



📢 转载信息
原文作者:Xin Huang, Florian Saupe, Jaime Campos Salas, Benjamin Chislett, Max Xu, Faradawn Yang
EAGLE 是目前用于大型语言模型 (LLM) 推理的推测性解码最先进的方法,但其自回归草稿会产生一个隐藏的瓶颈:草稿的 token 越多,草稿器需要进行的顺序前向传播就越多。最终,这些开销会侵蚀掉收益。P-EAGLE 通过一次前向传播生成所有 K 个草稿 token,消除了这个上限,在 NVIDIA B200 上实际工作负载上比原生 EAGLE-3 快 1.69 倍。
您可以通过下载(或训练)一个支持并行的草稿头来获得此性能提升,在 vLLM 服务管道中添加 "parallel_drafting": true。预训练的 P-EAGLE 草稿头已在 HuggingFace 上提供,适用于 GPT-OSS 120B、GPT-OSS 20B 和 Qwen3-Coder 30B,因此您可以立即开始使用。
在本篇文章中,我们将解释 P-EAGLE 的工作原理,以及我们如何从 v0.16.0 (PR#32887) 开始将其集成到 vLLM 中,以及如何使用我们预训练的检查点来服务它。以下是使用的工件列表:
- ArXiv 论文
- HuggingFace 模型 (GPT-OSS 120B, GPT-OSS 20B, Qwen3-Coder-30B-A3B-Instruct)
- vLLM 集成 统一并行草稿
- vLLM-Speculators (RFC, PR)
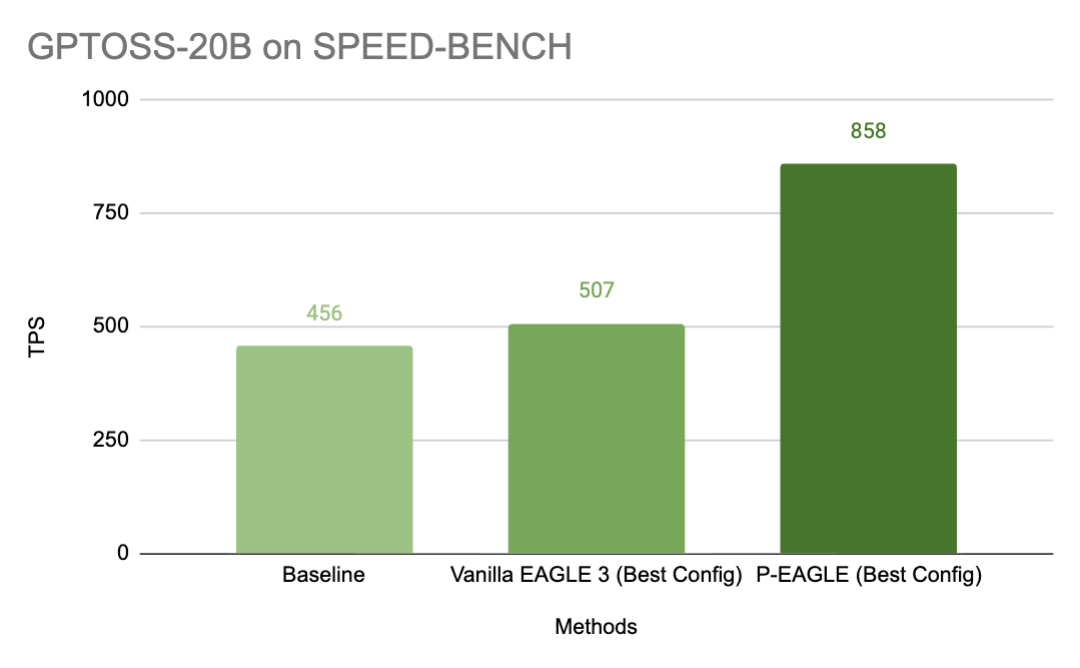
图 1:在 NVIDIA B200 卡上,并发数为 1 时,P-EAGLE 在 SPEED-BENCH 上的表现优于其他方法。
快速启动 P-EAGLE:
您可以通过在 SpeculativeConfig 类中进行一次配置更改来启用并行草稿:
# vllm/config/speculative.py
parallel_drafting: bool = True以下是一个在 vLLM 中使用 P-EAGLE 作为草稿器启用并行草稿的示例命令:
vllm serve openai/gpt-oss-20b \
--speculative-config '{"method": "eagle3", "model": "amazon/gpt-oss-20b-p-eagle", "num_speculative_tokens": 5, "parallel_drafting": true}'EAGLE 的草稿瓶颈
EAGLE 在标准自回归解码的基础上实现了 2-3 倍的速度提升,并且已广泛部署在 vLLM、SGLang 和 TensorRT-LLM 等生产推理框架中。EAGLE 以自回归方式草稿 token。要生成 K 个草稿 token,它需要对草稿模型进行 K 次前向传播。随着草稿模型在草稿长输出方面变得越来越好,这种草稿开销变得越来越显著——草稿器的延迟随着推测深度的增加而线性扩展,限制了我们可以多么积极地进行推测。
我们的方法:并行 EAGLE (P-EAGLE)
我们提出了 P-EAGLE,它将 EAGLE 从自回归生成转变为并行草稿生成。在 B200 GPU 上,P-EAGLE 在 GPT-OSS 20B over MT-Bench、HumanEval 和 SpeedBench 的实际工作负载上,比原生 EAGLE-3 快 1.05-1.69 倍。它现在已集成到 vLLM 中,以实现并行推测性解码,并已准备好加速实际部署。
P-EAGLE 在一次前向传播中生成 K 个草稿 token。图 2 展示了该架构,它由两个步骤组成。
步骤 1:预填充。目标模型处理提示并生成一个新 token,就像在正常推理期间一样。在此过程中,P-EAGLE 捕获模型的内部隐藏状态:每个提示位置的 h_prompt,以及新生成的 token 的 h_context。这些隐藏状态编码了目标模型在每个位置“知道”的内容,并将指导草稿器的预测。此步骤与自回归 EAGLE 相同。
步骤 2:P-EAGLE 草稿器。草稿器并行构建每个位置的输入。每个输入由一个 token embedding 与隐藏状态连接而成。
对于提示位置,输入将每个提示 token embedding emb(p) 与目标模型的相应 h_prompt 配对。遵循自回归 EAGLE 的相同约定,位置向后移动一位。位置 i 接收来自位置 i-1 的 token 和隐藏状态,使其能够预测位置 i 的 token。
对于位置 1(下一个 token 预测,NTP),输入将新生成的 token embedding emb(new) 与 h_context 配对。此位置的操作与标准的自回归 EAGLE 相同。对于位置 2 到 K(多 token 预测,MTP),所需的输入——token embedding 和隐藏状态——尚不存在。P-EAGLE 使用两个可学习参数来填充这些:一个共享的掩码 token embedding emb(mask) 和一个共享的隐藏状态 h_shared。这些是在训练期间学习到的固定向量,用作中性占位符。
位置一起通过 N 个 Transformer 层,然后通过语言模型头,在一次前向传播中预测草稿 token t1、t2、t3 和 t4。
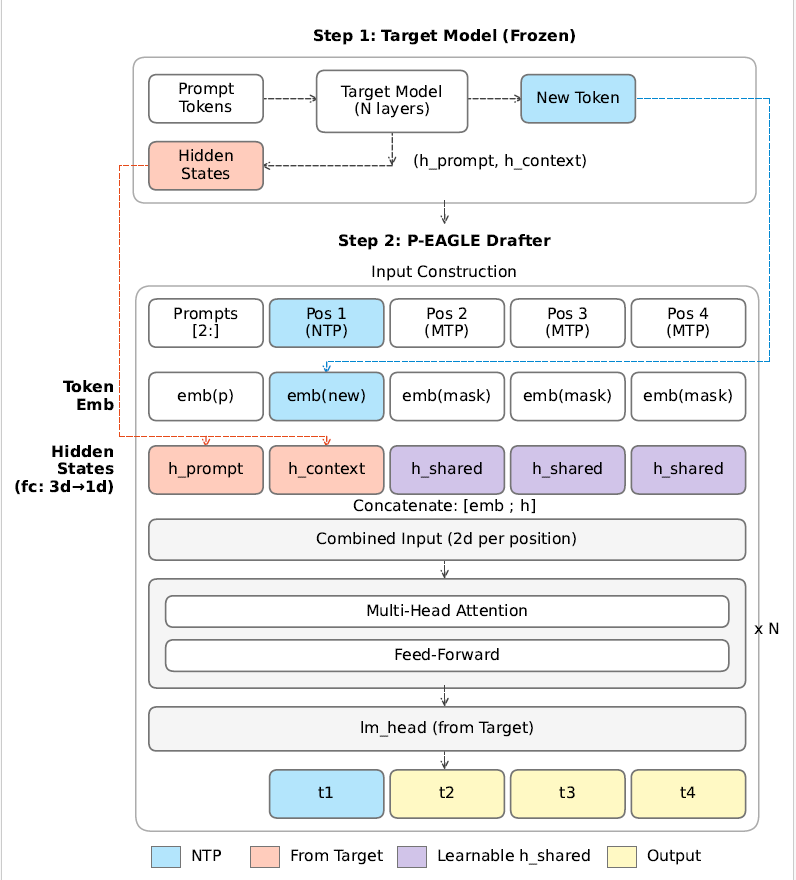
图 2:P-EAGLE 架构概述。
训练 P-EAGLE 处理长序列
现代推理模型会生成长序列。如图 3 所示,在 UltraChat 数据集上,GPT-OSS 120B 生成的序列(包括提示)的中位数长度为 3,891 个 token,P90 为 10,800 个 token。草稿模型必须在匹配的上下文长度上进行训练,才能在推理时有效。
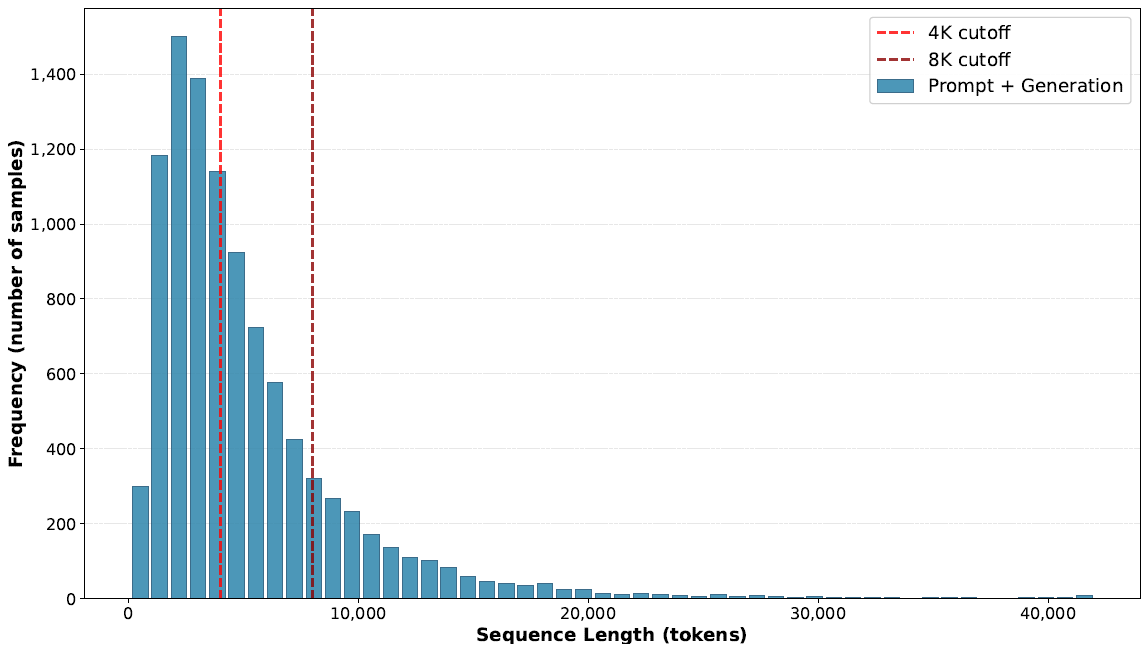
图 3:UltraChat 数据集上 GPT-OSS 120B 的序列长度(提示 + 生成)分布。推理级别:中等。
一个关键的挑战是,并行草稿在训练期间会增加内存需求。在长度为 N 的序列上训练 K 个并行组会产生 N × K 个总位置。当 N = 8,192 且 K = 8 时,单个训练样本包含 65,536 个位置。注意力机制要求每个位置都能关注所有有效位置——65K × 65K 意味着超过 40 亿个元素,在 bf16 格式下占用 8GB 内存。
位置采样 [An et al., 2025] 通过随机跳过位置来减少内存占用,但过度跳过会降低草稿质量。梯度累积是内存受限训练的标准解决方案,但它是在不同的训练样本之间分割的。当单个序列超过内存限制时,就无法进行分割了。
P-EAGLE 引入了一种序列分区算法来进行序列内分割。该算法将 N × K 个位置序列划分为连续的块,在块边界之间保持正确的注意力依赖关系,并跨序列的块累积梯度。有关详细信息,请参阅 P-EAGLE 论文。
在 vLLM 中的实现
并行草稿的挑战
在许多推测性解码设置中,草稿和验证共享相同的每个请求 token 布局。这在 EAGLE 中基本成立:草稿器消耗一个窗口,该窗口与验证器将要检查的内容相匹配;K 个草稿 token 和一个额外的采样 token。
并行草稿打破了这种一致性。为了在一次草稿器前向传播中预测 K 个 token,我们附加了 MASK 占位符(例如,[token, MASK, MASK, …])。这些额外的 L 位置仅用于草稿,因此草稿批次的形状不再与验证批次的形状匹配。由于我们无法重用验证元数据,因此必须重建批次元数据。我们扩展输入 token ID、隐藏状态和位置以插入掩码 token/embedding 的槽,按请求增加位置,然后根据更新的位置重新计算槽映射和每个请求的起始索引。
Triton 内核
为了抵消重建批次元数据的开销,我们实现了一个融合的 Triton 内核,通过复制和扩展目标模型批次来填充 GPU 上的草稿器输入批次。在一次传递中,内核将前一个 token ID 和位置从目标批次复制到新的目标槽中,并插入目标模型采样的每个请求的奖励 token。然后,它用特殊的 MASK token ID 填充额外的并行草稿槽。最后,它生成轻量级的元数据:一个被拒绝的 token 掩码,一个用于并行草稿槽的掩码 token 掩码,用于采样草稿 token 的新 token 索引,以及一个隐藏状态映射。
这个逻辑否则将需要许多 GPU 操作(复制/散布 + 插入 + 填充 + 掩码 + 重映射)。将其融合到一个内核中可以减少启动开销和额外的内存流量,从而使草稿设置成本较低。
隐藏状态管理
对于将隐藏状态传递给草稿模型的 EAGLE 类方法,并行草稿分别处理这些字段的填充。由于隐藏状态比输入批次的其余部分大得多,因此我们将工作分开:Triton 内核输出一个映射,一个专用的复制内核将学习到的隐藏状态占位符广播到掩码 token 槽中。
# 将目标隐藏状态复制到其新位置
self.hidden_states[out_hidden_state_mapping] = target_hidden_states
# 使用学习到的并行草稿隐藏状态填充掩码位置
mask = self.is_masked_token_mask[:total_num_output_tokens]
torch.where(
mask.unsqueeze(1),
self.parallel_drafting_hidden_state_tensor,
self.hidden_states[:total_num_output_tokens],
out=self.hidden_states[:total_num_output_tokens],
)
parallel_drafting_hidden_state_tensor 从模型的 mask_hidden 缓冲区加载,这是一个学习到的表示,它告诉模型这些位置应该预测未来的 token。
对于 KV 缓存槽映射,有效 token 获得正常的槽分配,而被拒绝的 token 被映射到 PADDING_SLOT_ID (-1) 以防止错误的缓存写入。对于 CUDA 图,我们将捕获范围扩展 K × max_num_seqs 以容纳并行草稿引入的更大的草稿批次。
vLLM P-EAGLE 基准测试
我们在 GPT-OSS-20B 上训练了 P-EAGLE,并在三个基准上进行了评估:用于多轮指令遵循的 MT-Bench,用于长期代码生成的 SPEED-Bench Code,以及用于函数级代码合成的 HumanEval。与公开可用的原生 EAGLE-3 检查点 相比,P-EAGLE 在低并发(c=1)下实现了 55-69% 的更高吞吐量,在高并发(c=64)下也保持了 5-25% 的增益。结果如图 4-6 所示。
P-EAGLE 草稿器是一个轻量级的 4 层模型,用于预测最多 10 个 token 的并行。为了评估性能,我们在并发级别 C ∈ {1,2,4,8,16,32,64} 上进行了 K ∈ {3,5,7} 的推测深度扫描。我们的目标是确定 P-EAGLE 和原生 EAGLE-3 的最佳部署配置。对于 P-EAGLE 和原生 EAGLE-3,均使用线性草稿。在此上下文中,“最佳 P-EAGLE”和“最佳 EAGLE-3”指的是实现峰值吞吐量的配置。这些配置以每秒 token (TPS) 为单位进行测量,并考虑了给定的推测深度 K。对于每种方法,我们选择 K 来最大化给定服务条件下的 TPS。
一个一致的模式出现了。P-EAGLE 在所有并发级别下,在 K=7 时达到峰值 TPS。相比之下,原生 EAGLE-3 在 K=3 时达到最高 TPS,其改进的深度有时会根据并发情况转向更高的值。这种行为反映了并行草稿的一个基本优势。P-EAGLE 在一次前向传播中生成所有 K 个草稿 token,这使得它能够从更深的推测中获益,而无需承担额外的顺序开销。相比之下,自回归草稿器必须逐步生成推测 token,这限制了它们有效扩展到更大 K 的能力。
所有实验都在一个 NVIDIA B200 (Blackwell) GPU 上使用 vLLM 进行,并采用以下服务配置。
VLLM_USE_FLASHINFER_MOE_MXFP4_MXFP8=1 \
vllm serve openai/gpt-oss-20b \
--speculative-config '{ "method": "eagle3", "model": "amazon/GPT-OSS-20B-P-EAGLE", "num_speculative_tokens": 7, "parallel_drafting": true}' \
--port 8000 \
--max-num-seqs 1024 \
--max-model-len 100000 \
--max-num-batched-tokens 100000 \
--max-cudagraph-capture-size 4096 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--kv-cache-dtype fp8 \
--async-scheduling \
--stream-interval 20注意。使用 EAGLE 草稿器服务 GPT-OSS-20B 目前需要一个单行 vLLM 补丁 (PR#36684)。在启动之前应用它。此修复预计将在即将发布的 vLLM 版本中发布。
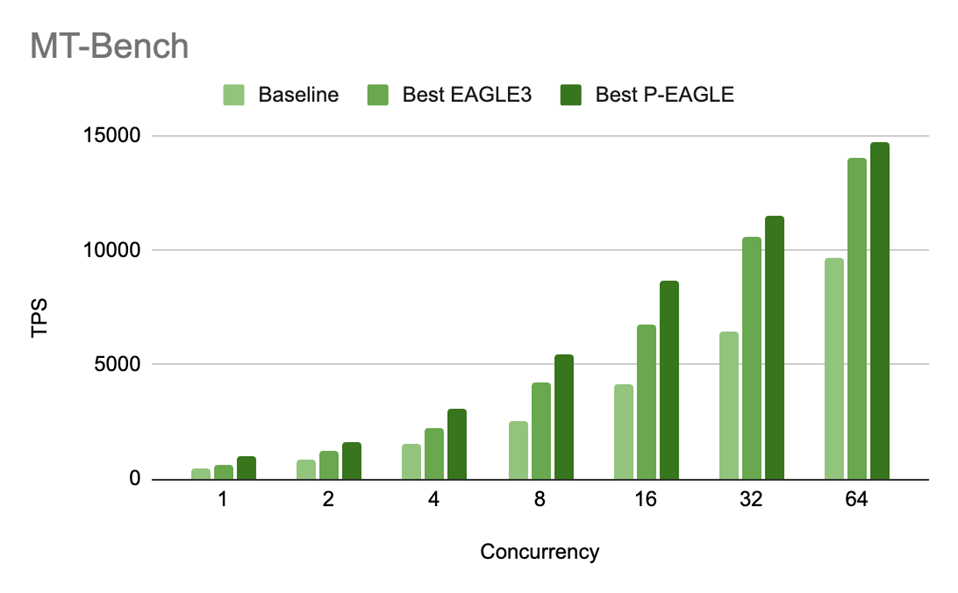
图 4:MT-Bench 在 GPT-OSS-20B 上,P-EAGLE vs EAGLE-3 的吞吐量 (TPS) 随并发级别的变化。P/E 加速比为:1.55 倍 (c=1),1.29 倍 (c=2),1.35 倍 (c=4),1.28 倍 (c=8),1.27 倍 (c=16),1.09 倍 (c=32),和 1.05 倍 (c=64)。
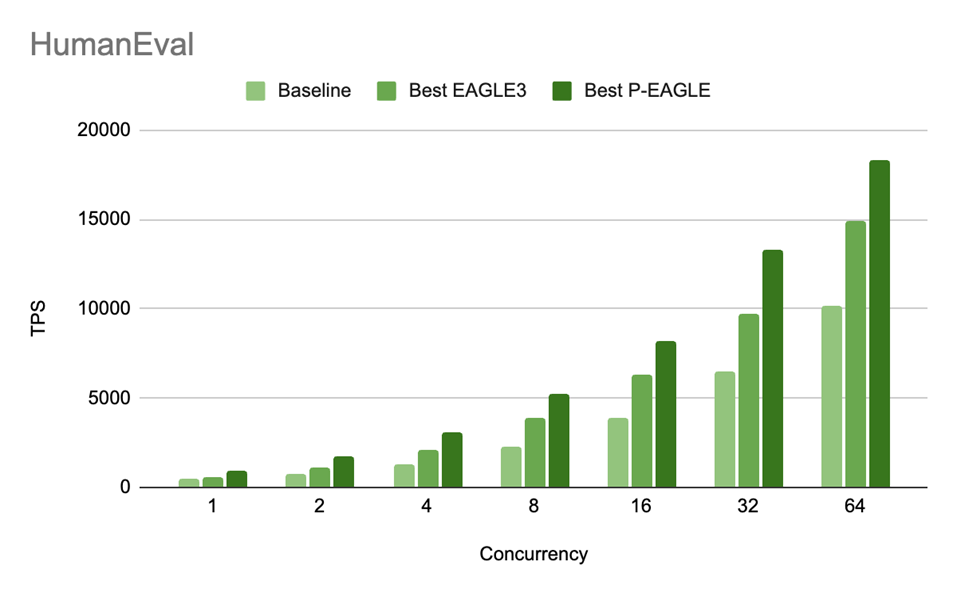
图 5:HumanEval 在 GPT-OSS-20B 上,P-EAGLE vs EAGLE-3 的吞吐量 (TPS) 随并发级别的变化。P/E 加速比为:1.55 倍 (c=1),1.53 倍 (c=2),1.45 倍 (c=4),1.35 倍 (c=8),1.31 倍 (c=16),1.37 倍 (c=32),和 1.23 倍 (c=64)。
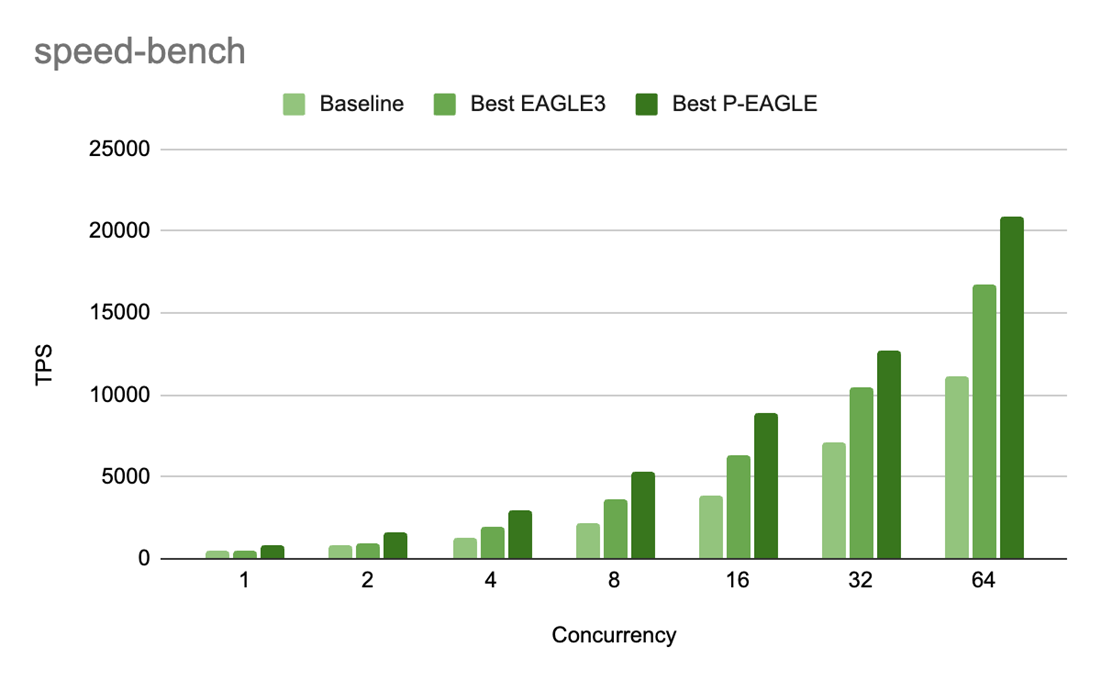
图 6:Speed-bench 在 GPT-OSS-20B 上,P-EAGLE vs EAGLE-3 的吞吐量 (TPS) 随并发级别的变化。P/E 加速比为:1.69 倍 (c=1),1.61 倍 (c=2),1.54 倍 (c=4),1.45 倍 (c=8),1.40 倍 (c=16),1.22 倍 (c=32),和 1.25 倍 (c=64)。
除了降低草稿开销外,P-EAGLE 的吞吐量提升还来自于更好的接受长度 (AL),即验证器在每次推测轮次中接受的平均草稿 token 数。更高的 AL 意味着更多的草稿工作转化为实际输出,这直接提高了有效 OTPS/TPS。
下表比较了 P-EAGLE 和原生 EAGLE-3 在 GPT-OSS-20B 上三个基准的 AL:
P-EAGLE (AL):
| 配置 | HumanEval | SPEED-Bench | MT-Bench |
| K=3 | 3.02 | 2.87 | 2.87 |
| K=7 | 3.94 | 3.38 | 3.70 |
EAGLE-3 (AL):
| 配置 | HumanEval | SPEED-Bench | MT-Bench |
| K=3 | 2.65 | 2.24 | 2.70 |
| K=7 | 3.03 | 2.59 | 3.27 |
在相同的推测深度 K 下,P-EAGLE 始终比 EAGLE-3 获得更高的 AL。在 K=7 时,P-EAGLE 在 HumanEval 上(3.94 vs 3.03)比 EAGLE-3 高出 30%,在 SPEED-Bench 上(3.38 vs 2.59)高出 31%,在 MT-Bench 上(3.70 vs 3.27)高出 13%。值得注意的是,P-EAGLE 从更深的推测中受益更多。从 K=3 到 K=7,P-EAGLE 的 AL 在 HumanEval 上增加了 0.92 (3.02 到 3.94),而 EAGLE-3 仅增加了 0.38 (2.65 到 3.03)。这种在较高 K 值下差距的扩大与 P-EAGLE 的单次前向并行草稿一致,后者不会产生额外的深度推测成本。
复现结果
启动服务器后,使用 `vllm bench serve` 运行基准测试:
# MT-Bench
export MODEL="openai/gpt-oss-20b"
export BASE_URL="http://localhost:8000"
vllm bench serve \
--dataset-name hf \
--dataset-path philschmid/mt-bench \
--num-prompts 80 \
--max-concurrency 1 \
--model $MODEL \
--base-url $BASE_URL \
--temperature 0.0 \
--hf-output-len 2048
# HumanEval
# command:
# Download HumanEval dataset openai/openai_humaneval
vllm bench serve \
--dataset-name custom \
--dataset-path <dataset path> \
--num-prompts 164 \
--max-concurrency 1 \
--model $MODEL \
--base-url $BASE_URL \
--temperature 0.0 \
--custom-output-len 2048
结论
P-EAGLE 消除了推测性解码中的顺序瓶颈,在实际工作负载上比原生 EAGLE-3 的速度提升高达 1.69 倍。通过将草稿数量与前向传播数量解耦,我们现在可以探索更大的草稿架构,这甚至可以带来比单层基线更高的接受率。此实现通过手工编写的融合内核,仔细处理了输入准备、注意力元数据管理和 KV 缓存槽映射的复杂性。虽然它需要专门训练的模型,但其性能优势使其成为 vLLM 推测性解码能力的宝贵补充。
随着更多并行训练模型的可用,我们预计这种方法将成为生产 LLM 部署的首选。P-EAGLE 的架构效率和 vLLM 的强大基础设施相结合,为寻求最大推理性能和降低延迟的用户提供了一条清晰的路径。
立即尝试:从 HuggingFace 下载预训练的 P-EAGLE 草稿头,在 vLLM 配置中为任何受支持的模型设置 "parallel_drafting": true,亲身体验性能提升。
致谢
我们要感谢 Nvidia 的贡献者和合作者:Xin Li、Kaihang Jiang、Omri Almog,以及我们的团队成员:Ashish Khetan 和 George Karypis。
关于作者
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区