



📢 转载信息
原文链接:https://blogs.nvidia.com/blog/rtx-ai-garage-open-models-google-gemma-4/
原文作者:Michael Fukuyama
开放模型正在推动本地 AI 的新浪潮,将创新从云端扩展到日常设备。随着这些模型的不断进步,其价值日益取决于对本地实时上下文的访问能力,从而将有意义的洞察转化为实际行动。
为了适应这一转变,Google 最新推出的 Gemma 4 系列模型引入了一类小型、快速且全能的模型,旨在跨多种设备实现高效的本地运行。
Google 与 NVIDIA 展开合作,针对 NVIDIA GPU 对 Gemma 4 进行了优化,使其能够在各种系统中实现高效性能——从数据中心部署到 NVIDIA RTX 支持的 PC 和工作站,以及 NVIDIA DGX Spark 个人 AI 超级计算机和 NVIDIA Jetson Orin Nano 边缘 AI 模块。
Gemma 4:针对 NVIDIA GPU 优化的紧凑型模型
最新加入 Gemma 4 开放模型系列的成员——涵盖 E2B、E4B、26B 和 31B 等不同变体——专为从边缘设备到高性能 GPU 的高效部署而设计。
这一代紧凑型模型支持多项任务,包括:
- 推理: 在复杂问题解决任务中表现强劲。
- 编码: 为开发人员工作流程提供代码生成与调试支持。
- 代理(Agents): 原生支持结构化工具调用(函数调用)。
- 视觉、视频和音频功能: 具备物体识别、自动语音识别以及文档或视频智能处理能力,实现丰富的多模态交互。
- 交错式多模态输入: 可以在单个提示词中以任何顺序混合文本和图像。
- 多语言: 开箱即支持 35 种以上语言,预训练语种超过 140 种。
E2B 和 E4B 模型 专为边缘端的超高效、低延迟推理而构建,能够在包括 Jetson Nano 模块在内的众多设备上实现近乎零延迟的完全离线运行。
26B 和 31B 模型 旨在提供高性能的推理和以开发人员为中心的工作流程,非常适合代理 AI 应用。通过优化,这些模型在 NVIDIA RTX GPU 和 DGX Spark 上运行高效,能够为开发环境、编码助手和代理驱动的工作流程提供强大支持。
随着本地代理 AI 的持续普及,OpenClaw 等应用程序正在 RTX PC、工作站和 DGX Spark 上实现全天候待命的 AI 助手。最新的 Gemma 4 模型兼容 OpenClaw,允许用户构建能够从个人文件、应用程序和工作流程中提取上下文以实现任务自动化的本地代理。
入门指南:在 RTX GPU 和 DGX Spark 上运行 Gemma 4
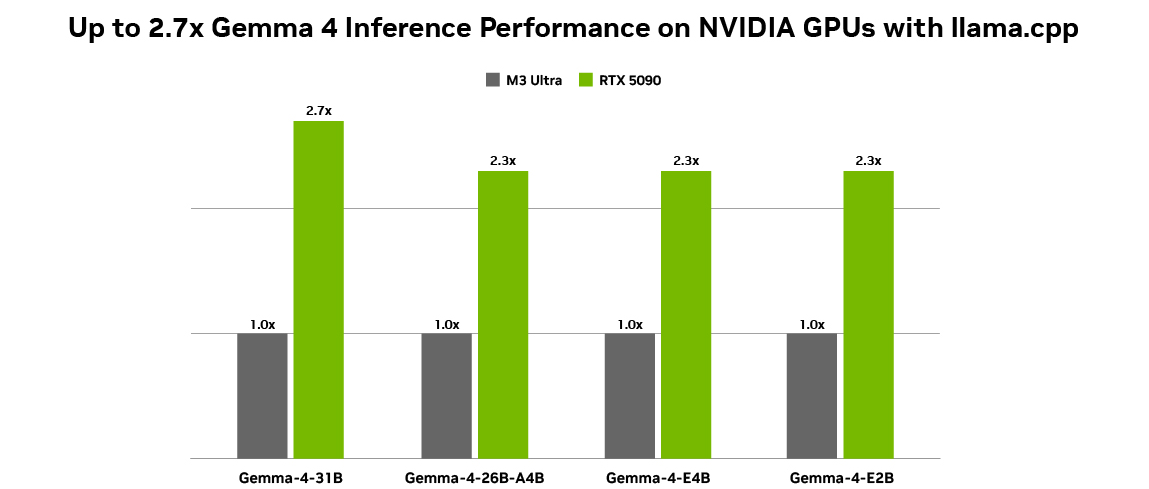
NVIDIA 已与 Ollama 和 llama.cpp 合作,为每一款 Gemma 4 模型提供最佳的本地部署体验。
用户可以下载 Ollama 运行 Gemma 4 模型,或安装 llama.cpp 并配合 Gemma 4 GGUF Hugging Face 检查点使用。此外,Unsloth 提供首日支持,通过 Unsloth Studio 提供经过优化和量化的模型,以便进行高效的本地微调和部署。
在 NVIDIA GPU 上运行 Gemma 4 等开放模型可实现最佳性能,因为 NVIDIA Tensor Cores 能够加速 AI 推理工作负载,从而为本地运行带来更高的吞吐量和更低的延迟。此外,CUDA 软件堆栈确保了在主流框架和工具之间的广泛兼容性,使新模型能够从第一天起就高效运行。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区