



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2025/07/01/peva/
原文作者:BAIR Blog

Predicting Ego-centric Video from human Actions (PEVA)。给定过去的视频帧和指定3D姿态变化的动作,PEVA能够预测下一帧视频。结果显示,通过初始帧和一系列动作序列,该模型可以生成原子动作视频、模拟反事实场景并支持长视频生成。
近年来,能够模拟未来结果以进行规划和控制的世界模型取得了显著进展。从直观物理到多步视频预测,这些模型的功能越来越强大。但很少有模型专为真正的具身智能体设计。为了创建具身智能体的世界模型,我们需要一个在现实世界中行动的真实具身智能体。与抽象控制信号不同,真实的具身智能体拥有复杂的物理基础动作空间。它们必须在多样的现实场景中行动,并具备第一人称视角(Egocentric view),而非美观的固定相机场景。

为什么实现起来很难?
- 动作与视觉高度依赖上下文。 相同的视角可能导致不同的移动,反之亦然。这是因为人类在复杂的、具体的、以目标为导向的环境中行动。
- 人类控制是高维且结构化的。 全身运动跨越48个以上的自由度,并具有分层、依赖时间的动态特性。
- 第一人称视角揭示了意图但隐藏了身体。 第一人称视觉反映了目标,但没有反映运动执行,模型必须从不可见的物理动作中推断后果。
- 感知滞后于动作。 视觉反馈通常会延迟几秒,这要求长期的预测和时间推理。
我们做了什么?

我们训练了一个名为 PEVA 的模型,用于基于人类动作预测第一人称视频(Whole-Body-Conditioned Egocentric Video Prediction)。PEVA根据由身体关节层级结构组成的运动学姿态轨迹进行条件化,学习模拟人类物理动作如何从第一人称视角塑造环境。我们在 Nymeria 数据集上训练了一个自回归条件扩散Transformer,该数据集配对了现实世界的第一人称视频与身体姿态捕捉数据。
方法论
基于运动的结构化动作表示
为了连接人类运动和第一人称视觉,我们将每个动作表示为一个丰富的、高维向量,捕捉全身动态和详细的关节运动。我们使用3个自由度的根节点平移和15个上身关节来编码运动,形成48维动作空间(3 + 15 × 3 = 48)。
PEVA设计:自回归条件扩散Transformer
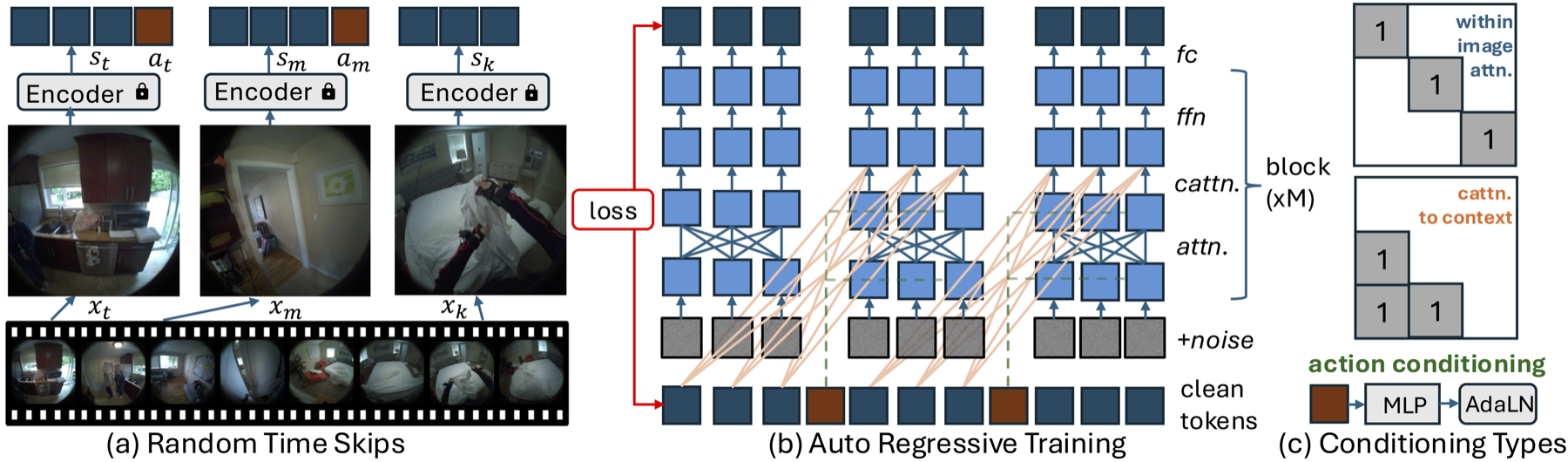
为了处理高维、时间延长且受物理约束的人类动作,我们对CDiT方法进行了三项改进:随机跳帧(Random Timeskips)、序列级训练(Sequence-Level Training)以及动作嵌入(Action Embeddings)。
规划能力
PEVA可以通过模拟多个候选动作并根据感知相似度(LPIPS)对目标进行打分来执行规划。它能有效排除导致错误路径的动作(如碰到水槽或走到室外),从而找到通往目标的正确路径。

未来方向
虽然PEVA在基于全身运动预测第一人称视频方面取得了进展,但这只是迈向具身规划的早期一步。目前的规划局限于模拟候选手臂动作,且缺乏长期的轨迹优化。将PEVA扩展到闭环控制或交互式环境是下一步的关键。未来的工作可以探索将PEVA与高级目标条件及以对象为中心的表示相结合。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区