



📢 转载信息
原文作者:Vivek Gangasani, Andrew Smith, and Goutham Annem
我们感谢 llm-d 团队的 Greg Pereira 和 Robert Shaw 在将 llm-d 引入 AWS 方面提供的支持。
在代理和推理时代,大型语言模型(LLM)通过复杂的推理链生成的 token 数量是单次回复的 10 倍。代理 AI 工作流还会产生高度可变的需求,并进一步呈指数级增长处理量,从而拖慢推理过程并降低用户体验。随着世界从原型设计 AI 解决方案转向大规模部署 AI,高效的推理正成为关键的制约因素。
LLM 推理包含两个不同的阶段:预填充(prefill)和解码(decode)。预填充阶段是计算密集型的。它并行处理整个输入提示,以生成初始的键值(KV)缓存条目。解码阶段是内存密集型的。它以自回归方式一次生成一个 token,同时需要大量的内存带宽来访问模型权重和不断增长的 KV 缓存。使情况更复杂的是,推理请求的计算需求因输入和输出长度而异,这使得高效的资源利用率尤其具有挑战性。
传统方法通常涉及在预定的基础设施和拓扑上部署模型,或者使用不考虑 LLM 推理这些独特阶段的基本分布式策略。这会导致资源利用率低下,GPU 在推理的不同阶段利用不足或过载。虽然 vLLM 已成为一种流行的开源推理引擎,通过近乎连续的批处理和 PagedAttention 提高了效率,但大规模部署的组织在编排部署和优化多个节点之间的路由决策方面仍然面临挑战。
我们宣布与 llm-d 团队合作,将强大的分布式推理功能引入 AWS,使客户能够提高性能、最大化 GPU 利用率并降低大规模推理工作负载的服务成本。此次发布是与 llm-d 社区数月紧密合作的结果,旨在提供一个名为 ghcr.io/llm-d/llm-d-aws 的新容器,其中包含特定于 AWS 的库,如 Elastic Fabric Adapter (EFA) 和 libfabric,以及 llm-d 与 NIXL 库的集成,以支持多节点分布式推理和专家并行等关键功能。我们还通过多轮迭代进行了广泛的基准测试,以达到一个稳定的版本,使客户能够在 Amazon SageMaker HyperPod 和 Amazon Elastic Kubernetes Service (Amazon EKS) 等 AWS Kubernetes 系统上开箱即用地访问这些强大的功能。
在本文中,我们将介绍下一代推理功能背后的概念,包括分布式服务、智能请求调度和专家并行。我们将讨论它们的优势,并介绍如何在 Amazon SageMaker HyperPod EKS 上实现它们,以在推理性能、资源利用率和运营效率方面取得显著的改进。
什么是 llm-d?
llm-d 是一个开源的、Kubernetes 原生的分布式大型语言模型(LLM)服务框架。llm-d 构建在 vLLM 之上,通过生产级编排、高级调度和高性能互连支持来扩展核心推理引擎,从而实现可扩展的多节点模型服务。
llm-d 不将推理视为单节点执行问题,而是引入了分布式服务的架构模式——将预填充、解码和 KV 缓存管理等阶段分离并跨分布式 GPU 资源进行改进。这使得运营商能够有效地利用 AWS Elastic Fabric Adapter (EFA) 等高速 fabric,同时保持与 Kubernetes 原生部署工作流的兼容性。
为了使这些功能可用,llm-d 提供了一套“明路”(well-lit paths)——参考服务架构,它们打包了针对不同性能、可扩展性和工作负载目标的成熟优化策略:
智能推理调度
虽然智能调度示例基于队列深度等其他因素进行路由决策,但其独特的路由方法是它试图猜测 KV 缓存中请求的局部性,而无需了解 KVCache 的状态。在单实例环境中,像 vLLM 这样的引擎使用自动前缀缓存来重用先前 KV 缓存条目,减少重复计算,从而驱动更快、更高效的性能。然而,一旦扩展到分布式、多副本环境,关于哪个 kvblocks 存在于哪个 GPU 上的假设就可能失效。如果不了解其中间状态下请求的局部性,请求可能会被路由到缺乏相关缓存上下文的实例,从而完全抵消前缀缓存的好处。
llm-d 调度程序通过维护跨服务副本的缓存状态可见性并据此路由请求来解决此问题。对于具有高前缀重用的工作负载,例如多轮对话或代理工作流,这种缓存感知路由可以通过确保请求被定向到已持有相关 KV 缓存条目的服务器来显著提高吞吐量和降低延迟。
预填充和解码分布式
如前所述,LLM 推理的预填充和解码阶段具有根本不同的资源配置,预填充是计算密集型的,而解码是内存带宽密集型的。在传统部署中,这两个阶段共享相同的硬件,这意味着两者都无法独立优化。分离这两个阶段可以带来多种优化机会。例如,如果您的输出上下文长度大于输入长度,您可以为解码分配比预填充更多的 GPU。您还可以将这两个阶段放置在不同类型的硬件上,每种硬件都针对其各自的工作负载特性进行了优化。
在 llm-d 中,预填充服务器针对高效处理输入提示进行了优化,而解码服务器则专注于以低延迟生成输出 token。智能调度程序决定哪些实例应接收给定请求,并通过与解码实例并行运行的 sidecar 来协调传输。sidecar 指示 vLLM 通过高速互连执行点对点 KV 缓存传输,以确保解码服务器以最小的开销从预填充服务器接收必要的缓存上下文。这种分布式处理显著提高了首次 token 时间(TTFT)和整体吞吐量,尤其适用于具有长提示或处理大型模型的工作负载。
广泛的专家并行
对于像 DeepSeek-R1、Qwen3.5、Minimax 和 Kimi K2.5 这样的混合专家(MoE)模型,llm-d 提供了优化的部署模式,使用数据并行和专家并行。这种方法通过将专家横向分布在多个节点上同时保持性能,从而能够高效地部署大型 MoE 模型。通过将模型专家分布在加速器上并使用改进的通信模式,llm-d 可以显著降低这些复杂架构的端到端延迟并提高吞吐量。然而,扩展 MoE 模型会引入更复杂的并行、通信和调度要求,这些要求必须针对每个部署场景进行仔细调整。
分层前缀缓存
前缀缓存可避免执行重复且昂贵的 KV 缓存计算,从而提高 TTFT 和整体吞吐量等指标。虽然 vLLM 等推理引擎内置了本地前缀缓存,但它们受到给定实例上可用 GPU 内存量的限制。为了将 KV 缓存的有效大小扩展到 GPU 内存限制之外,llm-d 提供了一个分层缓存路径,可将 KV 缓存条目从 GPU 内存卸载到其他存储层,如 CPU 内存或本地磁盘。
这些“明路”作为模型服务器配置和部署的起点。它们被设计为 vLLM 部署和推理调度器配置的可组合构建块,这意味着跨多个路径的功能可以组合和配置在一起,以满足特定的工作负载要求。
在 AWS 上运行 llm-d
Amazon SageMaker HyperPod EKS
Amazon SageMaker HyperPod 提供了一个有弹性的、高性能的 Kubernetes 基础设施,针对大规模模型训练和推理进行了优化。它提供了持久的高性能集群,解决了组织在部署大型模型时面临的许多基础设施挑战。该系统内置了健康监控,能够主动检测和修复硬件故障,以维护生产工作负载的高可用性。原生 Kubernetes 支持简化了容器编排,使其成为 llm-d Kubernetes 原生架构的理想基础。
参考架构
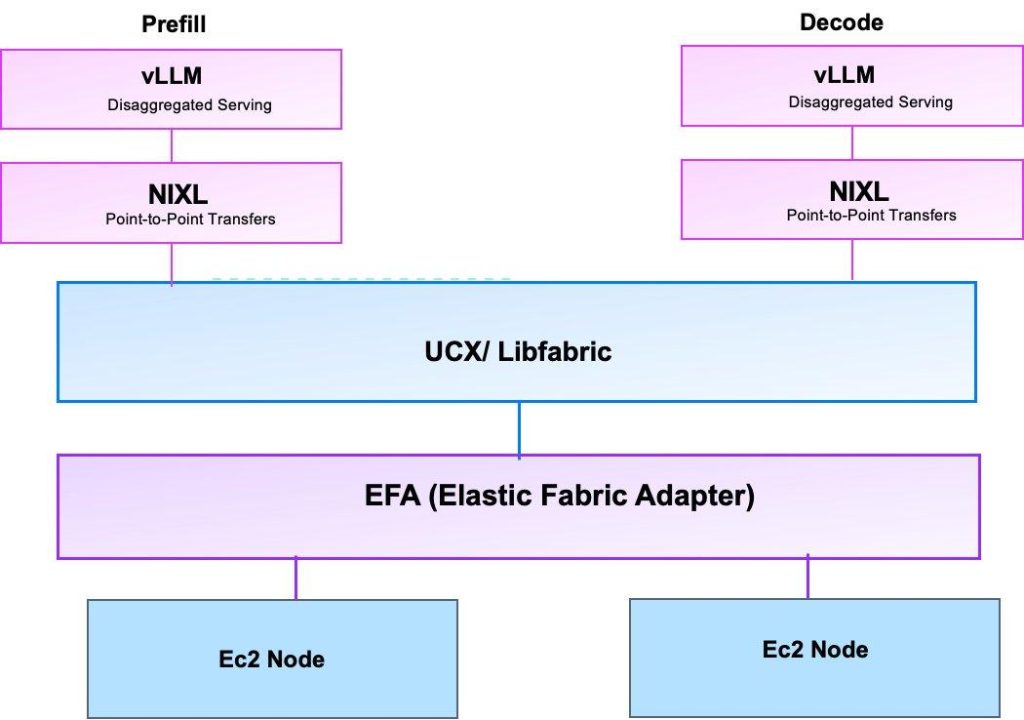
为了理解 llm-d 如何在 AWS 基础设施上高效运行,理解支持高性能分布式推理的通信层很重要。对于单节点上的 GPU 到 GPU 通信,NVLink 和 NVSwitch 用于预填充和解码工作器之间的高带宽传输。以下各节将介绍关键组件及其工作原理。
NIXL 用于点对点推理传输
NCCL 在 LLM 训练中被广泛使用,擅长集体通信模式,而分布式推理架构需要高效的点对点数据传输,例如,将 KV 缓存数据从预填充节点移动到解码节点。NVIDIA Inference Xfer Library (NIXL) 专为此场景而构建。NIXL 提供了一个内存抽象层,涵盖 CPU 内存、GPU 内存和存储后端,包括文件、块和对象存储(如 Amazon S3)。它作为各种传输方法的抽象层,包括用于 EFA 接口的 libfabric、UCCL 和 GPUDirect Storage。
通过 NIXL,实例使用 RDMA 在预填充和解码服务器之间传输 KV 缓存数据。RDMA 允许 GPU 绕过操作系统直接读取对等设备内存,这对于 TTFT 是关键性能指标的推理工作负载至关重要。在 llm-d 架构中,vLLM 服务器部署在 InferencePools 中进行路由,并通过 NIXL 作为 KV 缓存共享的连接器来配置预填充/解码分布式。NIXL 利用连接到实例的 EFA 接口进行高带宽通信,确保在分布式阶段之间传输缓存上下文的开销保持最小。
UCX 和传输层
Unified Communication X (UCX) 是一个较低级别的通信框架,它提供了 NIXL 可以用于节点间通信的传输层。UCX 支持 RDMA 操作,可实现零拷贝、内核旁路的网络通信,这对于最大限度地减少分布式工作负载中的延迟和最大化带宽至关重要。重要的是,UCX 通过 libfabric 接口原生支持 AWS Elastic Fabric Adapter (EFA),在 GPU 需要跨节点通信时,为 NCCL 提供了高性能的管道。
Elastic Fabric Adapter (EFA)
EFA 在 AWS 上提供高性能网络接口,这对于跨多个节点扩展分布式推理至关重要。EFA 使用 libfabric 作为其用户空间接口,而 UCX 包含一个可以利用 EFA 的 libfabric 传输层。这种集成意味着,当 llm-d 在多个节点上部署 vLLM 时,底层通信堆栈可以充分利用 EFA 的低延迟、高带宽网络,而无需在应用程序级别进行更改。
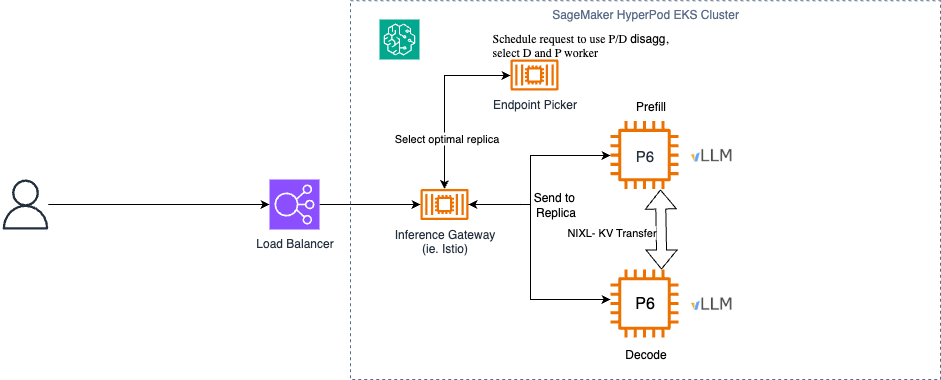
我们可以配置 AWS Load Balancer Controller 来配置负载均衡器以连接到 Inference Gateway。Inference Gateway (IGW) 位于 vLLM 实例的前面,根据缓存局部性和服务器负载等各种因素提供智能请求调度和路由。KV Cache Manager 支持缓存感知路由和分布式缓存管理,跟踪哪些 KV 缓存块位于哪些节点上。这些组件协同工作,创建一个灵活、可扩展的 LLM 推理系统,解决了大规模服务大型模型的独特挑战。
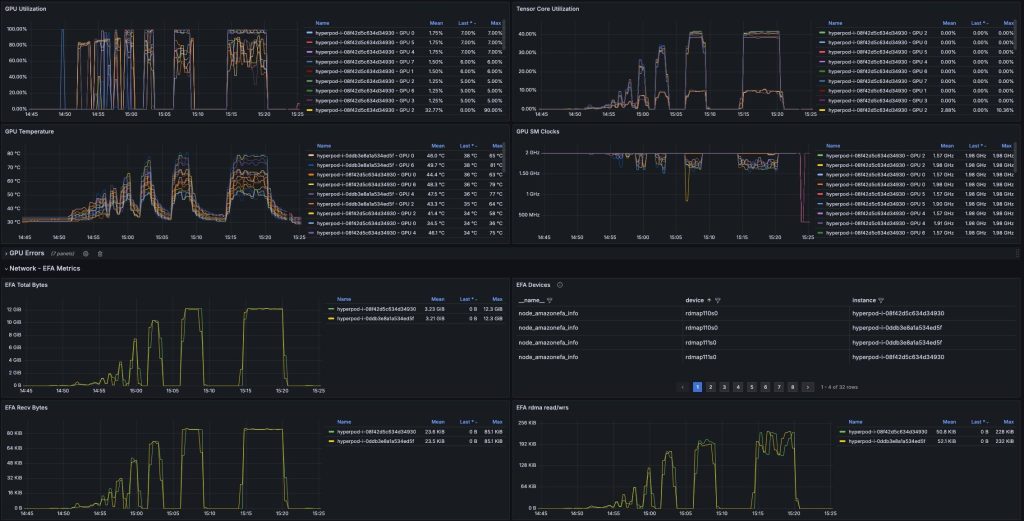
借助 SageMaker HyperPod 的可观察性仪表板,您可以在推理时监控关键指标,如 GPU 利用率、EFA 指标和错误计数,以主动监控和优化您的推理工作负载。
最佳实践
分布式推理允许您将预填充节点与解码节点分开扩展,从而能够根据工作负载调整性能。例如,较长的输入序列长度和较短的输出序列长度是预填充密集型工作负载。分布式推理允许您扩展预填充 pod 以更有效地处理更多请求,而无需增加成本。但它并非适用于所有工作负载。您可以尝试将其用于大型模型、长输入序列和稀疏 MoE 架构。
llm-d 还提供了通过推理网关根据请求队列和 KV 缓存事件等指标智能路由流量到特定 pod 的路径。这有助于提高 LLM 推理工作负载的性能和 KV 缓存命中率,从而提高吞吐量。该项目仍在开发中,并不断为托管 LLM 工作负载添加更多路径和改进。
部署概述
先决条件
在继续部署任何一种模式之前,您需要在本地设备上设置以下组件:
- AWS Command Line Interface (AWS CLI)
- kubectl
- HuggingFace 账户用于创建访问令牌
- Helm
- helmfile
- 对 SageMaker HyperPod 或 EKS 集群的访问权限
llm-d 设置
llm-d 使用 Gateway Inference API Extension,这需要安装 CRDs 和 Istio 等实现。克隆 llm-d 存储库并导航到安装助手:
git clone https://github.com/llm-d/llm-d.git
cd guides/prereq/gateway-provider安装提供程序和实现
./install-gateway-provider-dependencies.sh
helmfile apply -f istio.helmfile.yaml #或 kgateway(如果使用 Kgateway)安装完成后,您就可以开始部署指南了。
模型部署
llm-d 存储库在其 GitHub 上提供了许多用于 Kubernetes 推理的“明路”。每个指南都使用 helmfile 进行配置,并分为两个文件夹。一个用于 Gateway AI Extension,它配置 Kubernetes Gateway;另一个用于模型服务,它配置模型托管配置。
包含 AWS 库的 Docker 镜像:ghcr.io/llm-d/llm-d-aws:v0.5.1
要使用 AWS Load Balancer 公开 Gateway,您可以在 ./guides/prereq/gateway-provider/common-configurations 下配置所需的 Type 和 Annotations。
例如,我们将 ./guides/prereq/gateway-provider/common-configurations/istio.yaml 配置为:
# Infra values
gateway:
gatewayClassName: istio
gatewayParameters:
accessLogging: false
logLevel: error
resources:
limits:
cpu: "16"
memory: 16Gi
requests:
cpu: "4"
memory: 4Gi
service:
type: LoadBalancer
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internal
service.beta.kubernetes.io/aws-load-balancer-type: external # GAIE values
inferenceExtension:
flags:
v: 1
provider:
name: istio
istio:
destinationRule:
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 256000
maxRequestsPerConnection: 256000
http2MaxRequests: 256000
idleTimeout: "900s"
tcp:
maxConnections: 256000
maxConnectionDuration: "1800s"
connectTimeout: "900s" # MS values
routing:
proxy:
zapLogLevel: error当 Istio Gateway 创建后,它将在您的 VPC 中配置一个网络负载均衡器供使用。从这里,您可以按照 README 文件中的说明配置示例来部署堆栈。要开始运行 inference-scheduling 示例,请从 llm-d 目录运行:
cd guides/inference-scheduling在这里您将看到结构如下:
❯ tree
.
├── gaie-inference-scheduling
│ └── values.yaml
├── helmfile.yaml.gotmpl
├── httproute.gke.yaml
├── httproute.yaml
├── ms-inference-scheduling
│ ├── digitalocean-values.yaml
│ ├── values_amd.yaml
│ ├── values_cpu.yaml
│ ├── values_tpu.yaml
│ ├── values_xpu.yaml
│ ├── values-hpu.yaml
│ └── values.yaml
└── README.mdms-inference-scheduling 文件夹包含在您的节点上运行 vLLM 副本的配置值。gaie-inference-scheduling 将使用您之前选择的提供程序来配置推理网关。
准备好部署后,运行 helmfile apply 将指南部署到您的集群。
使用预填充-解码分布式进行部署
使用预填充/解码分布式进行部署的指南位于 guides/pd-disaggregation。要在 SageMaker HyperPod 集群等环境中运行,您必须将副本配置为使用启用了 EFA 的映像运行,并确保为 pod 分配 EFA 接口。
在 ms-pd/values.yaml 中,您可以类似地进行配置:
containers: -
name: "vllm"
image: ghcr.io/llm-d/llm-d-aws
modelCommand: vllmServe
args:
- "--block-size"
- "128"
- "--kv-transfer-config"
- '{"kv_connector":"NixlConnector", "kv_role":"kv_both","kv_connector_extra_config": {"backends": ["LIBFABRIC"]}}'
- "--disable-uvicorn-access-log"
- "--max-model-len"
- "32000"
env:
- name: VLLM_NIXL_SIDE_CHANNEL_HOST
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: HF_HOME
value: "/model-cache"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
- containerPort: 5600
name: nixl
protocol: TCP
resources:
limits:
memory: 64Gi
cpu: "8"
# note: GPU resources get controlled by parallelism + accelerators above
vpc.amazonaws.com/efa:4
requests:
memory: 64Gi
cpu: "8"
# note: GPU resources get controlled by parallelism + accelerators above
vpc.amazonaws.com/efa: 4映像需要使用 llm-d 的 AWS 兼容容器。vLLM 配置为使用 libfabric 后端,以最大化网络带宽。要配置 EFA 接口的数量,您应该根据每个 Pod 运行的 GPU 数量和实例上可用的 EFA 接口数量进行分配。例如,p5.48xlarge 实例有 8 个 H100 GPU 和 32 个 Elastic Fabric Adapter 接口,因此您应该为每个副本配置每个 GPU 4 个 EFA 接口。
可选地,您也可以为 kv_connector_extra_config 配置 "enable_cross_layers_blocks": "True",以减少 vLLM 将传输的数据量。
运行推理
部署后,EKS 将创建一个 AWS Network Load Balancer 用于部署。要获取负载均衡器 DNS 名称,请运行 kubectl get gateways。然后您可以使用 curl 调用它:
export OPENAI_API_BASE=<generated ELB endpoint>
curl $OPENAI_API_BASE/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "RedHatAI/Llama-3.3-70B-Instruct-FP8-dynamic",
"messages": [
{
"role": "user",
"content": "Hello! Who are you?"
}
],
"max_tokens": 256
}' | jq分布式推理
基准测试
我们在 ml.p6-b200.48xlarge 上使用具有 4 个张量并行度的 vLLM 部署了 OpenAI 的 GPT-OSS。我们将其与 llm-d 的预填充/解码分布式路径进行了比较,该路径具有 4 个预填充 pod,每个 pod 具有 1 个张量并行度,以及 1 个具有 4 个张量并行度的解码 pod。这些 pod 使用 NIXL 连接,并以 Libfabric 作为底层传输后端,以在实例上使用 Elastic Fabric Adapter 网络。
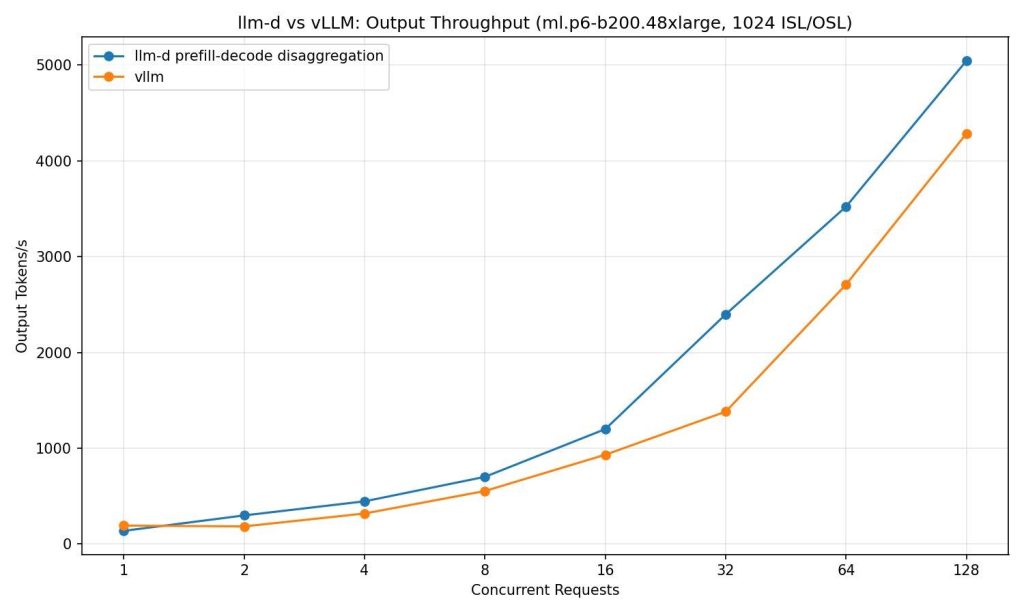
在我们的测试中,我们发现在使用 1024 个输入 token 和 1024 个输出 token 的输入序列进行负载测试,并发度高达 128 时,与使用标准 vLLM 部署相比,使用 llm-d 的预填充/解码分布式路径可以将 token 每秒增加高达 70%。此性能配置文件因您的 vLLM 配置和工作负载而异。调整预填充/解码比例和其他 vLLM 服务器可用的参数可能会带来更多性能。
结论
llm-d 提供了诸如预填充/解码分布式、精确的 KV 感知路由和分层 KV 缓存等部署方法。这些方法为大规模托管提供了进一步提高性能的方法。您可以根据需要调整 vLLM 设置,以改进 TTFT、ITL 或缓存命中率等指标。您还可以使用 LMCache 等框架进行 KV 卸载。请在 https://llm-d.ai/docs/architecture 查看 llm-d。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区