



📢 转载信息
原文链接:https://machinelearningmastery.com/uncertainty-in-machine-learning-probability-noise/
原文作者:Matthew Mayo

编者按:本文是我们关于可视化机器学习基础知识系列文章的最新一篇。
欢迎阅读我们可视化机器学习基础知识系列的最新文章。在该系列中,我们的目标是将重要且通常复杂的技术概念分解为直观的视觉指南,以帮助您掌握该领域的核心原理。本篇重点关注机器学习中的不确定性、概率和噪声。
机器学习中的不确定性
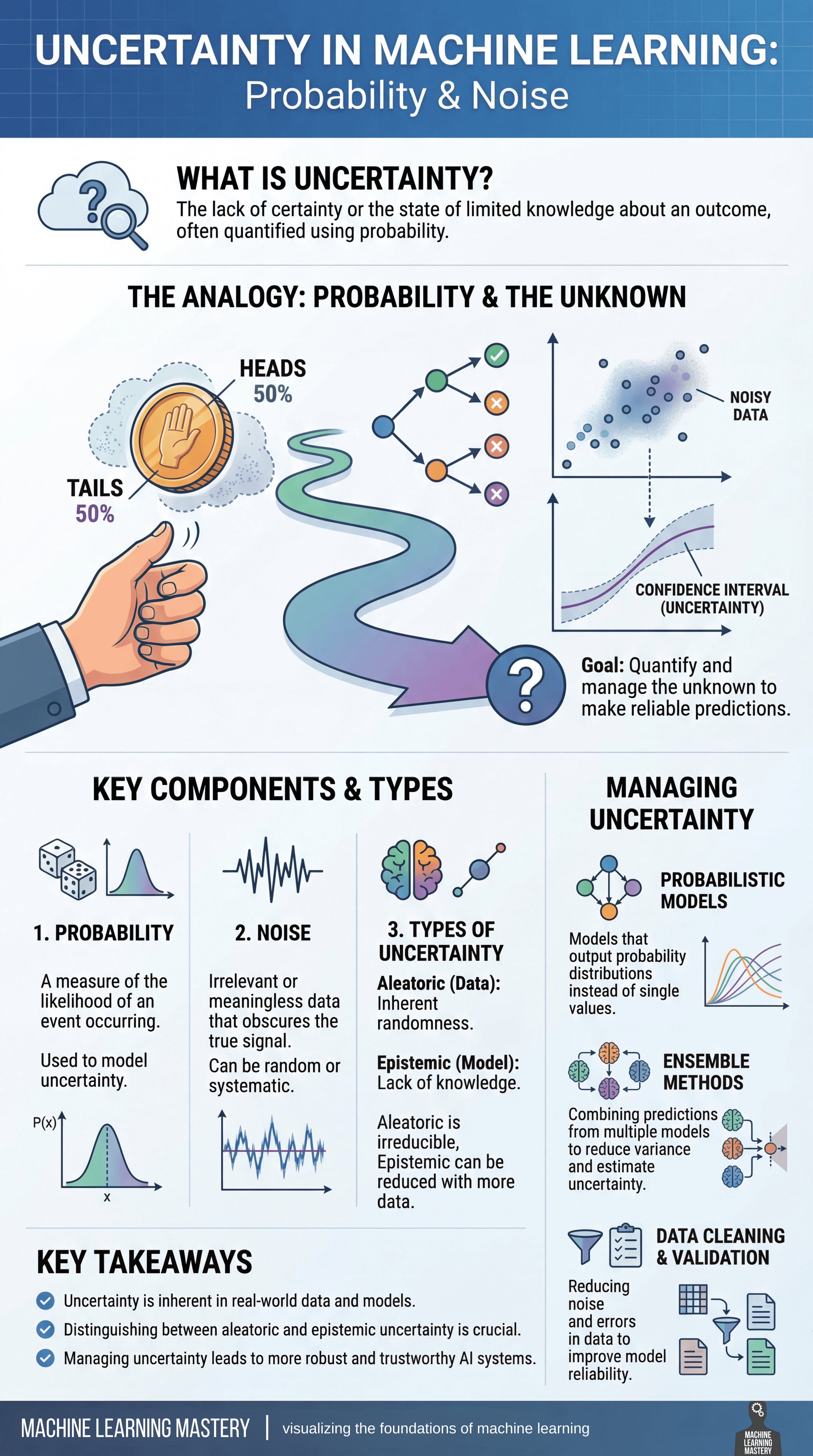
不确定性是机器学习中不可避免的一部分,每当模型试图对现实世界做出预测时都会出现。从本质上讲,不确定性反映了对某一结果的知识不完整,并且通常使用概率来量化。不确定性并非模型的缺陷,而是模型为了产生可靠和可信赖的预测而必须明确考虑的因素。
思考不确定性的一种有效方式是通过概率和未知的角度来看待。就像抛一个公平的硬币一样,尽管概率定义明确,但结果是不确定的,机器学习模型也经常在存在多种可能结果的环境中运行。当数据流经模型时,预测会分岔到不同的路径,这些路径受到随机性、信息不完整性和数据本身变异性的影响。
处理不确定性的目标不是消除它,而是测量和管理它。这涉及到理解几个关键组成部分:
- 概率提供了一个数学框架,用于表达事件发生的可能性。
- 噪声代表数据中不相关或随机的变化,它会掩盖真实的信号,可能是随机的,也可能是系统的。
这些因素共同决定了模型预测中存在的不确定性。
并非所有不确定性都是相同的。偶然不确定性(Aleatoric uncertainty)源于数据中固有的随机性,即使收集更多信息也无法减少。另一方面,认知不确定性(Epistemic uncertainty)源于对模型或数据生成过程的知识不足,通常可以通过收集更多数据或改进模型来减少。区分这两种类型对于解释模型行为和决定如何提高性能至关重要。
为了管理不确定性,机器学习从业者依赖于几种策略。概率模型输出完整的概率分布,而不是单一的点估计,从而明确地表达不确定性。集成方法结合多个模型的预测来减少方差并更好地估计不确定性。数据清洗和验证通过在训练前减少噪声和纠正错误,进一步提高了可靠性。
不确定性是真实世界数据和机器学习系统的固有属性。通过识别其来源并将其直接纳入建模和决策制定中,从业者可以构建出不仅更准确,而且更稳健、透明和可信赖的模型。
下面的可视化工具提供了这些信息的简洁摘要,供您快速参考。您可以在此处获取高分辨率信息图的PDF版本。
不确定性、概率与噪声:可视化机器学习的基础
作者供图(点击放大)
机器学习精通资源
以下是一些关于概率和噪声的精选学习资源:
- 机器学习中的不确定性简介 – 本文解释了不确定性在机器学习中的含义,探讨了数据噪声、覆盖不全和模型不完美等主要原因,并描述了概率如何提供量化和管理这种不确定性的工具。
关键要点:概率对于理解和管理预测建模中的不确定性至关重要。 - 机器学习概率(7天迷你课程) – 这个结构化的速成课程指导读者了解机器学习中所需的关键概率概念,从基础概率类型和分布到朴素贝叶斯和熵,并提供实用的课程,旨在建立您在Python中应用这些思想的信心。
关键要点:建立坚实的概率基础可以增强您应用和解释机器学习模型的能力。 - 使用Python理解机器学习中的概率分布 – 本教程介绍了机器学习中使用的重要概率分布,展示了它们如何应用于建模残差和分类等任务,并提供了Python示例,以帮助从业者有效地理解和使用它们。
关键要点:掌握概率分布有助于您在整个机器学习工作流程中对不确定性进行建模并选择合适的统计工具。
请留意我们关于可视化机器学习基础知识系列的更多文章。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区