



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/07/01/peva/
原文作者:BAIR Blog

Predicting Ego-centric Video from human Actions (PEVA):给定过去的视频帧和指定3D姿态变化的动作,PEVA能够预测下一帧视频。结果表明,在初始帧和一系列动作序列的引导下,我们的模型可以生成原子动作视频、模拟反事实场景,并支持长视频生成。
近年来,世界模型在规划和控制领域取得了显著进展,从直观物理模拟到多步视频预测,模型能力愈发强大。然而,专门为具身智能体设计的研究尚属少数。要创造真正面向具身智能的世界模型,我们需要一个在真实世界中行动的真实载体。这些载体应具备物理接地(Physically Grounded)的复杂动作空间,而非抽象的控制信号,并能在多样的现实场景中处理第一人称视角(Egocentric View)。

为什么这很难?
- 动作与视觉高度依赖上下文:相同的视角可能产生不同的运动,反之亦然,这是因为人类是在复杂、具身、目标导向的环境中行动的。
- 人体控制是高维且结构化的:全身运动包含超过48个自由度,具有层级化、依赖时间的动态特性。
- 第一人称视角揭示意图但隐藏身体:第一人称视觉反映了目标而非动作执行过程,模型必须从不可见的物理动作中推断后果。
- 感知滞后于动作:视觉反馈往往在动作发生后数秒才出现,这要求模型具备长程预测和时间推理能力。
人类的行为通常是“先看后动”——眼睛锁定目标,大脑进行简短的视觉“模拟”,身体随之移动。在每一个瞬间,我们的第一人称视角既是环境输入,也反映了后续移动背后的意图。当我们考虑身体运动时,应兼顾脚部(移动与导航)和手部(操作),即全身控制。
我们做了什么?

我们训练了一个模型,通过人体动作预测第一人称视频(PEVA),实现全身条件下的第一人称视频预测。PEVA基于人体关节层级结构化的运动姿态轨迹进行条件控制,学习模拟物理人类动作如何从第一人称视角塑造环境。我们在大规模真实世界第一人称视频与全身动作捕捉数据集 Nymeria 上训练了一个自回归条件扩散Transformer。通过层级评估协议,该工作展示了在复杂现实环境和具身行为建模方面的初步尝试。
方法论
基于运动的结构化动作表示
为了架起人类运动与第一人称视觉之间的桥梁,我们将每个动作表示为一个捕捉全身动态和关节细节的高维向量。我们使用基于人体运动学树的全局平移和相对关节旋转,构建了一个48维的动作空间(3自由度根节点平移 + 15个上半身关节 × 3个欧拉角)。所有数据经归一化以确保学习的稳定性,使模型能够将物理移动与视觉后果联系起来。
PEVA架构:自回归条件扩散Transformer
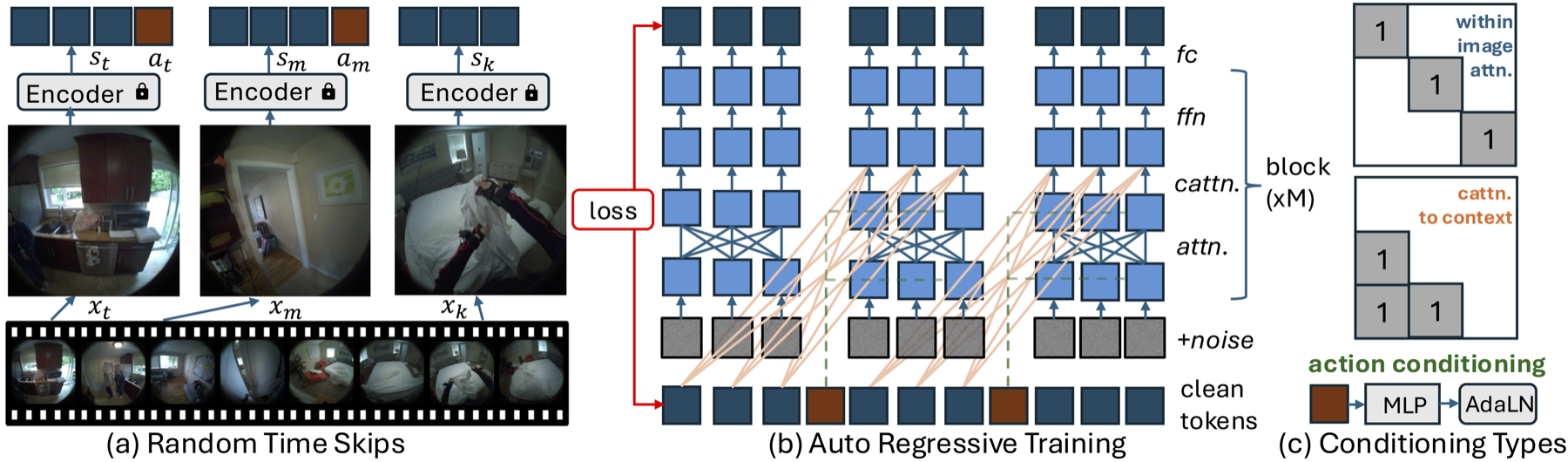
针对人体高维、时延长的特点,我们对现有的条件扩散Transformer(CDiT)进行了三项扩展:
- 随机跳帧(Random Timeskips):使模型既能学习短期运动动态,也能掌握长期活动模式。
- 序列级训练(Sequence-Level Training):通过对每个帧前缀应用损失,建模完整的运动序列。
- 动作嵌入(Action Embeddings):将时间t的所有动作拼接为1D张量,以条件化每个AdaLN层。
在推理阶段,我们采用自回归滚动策略。从上下文帧开始,模型预测下一帧并将其添加到上下文,同时丢弃最旧的帧,逐步解码为像素空间。
原子动作与长程演进
我们将复杂动作拆解为原子动作(如手部移动、全身位移),以测试模型对关节级运动如何影响视野的理解。同时,模型展现了在长达16秒的生成周期内维持视觉和语义一致性的卓越能力。
未来展望
PEVA在基于人体动作预测第一人称视频方面取得了有希望的结果,但目前仍处于具身规划的早期阶段。未来的工作将重点关注:扩展至闭环控制、引入明确的任务意图条件控制,以及将PEVA与对象中心化表示相结合。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区