



📢 转载信息
原文作者:Lingran Xia, Chinmay Bapat, Deepti Ragha, Kareem Syed-Mohammed, Vivek Gangasani, Victor Wang, and Xu Deng
在 2025 年,生成式 AI 已经从文本生成发展到多模态用例,范围涵盖音频转录和翻译,以及需要实时数据流的语音代理。当今的应用需要更多:用户和模型之间持续的实时对话——数据能够通过单个持久连接双向同时流动。想象一下语音转文本的用例,您需要以流的形式输入音频流,并以连续流的形式接收转录的文本。此类用例将需要双向流媒体功能。
我们正在为 Amazon SageMaker AI 推理 引入双向流媒体功能,这使推理从事务性交换转变为连续对话。当对话自然流畅、不中断时,语音才能与实时 AI 配合得最好。借助双向流媒体,语音转文本变得即时。模型在收听和转录的同时进行,因此话音一落,文字就会出现。想象一下呼叫者向客服热线描述问题。当他们说话时,实时文字记录会出现在呼叫中心座席面前,为座席提供即时背景信息,并允许他们在呼叫者说完之前做出回应。这种持续的交流使语音体验感觉流畅、响应迅速且人性化。
本文将向您展示如何构建和部署一个具有双向流媒体功能的容器到 SageMaker AI 端点。我们还将演示如何引入您自己的容器,或在 SageMaker AI 上使用我们合作伙伴 Deepgram 的预构建模型和容器来启用实时推理的双向流媒体功能。
双向流媒体:深入解析
通过双向流媒体,数据通过一个持久连接同时双向流动。
在传统的推理请求方法中,客户端发送一个完整的问题并等待,而模型处理请求并返回一个完整的答案,然后客户端才能发送下一个问题。
Client: [发送完整问题] → 等待... Model: ...处理... [返回完整答案] Client: [发送下一个问题] → 等待... Model: ...处理... [返回完整答案]在双向流媒体中,客户端的语音开始流动,而模型同时开始处理并立即转录答案。
Client: [携带足够上下文的问题开始流动] → Model: ← [答案立即开始流动] Client: → [继续/调整问题] ↓ Model: ← [实时调整答案]用户在模型开始生成结果时即可看到结果。通过一个持久连接取代数百个短暂连接,可以减少网络基础设施、TLS 握手和连接管理的开销。模型可以在连续流中保持上下文,从而实现多轮交互,而无需每次都重新发送对话历史记录。~~ ~~
SageMaker AI 推理双向流媒体功能
SageMaker AI 推理将 HTTP/2 和 WebSocket 协议结合起来,实现了客户端和模型之间实时、双向的通信。当您使用双向流媒体调用 SageMaker AI 推理端点时,您的请求会经过 SageMaker AI 中的三层基础设施:
- 客户端到 SageMaker AI 路由器:您的应用程序使用 HTTP/2 连接到 Amazon SageMaker AI 运行时端点,建立支持双向流媒体的高效、多路复用的连接。
- SageMaker AI 路由器到模型容器:路由器将您的请求转发到一个 Sidecar(与您的模型容器并排运行的轻量级代理),然后 Sidecar 在
ws://localhost:8080/invocations-bidirectional-stream处与您的模型容器建立一个 WebSocket 连接。
一旦建立连接,数据就会在两个方向自由流动:
- 请求流:您的应用程序通过 HTTP/2 发送输入作为一系列有效负载块。SageMaker AI 基础架构会将这些块转换为 WebSocket 数据帧——可能是文本(对于 UTF-8 数据)或二进制——并将它们转发到您的模型容器。模型会实时接收这些帧,甚至可以在完整输入到达之前就开始处理,例如在转录用例中。
- 响应流:您的模型生成输出,并通过 WebSocket 帧将其发送回来。SageMaker AI 将每个帧封装到一个响应有效负载中,并通过 HTTP/2 直接流式传输到您的应用程序。用户在模型生成结果时就能看到结果——对于文本是逐字,对于视频是逐帧,或对于音频是逐样本。
Sidecar 和模型容器之间的 WebSocket 连接在会话期间保持打开状态,并具有内置的健康监控功能。为了保持连接健康,SageMaker AI 每 60 秒发送一次 WebSocket ping 帧以验证连接是否处于活动状态,而您的模型容器会以 pong 帧响应以确认其健康状况。如果连续 5 次 ping 未得到答复,连接将优雅地关闭。
构建您自己的容器以实现双向流媒体
如果您想使用开源模型或自己的模型,可以自定义容器以支持双向流媒体。您的容器必须实现 WebSocket 协议来处理传入的数据帧并将响应帧发送回 SageMaker AI。
首先,让我们构建一个带有自带容器用例的双向流媒体应用程序示例。通过此示例,我们将:
- 构建一个具有双向流媒体功能的 Docker 容器——一个简单的回显容器,它将接收到的字节作为输入流式传输到容器中
- 将容器部署到 SageMaker AI 端点
- 使用新的双向流媒体 API 调用 SageMaker AI 端点
先决条件
- 具有 SageMaker AI 权限的 AWS 账户
- AmazonSageMakerFullAccess IAM 托管策略,以允许创建端点
- 明确允许
sagemaker:InvokeEndpoint*动作的 IAM 权限,用于端点调用。
- 本地安装的 Docker
- Python 3.12+
- 安装 aws-sdk-python 以使用 SageMaker AI 运行时
InvokeEndpointWithBidirectionalStreamAPI
构建具有双向流媒体功能的 Docker 容器
首先,克隆我们的 演示仓库,并按照 README.md 中定义设置您的环境。以下步骤将创建一个简单的演示 Docker 镜像并将其推送到您账户中的 Amazon ECR 仓库。
# 该应用程序使用环境变量进行 AWS 身份验证。在运行应用程序之前设置它们: # export AWS_ACCESS_KEY_ID="your-access-key" # export AWS_SECRET_ACCESS_KEY="your-secret-key" # export AWS_DEFAULT_REGION="us-west-2" container_name="sagemaker-bidirectional-streaming" container_tag="latest" cd container account=$(aws sts get-caller-identity --query Account --output text) # 获取当前配置中定义的区域(如果未定义,则默认为 us-west-2) region=$(aws configure get region) region=${region:-us-west-2} container_image_uri="${account}.dkr.ecr.${region}.amazonaws.com/${container_name}:${container_tag}" # 如果 ECR 中不存在该仓库,则创建它。 aws ecr describe-repositories --repository-names "${container_name}" --region "${region}" > /dev/null 2>&1 if [ $? -ne 0 ] then aws ecr create-repository --repository-name "${container_name}" --region "${region}" > /dev/null fi # 获取 ECR 的登录命令并直接执行它 aws ecr get-login-password --region ${region} | docker login --username AWS --password-stdin ${account}.dkr.ecr.${region}.amazonaws.com/${container_name} # 使用镜像名称在本地构建 docker 镜像,然后将其推送到 ECR # 使用完整名称。 docker build --platform linux/amd64 --provenance=false -t ${container_name} . docker tag ${container_name} ${container_image_uri} docker push ${container_image_uri}这会创建一个带有 Docker 标签的容器,告知 SageMaker AI 此容器支持双向流媒体功能。
com.amazonaws.sagemaker.capabilities.bidirectional-streaming=true将演示双向流媒体容器部署到 SageMaker AI 端点
以下示例脚本创建带有已创建容器的 SageMaker AI 端点:
import boto3 from datetime import datetime sagemaker_client = boto3.client('sagemaker', region_name=REGION) # 创建模型 sagemaker_client.create_model( ModelName=MODEL_NAME, PrimaryContainer={'Image': IMAGE_URI, 'Mode': 'SingleModel'}, ExecutionRoleArn=ROLE ) # 创建配置 sagemaker_client.create_endpoint_config( EndpointConfigName=ENDPOINT_CONFIG_NAME, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': MODEL_NAME, 'InitialInstanceCount': 1, 'InstanceType': INSTANCE_TYPE, 'InitialVariantWeight': 1.0 }] ) # 创建端点 sagemaker_client.create_endpoint( EndpointName=ENDPOINT_NAME, EndpointConfigName=ENDPOINT_CONFIG_NAME ) print(f"Endpoint '{ENDPOINT_NAME}' creation initiated")使用新的双向流媒体 API 调用 SageMaker AI 端点
一旦 SageMaker AI 端点处于 InService 状态,我们就可以继续调用该端点以测试测试容器的双向流媒体功能。
#!/usr/bin/env python3 """ SageMaker AI 双向流媒体 Python SDK 脚本。 此脚本连接到 SageMaker AI 端点以进行双向流媒体通信。 """ import argparse import asyncio import sys from aws_sdk_sagemaker_runtime_http2.client import SageMakerRuntimeHTTP2Client from aws_sdk_sagemaker_runtime_http2.config import Config, HTTPAuthSchemeResolver from aws_sdk_sagemaker_runtime_http2.models import InvokeEndpointWithBidirectionalStreamInput, RequestStreamEventPayloadPart, RequestPayloadPart from smithy_aws_core.identity import EnvironmentCredentialsResolver from smithy_aws_core.auth.sigv4 import SigV4AuthScheme import logging def parse_arguments(): """解析命令行参数。""" parser = argparse.ArgumentParser( description="Connect to SageMaker AI endpoint for bidirectional streaming" ) parser.add_argument( "ENDPOINT_NAME", help="Name of the SageMaker AI endpoint to connect to" ) return parser.parse_args() # 配置 AWS_REGION = "us-west-2" BIDI_ENDPOINT = f"https://runtime.sagemaker.{AWS_REGION}:8443" logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) class SimpleClient: def __init__(self, endpoint_name, region=AWS_REGION): self.endpoint_name = endpoint_name self.region = region self.client = None self.stream = None self.response = None self.is_active = False def _initialize_client(self): config = Config( endpoint_uri=BIDI_ENDPOINT, region=self.region, aws_credentials_identity_resolver=EnvironmentCredentialsResolver(), auth_scheme_resolver=HTTPAuthSchemeResolver(), auth_schemes={"aws.auth#sigv4": SigV4AuthScheme(service="sagemaker")} ) self.client = SageMakerRuntimeHTTP2Client(config=config) async def start_session(self): if not self.client: self._initialize_client() logger.info(f"Starting session with endpoint: {self.endpoint_name}") self.stream = await self.client.invoke_endpoint_with_bidirectional_stream( InvokeEndpointWithBidirectionalStreamInput(endpoint_name=self.endpoint_name) ) self.is_active = True self.response = asyncio.create_task(self._process_responses()) async def send_words(self, words): for i, word in enumerate(words): logger.info(f"Sending payload: {word}") await self.send_event(word.encode('utf-8')) await asyncio.sleep(1) async def send_event(self, data_bytes): payload = RequestPayloadPart(bytes_=data_bytes) event = RequestStreamEventPayloadPart(value=payload) await self.stream.input_stream.send(event) async def end_session(self): if not self.is_active: return await self.stream.input_stream.close() logger.info("Stream closed") async def _process_responses(self): try: output = await self.stream.await_output() output_stream = output[1] while self.is_active: result = await output_stream.receive() if result is None: logger.info("No more responses") break if result.value and result.value.bytes_: response_data = result.value.bytes_.decode('utf-8') logger.info(f"Received: {response_data}") except Exception as e: logger.error(f"Error processing responses: {e}") def main(): """主函数,用于解析参数并运行流式客户端。""" args = parse_arguments() print("=" * 60) print("SageMaker AI 双向流媒体客户端") print("=" * 60) print(f"Endpoint Name: {args.ENDPOINT_NAME}") print(f"AWS Region: {AWS_REGION}") print("=" * 60) async def run_client(): sagemaker_client = SimpleClient(endpoint_name=args.ENDPOINT_NAME) try: await sagemaker_client.start_session() words = ["I need help with", "my account balance", "I can help with that", "and recent charges"] await sagemaker_client.send_words(words) await asyncio.sleep(2) await sagemaker_client.end_session() sagemaker_client.is_active = False if sagemaker_client.response and not sagemaker_client.response.done(): sagemaker_client.response.cancel() logger.info("Session ended successfully") return 0 except Exception as e: logger.error(f"Client error: {e}") return 1 try: exit_code = asyncio.run(run_client()) sys.exit(exit_code) except KeyboardInterrupt: logger.info("Interrupted by user") sys.exit(1) except Exception as e: logger.error(f"Unexpected error: {e}") sys.exit(1) if __name__ == "__main__": main()以下是展示前一个脚本生成的输入和输出流的示例输出。容器将传入数据回显到输出流,演示了双向流媒体功能。

SageMaker AI 与 Deepgram 模型的集成
SageMaker AI 与 Deepgram 合作,为 SageMaker AI 端点构建了双向流媒体支持。Deepgram 是 AWS 高级合作伙伴,提供具有行业领先准确性和速度的企业级语音 AI 模型。其模型为联络中心、媒体平台和对话式 AI 应用提供实时转录、文本转语音和语音代理支持。
对于那些有严格合规要求,即音频处理绝对不能离开其 AWS VPC 的客户来说,传统的自托管选项需要在设置和维护方面产生巨大的运营开销。Amazon SageMaker 双向流媒体改变了这一体验,使客户只需在 AWS 管理控制台中执行几个操作,即可部署和扩展实时 AI 应用。
Deepgram Nova-3 语音转文本模型现已在 AWS Marketplace 中以 SageMaker AI 端点形式提供,更多模型即将推出。Deepgram Nova-3 的功能包括多语言转录、企业级性能和特定领域识别。Deepgram 为开发者在 Amazon SageMaker AI 上提供 14 天免费试用,以便在不产生软件许可费的情况下原型设计应用程序。此期间仍将产生所选机器类型的基础设施费用。有关更多详细信息,请参阅 Amazon SageMaker AI 定价文档。
下一节将提供高级概述和示例代码。有关其他信息和示例,请参阅 Deepgram 文档页面上的详细快速入门指南。如果设置过程中需要其他帮助,请联系 Deepgram 开发者社区。
设置 Deepgram SageMaker AI 实时推理端点
要设置 Deepgram SageMaker AI 端点:
- 导航到 Amazon SageMaker AI 控制台中的 AWS Marketplace 模型包部分并搜索 Deepgram。
- 订阅该产品,然后继续执行产品页面上的启动向导。
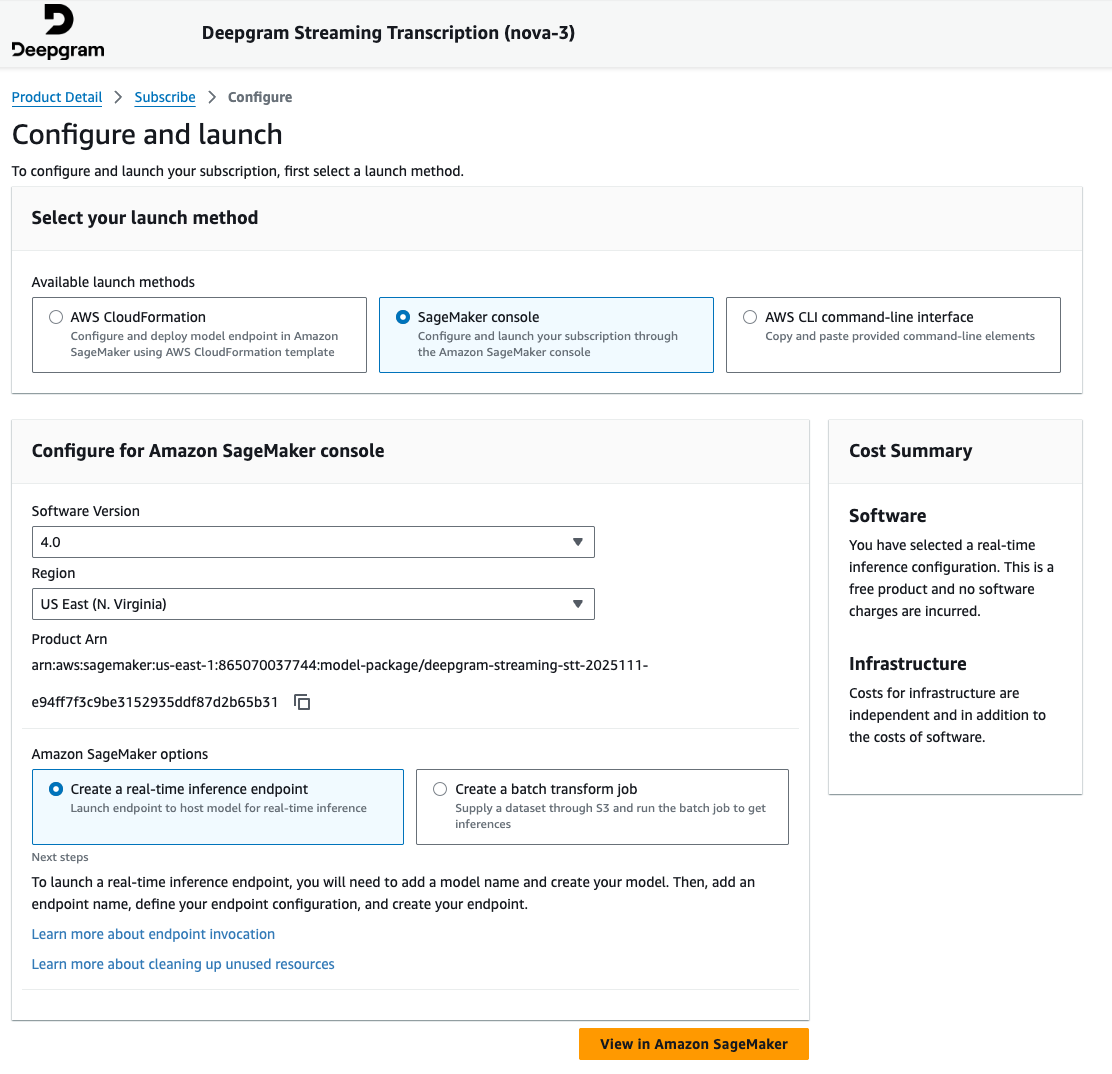
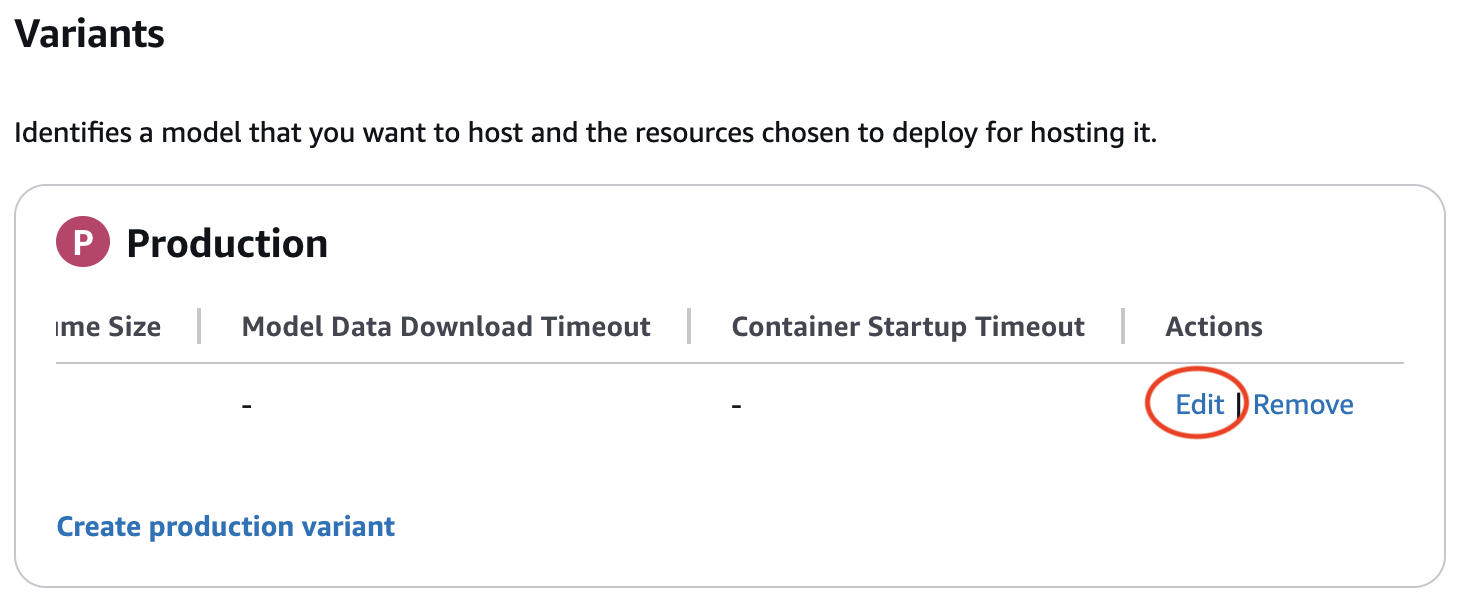
- 通过在 Amazon SageMaker AI 实时端点创建向导中提供详细信息来继续操作。在创建端点配置时,请验证您是否编辑了生产变体以包含有效的实例类型。滚动到生产变体表的最右侧时,可能会隐藏“编辑”按钮。
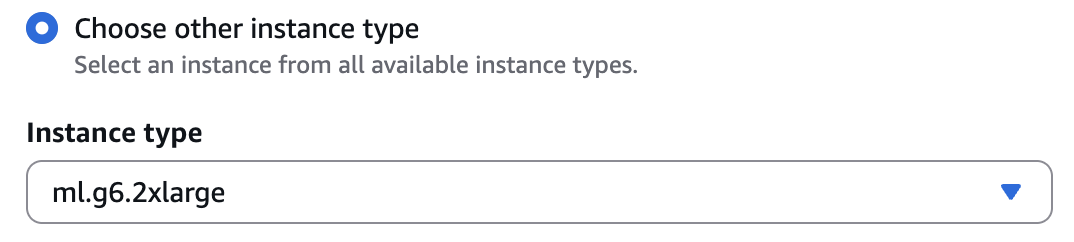
ml.g6.2xlarge是初步测试的首选实例类型。有关特定的硬件要求和选择指南,请参阅 Deepgram 文档。
- 在端点摘要页面,记下您提供的端点名称,因为在下一节中需要用到它。
使用 Deepgram SageMaker AI 实时推理端点
我们现在将介绍一个示例 TypeScript 应用程序,它将一个音频文件流式传输到托管在 SageMaker AI 实时推理端点上的 Deepgram 模型,并实时打印流式传输回来的转录内容。
- 创建一个简单的函数来流式传输 WAV 文件
- 此函数打开一个本地音频文件,并以小的二进制块将其发送到 Amazon SageMaker AI 推理。
import * as fs from "fs"; import * as path from "path"; import { RequestStreamEvent } from '@aws-sdk/client-sagemaker-runtime-http2'; function sleep(ms: number): Promise<void> { return new Promise(resolve => setTimeout(resolve, ms)); } async function* streamWavFile(filePath: string): AsyncIterable<RequestStreamEvent> { const full = path.resolve(filePath); if (!fs.existsSync(full)) { throw new Error(`Audio file not found: ${full}`); } console.log(`Streaming audio: ${full}`); const readStream = fs.createReadStream(full, { highWaterMark: 512_000 }); // 512 KB for await (const chunk of readStream) { yield { PayloadPart: { Bytes: chunk, DataType: "BINARY" } }; } // 保持流活动以在发送完整个音频文件后接收转录响应 console.log("Audio sent, waiting for transcription to finish..."); await sleep(15000); // 等待 15 秒处理最后的音频块。// 长音频文件可能需要在处理转录时发送保持活动数据包。有关详细信息,请参阅 https://developers.deepgram.com/docs/audio-keep-alive // 告诉容器我们已完成 yield { PayloadPart: { Bytes: new TextEncoder().encode('{"type":"CloseStream"}'), DataType: "UTF8" } }; }- 配置 Amazon SageMaker AI 运行时客户端
- 本节配置 AWS 区域、SageMaker AI 端点名称以及容器内的 Deepgram 模型路由。根据需要更新以下值:
- 如果未在 us-east-1 中使用,则更新
region - 上面设置端点时记录的
endpointName - 如果使用不同的本地存储音频文件名称,则更新
test.wav
- 如果未在 us-east-1 中使用,则更新
- 本节配置 AWS 区域、SageMaker AI 端点名称以及容器内的 Deepgram 模型路由。根据需要更新以下值:
import { SageMakerRuntimeHTTP2Client, InvokeEndpointWithBidirectionalStreamCommand } from '@aws-sdk/client-sagemaker-runtime-http2'; const region = "us-east-1"; // AWS 区域 const endpointName = "REPLACEME"; // 您的 SageMaker Deepgram 端点名称 const audioFile = "test.wav"; // 本地音频文件 // 模型容器内 Deepgram WebSocket 路径 const modelInvocationPath = "v1/listen"; const modelQueryString = "model=nova-3"; const client = new SageMakerRuntimeHTTP2Client({ region });- 调用端点并打印流式转录
- 最后这个片段将音频流发送到 SageMaker AI 端点,并在 Deepgram 的流式 JSON 事件到达时打印它们。该应用程序将显示实时语音转文本输出的生成过程。
async function run() { console.log("Sending audio to Deepgram via SageMaker..."); const command = new InvokeEndpointWithBidirectionalStreamCommand({ EndpointName: endpointName, Body: streamWavFile(audioFile), ModelInvocationPath: modelInvocationPath, ModelQueryString: modelQueryString }); const response = await client.send(command); if (!response.Body) { console.log("No streaming response received."); return; } const decoder = new TextDecoder(); for await (const msg of response.Body) { if (msg.PayloadPart?.Bytes) { const text = decoder.decode(msg.PayloadPart.Bytes); try { const parsed = JSON.parse(text); // 提取并显示转录内容 if (parsed.channel?.alternatives?.[0]?.transcript) { const transcript = parsed.channel.alternatives[0].transcript; if (transcript.trim()) { console.log("Transcript:", transcript); } } console.debug("Deepgram (raw):", parsed); } catch { console.error("Deepgram (error):", text); } } } console.log("Streaming finished."); } run().catch(console.error);结论
在本文中,我们概述了如何使用生成式 AI 构建实时代理,讨论了其中的挑战,以及 SageMaker AI 双向流媒体如何帮助您应对这些挑战。我们还详细介绍了如何构建自己的容器以利用双向流媒体功能。然后,我们引导您完成了构建一个示例聊天机器人容器以及我们合作伙伴 Deepgram 提供的实时语音转文本模型的步骤,该模型是实时语音 AI 代理应用的核心组成部分。
立即开始使用 LLM 和 SageMaker AI 构建双向流媒体应用程序。
关于作者
 Lingran Xia 是 AWS 的一名软件开发工程师。他目前专注于提高机器学习模型的推理性能。在空闲时间,他喜欢旅行和滑雪。
Lingran Xia 是 AWS 的一名软件开发工程师。他目前专注于提高机器学习模型的推理性能。在空闲时间,他喜欢旅行和滑雪。
 Vivek Gangasani 是 SageMaker 推理部门的全球 GenAI 专家解决方案架构师。他推动 SageMaker 推理的上市(GTM)和外向产品战略。他还帮助企业和初创公司使用 SageMaker 和 GPU 部署、管理和扩展其 GenAI 模型。目前,他专注于为托管大型语言模型开发推理性能和 GPU 效率优化策略和解决方案。在空闲时间,Vivek 喜欢徒步旅行、看电影和尝试不同的美食。
Vivek Gangasani 是 SageMaker 推理部门的全球 GenAI 专家解决方案架构师。他推动 SageMaker 推理的上市(GTM)和外向产品战略。他还帮助企业和初创公司使用 SageMaker 和 GPU 部署、管理和扩展其 GenAI 模型。目前,他专注于为托管大型语言模型开发推理性能和 GPU 效率优化策略和解决方案。在空闲时间,Vivek 喜欢徒步旅行、看电影和尝试不同的美食。
 Victor Wang 是亚马逊云科技(Amazon Web Services)的高级解决方案架构师,常驻旧金山,为包括 Deepgram 在内的 GenAI 初创公司提供支持。Victor 在亚马逊工作了 7 年;之前的职位包括 AWS 站点到站点 VPN 的软件开发人员、AWS 公共部门合作伙伴的 AWS ProServe 顾问以及 Amazon Aurora MySQL 的技术项目经理。他的热情是学习新技术和环游世界。Victor 已经飞行了超过 200 万英里,并计划继续他永恒的探索之旅。
Victor Wang 是亚马逊云科技(Amazon Web Services)的高级解决方案架构师,常驻旧金山,为包括 Deepgram 在内的 GenAI 初创公司提供支持。Victor 在亚马逊工作了 7 年;之前的职位包括 AWS 站点到站点 VPN 的软件开发人员、AWS 公共部门合作伙伴的 AWS ProServe 顾问以及 Amazon Aurora MySQL 的技术项目经理。他的热情是学习新技术和环游世界。Victor 已经飞行了超过 200 万英里,并计划继续他永恒的探索之旅。
 Chinmay Bapat 是 AWS Amazon SageMaker AI 推理团队的工程经理,负责领导构建可扩展的生成式 AI 推理基础设施的工程工作。他的工作使客户能够高效、大规模地部署和提供大型语言模型和其他 AI 模型。在工作之余,他喜欢玩棋盘游戏并正在学习滑雪。
Chinmay Bapat 是 AWS Amazon SageMaker AI 推理团队的工程经理,负责领导构建可扩展的生成式 AI 推理基础设施的工程工作。他的工作使客户能够高效、大规模地部署和提供大型语言模型和其他 AI 模型。在工作之余,他喜欢玩棋盘游戏并正在学习滑雪。
 Deepti Ragha 是 Amazon SageMaker AI 团队的高级软件开发工程师,专注于 ML 推理基础设施和模型托管优化。她构建的功能可以提高部署性能、降低推理成本,并使各种规模的组织都能轻松使用 ML。在工作之余,她喜欢旅行、徒步旅行和园艺。
Deepti Ragha 是 Amazon SageMaker AI 团队的高级软件开发工程师,专注于 ML 推理基础设施和模型托管优化。她构建的功能可以提高部署性能、降低推理成本,并使各种规模的组织都能轻松使用 ML。在工作之余,她喜欢旅行、徒步旅行和园艺。
 Kareem Syed-Mohammed 是 AWS 的产品经理。他专注于在 SageMaker HyperPod 上启用 Gen AI 模型开发和治理。在此之前,在 Amazon QuickSight,他领导了嵌入式分析和开发者体验。除了 QuickSight 之外,他还曾在 AWS Marketplace 和亚马逊零售部门担任产品经理。Kareem 的职业生涯始于 Expedia 的呼叫中心技术、Local Expert 和广告的开发人员,以及麦肯锡的管理顾问。
Kareem Syed-Mohammed 是 AWS 的产品经理。他专注于在 SageMaker HyperPod 上启用 Gen AI 模型开发和治理。在此之前,在 Amazon QuickSight,他领导了嵌入式分析和开发者体验。除了 QuickSight 之外,他还曾在 AWS Marketplace 和亚马逊零售部门担任产品经理。Kareem 的职业生涯始于 Expedia 的呼叫中心技术、Local Expert 和广告的开发人员,以及麦肯锡的管理顾问。
 Xu Deng 是 SageMaker 团队的软件工程师经理。他专注于帮助客户在 Amazon SageMaker 上构建和优化他们的 AI/ML 推理体验。在业余时间,他喜欢旅行和滑雪。
Xu Deng 是 SageMaker 团队的软件工程师经理。他专注于帮助客户在 Amazon SageMaker 上构建和优化他们的 AI/ML 推理体验。在业余时间,他喜欢旅行和滑雪。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区