



📢 转载信息
原文链接:https://www.kdnuggets.com/collecting-real-time-data-with-apis-a-hands-on-guide-using-python
原文作者:Josep Ferrer

Image by Author
# 引言
收集高质量、相关信息的能力仍然是任何数据专业人员的核心技能。虽然收集数据的方法有很多,但其中最强大和最可靠的方法之一是通过API(应用程序编程接口)。它们充当桥梁,使不同的软件系统能够无缝地通信和共享数据。
在本文中,我们将分解使用API进行数据收集的基本要素——它们为何重要、如何工作,以及如何在Python中开始使用它们。
# 什么是API?
API(应用程序编程接口)是一组规则和协议,允许不同的软件系统有效地通信和交换数据。
把它想象成在餐馆用餐。你不需要直接和厨师说话,而是向服务员下订单。服务员会检查所需原料是否可用,将请求传达给厨房,并在菜品准备好后将餐点送回来。
API的工作方式相同:它接收你对特定数据的请求,检查该数据是否存在,如果可用,则将其返回——充当你和数据源之间的信使。
在使用API时,交互通常涉及以下组件:
- Client:发送请求以访问数据或功能的应用或系统
- Request:客户端向服务器发送结构化请求,指定所需数据
- Server:处理请求并提供所需数据或执行操作的系统
- Response:服务器处理请求并以结构化格式(通常是JSON或XML)返回数据或结果
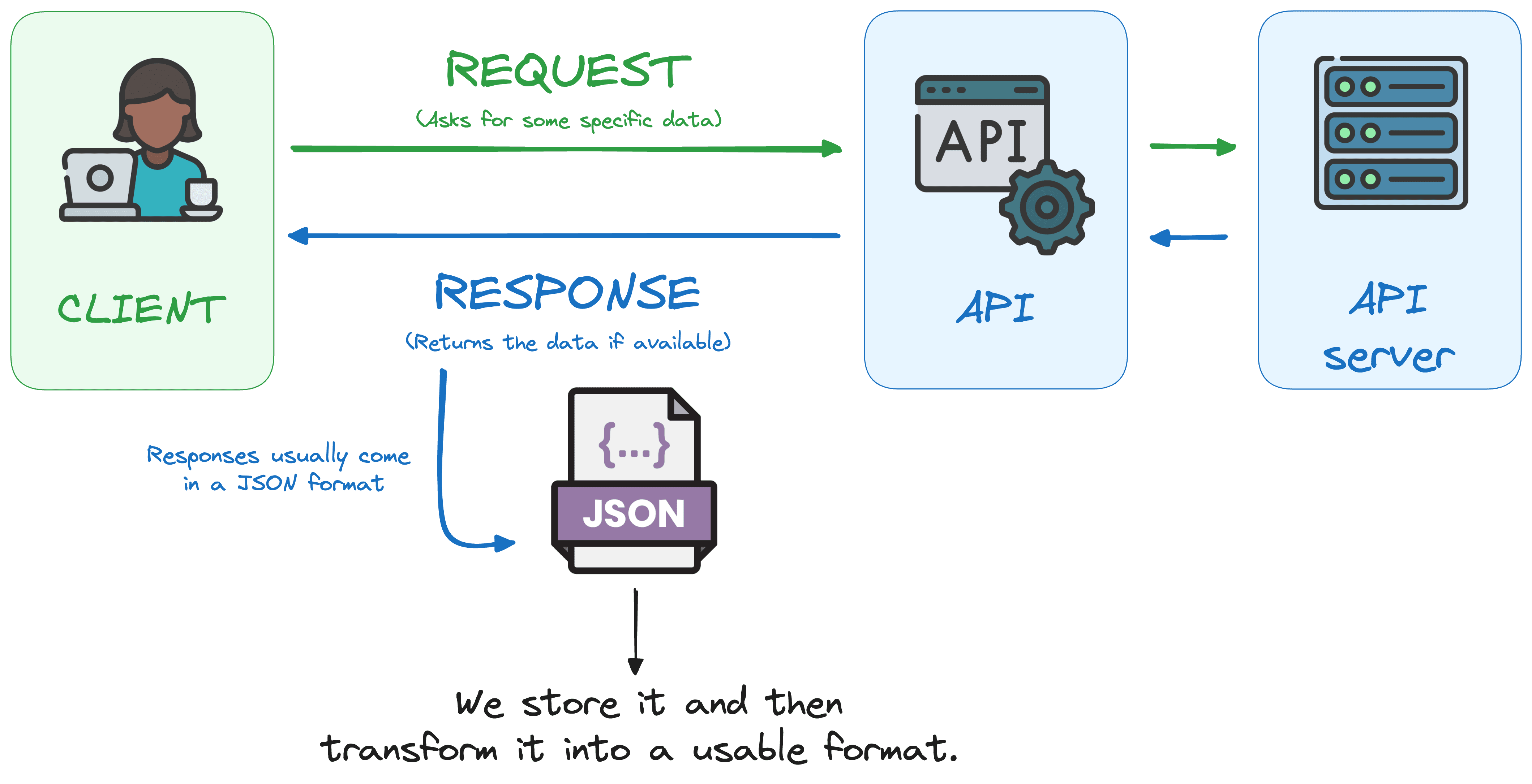
Image by Author
这种通信允许应用程序高效地共享信息或功能,从而实现获取数据库数据或与第三方服务交互等任务。
# 为什么要使用API进行数据收集?
API为数据收集提供了多项优势:
- Efficiency:它们提供对数据的直接访问,无需手动收集数据
- Real-time Access:API通常提供最新信息,这对于时间敏感的分析至关重要
- Automation:它们支持自动化的数据检索过程,减少人为干预和潜在错误
- Scalability:API可以处理大量请求,使其适用于广泛的数据收集任务
# 在Python中实现API调用
在Python中进行基本的API调用是开始数据收集最简单、最实用的练习之一。流行的requests库使发送HTTP请求和处理响应变得非常简单。
为了演示其工作原理,我们将使用Random User Generator API,这是一个提供JSON格式虚拟用户数据的免费服务,非常适合测试和学习。
以下是进行首次API调用的分步指南。
// 安装 Requests 库:
pip install requests
// 导入所需的库:
import requests import pandas as pd
// 查看文档页面:
在发出任何请求之前,了解API的工作原理非常重要。这包括审查可用的endpoints(端点)、参数和响应结构。首先访问Random User API 文档。
// 定义 API 端点和参数:
根据文档,我们可以构建一个简单的请求。在此示例中,我们获取仅限于美国用户的数据:
url = 'https://randomuser.me/api/' params = {'nat': 'us'}
// 发出 GET 请求:
使用带有 URL 和参数的 requests.get() 函数:
response = requests.get(url, params=params)
// 处理响应:
检查请求是否成功,然后处理数据:
if response.status_code == 200: data = response.json() # 根据需要处理数据 else: print(f"Error: {response.status_code}")
// 将数据转换为数据框:
为了方便处理数据,我们可以将其转换为 pandas DataFrame:
data = response.json() df = pd.json_normalize(data["results"]) df
现在,让我们用一个真实的案例来举例说明。
# 使用 Eurostat API
Eurostat是欧盟的统计局。它提供关于经济、人口、环境、工业和旅游等广泛主题的高质量、统一的统计数据——涵盖所有欧盟成员国。
通过其API,Eurostat以机器可读的格式提供对大量数据集的公共访问,使其成为对欧洲层面数据分析感兴趣的数据专业人员、研究人员和开发人员的宝贵资源。
// 步骤 0:了解 API 中的数据:
如果您查看Eurostat的数据部分,会发现一个导航树。我们可以尝试在以下子部分中识别一些感兴趣的数据:
- Detailed Datasets:多维格式的完整Eurostat数据
- Selected Datasets:包含较少指标的简化数据集,维度为2-3个
- EU Policies:按特定欧盟政策领域分组的数据
- Cross-cutting:从多个来源汇编的主题数据
// 步骤 1:查看文档:
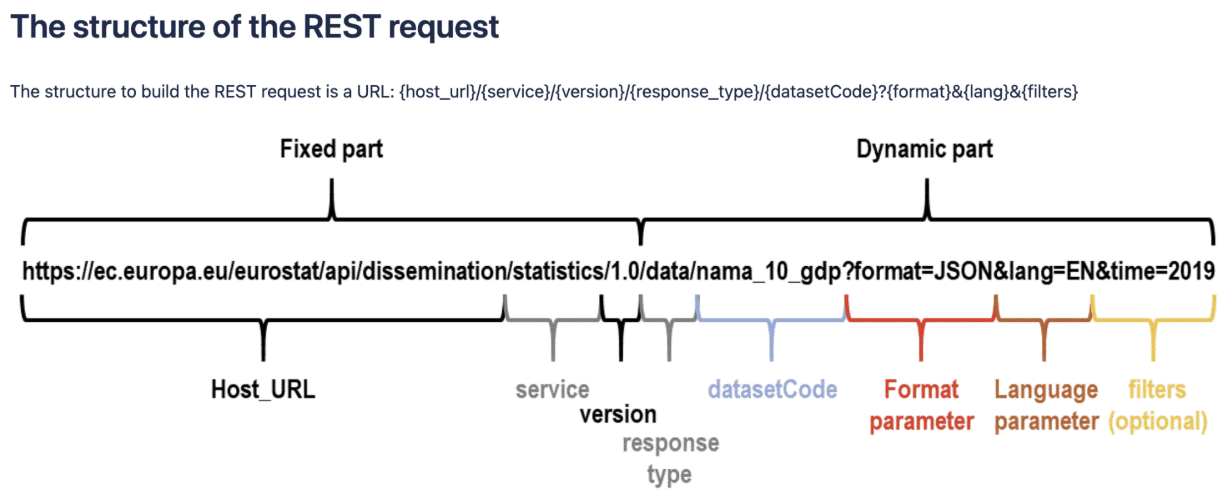
始终从文档开始。您可以在此处找到Eurostat的API指南。它解释了API结构、可用端点以及如何形成有效的请求。
// 步骤 2:生成第一个调用请求:
要使用Python生成API请求,第一步是安装并导入requests库。请记住,我们在前面的简单示例中已经安装了它。然后,我们可以使用Eurostat文档中的一个演示数据集轻松生成调用请求。
# 我们导入 requests 库 import requests # 定义 URL 端点 -> 我们使用 EUROSTATS API 文档中的演示 URL。 url = "https://ec.europa.eu/eurostat/api/dissemination/statistics/1.0/data/DEMO_R_D3DENS?lang=EN" # 发出 GET 请求 response = requests.get(url) # 打印状态码和响应数据 print(f"Status Code: {response.status_code}") print(response.json()) # 打印 JSON 响应
专业提示:我们可以将URL拆分为基础URL和参数,以便于理解我们正在向API请求什么数据。
# 我们导入 requests 库 import requests # 定义 URL 端点 -> 我们使用 EUROSTATS API 文档中的演示 URL。 url = "https://ec.europa.eu/eurostat/api/dissemination/statistics/1.0/data/DEMO_R_D3DENS" # 定义要添加到 URL 中的参数。 params = { 'lang': 'EN' # 指定语言为英语 } # 发出 GET 请求 response = requests.get(url, params=params) # 打印状态码和响应数据 print(f"Status Code: {response.status_code}") print(response.json()) # 打印 JSON 响应
// 步骤 3:确定要调用的数据集:
您可以从Eurostat数据库中选择任何数据集,而不是使用演示数据集。例如,让我们查询数据集 TOUR_OCC_ARN2,其中包含旅游住宿数据。
# 我们导入 requests 库 import requests # 定义 URL 端点 -> 我们使用 EUROSTATS API 文档中的演示 URL。 base_url = "https://ec.europa.eu/eurostat/api/dissemination/statistics/1.0/data/" dataset = "TOUR_OCC_ARN2" url = base_url + dataset # 定义要添加到 URL 中的参数。 params = { 'lang': 'EN' # 指定语言为英语 } # 发出 GET 请求 -> 我们生成请求并获取响应 response = requests.get(url, params=params) # 打印状态码和响应数据 print(f"Status Code: {response.status_code}") print(response.json()) # 打印 JSON 响应
// 步骤 4:理解响应
Eurostat的API以JSON-stat格式返回数据,这是一种多维统计数据的标准。您可以将响应保存到文件中并探索其结构:
import requests import json # 定义 URL 端点和数据集 base_url = "https://ec.europa.eu/eurostat/api/dissemination/statistics/1.0/data/" dataset = "TOUR_OCC_ARN2" url = base_url + dataset # 定义要添加到 URL 中的参数 params = { 'lang': 'EN', "time": 2019 # 指定语言为英语 } # 发出 GET 请求并获取响应 response = requests.get(url, params=params) # 检查状态码并处理响应 if response.status_code == 200: # 解析 JSON 响应 data = response.json() # 生成一个 JSON 文件并将响应数据写入其中 with open("eurostat_response.json", "w") as json_file: json.dump(data, json_file, indent=4) # 保存 JSON 并美化格式 print("JSON file 'eurostat_response.json' has been successfully created.") else: print(f"Error: Received status code {response.status_code} from the API.")
// 步骤 5:将响应转换为可用数据:
现在我们获取了数据,我们可以找到一种方法将其保存为表格格式(CSV),以简化分析过程。
import requests import pandas as pd # 步骤 1:向 Eurostat API 发出 GET 请求 base_url = "https://ec.europa.eu/eurostat/api/dissemination/statistics/1.0/data/" dataset = "TOUR_OCC_ARN2" # 旅游住宿统计数据集 url = base_url + dataset params = {'lang': 'EN'} # 请求英文数据 # 发出 API 请求并获取响应 response = requests.get(url, params=params) # 步骤 2:检查请求是否成功 if response.status_code == 200: data = response.json() # 步骤 3:提取维度和元数据 dimensions = data['dimension'] dimension_order = data['id'] # ['geo', 'time', 'unit', 'indic', etc.] # 动态提取每个维度的标签 dimension_labels = {dim: dimensions[dim]['category']['label'] for dim in dimension_order} # 步骤 4:确定每个维度的尺寸 dimension_sizes = {dim: len(dimensions[dim]['category']['index']) for dim in dimension_order} # 步骤 5:创建每个索引到其相应标签的映射 # 例如,如果我们有 'geo', 'time', 'unit', 和 'indic',将每个索引映射到正确的标签 index_labels = { dim: list(dimension_labels[dim].keys()) for dim in dimension_order } # 步骤 6:创建 CSV 的行列表 rows = [] for key, value in data['value'].items(): # `key` 是一个像 '123' 的字符串,我们需要将其分解为相应的标签 index = int(key) # 将字符串索引转换为整数 # 计算每个维度的索引 indices = {} for dim in reversed(dimension_order): dim_index = index % dimension_sizes[dim] indices[dim] = index_labels[dim][dim_index] index //= dimension_sizes[dim] # 从所有维度构建带有标签的行 row = {f"{dim.capitalize()} Code": indices[dim] for dim in dimension_order} row.update({f"{dim.capitalize()} Name": dimension_labels[dim][indices[dim]] for dim in dimension_order}) row["Value (Tourist Accommodations)"] = value rows.append(row) # 步骤 7:创建 DataFrame 并保存为 CSV if rows: df = pd.DataFrame(rows) csv_filename = "eurostat_tourist_accommodation.csv" df.to_csv(csv_filename, index=False) print(f"CSV file '{csv_filename}' has been successfully created.") else: print("No valid data to save as CSV.") else: print(f"Error: Received status code {response.status_code} from the API.")
// 步骤 6:生成特定视图
假设我们只想保留对应于露营地、公寓或酒店的记录。我们可以生成一个包含此条件的最终表格,并获得一个可以处理的pandas DataFrame。
# 检查 'Nace_r2 Name' 列中的唯一值 set(df["Nace_r2 Name"]) # 要过滤的选项列表 options = ['Camping grounds, recreational vehicle parks and trailer parks', 'Holiday and other short-stay accommodation', 'Hotels and similar accommodation'] # 根据 'Nace_r2 Name' 列的值过滤 DataFrame df = df[df["Nace_r2 Name"].isin(options)] df
# 使用API的最佳实践
- Read the Docs:始终查阅官方API文档,以了解端点和参数
- Handle Errors:使用条件语句和日志记录来优雅地处理失败的请求
- Respect Rate Limits:避免使服务器不堪重负——检查速率限制是否适用
- Secure Credentials:如果API需要身份验证,切勿在公共代码中暴露API密钥
# 总结
Eurostat的API是通往大量结构化、高质量欧洲统计数据的强大门户。通过学习如何导航其结构、查询数据集和解释响应,您可以直接从Python脚本中自动化访问关键数据,以支持分析、研究或决策制定。
您可以在我的GitHub仓库My-Articles-Friendly-Links中查看相应的代码My-Articles-Friendly-Links。
Josep Ferrer 是一位来自巴塞罗那的分析工程师。他拥有物理工程学位,目前从事应用于人类移动性数据科学方面的工作。他兼职担任内容创作者,专注于数据科学和技术。Josep撰写所有与AI相关的内容,涵盖了该领域正在发生的爆炸性应用。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区