



📢 转载信息
原文链接:https://machinelearningmastery.com/build-semantic-search-with-llm-embeddings/
原文作者:Iván Palomares Carrascosa
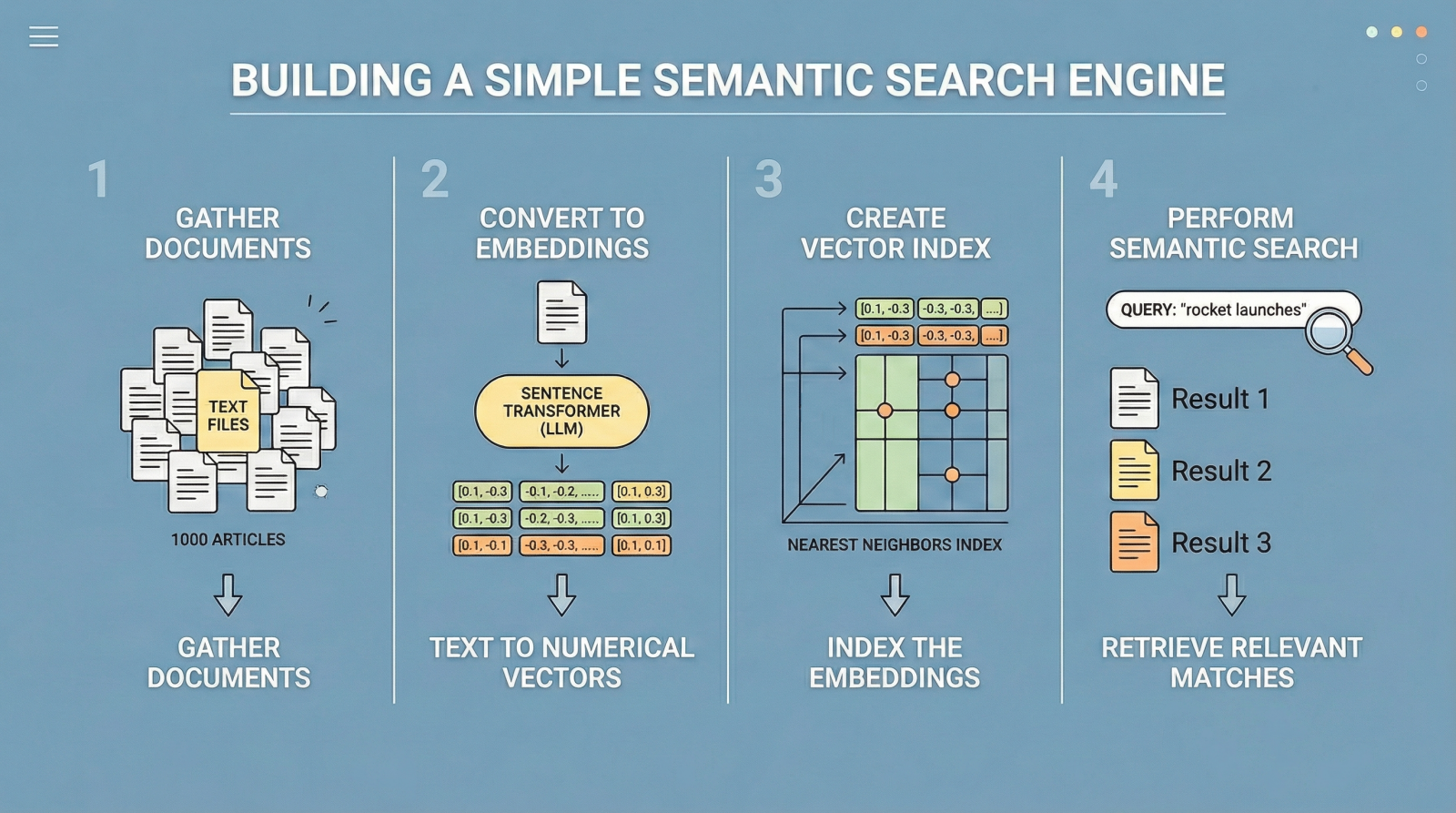
在本文中,您将学习如何使用简单的语义搜索引擎,该引擎基于句子嵌入和最近邻搜索。
我们将涵盖的主题包括:
- 理解基于关键词的搜索的局限性。
- 使用句子转换器模型生成文本嵌入。
- 在Python中实现一个最近邻语义搜索管道。
让我们开始吧。
使用LLM嵌入构建简单的语义搜索引擎
图片来源:Editor
引言
传统的搜索引擎在历史上一直依赖于关键词搜索。换句话说,给定一个类似“日本福冈最好的寺庙和神社”的查询,结果是基于关键词匹配检索的,因此包含“寺庙”、“神社”和“福冈”等词语共现的文本文档被认为是最相关的。
然而,这种经典方法出了名地僵化,因为它在很大程度上依赖于精确的单词匹配,并且会遗漏其他重要的语义细微之处,例如同义词或替代措辞——例如,“幼犬”而不是“小狗”。结果,高度相关的文档可能会被无意中排除。
语义搜索通过关注意义而非精确措辞来解决这一限制。大型语言模型(LLMs)在这里发挥着关键作用,因为其中一些模型经过训练,可以将文本转换为称为嵌入的数值向量表示,这些嵌入编码了文本背后的语义信息。当两个文本如“小型犬生性好奇”和“幼犬生性好奇”被转换为嵌入向量时,由于它们共享相同的含义,这些向量将高度相似。同时,“幼犬生性好奇”和“太宰府是福冈的标志性神社”的嵌入向量将非常不同,因为它们代表不相关的概念。
遵循这一原则——您可以在这里更深入地探讨——本文的其余部分将指导您完成构建一个简洁高效的语义搜索引擎的完整过程。尽管它很简约,但性能却很有效,并且可以作为理解现代搜索和检索系统(如检索增强生成(RAG)架构)如何构建的起点。
下面解释的代码可以在Google Colab或Jupyter Notebook实例中无缝运行。
分步指南
首先,我们为这个实际示例进行必要的导入:
import pandas as pd
import json
from pydantic import BaseModel, Field
from openai import OpenAI
from google.colab import userdata
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler我们将使用一个名为"ag_news"的玩具公共数据集,其中包含新闻文章的文本。以下代码加载数据集并选择前1000篇文章。
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from sklearn.neighbors import NearestNeighbors我们现在加载数据集并提取"text"列,其中包含文章内容。之后,我们打印第一篇文章的一个简短样本以检查数据:
print("Loading dataset...")
dataset = load_dataset("ag_news", split="train[:1000]") # Extract the text column into a Python list
documents = dataset["text"]
print(f"Loaded {len(documents)} documents.")
print(f"Sample: {documents[0][:100]}...")下一步是为我们的1000篇文本获取嵌入向量(数值表示)。如前所述,一些LLM经过专门训练,可以将文本转换为捕获语义特征的数值向量。Hugging Face的句子转换器模型,例如"all-MiniLM-L6-v2",是一个常见的选择。以下代码初始化模型并将文本文档批次编码为嵌入。
print("Loading embedding model...")
model = SentenceTransformer("all-MiniLM-L6-v2") # Convert text documents into numerical vector embeddings
print("Encoding documents (this may take a few seconds)...")
document_embeddings = model.encode(documents, show_progress_bar=True)
print(f"Created {document_embeddings.shape[0]} embeddings.")接下来,我们初始化一个NearestNeighbors对象,它实现了一种最近邻策略来查找给定查询的k个最相似的文档。就嵌入而言,这意味着识别最接近的向量(最小的角度距离)。我们使用余弦度量,其中越相似的向量具有越小的余弦距离(和越高的余弦相似度值)。
search_engine = NearestNeighbors(n_neighbors=5, metric="cosine")
search_engine.fit(document_embeddings)
print("Search engine is ready!")我们搜索引擎的核心逻辑封装在以下函数中。它接受一个纯文本查询,通过top_k指定要检索的顶级结果数量,计算查询嵌入,并从索引中检索最近邻。
函数内的循环打印按相似度排名的前k个结果:
def semantic_search(query, top_k=3):
# Embed the incoming search query
query_embedding = model.encode([query])
# Retrieve the closest matches
distances, indices = search_engine.kneighbors(query_embedding, n_neighbors=top_k)
print(f"\n🔍 Query: '{query}'")
print("-" * 50)
for i in range(top_k):
doc_idx = indices[0][i]
# Convert cosine distance to similarity (1 - distance)
similarity = 1 - distances[0][i]
print(f"Result {i+1} (Similarity: {similarity:.4f})")
print(f"Text: {documents[int(doc_idx)][:150]}...\n")就是这样。要测试该函数,我们可以构建几个示例搜索查询:
semantic_search("Wall street and stock market trends")
semantic_search("Space exploration and rocket launches")结果按相似度排序(为清晰起见在此处截断):
🔍 Query: 'Wall street and stock market trends'
--------------------------------------------------
Result 1 (Similarity: 0.6258)
Text: Stocks Higher Despite Soaring Oil Prices NEW YORK - Wall Street shifted higher Monday as bargain hunters shrugged off skyrocketing oil prices and boug...
Result 2 (Similarity: 0.5586)
Text: Stocks Sharply Higher on Dip in Oil Prices NEW YORK - A drop in oil prices and upbeat outlooks from Wal-Mart and Lowe's prompted new bargain-hunting o...
Result 3 (Similarity: 0.5459)
Text: Strategies for a Sideways Market (Reuters) Reuters - The bulls and the bears are in this together, scratching their heads and wondering what's t...
🔍 Query: 'Space exploration and rocket launches'
--------------------------------------------------
Result 1 (Similarity: 0.5803)
Text: Redesigning Rockets: NASA Space Propulsion Finds a New Home (SPACE.com) SPACE.com - While the exploration of the Moon and other planets in our solar s...
Result 2 (Similarity: 0.5008)
Text: Canadian Team Joins Rocket Launch Contest (AP) AP - The #36;10 million competition to send a private manned rocket into space started looking more li...
Result 3 (Similarity: 0.4724)
Text: The Next Great Space Race: SpaceShipOne and Wild Fire to Go For the Gold (SPACE.com) SPACE.com - A piloted rocket ship race to claim a #36;10 million...总结
我们在这里构建的内容可以看作是通往检索增强生成系统的门户。虽然这个例子有意地很简单,但像这样简单的语义搜索引擎构成了现代将语义搜索与大型语言模型相结合的架构的基础检索层。
既然您已经了解了如何构建一个基本的语义搜索引擎,您可能希望更深入地探索检索增强生成系统。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区