



📢 转载信息
原文作者:Shreyas Subramanian, Nick McCarthy, Shalendra Chhabra, and Shreeya Sharma
2025年12月,我们宣布在 Amazon Bedrock 上支持强化微调(RFT),并首先支持 Nova 模型。随后,我们在2026年2月扩展了对 OpenAI GPT OSS 20B 和 Qwen 3 32B 等开放权重模型的支持。Amazon Bedrock 中的 RFT 实现了端到端自定义工作流的自动化,使模型能够通过小规模提示词集对多个可能响应进行反馈学习,而非依赖传统的庞大数据集。
强化微调的工作原理
强化微调(RFT)代表了我们自定义大语言模型(LLM)方式的范式转变。与需要从静态输入/输出对中学习的传统监督微调(SFT)不同,RFT 通过迭代反馈循环使模型能够不断生成响应、获取评估并持续提升决策能力。
核心理念:从反馈中学习
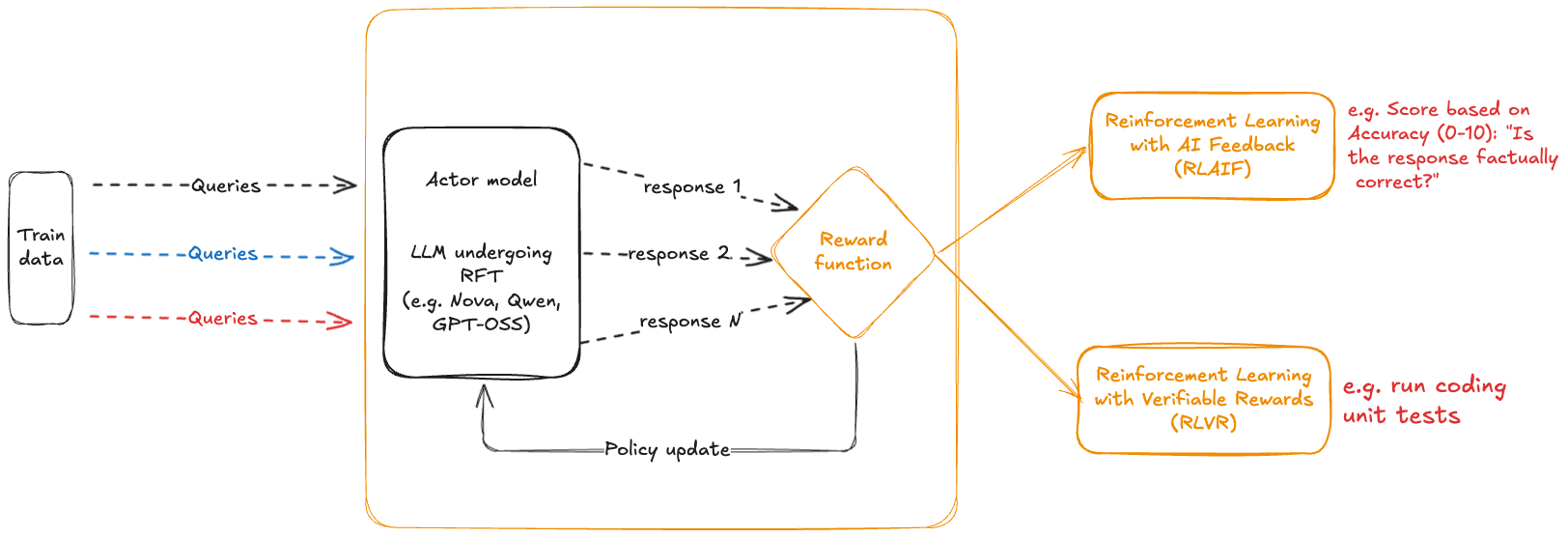
强化学习的核心在于通过对行为提供反馈来引导代理(在此案例中为 LLM)做出更优决策。模型会针对给定的提示生成多个潜在响应,根据响应符合标准的程度获得评分(奖励),并学会倾向于产生高分输出的模式和策略。
RFT 的关键组件
关键组件包括代理(策略)模型、输入状态、输出行为以及奖励函数,如下图所示:
Amazon Bedrock RFT 的工作流程
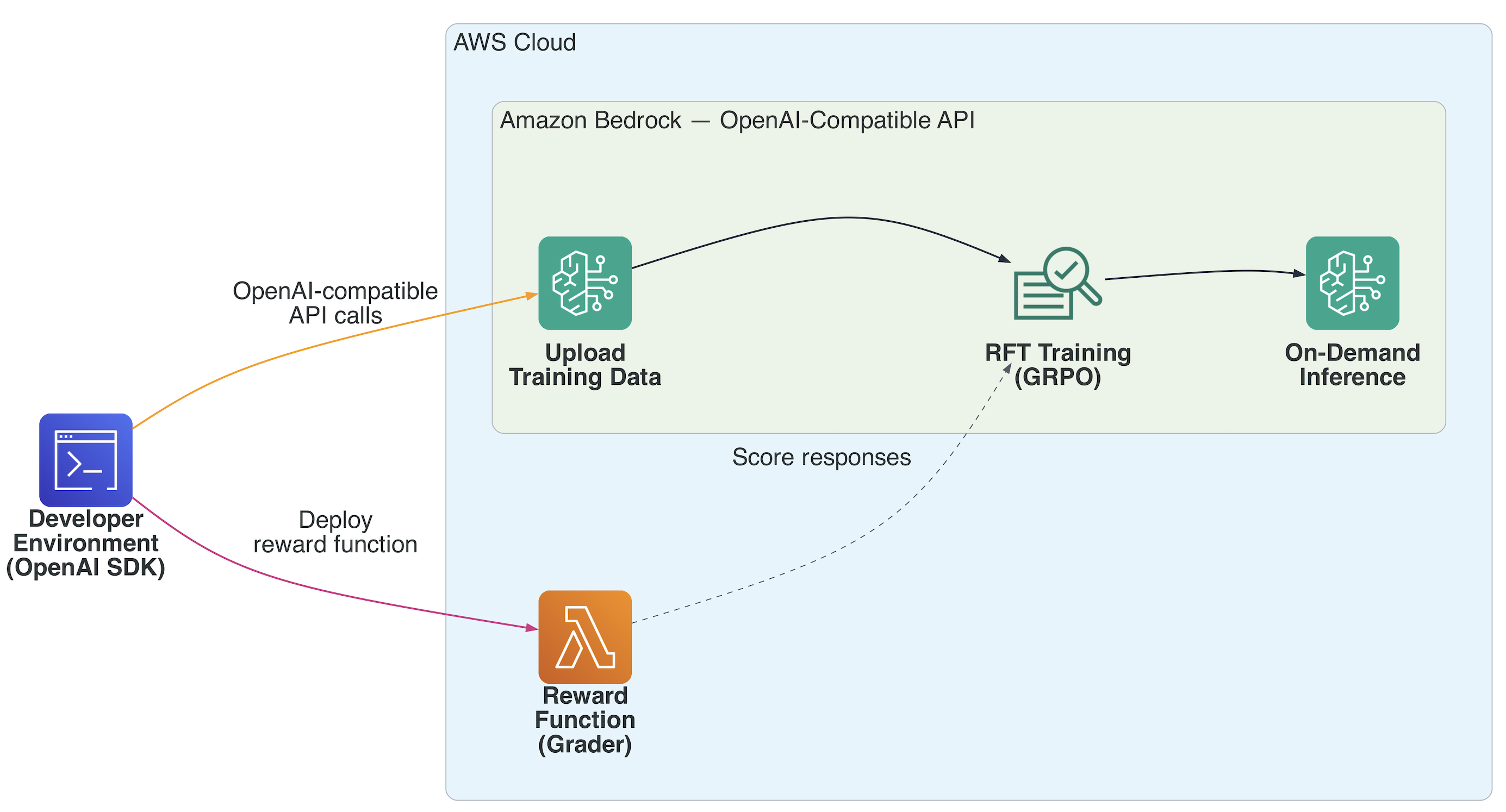
Amazon Bedrock RFT 旨在实现企业级的强化微调实用化。整个 RFT 流水线会自动运行:
- 上传训练数据:通过 Files API 上传 JSONL 格式文件。
- 部署奖励函数:作为 AWS Lambda 函数部署,对模型生成的响应进行评分。
- 创建微调作业:Bedrock 的 GRPO 引擎会生成响应并发送至 Lambda 进行评估。
- 监控训练:通过事件和检查点实时跟踪进度。
- 按需调用:无需预置端点,直接调用已微调的模型。
在此过程中,您的数据不会离开 AWS 的安全环境,也不会被用于训练 Amazon Bedrock 提供的基础模型。
技术实施步骤概要
1. 配置 OpenAI 客户端
将标准的 OpenAI SDK 指向您的 Amazon Bedrock Mantle 端点。通过 aws-bedrock-token-generator 库生成 API 密钥即可轻松完成身份验证。
2. 准备与上传数据
训练数据为 JSONL 格式,必须包含 messages 和可选的 reference_answer(参考答案)。对于 GSM8K 等任务,参考答案可作为奖励函数计算分数的依据。
3. 部署 Lambda 奖励函数
奖励函数是 RFT 的灵魂。它接收模型响应,对比预期的参考答案,并返回 0 到 1 之间的分值。您可以根据用例编写自定义 Python 逻辑。
4. 创建与监控训练
使用标准的 API 调用即可启动作业。在训练过程中,重点关注 critic_rewards_mean(奖励均值,预期应上升)和 actor_entropy(策略熵,应保持平稳而非坍缩)。
5. 按需推理
微调完成后,您可以使用模型 ID 直接调用 client.chat.completions.create() 进行推理,无需任何额外的端点部署开销。
本指南中涉及的完整代码示例及 Jupyter Notebook 已在 GitHub 公开,您可以访问 Amazon Bedrock Samples GitHub 仓库 获取详细参考。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区