



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/rtx-ai-garage-fine-tuning-unsloth-dgx-spark/
原文作者:Annamalai Chockalingam
现代工作流程展示了生成式AI和智能体AI在PC上应用的无限可能性。
其中一些例子包括训练一个聊天机器人来处理产品支持问题,或构建一个管理个人日程的个人助理。然而,挑战依然存在:如何让小型语言模型对专业智能体任务做出始终如一、高准确度的响应。
这就是微调(fine-tuning)发挥作用的地方。
Unsloth是全球使用最广泛的开源LLM微调框架之一,它提供了一种易于上手的方式来定制模型。它专为在NVIDIA GPU上进行高效、低内存的训练而优化——无论是从GeForce RTX台式机和笔记本电脑,到RTX PRO工作站,再到世界最小的AI超级计算机DGX Spark。
微调的另一个强大起点是刚刚发布的NVIDIA Nemotron 3系列开源模型、数据集和库。Nemotron 3系列引入了最高效的开源模型系列,非常适合智能体AI微调。
教AI学习新技巧
微调就像是给一个AI模型进行一次集中的训练课程。通过与特定主题或工作流程相关的示例,模型通过学习新模式并适应手头的任务来提高其准确性。
为模型选择哪种微调方法,取决于开发人员想要调整原始模型的程度。根据他们的目标,开发人员可以使用以下三种主要的微调方法之一:
参数高效微调(如LoRA或QLoRA):
- 工作原理: 只更新模型的一小部分,以实现更快、成本更低的训练。这是一种更智能、更高效的增强模型的方法,而无需对其进行大幅度更改。
- 目标用例: 适用于几乎所有传统上需要完全微调的场景——包括增加领域知识、提高编程准确性、使模型适应法律或科学任务、完善推理能力,或调整语气和行为。
- 要求: 小型到中等规模的数据集(100-1,000个提示-样本对)。
完全微调(Full fine-tuning):
- 工作原理: 更新模型的所有参数——适用于教模型遵循特定格式或风格。
- 目标用例: 高级用例,例如构建必须就特定主题提供帮助、遵守一套既定准则并以特定方式响应的AI代理和聊天机器人。
- 要求: 大型数据集(1,000个以上提示-样本对)。
强化学习(Reinforcement learning):
- 工作原理: 使用反馈或偏好信号调整模型的行为。模型通过与其环境交互来学习,并利用反馈随时间推移进行自我改进。这是一种复杂的高级技术,它将训练和推理交织在一起——并且可以与参数高效微调和完全微调技术结合使用。详情请参阅Unsloth的强化学习指南。
- 目标用例: 提高模型在特定领域(如法律或医学)的准确性,或构建可以代表用户协调操作的自主智能体。
- 要求: 一个包含动作模型、奖励模型和一个供模型从中学习的环境的过程。
需要考虑的另一个因素是每种方法的所需VRAM。下表概述了在Unsloth上运行每种微调方法的要求。
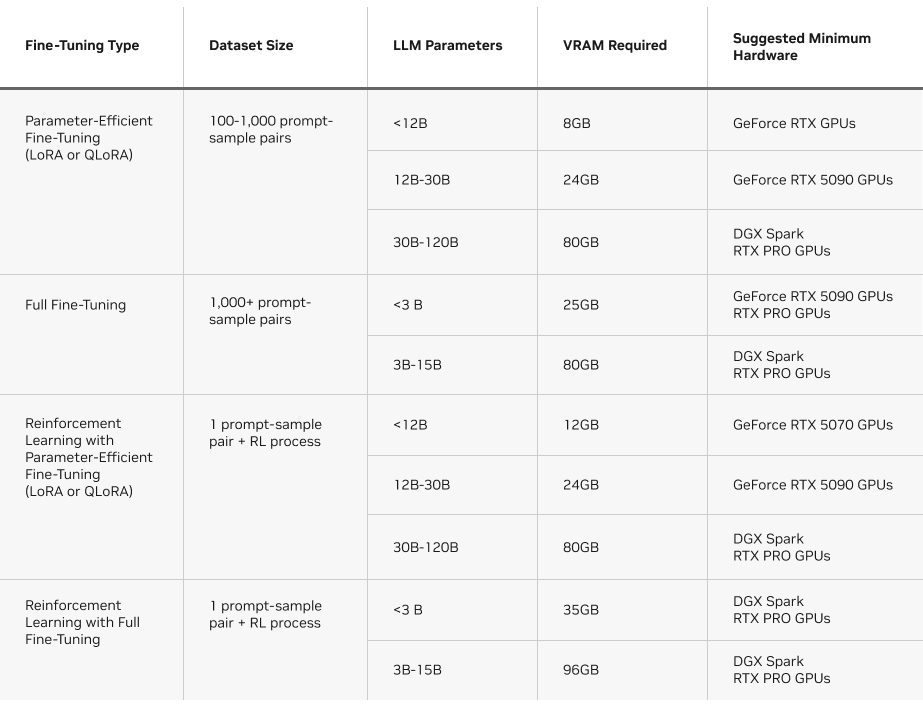
Unsloth:在NVIDIA GPU上快速微调的途径
LLM微调是一项内存和计算密集型工作负载,涉及数十亿次的矩阵乘法,以在每个训练步骤中更新模型权重。这类繁重的并行工作负载需要NVIDIA GPU的强大能力才能快速高效地完成整个过程。
Unsloth在此项工作负载中表现出色,它将复杂的数学运算转换为高效的自定义GPU内核,以加速AI训练。
Unsloth有助于将Hugging Face transformers库在NVIDIA GPU上的性能提高2.5倍。这些特定于GPU的优化,结合Unsloth的易用性,使微调对更广泛的AI爱好者和开发人员社区来说变得触手可及。
该框架是为NVIDIA硬件构建和优化的——从GeForce RTX笔记本电脑到RTX PRO工作站和DGX Spark——在减少VRAM消耗的同时提供最佳性能。
Unsloth提供了有用的指南,介绍如何开始以及如何管理不同的LLM配置、超参数和选项,还提供示例notebook和分步工作流程。
请查看以下一些Unsloth指南:
了解如何在NVIDIA DGX Spark上安装Unsloth。阅读NVIDIA技术博客,深入了解NVIDIA Blackwell平台上微调和强化学习的内容。
如需动手实践的本地微调演练,请观看下方的视频,其中Matthew Berman展示了在NVIDIA GeForce RTX 5090上使用Unsloth运行的强化学习。
现已推出:NVIDIA Nemotron 3系列开源模型
新的Nemotron 3系列开源模型——包括Nano、Super和Ultra尺寸——基于新的混合稀疏专家(MoE)架构构建,引入了最有效率的开源模型系列,并具有领先的准确性,是构建智能体AI应用的理想选择。
现已推出的Nemotron 3 Nano 30B-A3B是该系列中计算效率最高的模型。它针对软件调试、内容摘要、AI助理工作流程和信息检索等任务进行了优化,且推理成本较低。其混合MoE设计带来了以下优势:
- 推理令牌减少高达60%,显著降低推理成本。
- 100万个令牌的上下文窗口,使模型能够为长、多步骤任务保留更多信息。
Nemotron 3 Super是用于多智能体应用的高精度推理模型,而Nemotron 3 Ultra则适用于复杂的AI应用。预计这两款模型将于2026年上半年发布。
NVIDIA今天还发布了一套开放的训练数据集和最先进的强化学习库。Nemotron 3 Nano的微调已在Unsloth上可用。
立即从Hugging Face下载Nemotron 3 Nano,或通过Llama.cpp和LM Studio进行实验。
DGX Spark:紧凑型AI动力源
DGX Spark 实现了本地微调,并将强大的AI性能融入紧凑型台式超级计算机中,使开发人员能够获得比典型PC更多的内存。
DGX Spark 基于NVIDIA Grace Blackwell架构构建,可提供高达每秒浮点运算10^15次(FP4)的AI性能,并包含128GB的统一CPU-GPU内存,为开发人员提供了运行更大模型、更长上下文窗口和更具挑战性的本地训练工作负载的充足空间。
对于微调任务,DGX Spark 实现了以下目标:
- 更大规模的模型。 拥有超过300亿参数的模型通常会超出消费级GPU的VRAM容量,但在DGX Spark的统一内存中可以轻松容纳。
- 更先进的技术。 全模型微调和基于强化学习的工作流程——这些流程需要更多内存和更高吞吐量——在DGX Spark上运行速度明显更快。
- 本地控制,无需云队列。 开发人员可以在本地运行计算密集型任务,而无需等待云实例或管理多个环境。
DGX Spark的优势不仅限于LLM。例如,高分辨率扩散模型通常需要比典型台式机更多的内存。凭借FP4支持和大型统一内存,DGX Spark可以在几秒钟内生成1,000张图像,并为创意或多模态管道维持更高的吞吐量。
下表显示了在DGX Spark上微调Llama系列模型的性能情况。

随着微调工作流程的不断发展,新的Nemotron 3系列开源模型为优化RTX系统和DGX Spark提供了可扩展的推理和长上下文性能。
了解更多关于DGX Spark如何实现密集型AI任务的信息。
#ICYMI — NVIDIA RTX AI PC的最新进展
🚀 FLUX.2 图像生成模型现已发布,针对NVIDIA RTX GPU优化
Black Forest Labs的新模型提供了FP8量化版本,可减少VRAM占用并提高40%的性能。
✨ Nexa.ai 扩展RTX PC上的本地AI能力,引入Hyperlink实现智能体搜索
新的设备端搜索智能体实现了3倍更快的检索增强生成(RAG)索引和2倍更快的LLM推理速度,将1GB密集文件夹的索引时间从大约15分钟缩短到仅四到五分钟。此外,DeepSeek OCR现在可以通过NexaSDK在GGUF中本地运行,在RTX GPU上实现图表、公式和多语言PDF的即插即用解析。
🤝Mistral AI 推出针对NVIDIA GPU优化的新模型系列
新的Mistral 3模型从云端到边缘都经过优化,可通过Ollama和Llama.cpp进行快速的本地实验。
🎨Blender 5.0 发布,带来HDR色彩和主要的性能提升
该版本增加了ACES 2.0广色域/HDR色彩、NVIDIA DLSS(使毛发和皮毛渲染速度提高5倍)、对海量几何体的更好处理,以及Grease Pencil的运动模糊功能。
请在Facebook、Instagram、TikTok和X上关注NVIDIA AI PC,并通过订阅RTX AI PC电子报保持最新信息。在LinkedIn和X上关注NVIDIA Workstation。
请参阅有关软件产品信息的声明。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区