



📢 转载信息
原文作者:Haochen Xie, Flora Wang, Hari Prasanna Das, and Yuan Tian
AI 智能体正迅速从简单的聊天界面发展成为能够处理复杂、耗时任务的自主工作者。随着组织部署智能体来训练 机器学习 (ML) 模型、处理大型数据集和运行扩展模拟,模型上下文协议 (MCP) 已成为智能体-服务器集成的标准。但一个关键挑战仍然存在:这些操作可能需要数分钟甚至数小时才能完成,远远超出了典型的会话时间范围。通过使用 Amazon Bedrock AgentCore 和 Strands Agents 来实现持久化状态管理,您可以实现在生产环境中无缝、跨会话的任务执行。想象一下,您的 AI 智能体启动了一个多小时的数据处理作业,用户关闭了笔记本电脑,当用户几天后返回时,系统能够无缝地检索到已完成的结果——同时完全可见任务进度、结果和错误。这一能力将 AI 智能体从对话助手转变为能够处理企业级操作的可靠自主工作者。没有这些架构模式,当连接意外中断时,您将遇到超时错误、资源利用率低下和潜在的数据丢失。
在本文中,我们为您提供了一种实现此目标的全面方法。首先,我们介绍了一种上下文消息策略,它在扩展操作期间在服务器和客户端之间保持持续通信。接下来,我们开发了一个异步任务管理框架,允许您的 AI 智能体启动长期运行的流程而不会阻塞其他操作。最后,我们演示了如何将这些策略与 Amazon Bedrock AgentCore 和 Strands Agents 结合起来,以构建能够可靠处理复杂、耗时操作的生产级 AI 智能体。
处理长期运行任务的常见方法
在为长期运行任务设计 MCP 服务器时,您可能会面临一个基本的架构决策:服务器是应该保持活动连接并提供实时更新,还是应该将任务执行与初始请求分离?这个选择引出了两种截然不同的方法:上下文消息和异步任务管理。
使用上下文消息
上下文消息方法在整个任务执行期间保持 MCP 服务器和客户端之间的持续通信。这是通过使用 MCP 内置的 context 对象向客户端发送周期性通知来实现的。这种方法最适合任务通常在 10-15 分钟内完成且网络连接保持稳定的场景。上下文消息方法具有以下优势:
- 实现简单
- 无需额外的轮询逻辑
- 客户端实现直观
- 开销极小
使用异步任务管理
异步任务管理方法将任务启动与执行和结果检索分离开来。执行 MCP 工具后,该工具会立即返回一个任务启动消息,同时在后台执行任务。这种方法在要求严苛的企业场景中表现出色,在这些场景中,任务可能运行数小时,用户需要灵活地断开和重新连接,并且系统可靠性至关重要。异步任务管理方法提供了以下优势:
- 真正的“即发即忘”操作
- 在任务继续处理时可以安全地断开客户端连接
- 通过持久化存储防止数据丢失
- 支持长期运行操作(数小时)
- 对网络中断的弹性
- 异步工作流
上下文消息
我们首先探讨上下文消息方法,它为在保持活动连接的同时处理中等长度的操作提供了一个直接的解决方案。这种方法直接基于 MCP 的现有功能构建,需要的额外基础设施最少,使其成为扩展智能体处理时间限制的绝佳起点。想象一下,您为一个帮助数据科学家训练 ML 模型的 AI 智能体构建了一个 MCP 服务器。当用户要求智能体训练一个复杂模型时,底层过程可能需要 10-15 分钟——远超大多数环境中典型的 30 秒到 2 分钟的 HTTP 超时限制。如果没有适当的策略,连接将中断,操作将失败,用户将感到沮丧。在 MCP 客户端实现的 Streamable HTTP 传输中,这些超时限制尤其具有限制性。当任务执行超过超时限制时,连接会中止,智能体的工作流会中断。这就是上下文消息发挥作用的地方。下图说明了实现上下文消息方法时的工作流。上下文消息使用 MCP 的内置 context 对象,从服务器向 MCP 客户端发送周期性信号,从而在更长的操作过程中保持连接处于活动状态。您可以将其视为发送“心跳”消息,以帮助防止连接超时。
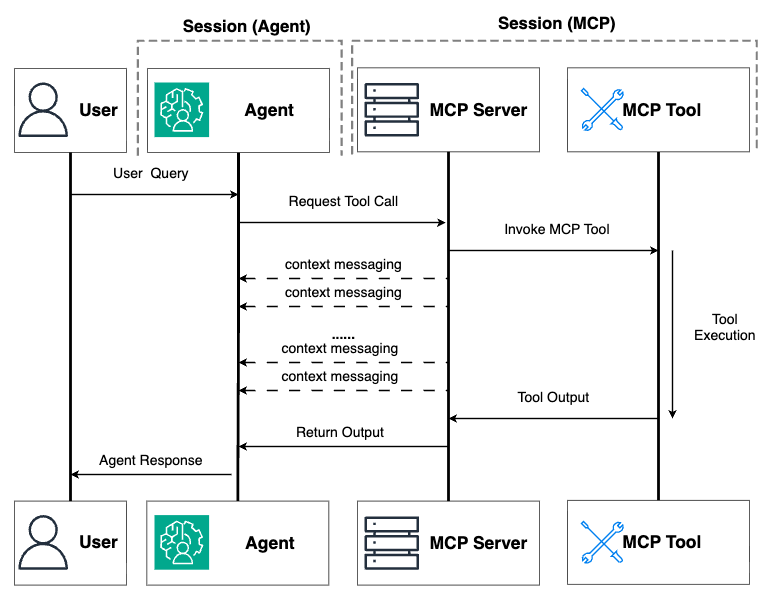
图 1:上下文消息方法中工作流的说明
以下是实现上下文消息的代码示例:
from mcp.server.fastmcp import Context, FastMCP import asyncio mcp = FastMCP(host="0.0.0.0", stateless_http=True) @mcp.tool() async def model_training(model_name: str, epochs: int, ctx: Context) -> str: """Execute a task with progress updates.""" for i in range(epochs): # Simulate long running time training work progress = (i + 1) / epochs await asyncio.sleep(5) await ctx.report_progress( progress=progress, total=1.0, message=f"Step {i + 1}/{epochs}", ) return f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82." if __name__ == "__main__": mcp.run(transport="streamable-http")这里的关键元素是在工具定义中包含 Context 参数。当您包含带有 Context 类型提示的参数时,FastMCP 会自动注入此对象,使您可以访问 ctx.info() 和 ctx.report_progress() 等方法。这些方法在不终止工具执行的情况下向连接的客户端发送消息。
训练循环中对 report_progress() 的调用充当了那些关键的心跳消息,确保 MCP 连接在整个扩展处理期间保持活动状态。
对于许多实际场景,很难量化确切的进度——例如在处理不可预测的数据集或进行外部 API 调用时。在这些情况下,您可以实现一个基于时间的心跳系统:
from mcp.server.fastmcp import Context, FastMCP import time import asyncio mcp = FastMCP(host="0.0.0.0", stateless_http=True) @mcp.tool() async def model_training(model_name: str, epochs: int, ctx: Context) -> str: """Execute a task with progress updates.""" done_event = asyncio.Event() start_time = time.time() async def timer(): while not done_event.is_set(): elapsed = time.time() - start_time await ctx.info(f"Processing ......: {elapsed:.1f} seconds elapsed") await asyncio.sleep(5) # Check every 5 seconds return timer_task = asyncio.create_task(timer()) ## main task##################################### for i in range(epochs): # Simulate long running time training work progress = (i + 1) / epochs await asyncio.sleep(5) ################################################# # Signal the timer to stop and clean up done_event.set() await timer_task total_time = time.time() - start_time print(f"⏱️ Total processing time: {total_time:.2f} seconds") return f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82." if __name__ == "__main__": mcp.run(transport="streamable-http")此模式创建了一个与主任务并行运行的异步计时器,每隔几秒发送一次定期状态更新。使用 asyncio.Event() 进行协调有助于在主要工作完成后干净地停止计时器。
何时使用上下文消息
上下文消息最适用于以下情况:
- 任务完成时间为 1–15 分钟*
- 网络连接通常稳定
- 客户端会话可以在操作过程中保持活动状态
- 您需要在处理过程中进行实时进度更新
- 任务具有可预测的、有限的执行时间和明确的终止条件
*注意:“15 分钟”基于 Amazon Bedrock AgentCore 提供的同步请求的最大时间。有关 Bedrock AgentCore 服务配额的更多详细信息,请参阅 Amazon Bedrock AgentCore 的配额。如果托管智能体的基础架构未实施硬性时间限制,请在对可能挂起或无限期运行的任务使用此方法时极其谨慎。如果没有适当的保护措施,一个卡住的任务可能会无限期地保持打开的连接,从而导致资源耗尽、无响应的进程以及潜在的系统范围的稳定性问题。
以下是一些需要考虑的重要限制:
- 需要持续连接 – 客户端会话必须在整个操作过程中保持活动状态。如果用户关闭浏览器或网络中断,工作将会丢失。
- 资源消耗 – 保持连接打开会消耗服务器和客户端资源,可能会增加长期运行操作的成本。
- 网络依赖 – 网络不稳定仍然可能中断过程,需要完全重启。
- 最终超时限制 – 大多数基础设施都有无法通过心跳消息规避的硬性超时限制。
因此,对于可能需要数小时的真正长期运行操作,或对于需要用户断开和稍后重新连接的场景,您将需要更强大的异步任务管理方法。
异步任务管理
与要求客户端必须保持持续连接的上下文消息方法不同,异步任务管理模式遵循“即发即忘”模型:
- 任务启动 – 客户端发出请求以启动任务并立即收到一个任务 ID
- 后台处理 – 服务器异步执行工作,无需客户端连接
- 状态检查 – 客户端可以随时使用任务 ID 重新连接以检查进度
- 结果检索 – 任务完成后,结果将保持可用,供客户端在任何时候重新连接时检索
下图说明了异步任务管理方法中的工作流。
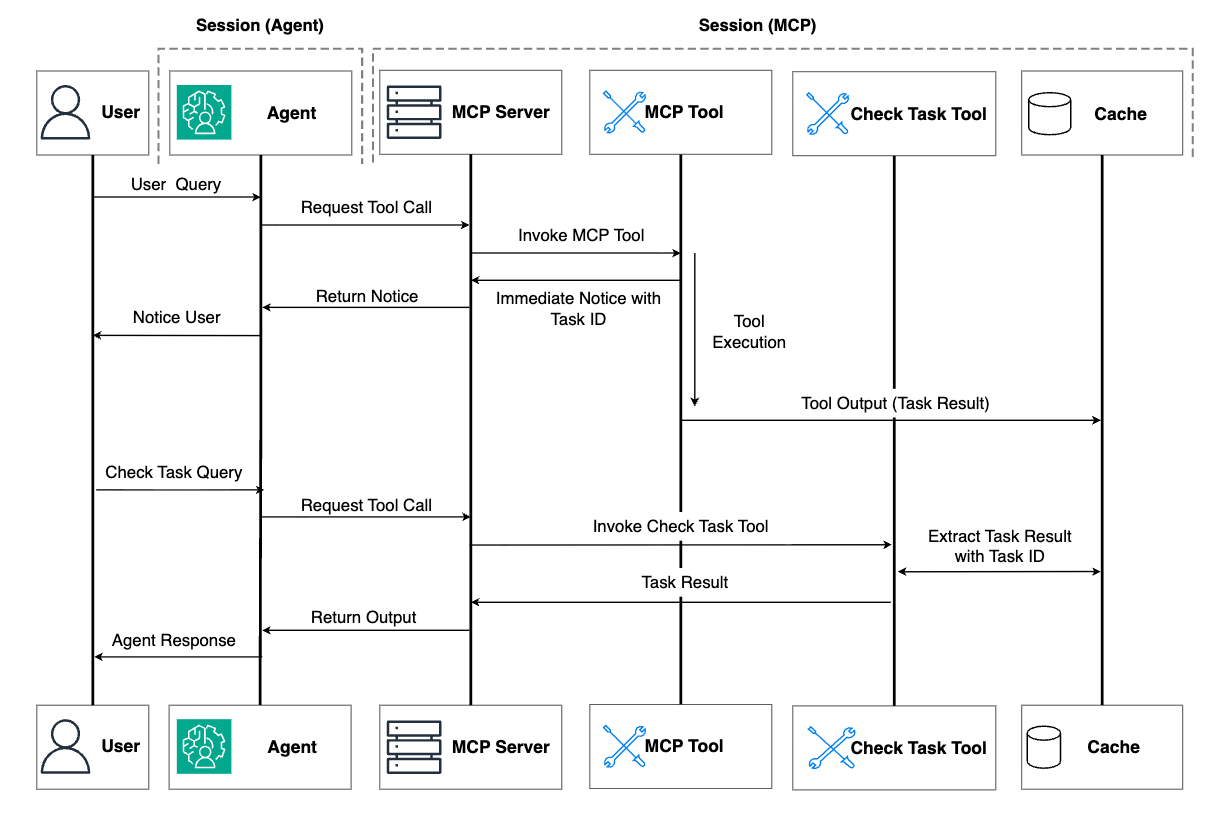
图 2:异步任务管理方法中工作流的说明
此模式类似于您在企业环境中与批处理系统的交互方式——提交作业、断开连接,并在方便时返回检查。以下是一个演示这些原则的实际实现:
from mcp.server.fastmcp import Context, FastMCP import asyncio import uuid from typing import Dict, Any mcp = FastMCP(host="0.0.0.0", stateless_http=True) # task storage tasks: Dict[str, Dict[str, Any]] = {} async def _execute_model_training( task_id: str, model_name: str, epochs: int ): """Background task execution.""" tasks[task_id]["status"] = "running" for i in range(epochs): tasks[task_id]["progress"] = (i + 1) / epochs await asyncio.sleep(2) tasks[task_id]["result"] = f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82." tasks[task_id]["status"] = "completed" @mcp.tool() def model_training( model_name: str, epochs: int = 10 ) -> str: """Start model training task.""" task_id = str(uuid.uuid4()) tasks[task_id] = { "status": "started", "progress": 0.0, "task_type": "model_training" } asyncio.create_task(_execute_model_training(task_id, model_name, epochs)) return f"Model Training task has been initiated with task ID: {task_id}. Please check back later to monitor completion status and retrieve results." @mcp.tool() def check_task_status(task_id: str) -> Dict[str, Any]: """Check the status of a running task.""" if task_id not in tasks: return {"error": "task not found"} task = tasks[task_id] return { "task_id": task_id, "status": task["status"], "progress": task["progress"], "task_type": task.get("task_type", "unknown") } @mcp.tool() def get_task_results(task_id: str) -> Dict[str, Any]: """Get results from a completed task.""" if task_id not in tasks: return {"error": "task not found"} task = tasks[task_id] if task["status"] != "completed": return {"error": f"task not completed. Current status: {task['status']}"} return { "task_id": task_id, "status": task["status"], "result": task["result"] } if __name__ == "__main__": mcp.run(transport="streamable-http")此实现创建了一个任务管理系统,其中包含三个不同的 MCP 工具:
model_training()– 启动新任务的入口点。它不是直接执行工作,而是:- 使用通用唯一标识符 (UUID) 生成一个唯一的任务标识符
- 在存储字典中创建一个初始任务记录
- 使用
asyncio.create_task()将实际处理启动为一个后台任务 - 立即返回任务 ID,允许客户端断开连接
check_task_status()– 允许客户端根据需要监控进度,方法是:- 在存储字典中按 ID 查找任务
- 返回当前状态和进度信息
- 为缺失的任务提供适当的错误处理
get_task_results()– 准备就绪时检索已完成的结果,方法是:- 验证任务是否存在且已完成
- 返回在后台处理期间存储的结果
- 在结果尚未准备好时提供清晰的错误消息
实际工作发生在私有的 _execute_model_training() 函数中,该函数在初始客户端请求完成后在后台独立运行。它会随着进度的推进更新共享存储中的任务状态和进度,使其信息可供后续的状态检查使用。
需要考虑的限制
尽管异步任务管理方法有助于解决连接问题,但它也带来了一系列自身的限制:
- 用户体验摩擦 – 该方法要求用户手动检查任务状态、跨会话记住任务 ID,并明确请求结果,从而增加了交互的复杂性。
- 易失性内存存储 – 使用内存中存储(如我们的示例所示)意味着如果服务器重启,任务和结果将会丢失,这使得该解决方案在没有持久存储的情况下不适合生产环境。
- 无服务器环境限制 – 在短暂的无服务器环境中,实例在不活动一段时间后会自动终止,导致内存中任务状态永久丢失。这造成了一种矛盾的情况:旨在处理长期运行操作的解决方案反而容易受到其旨在支持的持续时间的影响。除非用户保持定期签入以帮助防止会话时间限制,否则任务和结果都可能消失。
迈向稳健的解决方案
为了解决这些关键限制,您需要包含能够在服务器重启和实例终止后得以保留的外部持久性。这就是与专用存储服务集成变得至关重要的地方。通过使用外部智能体内存存储系统,您可以从根本上改变任务信息在何处以及如何维护。该方法不再依赖 MCP 服务器的易失性内存,而是使用持久的外部智能体内存存储服务,这些服务在服务器状态如何时仍然可用。
这种增强方法的关键创新在于,当 MCP 服务器运行长期任务时,它会将中间或最终结果直接写入外部内存存储中,例如智能体可以访问的 Amazon Bedrock AgentCore Memory,如下图所示。这有助于抵御两种运行时故障:
- 运行 MCP 服务器的实例在任务完成后可能因不活动而被终止
- 托管智能体本身的实例在短暂的无服务器环境中可能会被回收
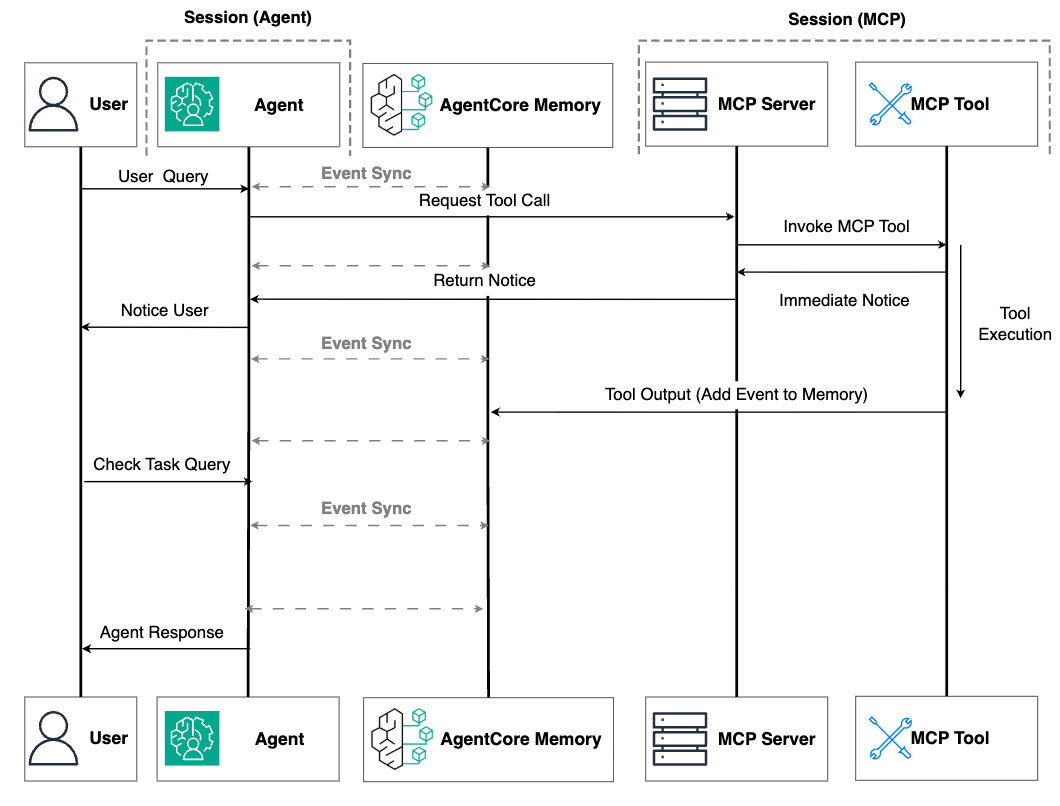
图 3. MCP 与外部内存的集成
通过外部内存存储,当用户返回与智能体交互时——无论是几分钟、几小时还是几天后——智能体都可以从持久存储中检索已完成的任务结果。这种方法最大限度地减少了运行时依赖性:即使 MCP 服务器和智能体实例都被终止,任务结果仍然安全地保存,并在需要时可供访问。
下一节将探讨如何使用 Amazon Bedrock AgentCore Runtime 作为无服务器托管环境、使用 AgentCore Memory 进行持久化智能体内存存储,以及使用 Strands Agents 框架将这些组件编排成一个连贯的系统,该系统能够在会话边界之间维护任务状态。
Amazon Bedrock AgentCore 和 Strands Agents 实现
在深入了解实现细节之前,了解在 Amazon Bedrock AgentCore 上托管 MCP 服务器的可用部署选项非常重要。主要有两种方法:Amazon Bedrock AgentCore Gateway 和 AgentCore Runtime。AgentCore Gateway 对调用具有 5 分钟的超时限制,因此不适合托管需要扩展响应时间或长期运行操作的 MCP 服务器。AgentCore Runtime 提供了更大的灵活性,具有 15 分钟的请求超时(用于同步请求)和可调整的最大会话持续时间(用于异步流程;默认持续时间为 8 小时)以及空闲会话超时。虽然您可以在传统服务器环境(Serverful)中托管 MCP 服务器以获得无限的执行时间,但 AgentCore Runtime 为大多数生产场景提供了最佳平衡。您可以获得无服务器优势,例如自动扩展、按使用付费定价和无需基础设施管理,而可调整的最大会话持续时间可以覆盖大多数现实世界中的长期运行任务——从数据处理和模型训练到报告生成和复杂模拟。您可以使用此方法构建复杂的 AI 智能体,而无需管理服务器的操作开销,仅将服务器部署保留给真正需要多天执行的罕见情况。有关 AgentCore Runtime 和 AgentCore Gateway 服务配额的更多信息,请参阅 Amazon Bedrock AgentCore 的配额。
接下来,我们将介绍实现过程,如下一个图中所示。此实现包含两个相互连接的组件:执行长期任务并将结果写入 AgentCore Memory 的 MCP 服务器,以及管理对话流程并在需要时检索这些结果的智能体。这种架构创造了一种无缝体验,用户可以在漫长的过程中断开连接,稍后返回时会发现他们的结果已在等待他们。
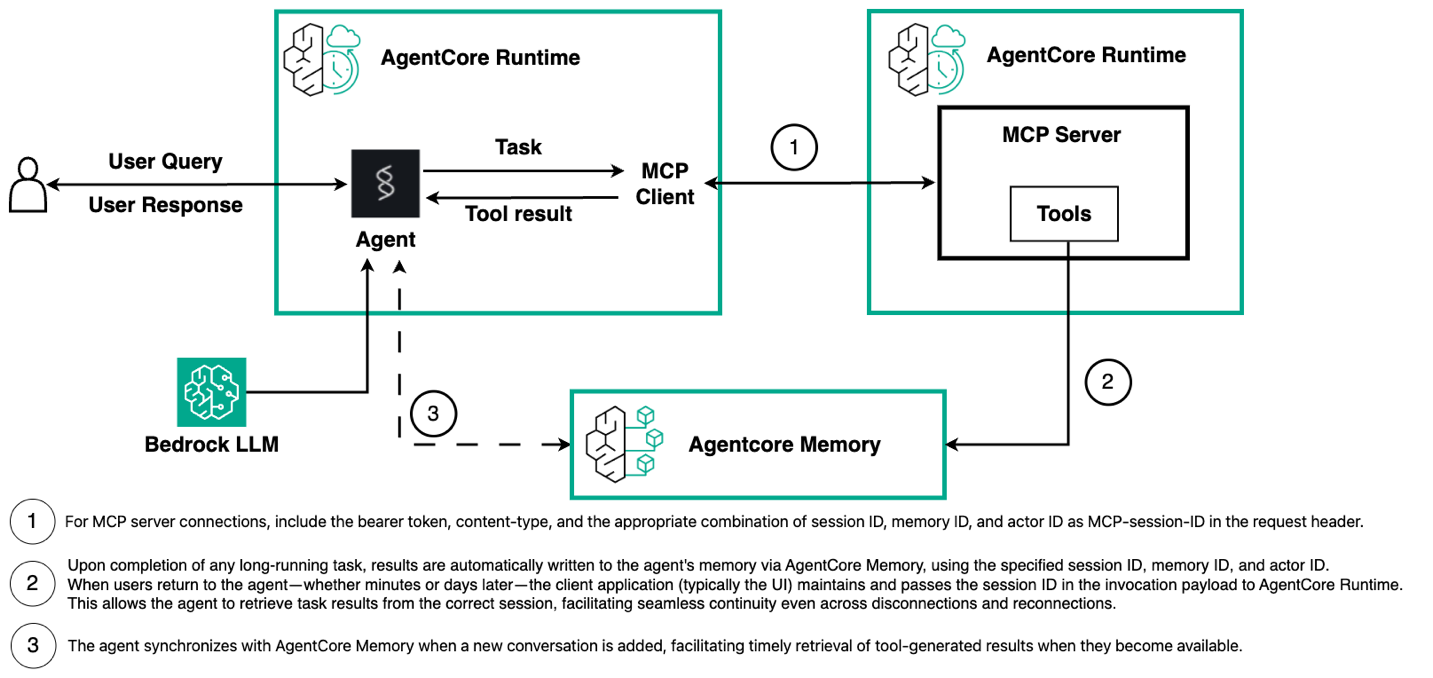
MCP 服务器实现
让我们看看我们的 MCP 服务器实现如何使用 AgentCore Memory 来实现持久性:
from mcp.server.fastmcp import Context, FastMCP import asyncio import uuid from typing import Dict, Any import json from bedrock_agentcore.memory import MemoryClient mcp = FastMCP(host="0.0.0.0", stateless_http=T... [内容被截断]🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区