



📢 转载信息
原文作者:Iván Palomares Carrascosa
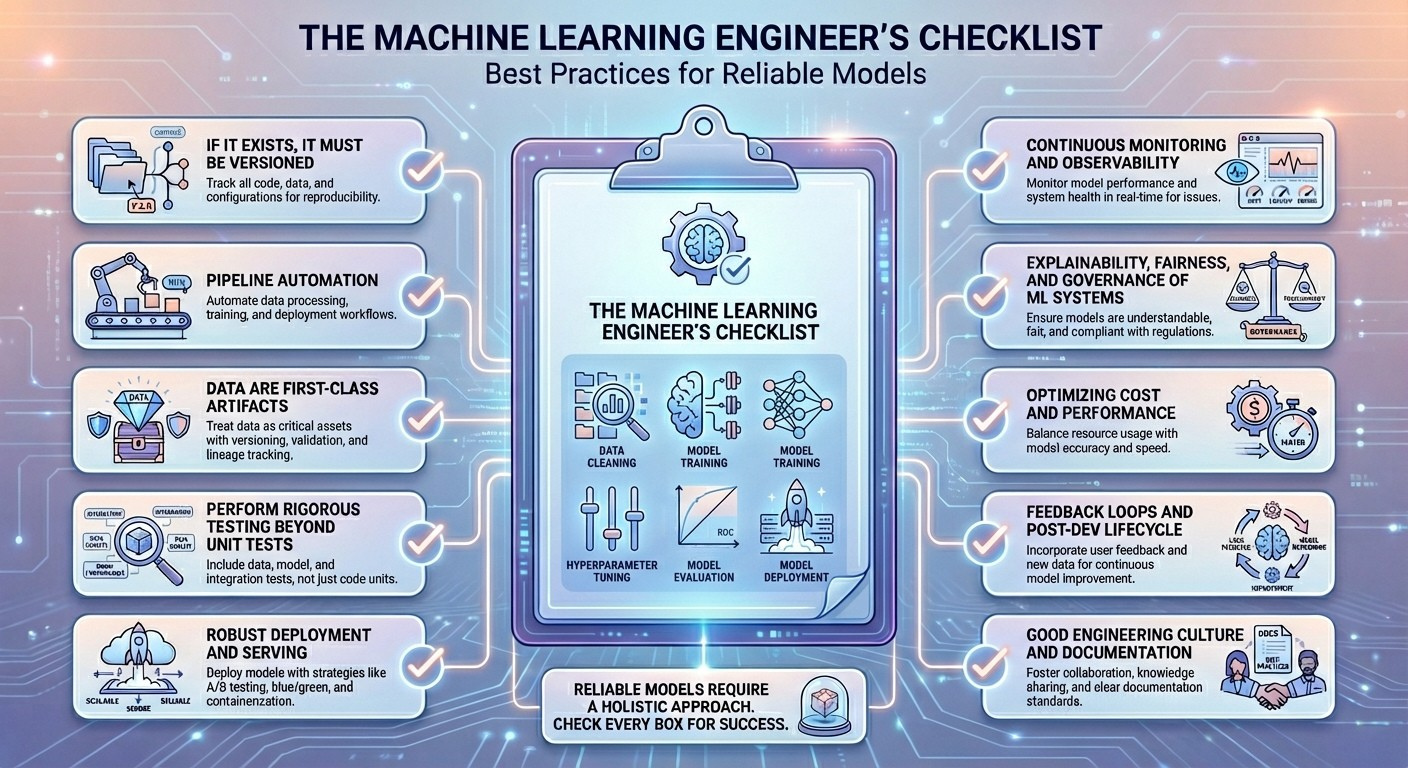
机器学习工程师清单:构建可靠模型的最佳实践
图片来源:Editor
引言
得益于成熟的框架和易于获取的计算能力,构建新训练的机器学习模型并使其成功运行是一项相对直接的任务。然而,模型在生产生命周期中真正的挑战始于第一次成功的训练运行之后。一旦部署,模型就会在一个动态的、不可预测的环境中运行,其性能可能会迅速下降,使成功的概念验证变成代价高昂的负资产。
实践者经常会遇到诸如数据漂移(生产数据特征随时间变化)、概念漂移(输入和输出变量之间潜在关系演变)或微妙的反馈循环(使未来训练数据产生偏差)等问题。这些陷阱——从灾难性的模型失败到缓慢、隐蔽的性能衰退——通常是由于缺乏适当的操作严谨性和监控系统造成的。
构建能够长期保持良好性能的可靠模型是另一回事,这需要纪律、强大的MLOps管道,当然还有技能。本文将重点关注这一点。通过提供一种系统性的方法来应对这些挑战,这份基于研究的清单概述了每位机器学习工程师都应熟悉的基本最佳实践、核心技能以及有时不容错过的工具。通过采纳本指南中概述的原则,您将有能力将初步模型转变为可维护、高质量的生产系统,确保它们在不可避免的现实世界变化和挑战中保持准确、无偏见和具有弹性。
话不多说,以下是我为您精心挑选的10项机器学习工程师最佳实践,旨在让您的模型在长期可靠性方面发挥最佳性能。
清单
1. 如果存在,就必须进行版本控制
数据快照、模型训练代码、使用的超参数以及模型制品——所有这些都很重要,并且在模型的整个生命周期中都会发生变化。因此,围绕机器学习模型的一切都应该得到适当的版本控制。例如,试想一下,您图像分类模型的性能(过去一直很好)在进行了一次具体的错误修复后开始下降。有了版本控制,您将能够重现旧的模型设置,并更安全地隔离问题的根本原因。
这里没有火箭科学——版本控制在整个工程界是广为人知的,核心技能包括管理Git工作流程、数据沿袭和实验跟踪;特定的工具如DVC、Git/GitHub、MLflow和Delta Lake。
2. 管道自动化
作为持续集成和持续交付 (CI/CD) 原则的一部分,涉及数据预处理、训练、验证和部署的可重复过程应封装在具有自动化运行和测试的管道中。假设一个获取新数据的夜间设置管道——例如传感器捕获的图像——会运行验证测试,根据需要重新训练模型(例如,由于数据漂移),重新评估业务关键绩效指标 (KPI),并将更新后的模型推送到暂存环境。这是管道自动化的一个常见例子,它需要工作流编排技能、对Docker和Kubernetes等技术的了解,以及测试自动化知识。
常用的有用工具包括:Airflow、GitLab CI、Kubeflow、Flyte和GitHub Actions。
3. 数据是“一等公民”的制品
在任何软件工程项目中对软件测试应用的严谨性,也必须体现在对数据质量和约束的执行上。数据是机器学习模型从创建到在生产中服务的必需的“营养物质”;因此,它们摄入的任何数据的质量都必须是最佳的。
对数据类型、模式设计以及诸如异常值、离群值、重复数据和噪声等数据质量问题的扎实理解,对于将数据视为一等资产至关重要。Evidently、dbt tests和Deequ等工具旨在帮助实现这一点。
4. 执行严格的单元测试以外的测试
测试机器学习系统涉及针对管道集成、特征逻辑以及输入和输出的统计一致性等方面的特定测试。如果重构的特征工程脚本对特征的原始分布应用了微妙的修改,您的系统可能会通过基本的单元测试,但通过分布测试,问题可以被及时发现。
测试驱动开发 (TDD) 和统计假设检验的知识是“将此最佳实践付诸实践”的有力盟友,需要关注的实用工具包括pytest库、定制的数据漂移测试以及单元测试中的模拟(mocking)。
5. 健壮的部署和服务
拥有健壮的机器学习模型部署和服务,意味着模型应该被打包、可重现、可扩展到大型环境,并且在需要时能够安全回滚。
所谓的蓝绿部署策略,即部署到两个“相同”的生产环境中,是一种确保在发生延迟峰值时可以快速将传入数据流量切换回旧环境的方法。云架构与容器化对此有所帮助,具体工具包括Docker、Kubernetes、FastAPI和BentoML。
6. 持续监控与可观测性
这可能已经在您的最佳实践清单上了,但作为机器学习工程的基本要素,它值得强调。对已部署模型的持续监控和可观测性涉及监控数据漂移、模型衰减、延迟、成本以及除准确率或错误率之外的其他特定于领域的业务指标。
例如,如果欺诈检测模型的召回率在出现新的欺诈模式后下降,正确设置的漂移警报可能会触发使用新交易数据重新训练模型的必要性。Prometheus和商业智能工具如Grafana在此可以提供很大帮助。
7. ML系统的可解释性、公平性和治理
机器学习工程师的另一个关键要素是,旨在确保交付具有透明、合规和负责任行为的模型,理解并遵守现有的国家或地区法规——例如《欧盟人工智能法案》。应用这些原则的一个例子是,在部署之前对贷款分类模型进行公平性检查,以保证任何受保护群体都不会被不合理地拒绝。为了实现可解释性和治理,强烈推荐使用SHAP、LIME、模型注册表和Fairlearn等工具。
8. 优化成本和性能
此最佳实践要求优化模型的训练和推理吞吐量,以及延迟和硬件消耗。利用此项工作的一种方法是将传统模型转向使用混合精度和量化等技术,从而在保持精度的同时显著降低 GPU 成本。已经提供对这些技术支持的库和框架包括PyTorch AMP、TensorRT和vLLM,仅举几例。
9. 反馈循环与后开发生命周期
此项中的具体最佳实践包括收集“真实”数据标签、在完善的工作流程下重新训练模型,以及弥合现实世界结果与模型预测之间的差距。推荐系统是一个很好的例子:它需要频繁地重新训练,并纳入最近的用户交互,以避免过时。毕竟,用户的偏好是随时间变化和演进的!
定义可靠的反馈循环和后开发生命周期所需的好用技能包括定义适当的数据标记策略、设计模型再训练方案,以及使用事件运行手册(事件运行手册是用于快速识别、分析和应对生产机器学习系统问题的分步指南)。同样,像Tecton和Feast这样的特征存储工具在追求这些实践时也很有帮助。
10. 良好的工程文化和文档记录
为了总结这份清单,良好的工程文化与所有其他九项最佳实践相结合,对于减少不明显的“技术债务”并提高系统可维护性至关重要。简单来说,清晰记录的模型意图可以防止未来的工程师将其用于非预期任务。沟通、跨职能协作和有效的知识管理是三个基本支柱。公司广泛使用的工具,如Confluence和Notion,可以提供帮助。
总结
尽管机器学习领域充满了复杂的挑战——从管理技术债务和数据漂移到维护公平性和高性能——但这些问题并非不可克服。最成功的 MLOps 团队将这些障碍视为流程改进的必要目标,而不是路障。通过采纳本清单中概述的系统化、严格的实践,工程师可以超越零散、临时的解决方案,建立一种持久的质量文化。遵循这些原则,从对一切进行版本控制到严格测试数据和自动化部署,将长期模型可靠性这一艰巨任务转变为一项可管理、可重现的工程工作。正是这种对最佳实践的承诺,最终将成功的科研项目与可持续、有影响力的生产系统区分开来。
本文提供了机器学习工程师的10项基本最佳实践清单,以帮助确保模型在长期开发和部署中的可靠性,并附带了遵循这些市场上的最佳实践的具体策略、示例场景和有用工具。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区