



📢 转载信息
原文链接:https://www.kdnuggets.com/visualizing-patterns-in-solutions-how-data-structure-affects-coding-style
原文作者:Nate Rosidi, KDnuggets Market Trends & SQL Content Specialist
 Image by Author
Image by Author
引言
当你解决足够多的面试式数据问题后,你就会开始注意到一个有趣的现象:数据集的“形状”会悄悄地决定你的编码风格。一个时间序列表会引导你使用窗口函数。一个星型模式会让你陷入JOIN链和GROUP BY。一个pandas任务,涉及两个DataFrame,几乎会直接让你想到.merge()和isin()。
本文将这种直觉转化为可衡量的数据。通过一系列代表性的SQL和pandas问题,我们将识别出基本的代码结构特征(如常用表表达式(CTE)的使用、窗口函数的使用频率、常见的pandas技术),并阐述哪些元素占主导地位以及其背后的原因。
数据结构为何改变你的编码风格
数据问题与其说是逻辑问题,不如说是包裹在表格中的约束条件:
行依赖于其他行(时间、排名、“前一个值”)
如果每一行的答案都依赖于相邻的行(例如昨天的温度、上一笔交易、累积总计),那么解决方案自然会倾向于使用窗口函数,如LAG()、LEAD()、ROW_NUMBER()和DENSE_RANK()。
以这个面试问题的表为例:

在给定日期,每个客户的结果无法孤立地确定。在将订单成本聚合到客户-日期级别后,每一行都需要与同一天内的其他客户进行比较,以确定哪个总计最高。
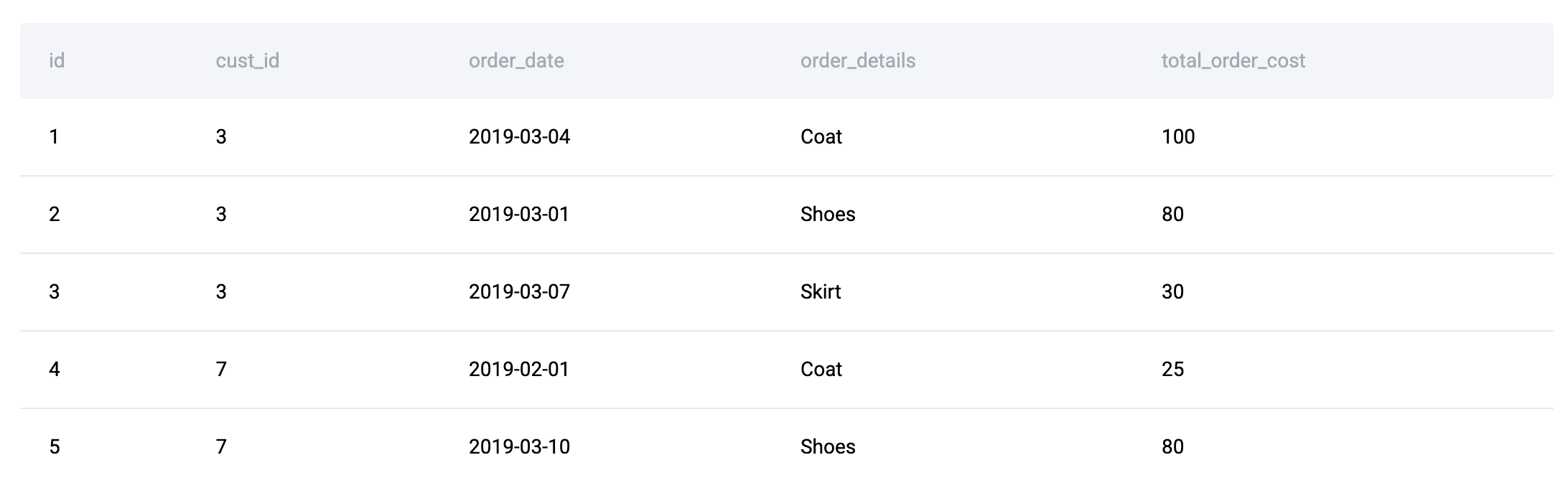
由于一行答案的确定性取决于其在某个时间分区内相对于同行的排名,这种数据集的形状自然会导致使用窗口函数,如RANK()或DENSE_RANK(),而不是简单的聚合。
多个具有角色的表(维度 vs. 事实)
当一个表描述实体,另一个表描述事件时,解决方案通常会倾向于JOIN + GROUP BY模式(SQL)或.merge() + .groupby()模式(pandas)。
例如,在这个面试问题中,数据表如下:

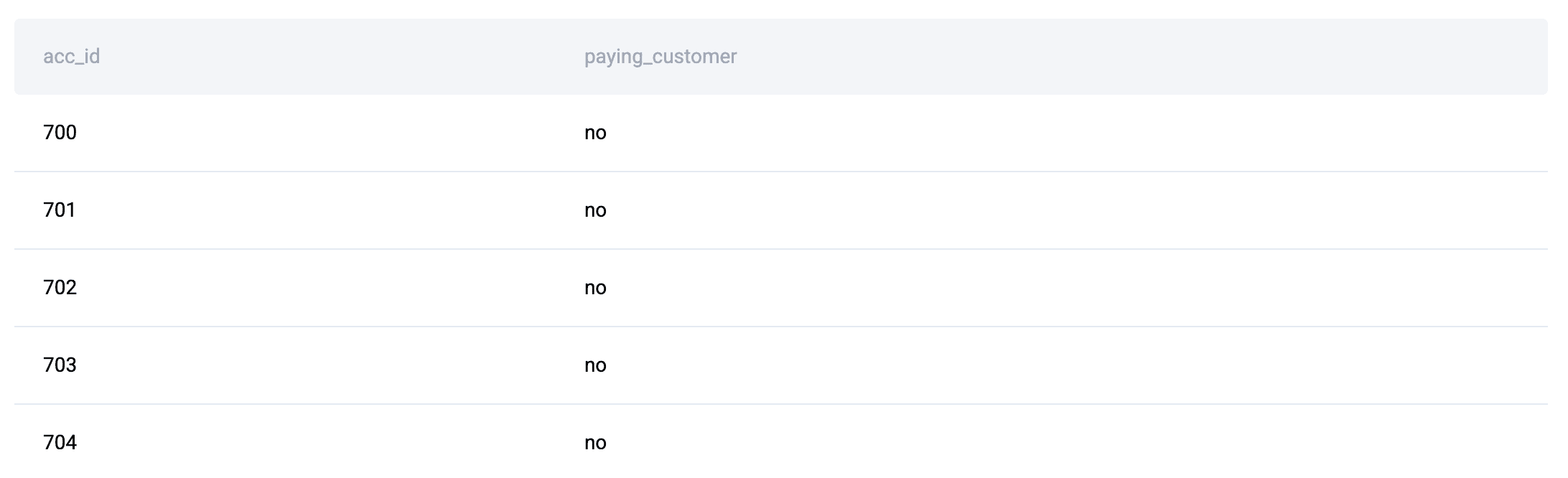
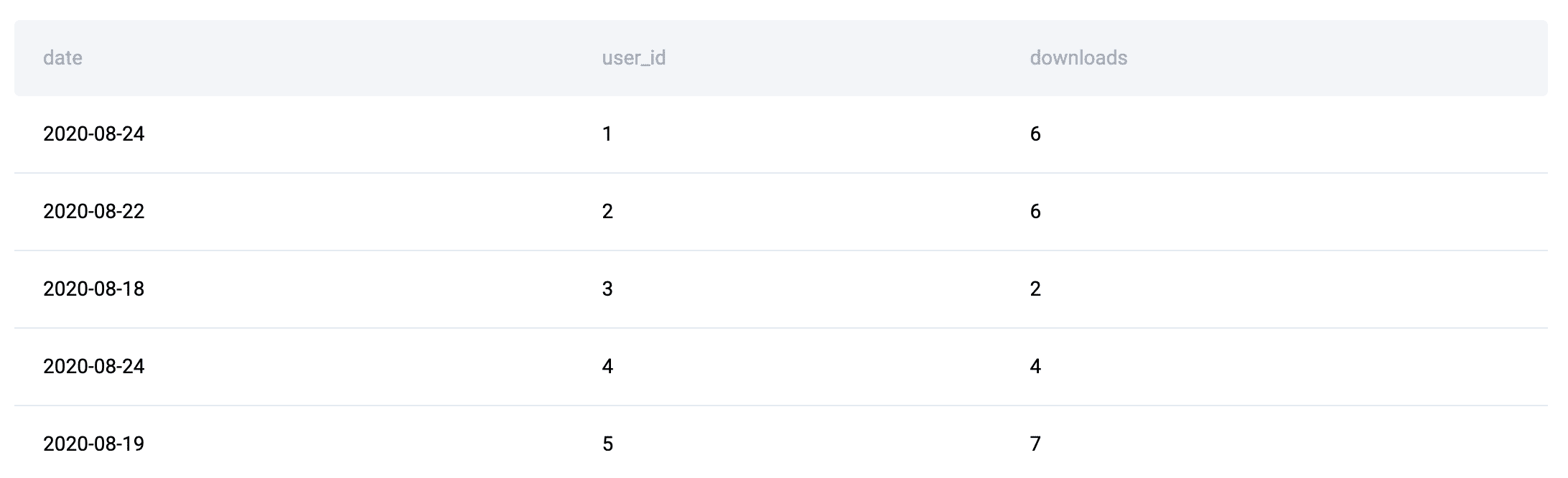
在这个例子中,由于实体属性(用户和账户状态)与事件数据(下载)是分开的,逻辑必须首先使用JOIN将它们重新组合,然后才能进行有意义的聚合(精确的维度)。这种事实模式是创建JOIN + GROUP BY解决方案的原因。
具有排除逻辑的小输出(反JOIN模式)
询问“谁从未做过X”的问题通常会转化为LEFT JOIN ... IS NULL / NOT EXISTS(SQL)或~df['col'].isin(...)(pandas)。
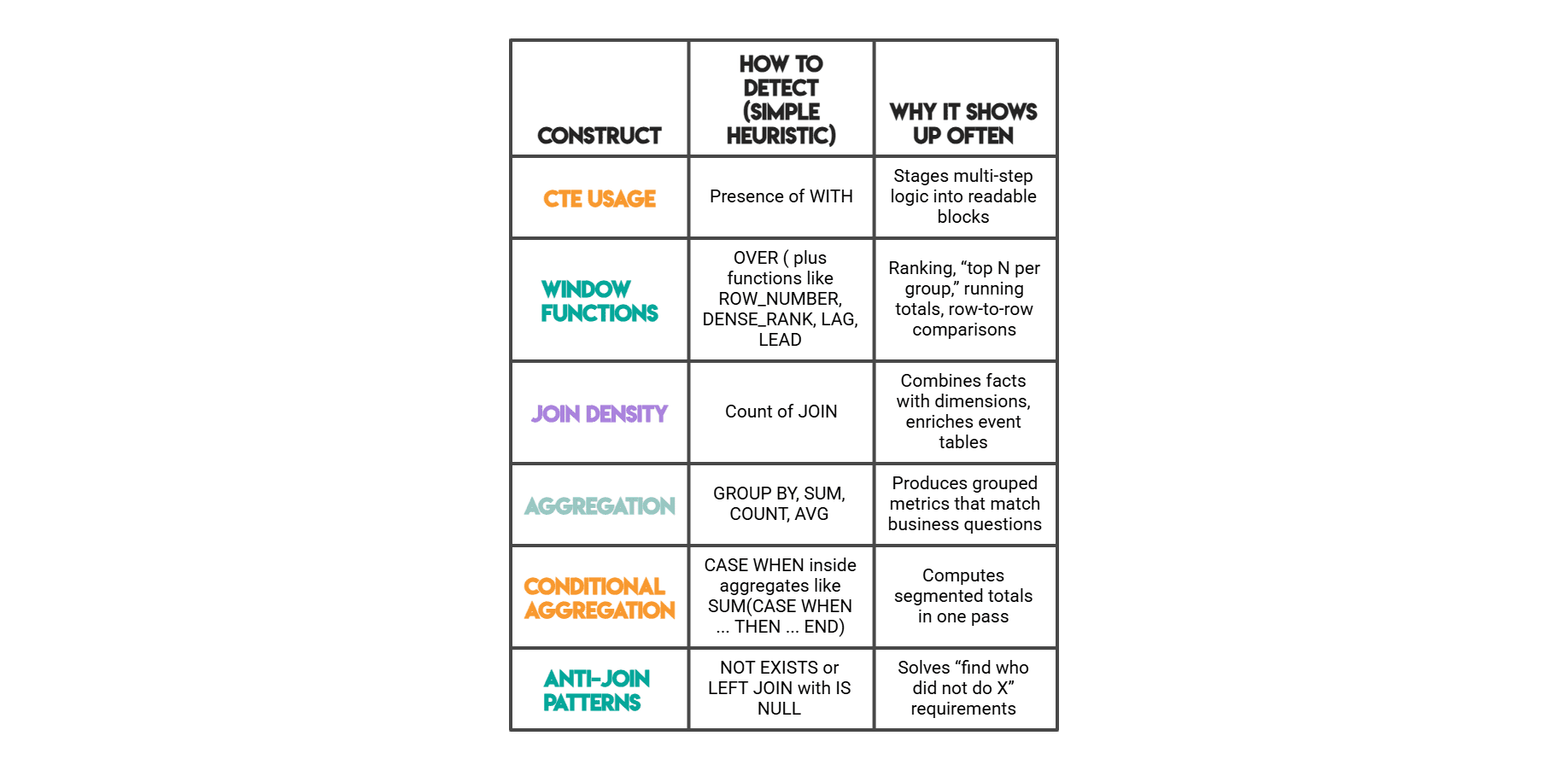
我们测量什么:代码结构特征
为了比较不同解决方案之间的“编码风格”,识别出一组可从SQL文本和Python代码中提取出来的基本可观察特征是有益的。
虽然这些可能不是衡量解决方案质量(例如正确性或效率)的完美指标,但它们可以作为分析师如何处理数据集的可靠信号。
我们测量的SQL特征
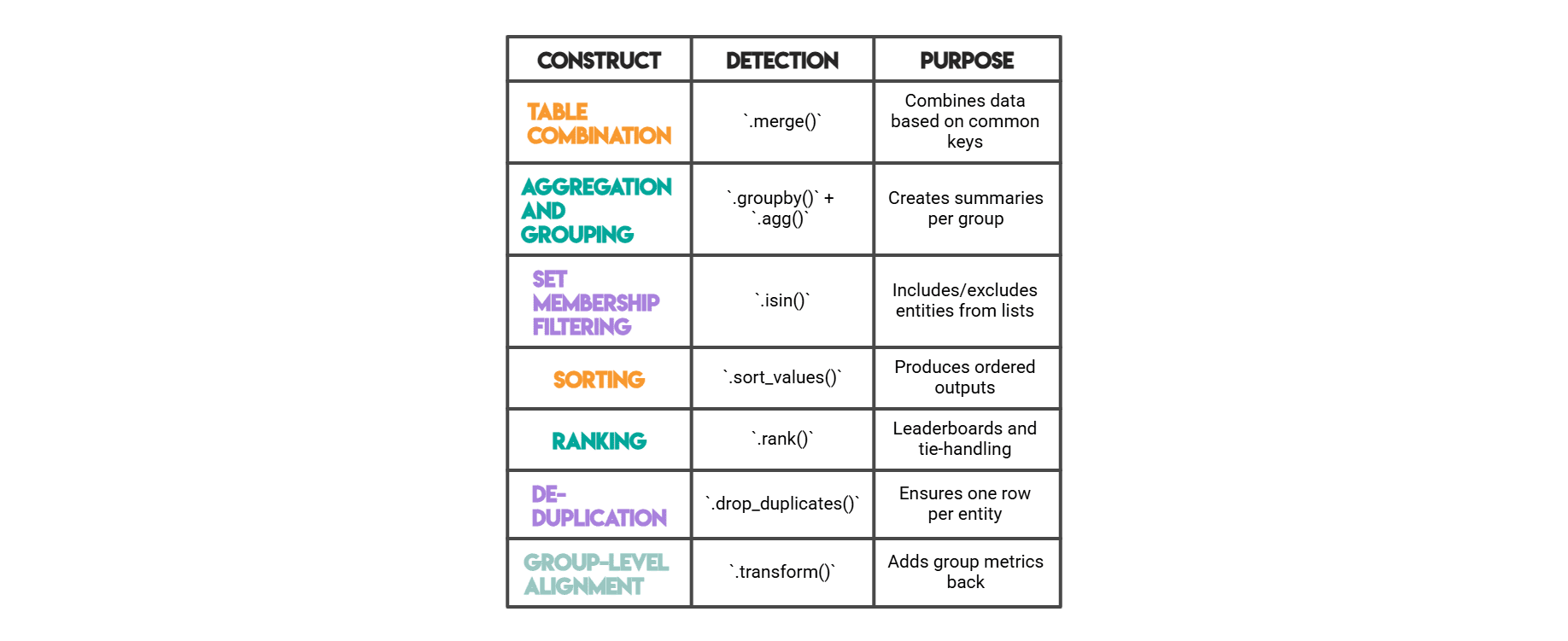
我们测量的Pandas特征
哪些构造最常见
为了超越轶事观察并量化这些模式,你需要一种更直接、更一致的方法来直接从解决方案代码中提取结构化信号。
作为这个工作流程的一个具体锚点,我们使用了StrataScratch平台上的所有教育性问题。
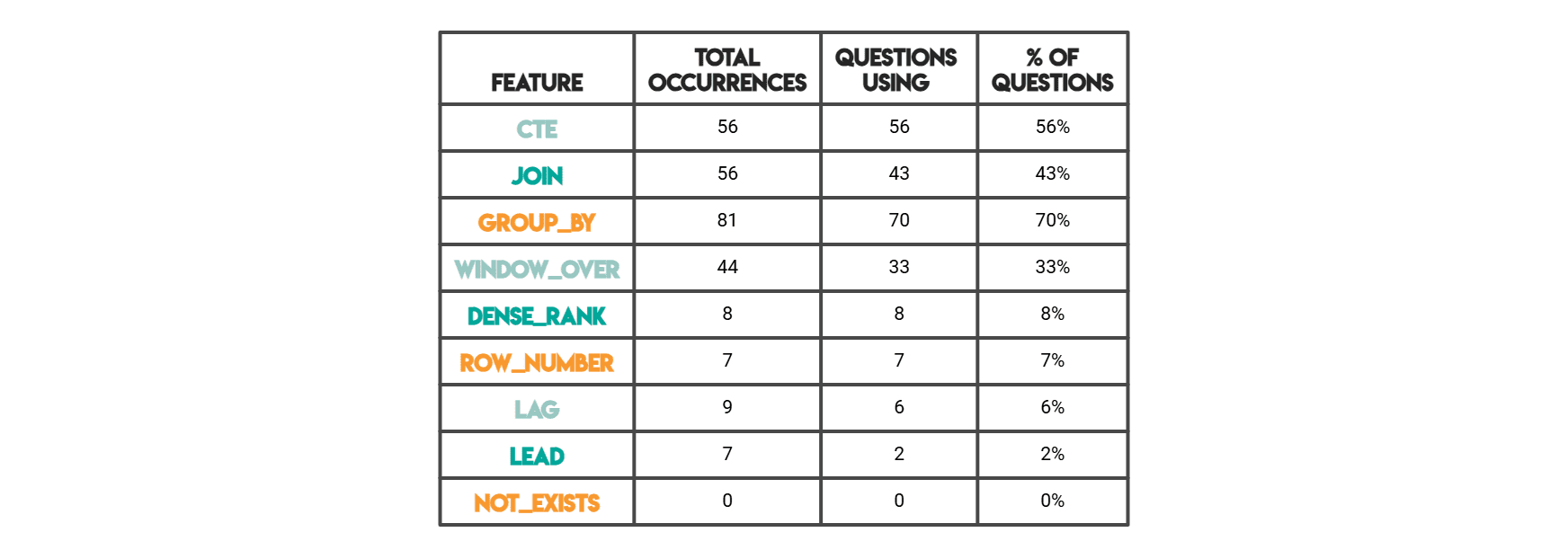
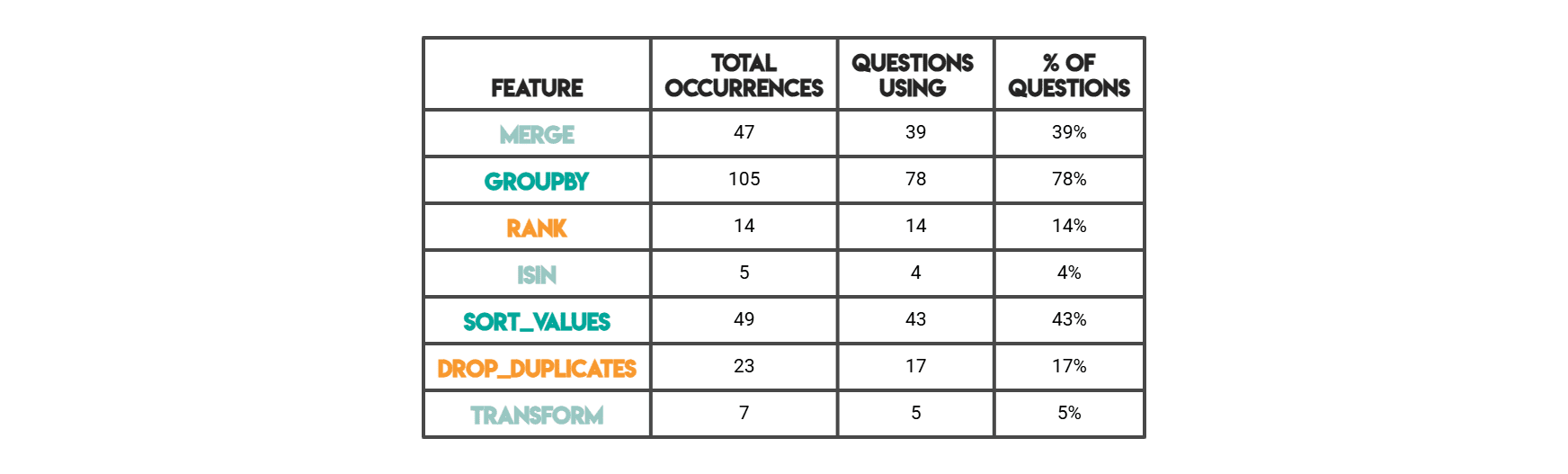
在下面的结果中,“总出现次数”是模式在所有代码中出现的原始计数。一个问题的解决方案可能使用3次JOIN,这3次都会被计入。 “使用该问题的数量”是指有多少个独立的问题至少出现过一次该特征(即每个问题“使用/未使用”的二元状态)。
这种方法将每个解决方案简化为有限的可观察特征集,使我们能够一致且可重现地比较问题之间的编码风格,并将数据集结构与主要构造直接关联起来。
SQL特征
Pandas特征(Python解决方案)
特征提取代码
下面,我们展示了使用的代码片段,你可以在自己的解决方案中使用(或用自己的话改写答案)并从代码文本中提取特征。
SQL特征提取(示例)
import re from collections import Counter sql = # insert code here SQL_FEATURES = { "cte": r"\bWITH\b", "join": r"\bJOIN\b", "group_by": r"\bGROUP\s+BY\b", "window_over": r"\bOVER\s*\(", "dense_rank": r"\bDENSE_RANK\b", "row_number": r"\bROW_NUMBER\b", "lag": r"\bLAG\b", "lead": r"\bLEAD\b", "not_exists": r"\bNOT\s+EXISTS\b", } def extract_sql_features(sql: str) -> Counter: sql_u = sql.upper() return Counter({k: len(re.findall(p, sql_u)) for k, p in SQL_FEATURES.items()})
Pandas特征提取(示例)
import re from collections import Counter pandas = # paste code here PD_FEATURES = { "merge": r"\.merge\s*\(", "groupby": r"\.groupby\s*\(", "rank": r"\.rank\s*\(", "isin": r"\.isin\s*\(", "sort_values": r"\.sort_values\s*\(", "drop_duplicates": r"\.drop_duplicates\s*\(", "transform": r"\.transform\s*\(", } def extract_pd_features(code: str) -> Counter: return Counter({k: len(re.findall(p, code)) for k, p in PD_FEATURES.items()})现在我们来更详细地讨论一下我们注意到的模式。
SQL频率亮点
窗口函数在“每日最高”和“允许平局的排名”任务中激增
例如,在这个面试问题中,我们需要计算每日每客户的总计,然后为每个日期选择最高的结果,包括平局。这是一个自然会导致窗口函数(如RANK()或DENSE_RANK())的需求,按日期分区。
解决方案如下:
WITH customer_daily_totals AS ( SELECT o.cust_id, o.order_date, SUM(o.total_order_cost) AS total_daily_cost FROM orders o WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01' GROUP BY o.cust_id, o.order_date ), ranked_daily_totals AS ( SELECT cust_id, order_date, total_daily_cost, RANK() OVER ( PARTITION BY order_date ORDER BY total_daily_cost DESC ) AS rnk FROM customer_daily_totals ) SELECT c.first_name, rdt.order_date, rdt.total_daily_cost AS max_cost FROM ranked_daily_totals rdt JOIN customers c ON rdt.cust_id = c.id WHERE rdt.rnk = 1 ORDER BY rdt.order_date;
这种两步方法——先聚合,然后按日期排名——解释了为什么窗口函数对于需要保留平局的“每组最高”场景是理想的,而基本的GROUP BY逻辑则不足以完成。
当问题涉及分阶段计算时,CTE的使用增加
通用表表达式(CTE)(或多个CTE)可以保持每个步骤的可读性,并使验证中间结果更容易。
这种结构也反映了分析师的思维方式:将数据准备与业务逻辑分开,使查询更容易理解、排查和适应不断变化的需求。
JOIN加聚合成为多表业务指标的默认选择
当度量存在于一个表中,而维度存在于另一个表中时,你通常无法避免JOIN子句。一旦连接完成,GROUP BY和条件总计(SUM(CASE WHEN ... THEN ... END))通常是最快捷的路径。
Pandas方法亮点
whenever .merge() 出现在答案依赖于一个以上的表时
这个面试问题是pandas模式的一个很好的例子。当行程和支付或折扣逻辑跨越列和表时,你通常首先组合数据,然后进行计数或比较。
import pandas as pd orders_payments = lyft_orders.merge(lyft_payments, on='order_id') orders_payments = orders_payments[(orders_payments['order_date'].dt.to_period('M') == '2021-08') & (orders_payments['promo_code'] == False)] grouped_df = orders_payments.groupby('city').size().rename('n_orders').reset_index() result = grouped_df[grouped_df['n_orders'] == grouped_df['n_orders'].max()]['city']
一旦表被合并,解决方案的其余部分就简化为熟悉的.groupby()和比较步骤,这强调了初始表合并如何简化pandas中的下游逻辑。
为什么这些模式会不断出现
基于时间的表通常需要窗口逻辑
当一个问题涉及到“每天”的总计、天与天之间的比较,或选择每天最高的值时,通常需要有序的逻辑。因此,带有OVER的排名函数很常见,尤其是当需要保留平局时。
多步业务规则受益于分阶段处理
有些问题混合了过滤规则、连接和计算度量。可以写在单个查询中,但这会增加阅读和调试的难度。CTE通过将数据丰富与聚合分开,使其更容易验证,从而解决了这个问题,这与Premium vs Freemium模型一致。
多表问题自然会增加JOIN的密度
如果一个度量依赖于存储在不同表中的属性,则需要进行连接。一旦表被组合起来,分组摘要通常是下一步。这种整体结构反复出现在混合了事件数据和实体配置文件的StrataScratch问题中。
更快、更简洁解决方案的实用技巧
- 如果输出依赖于有序行,请预期使用窗口函数,如
ROW_NUMBER()或DENSE_RANK() - 如果问题描述听起来像是“先计算A,然后从A计算B”,使用WITH块通常可以提高清晰度。
- 如果数据集分布在多个实体中,请及早考虑JOIN,并在编写最终select语句之前确定你的分组键。
- 在pandas中,当逻辑跨越多个DataFrame时,将
.merge()视为默认选项,然后使用.groupby()和清晰的过滤来构建度量。
结论
编码风格遵循结构:基于时间的和“每组最高”的问题倾向于产生窗口函数。多步业务规则倾向于产生CTE。
多表度量会增加JOIN的密度,而pandas通过.merge()和.groupby()反映了这些相同的操作。
更重要的是,及早识别这些结构化模式可以显著改变你处理新问题的方法。与其从语法或记忆技巧开始,不如从数据集本身进行推理:这是每组的最大值?分阶段的业务规则?多表度量?
这种思维的转变使你能够在编写任何代码之前就预测出主要框架。最终,这会带来更快的解决方案草拟、更简单的验证以及SQL和pandas之间更强的连贯性,因为你是在响应数据结构,而不仅仅是问题文本。
一旦你学会识别数据集的形状,你就可以及早预测出主要的构造。这使得解决方案编写起来更快,更容易调试,并且在新问题之间更加一致。
Nate Rosidi是一位数据科学家,从事产品策略工作。他还是教授分析学的兼职教授,并且是StrataScratch的创始人,该平台通过顶级公司的真实面试问题帮助数据科学家准备面试。Nate撰写关于职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖SQL的方方面面。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区