC(完全托管) – 最快的生产路径。Union.ai 2.0 管理基础设施、升级和扩展,而您的工作负载在您的AWS账户中运行。此选项非常适合希望完全专注于AI开发而不是基础设施操作的团队。
- Union 自托管 – 您可以部署Union.ai 2.0 的托管控制平面,同时在您的AWS账户中保持对数据和计算资源的控制。此选项结合了托管服务的优势以及数据主权和治理要求。
- Amazon EKS 上的 Flyte OSS – 您可以使用AWS Cloud Development Kit (AWS CDK) 在您的EKS集群上直接部署和操作开源Flyte。此选项提供了最大的控制权,非常适合具有强大Kubernetes专业知识并希望自定义部署的团队。 (edited)
Amazon EKS Blueprints for AWS CDK Union add-on 帮助AWS客户使用Amazon EKS上的Union部署、扩展和优化AI/ML工作负载。它提供模块化的基础设施即代码 (IaC) AWS CDK模板和精选的部署蓝图,用于运行可扩展的AI工作负载,包括:
- 模型训练和微调管道
- 大型语言模型 (LLM) 推理和服务
- 多模型部署和管理
- 代理式AI管道编排
Union.ai 2.0 和 Flyte 为在Amazon EKS上部署提供 IaC 模板:
- Terraform 模块 – 用于使用网络、安全性和可观测性的最佳实践在Amazon EKS上部署Flyte的预配置模块
- AWS CDK 支持 – 用于将Union集成到现有AWS基础设施中的AWS CDK构造
- GitOps 工作流 – 支持Flux和ArgoCD进行声明式基础设施管理
Union 插件在博客发布时可用,Flyte 插件即将推出——请持续关注GitHub仓库。
这些模板会自动配置EKS集群、节点组(包括GPU实例)、IAM角色、S3存储桶、Aurora数据库和所需的Flyte组件。
先决条件
要开始使用此解决方案,您必须具备以下先决条件:
- 具有适当权限的AWS账户。
- 处于标准支持的Amazon EKS版本。
- 所需的IAM角色。使用服务账户的IAM角色,Flyte可以将身份映射在Kubernetes资源和它们所依赖的AWS服务之间。这些配置用于后端,不会干扰用户到控制平面的通信
Union.ai 2.0 如何支持 Amazon S3 Vectors
随着AI应用程序越来越多地依赖向量嵌入来进行语义搜索和RAG,Union.ai 2.0通过Amazon S3 Vectors集成赋能团队,简化了大规模向量数据管理。此功能内置于Flyte 2.0中,现已可用。Amazon S3 Vectors 为语义搜索和AI应用程序提供专用的、成本优化的向量存储。凭借Amazon S3级别的弹性和持久性来存储向量数据集,并实现亚秒级查询性能,Amazon S3 Vectors非常适合需要大规模构建和增长向量索引的应用程序。Union.ai 2.0为RAG、语义搜索和多代理系统提供了对Amazon S3 Vectors的支持。如果您今天正在使用Union.ai 2.0并将Amazon S3作为对象存储,您可以立即开始使用Amazon S3 Vectors,只需最少的配置更改。
要进行设置,请使用Boto的专用API来存储和查询向量。您的Amazon S3 IAM角色已经到位。只需更新权限。
通过将Flyte 2.0的编排与Amazon S3 Vector支持相结合,多代理交易模拟可以扩展到数百个代理,这些代理可以从历史数据中学习、共享行业见解并实时执行协调策略。这些架构优势支持复杂的AI应用程序,例如需要语义记忆和实时协调的多代理系统。
要了解更多信息,请参阅使用Flyte 2.0和Amazon S3 Vectors的多代理交易模拟的示例用例。在此示例中,您将学习如何构建一个交易模拟,其中包含代表公司团队成员的多个代理,说明它们的交互、战略规划和协作交易活动
考虑一个多代理交易模拟,其中AI代理进行交互、测试策略并不断从经验中学习。为了实现逼真的代理行为,每个代理必须保留先前交互的上下文,本质上是构建一个指导未来决策的语义工件的记忆。该过程包括以下步骤:
- 在每次模拟回合后,使用嵌入模型将代理的学习嵌入到向量表示中。
- 使用Amazon S3 Vectors和适当的元数据和标签将嵌入存储在Amazon S3中。
- 在后续执行中,使用语义搜索检索相关记忆,以将代理决策建立在过去的经验之上。
使用Flyte 2.0,您的代理已经在编排感知的环境中运行。Amazon S3成为您的向量存储。它便宜、快速且完全集成,无需单独的向量数据库。有关实施多代理交易模拟的步骤和相关代码,请参阅GitHub repo。
总之,这种架构有助于为生产AI系统带来可衡量的优势:
- 降低运营复杂性 – 将您的AI/ML编排和向量存储整合到一个环境中,无需配置、维护和保护单独的向量数据库基础设施。
- 显著的成本节约 – Amazon S3 Vectors 提供的存储成本远低于专用的向量数据库,同时在大规模下提供亚秒级的相似性搜索性能。
- 零摩擦AWS集成 – 使用您现有的Amazon S3基础设施、IRSA配置和虚拟私有云 (VPC) 网络——无需额外的身份验证层或网络配置。
- 久经考验的可扩展性 – 建立在Amazon S3 99.999999999%的持久性和弹性可扩展性之上,以支持从GB到PB级的向量数据集,而无需重新架构。
客户成功案例:Woven by Toyota
丰田的自动驾驶部门Woven by Toyota,在为其自动驾驶技术编排复杂的AI工作负载方面面临挑战,需要PB级的数据处理和GPU密集型训练管道。在对其开源Flyte实现感到力不从心之后,他们于2023年迁移到了AWS上的Union.ai托管服务。这次迁移带来了变革性的影响:ML迭代周期加快了20多倍,通过竞价实例优化实现了数百万美元的年成本节约,并利用数千个并行工作进程实现了大规模扩展。
“Union.ai 丰富的专业知识使我们能够将精力集中在关键的ADAS相关功能上,快速行动,并信赖Union.ai来规模化地提供数据,”
– Alborz Alavian,Woven by Toyota 高级工程经理。
阅读关于Woven by Toyota迁移到Union.ai的完整案例研究。
结论
Union.ai 和 Flyte 为Amazon EKS上的AI/ML工作流(如构建自主系统、训练LLM或编排复杂的数据管道)提供了可靠、可扩展AI的基础。要开始使用,请选择您的路径:
- 企业就绪 – 通过AWS Marketplace(ISVA合作伙伴)部署Union.ai
- 资源感知AI编排 – 试用 v2
- 开源 – 在flyte.org上尝试Flyte
- 快速启动 – 使用Amazon EKS 蓝图中的AI 部署您的第一个AI管道
关于作者
 ND Ngoka 是AWS的高级解决方案架构师,专注于AI/ML和存储技术。他指导客户完成复杂的架构决策,使他们能够构建驱动业务成果的弹性、可扩展的解决方案。
ND Ngoka 是AWS的高级解决方案架构师,专注于AI/ML和存储技术。他指导客户完成复杂的架构决策,使他们能够构建驱动业务成果的弹性、可扩展的解决方案。
 Samhita Alla 是Union.ai的合作伙伴高级解决方案工程师,负责领导跨AI堆栈的战略集成技术执行,从分布式训练和实验跟踪到数据平台集成。她与合作伙伴和跨职能团队紧密合作,以评估可行性、构建生产就绪的解决方案并提供推动实际采用的技术内容。
Samhita Alla 是Union.ai的合作伙伴高级解决方案工程师,负责领导跨AI堆栈的战略集成技术执行,从分布式训练和实验跟踪到数据平台集成。她与合作伙伴和跨职能团队紧密合作,以评估可行性、构建生产就绪的解决方案并提供推动实际采用的技术内容。
 Kristy Cook 是Union.ai的合作伙伴主管,负责建立跨AI/ML生态系统的战略联盟,专注于持续增长。她在Meta、Yahoo和Neustar建立了有影响力的合作伙伴关系,带来了大规模运行AI解决方案的深厚专业知识。
Kristy Cook 是Union.ai的合作伙伴主管,负责建立跨AI/ML生态系统的战略联盟,专注于持续增长。她在Meta、Yahoo和Neustar建立了有影响力的合作伙伴关系,带来了大规模运行AI解决方案的深厚专业知识。
 Jim Fratantoni 是AWS的GenAI客户经理,专注于帮助AI初创公司扩展和与AWS联合销售。他热衷于与创始人合作,共同进入市场并推动企业客户的成功。
Jim Fratantoni 是AWS的GenAI客户经理,专注于帮助AI初创公司扩展和与AWS联合销售。他热衷于与创始人合作,共同进入市场并推动企业客户的成功。
 Theo Rashid 是Amazon的应用科学家,负责构建概率机器学习和预测模型。他是一位活跃的开源贡献者,热衷于机器学习堆栈中的开源工具,从概率编程库到工作流编排。他拥有伦敦帝国理工学院流行病学和生物统计学博士学位。
Theo Rashid 是Amazon的应用科学家,负责构建概率机器学习和预测模型。他是一位活跃的开源贡献者,热衷于机器学习堆栈中的开源工具,从概率编程库到工作流编排。他拥有伦敦帝国理工学院流行病学和生物统计学博士学位。
 Alex Fabisiak 是Amazon的高级应用科学家,从事应用预测和供应链问题。他专长于与最佳策略决策相关的概率和因果建模。他拥有加州大学洛杉矶分校的金融学博士学位。
Alex Fabisiak 是Amazon的高级应用科学家,从事应用预测和供应链问题。他专长于与最佳策略决策相关的概率和因果建模。他拥有加州大学洛杉矶分校的金融学博士学位。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区