



📢 转载信息
原文链接:https://www.kdnuggets.com/a-guide-to-kedro-your-production-ready-data-science-toolbox
原文作者:Iván Palomares Carrascosa
# 引言
数据科学项目通常始于探索性的 Python Notebook,但在某个阶段需要迁移到生产环境,如果规划不当,可能会变得很棘手。
QuantumBlack 的框架 Kedro 是一个开源工具,它通过将围绕项目结构、可扩展性和可重复性的概念付诸实践,从而架起了实验 Notebook 与生产就绪解决方案之间的桥梁。
本文将介绍并探讨 Kedro 的主要功能,引导您了解其核心概念,以便在深入研究这个用于处理实际数据科学项目的框架之前,有更好的理解。
# 开始使用 Kedro
使用 Kedro 的第一步,当然是在我们运行的环境中安装它,最好是在 IDE 中——Kedro 无法在 Notebook 环境中充分发挥其作用。打开您喜欢的 Python IDE,例如 VS Code,然后在集成终端中输入:
pip install kedro接下来,我们使用此命令创建一个新的 Kedro 项目:
kedro new如果命令运行正常,系统会询问您几个问题,包括项目的名称。我们将项目命名为 Churn Predictor。如果命令不起作用,可能是因为存在与安装多个 Python 版本相关的冲突。在这种情况下,最干净的解决方案是在 IDE 的虚拟环境中工作。以下是一些创建虚拟环境的快速解决方法(如果创建 Kedro 项目的命令已经成功运行,请忽略它们!):
python3.11 -m venv venv source venv/bin/activate pip install kedro kedro --version然后,在您的 IDE 中选择以下 Python 解释器以便今后使用:./venv/bin/python。
此时,如果一切顺利,您应该在 VS Code 的 'EXPLORER' 面板的左侧看到 churn-predictor 目录下的完整项目结构。在终端中,让我们导航到我们项目的主文件夹:
cd churn-predictor/现在是时候通过我们新创建的项目一窥 Kedro 的核心功能了。
# 探索 Kedro 的核心元素
我们将介绍的第一个元素——也是我们将自己创建的——是数据目录(data catalog)。在 Kedro 中,此元素负责将数据定义与主代码隔离开来。
作为项目结构的一部分,已经创建了一个空的 data catalog 文件。我们只需要找到它并填充内容。在 IDE 的资源管理器中,找到 churn-predictor 项目下的 conf/base/catalog.yml 文件并打开它,然后添加以下内容:
raw_customers: type: pandas.CSVDataset filepath: data/01_raw/customers.csv processed_features: type: pandas.ParquetDataset filepath: data/02_intermediate/features.parquet train_data: type: pandas.ParquetDataset filepath: data/02_intermediate/train.parquet test_data: type: pandas.ParquetDataset filepath: data/02_intermediate/test.parquet trained_model: type: pickle.PickleDataset filepath: data/06_models/churn_model.pkl简而言之,我们刚刚定义了(尚未创建)五个数据集,每个数据集都有一个可访问的键或名称:raw_customers、processed_features 等等。我们稍后创建的主要数据管道应该能够通过其名称引用这些数据集,从而抽象并完全隔离输入/输出操作与代码。
现在我们需要一些数据来作为上述数据目录定义中的第一个数据集。在本例中,您可以从这个示例中获取合成生成的客户数据,下载它,并将其集成到您的 Kedro 项目中。
接下来,我们导航到 data/01_raw 目录,创建一个名为 customers.csv 的新文件,并将示例数据集的内容粘贴进去。最简单的方法是查看 GitHub 上数据集文件的“原始”内容,全选、复制,然后粘贴到 Kedro 项目中的新文件中。
现在我们将创建一个 Kedro 管道(pipeline),它将描述将应用于我们原始数据集的数据科学工作流。在终端中输入:
kedro pipeline create data_processing此命令会在 src/churn_predictor/pipelines/data_processing/ 目录下创建几个 Python 文件。现在,我们将打开 nodes.py 并粘贴以下代码:
import pandas as pd from typing import Tuple def engineer_features(raw_df: pd.DataFrame) -> pd.DataFrame: """Create derived features for modeling.""" df = raw_df.copy() df['tenure_months'] = df['account_age_days'] / 30 df['avg_monthly_spend'] = df['total_spend'] / df['tenure_months'] df['calls_per_month'] = df['support_calls'] / df['tenure_months'] return df def split_data(df: pd.DataFrame, test_fraction: float) -> Tuple[pd.DataFrame, pd.DataFrame]: """Split data into train and test sets.""" train = df.sample(frac=1-test_fraction, random_state=42) test = df.drop(train.index) return train, test我们刚才定义的两个函数充当节点(nodes),可以在可重复的、模块化的工作流中对数据集应用转换。第一个函数通过从原始特征创建几个派生特征来进行一些简单、说明性的特征工程。同时,第二个函数定义了数据集到训练集和测试集的划分,例如用于进一步的下游机器学习建模。
同一子目录中还有另一个 Python 文件:pipeline.py。让我们打开它并添加以下内容:
from kedro.pipeline import Pipeline, node from .nodes import engineer_features, split_data def create_pipeline(**kwargs) -> Pipeline: return Pipeline([ node( func=engineer_features, inputs="raw_customers", outputs="processed_features", name="feature_engineering" ), node( func=split_data, inputs=["processed_features", "params:test_fraction"], outputs=["train_data", "test_data"], name="split_dataset" ) ])魔法的一部分发生在这里:请注意管道中节点输入和输出的名称。就像乐高积木一样,我们可以在数据目录中灵活地引用不同的数据集定义,当然,从我们之前创建的包含原始客户数据的那个数据集开始。
最后还有几步配置才能使一切正常工作。用于划分节点的测试数据比例被定义为一个需要传递的参数。在 Kedro 中,我们通过将这些“外部”参数添加到 conf/base/parameters.yml 文件中来定义它们。让我们将以下内容添加到这个目前为空的配置文件中:
test_fraction: 0.2此外,默认情况下,Kedro 项目会隐式导入 PySpark 库中的模块,而我们实际上不需要它们。在 settings.py(位于“src”子目录内)中,我们可以通过注释掉并修改代码开头的一些现有行来禁用此功能:
# Instantiated project hooks. # from churn_predictor.hooks import SparkHooks # noqa: E402 # Hooks are executed in a Last-In-First-Out (LIFO) order. HOOKS = ()保存所有更改,确保您的运行环境中已安装 pandas,并准备好从 IDE 终端运行项目:
kedro run这可能需要一些时间才能成功,具体取决于安装的 Kedro 版本。如果失败并出现 DatasetError,可能的解决方案是运行 pip install kedro-datasets 或 pip install pyarrow(或者两者都安装!),然后重试。
希望您能看到一堆“INFO”消息,告知您数据工作流的不同阶段正在进行。这是一个好兆头。在 data/02_intermediate 目录中,您可能会找到包含数据处理结果的几个 parquet 文件。
最后,您可以选择性地 pip install kedro-viz 并运行 kedro viz,在您的浏览器中打开一个交互式的可视化图,展示您的工作流,如下图所示:
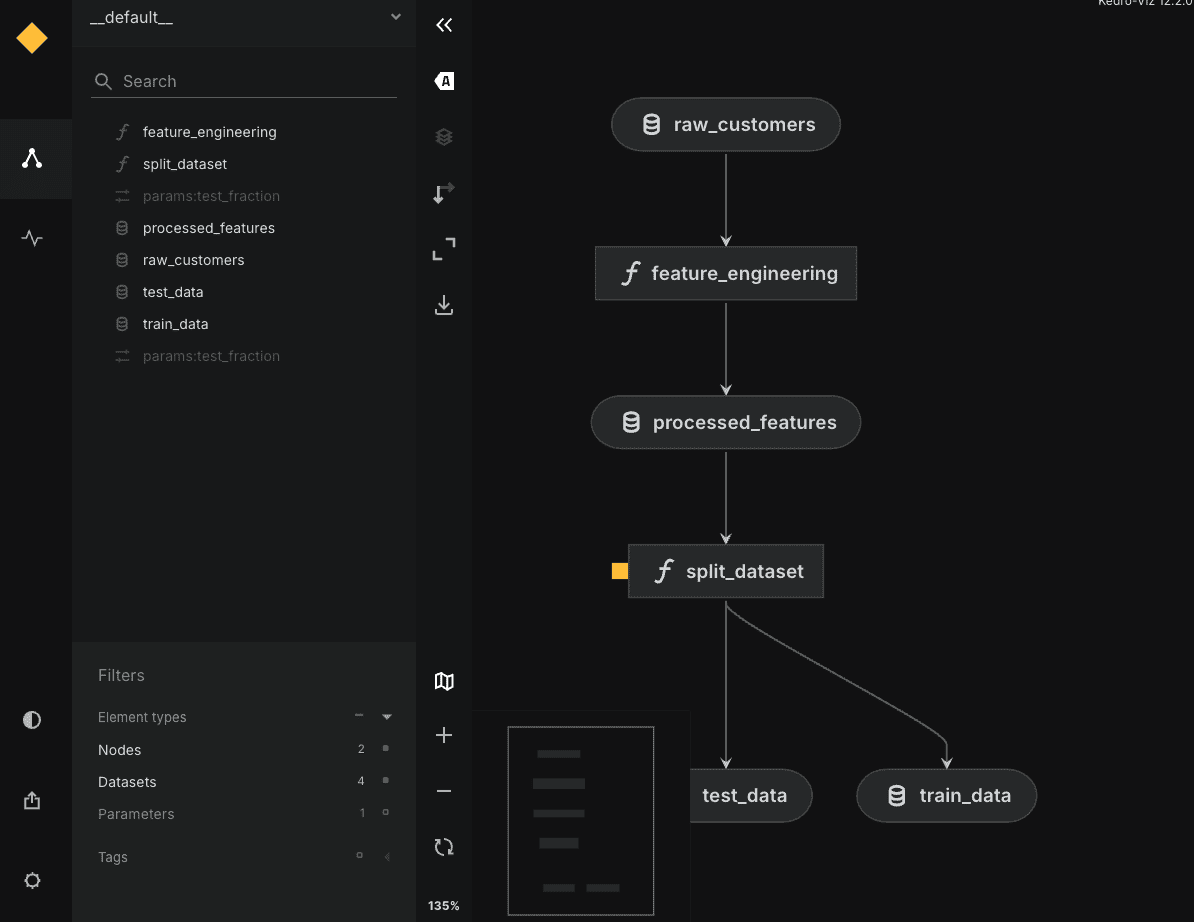
# 总结
我们将把对该工具的进一步探索留给未来的文章。如果您看到这里,您已经成功构建了第一个 Kedro 项目,并了解了它的核心组件和功能,理解了它们是如何协同工作的。
做得好!
Iván Palomares Carrascosa 是一位在人工智能、机器学习、深度学习和 LLM 领域的领导者、作家、演说家和顾问。他培训并指导他人利用人工智能在现实世界中创造价值。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区