



📢 转载信息
原文链接:https://www.kdnuggets.com/5-useful-python-scripts-for-synthetic-data-generation
原文作者:Kanwal Mehreen

Image by Editor
# 引言
合成数据顾名思义,是人为创建的,而不是从现实世界来源收集的。它看起来像真实数据,但可以避免隐私问题和高昂的数据收集成本。 这使得您能够轻松地测试软件和模型,同时运行实验来模拟发布后的性能。
尽管存在 Faker、SDV 和 SynthCity 等库,甚至大型语言模型(LLMs)也被广泛用于生成合成数据,但本文的重点是避免依赖这些外部库或 AI 工具。相反,您将学习如何通过编写自己的 Python 脚本来实现相同的结果。这有助于更深入地理解如何塑造数据集,以及偏差或错误是如何引入的。我们将从简单的示例脚本开始,以了解可用的选项。一旦您掌握了这些基础知识,就可以轻松地过渡到专门的库。
# 1. 生成简单的随机数据
最简单的起点是一个表格。例如,如果您需要一个用于内部演示的虚假客户数据集,您可以运行一个脚本来生成逗号分隔值(CSV)数据:
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
countries = ["Canada", "UK", "UAE", "Germany", "USA"]
plans = ["Free", "Basic", "Pro", "Enterprise"]
def random_signup_date():
start = datetime(2024, 1, 1)
end = datetime(2026, 1, 1)
delta_days = (end - start).days
return (start + timedelta(days=random.randint(0, delta_days))).date().isoformat()
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
country = random.choice(countries)
plan = random.choice(plans)
monthly_spend = round(random.uniform(0, 500), 2)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"country": country,
"plan": plan,
"monthly_spend": monthly_spend,
"signup_date": random_signup_date()
})
with open("customers.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved customers.csv")
输出:
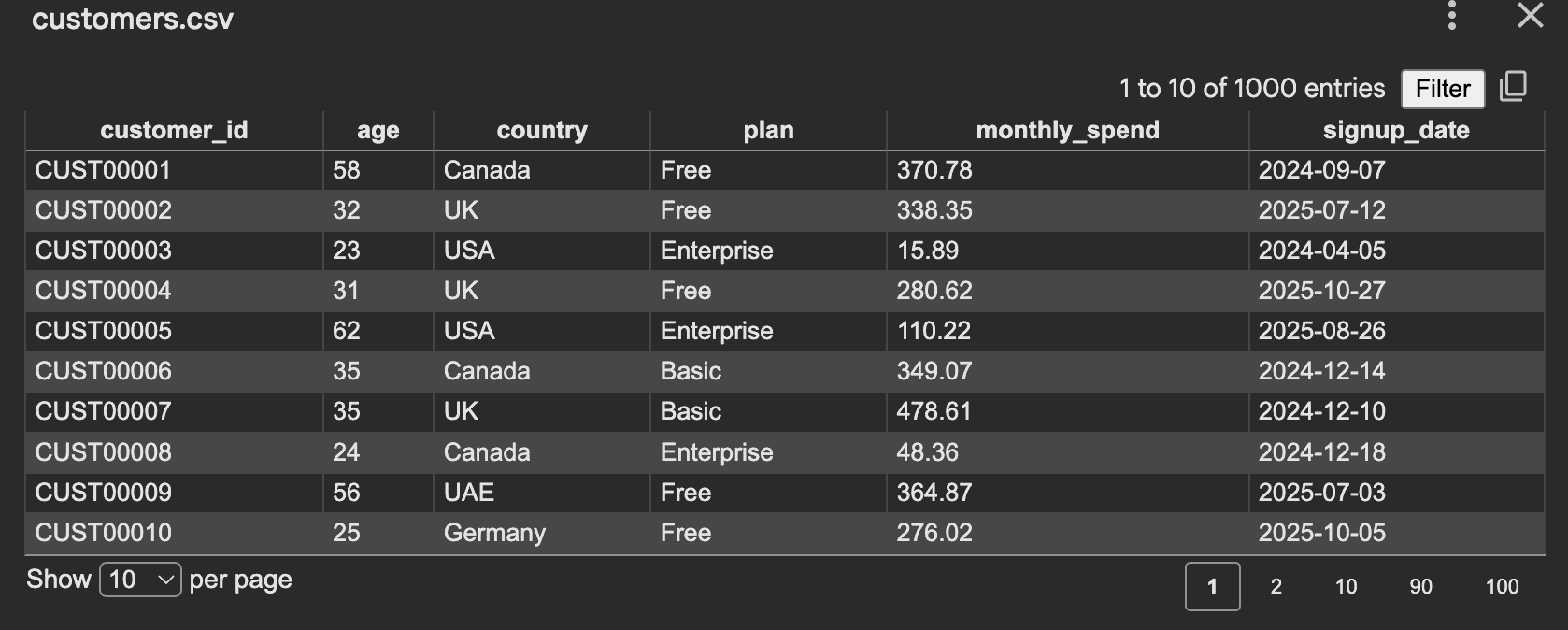
这个脚本很简单:您定义字段,选择范围,然后写入行。random 模块支持整数生成、浮点数值、随机选择和抽样。csv 模块设计用于读取和写入基于行的表格数据。这种类型的数据集适用于:
- 前端演示
- 仪表板测试
- API 开发
- 学习结构化查询语言(SQL)
- 单元测试输入管道
然而,这种方法有一个主要弱点:一切都是完全随机的。这通常会导致数据看起来平淡或不自然。企业客户的消费可能只有 2 美元,而“免费”用户可能消费 400 美元。老年用户的行为与年轻用户完全一样,因为没有潜在的结构。
在现实场景中,数据很少这样表现。与其独立生成值,不如引入关系和规则。这使得数据集感觉更真实,同时完全是合成的。例如:
- 企业客户的消费几乎不应该是零
- 消费范围应取决于所选计划
- 老年用户的平均消费可能略高
- 某些计划的普及程度应高于其他计划
让我们为脚本添加这些控制:
import csv
import random
random.seed(42)
plans = ["Free", "Basic", "Pro", "Enterprise"]
def choose_plan():
roll = random.random()
if roll < 0.45:
return "Free"
if roll < 0.75:
return "Basic"
if roll < 0.93:
return "Pro"
return "Enterprise"
def generate_spend(age, plan):
if plan == "Free":
base = random.uniform(0, 10)
elif plan == "Basic":
base = random.uniform(10, 60)
elif plan == "Pro":
base = random.uniform(50, 180)
else:
base = random.uniform(150, 500)
if age >= 40:
base *= 1.15
return round(base, 2)
rows = []
for i in range(1, 1001):
age = random.randint(18, 70)
plan = choose_plan()
spend = generate_spend(age, plan)
rows.append({
"customer_id": f"CUST{i:05d}",
"age": age,
"plan": plan,
"monthly_spend": spend
})
with open("controlled_customers.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved controlled_customers.csv")
输出:
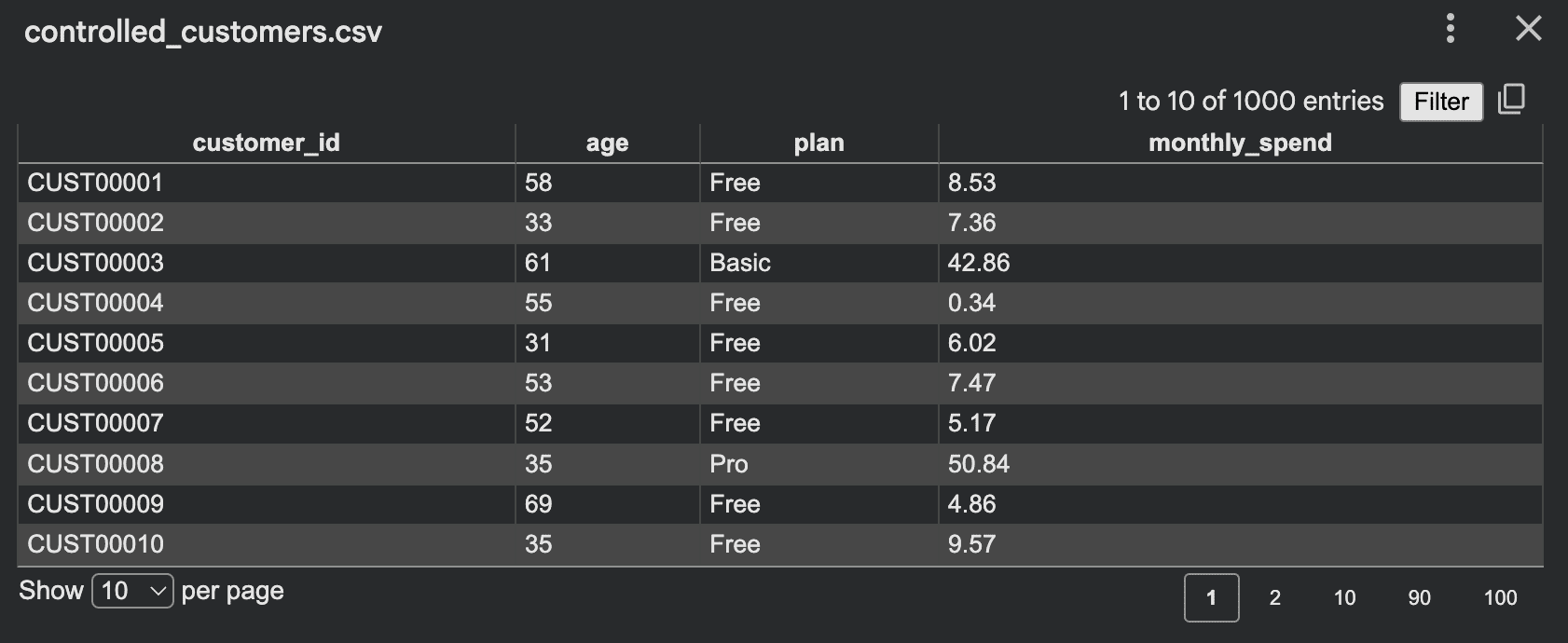
现在数据集保留了有意义的模式。您正在模拟行为,而不是生成随机噪声。有效的控制可能包括:
- 加权类别选择
- 真实的最小值和最大值范围
- 列之间的条件逻辑
- 故意添加罕见的边缘情况
- 以低速率插入缺失值
- 相关特征而不是独立特征
# 2. 模拟合成数据生成过程
基于模拟的生成是创建真实合成数据集的最佳方法之一。与其直接填充列,不如模拟一个过程。例如,考虑一个小型仓库,订单会到达,库存会减少,低库存水平会触发缺货订单。
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
inventory = {
"A": 120,
"B": 80,
"C": 50
}
rows = []
current_time = datetime(2026, 1, 1)
for day in range(30):
for product in inventory:
daily_orders = random.randint(0, 12)
for _ in range(daily_orders):
qty = random.randint(1, 5)
before = inventory[product]
if inventory[product] >= qty:
inventory[product] -= qty
status = "fulfilled"
else:
status = "backorder"
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": qty,
"stock_before": before,
"stock_after": inventory[product],
"status": status
})
if inventory[product] < 20:
restock = random.randint(30, 80)
inventory[product] += restock
rows.append({
"time": current_time.isoformat(),
"product": product,
"qty": restock,
"stock_before": inventory[product] - restock,
"stock_after": inventory[product],
"status": "restock"
})
current_time += timedelta(days=1)
with open("warehouse_sim.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved warehouse_sim.csv")
输出:
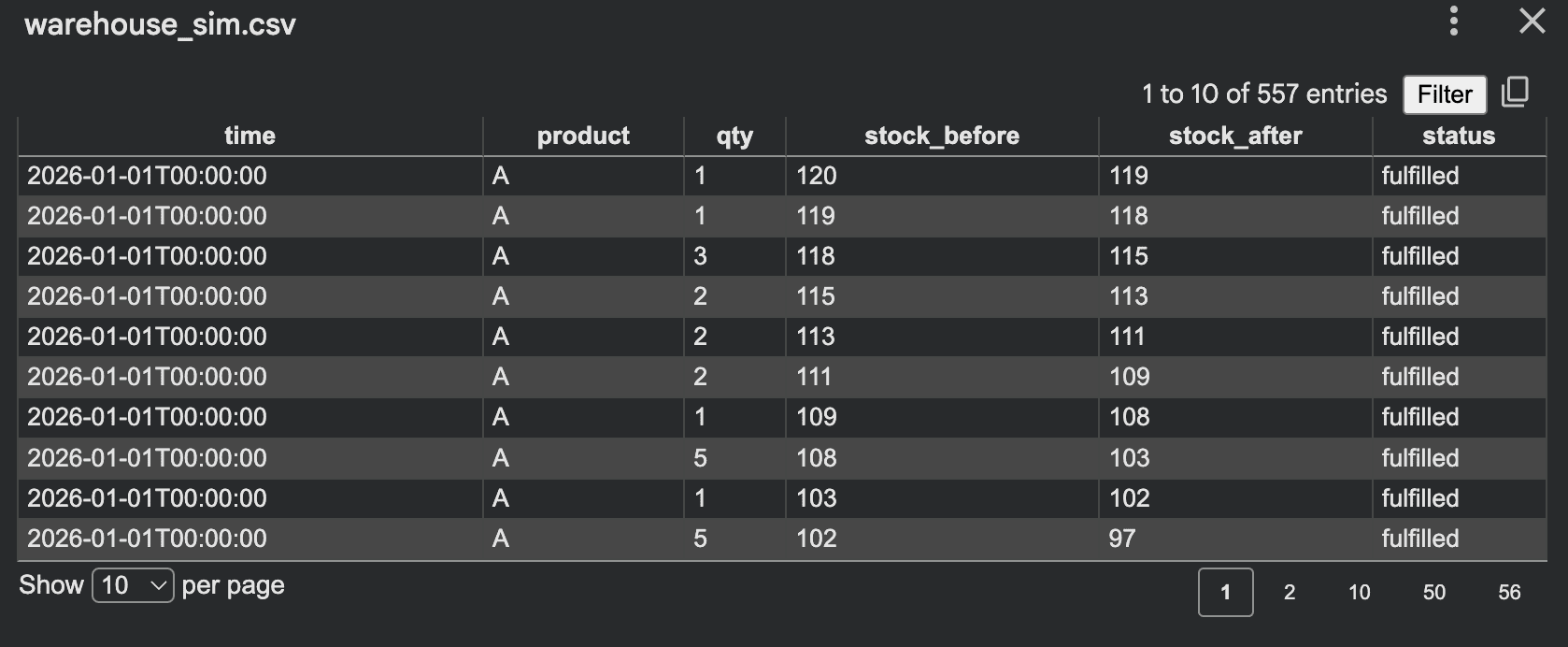
这种方法很棒,因为数据是系统行为的副产品,这通常会产生比直接随机行生成更真实的关系。其他模拟想法包括:
- 呼叫中心队列
- 叫车请求和司机匹配
- 贷款申请和批准
- 订阅和流失
- 患者预约流程
- 网站流量和转化
# 3. 生成时间序列合成数据
合成数据不仅仅限于静态表格。许多系统会生成随时间变化的序列,例如应用程序流量、传感器读数、每小时订单或服务器响应时间。以下是一个用于带有工作日模式的每小时网站访问量的简单时间序列生成器。
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
start = datetime(2026, 1, 1, 0, 0, 0)
hours = 24 * 30
rows = []
for i in range(hours):
ts = start + timedelta(hours=i)
weekday = ts.weekday()
base = 120
if weekday >= 5:
base = 80
hour = ts.hour
if 8 <= hour <= 11:
base += 60
elif 18 <= hour <= 21:
base += 40
elif 0 <= hour <= 5:
base -= 30
visits = max(0, int(random.gauss(base, 15)))
rows.append({
"timestamp": ts.isoformat(),
"visits": visits
})
with open("traffic_timeseries.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["timestamp", "visits"])
writer.writeheader()
writer.writerows(rows)
print("Saved traffic_timeseries.csv")
输出:
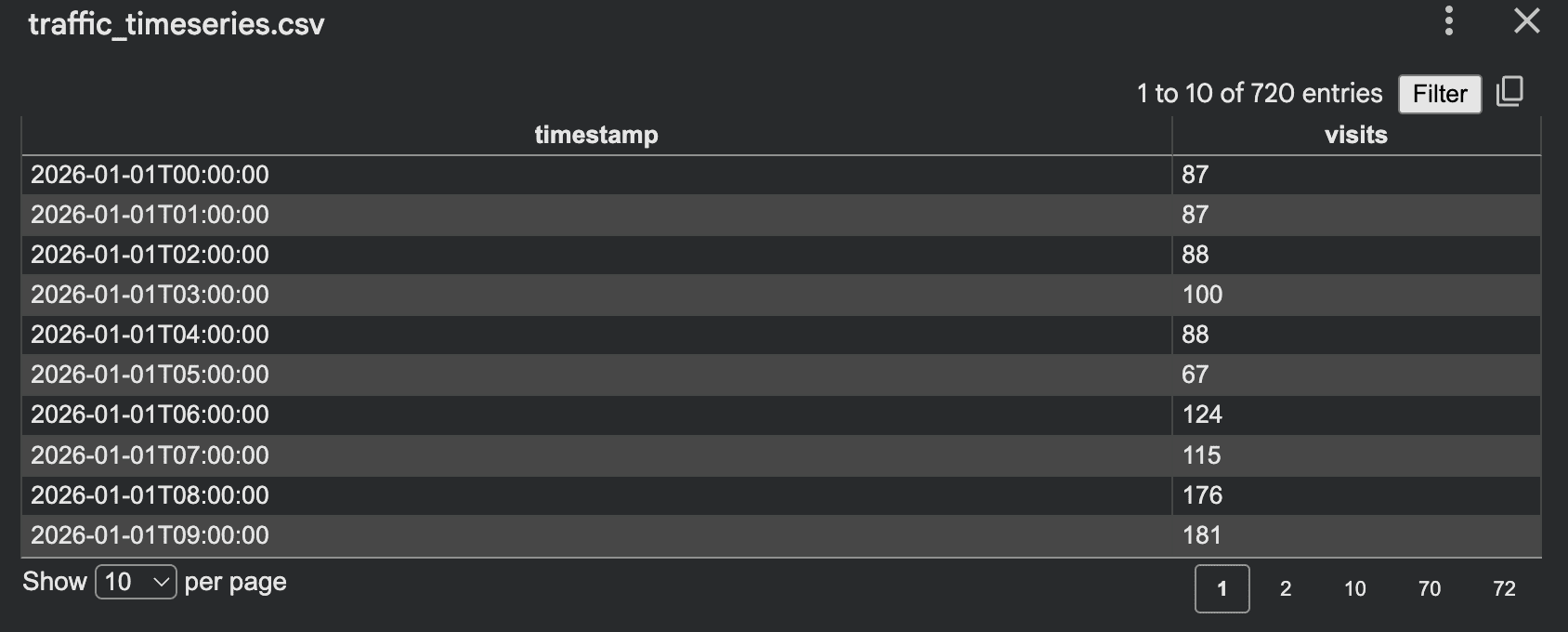
这种方法效果很好,因为它结合了趋势、噪声和周期性行为,同时易于解释和调试。
# 4. 创建事件日志
事件日志是另一种有用的脚本类型,非常适合产品分析和工作流测试。不是每行一个客户,而是为每个操作创建一行。
import csv
import random
from datetime import datetime, timedelta
random.seed(42)
events = ["signup", "login", "view_page", "add_to_cart", "purchase", "logout"]
rows = []
start = datetime(2026, 1, 1)
for user_id in range(1, 201):
event_count = random.randint(5, 30)
current_time = start + timedelta(days=random.randint(0, 10))
for _ in range(event_count):
event = random.choice(events)
if event == "purchase" and random.random() < 0.6:
value = round(random.uniform(10, 300), 2)
else:
value = 0.0
rows.append({
"user_id": f"USER{user_id:04d}",
"event_time": current_time.isoformat(),
"event_name": event,
"event_value": value
})
current_time += timedelta(minutes=random.randint(1, 180))
with open("event_log.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=rows[0].keys())
writer.writeheader()
writer.writerows(rows)
print("Saved event_log.csv")
输出:
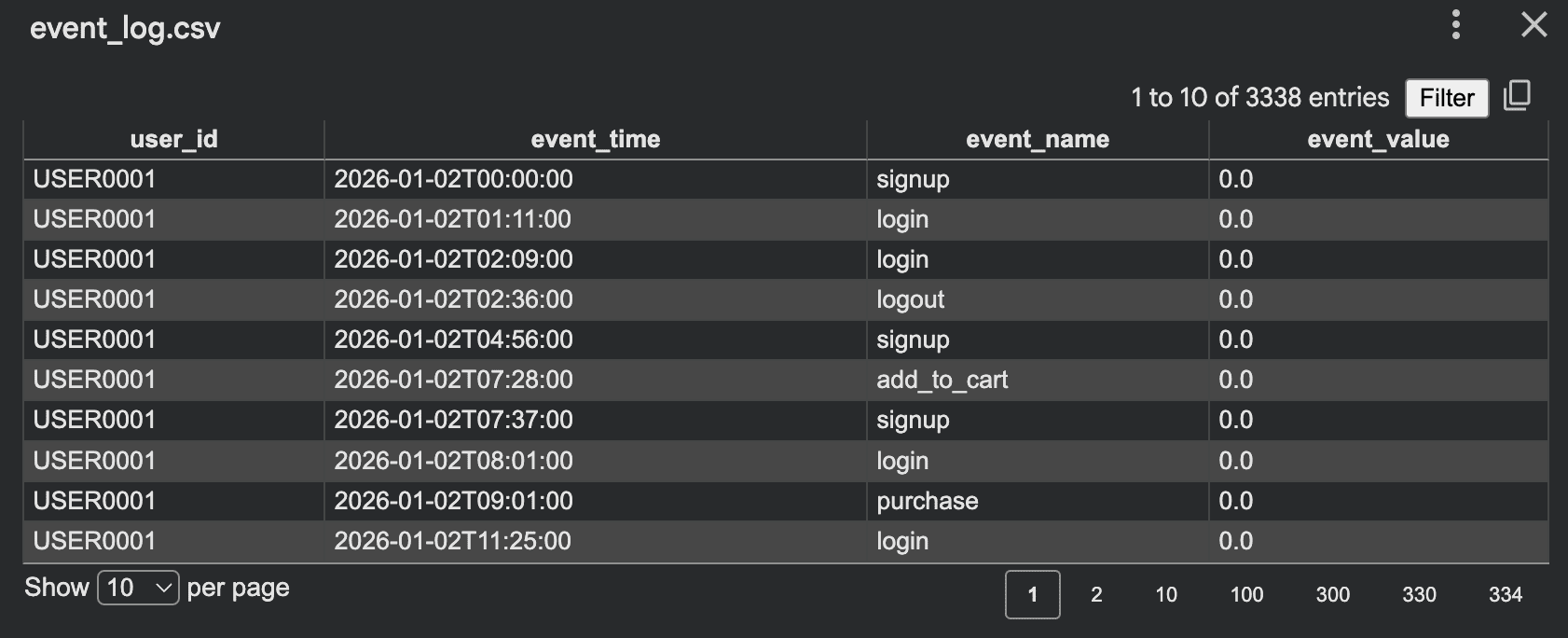
这种格式很有用:
- 漏斗分析
- 分析管道测试
- 商业智能(BI)仪表板
- 会话重建
- 异常检测实验
这里的一个有用技术是使事件依赖于先前的操作。例如,购买通常应该发生在登录或页面视图之后,这使得合成日志更具可信度。
# 5. 使用模板生成合成文本数据
合成数据对于自然语言处理(NLP)也很有价值。您不一定需要 LLM 来开始;您可以使用模板和受控的变异来构建有效的文本数据集。例如,您可以创建支持票证培训数据:
import json
import random
random.seed(42)
issues = [
("billing", "I was charged twice for my subscription"),
("login", "I cannot log into my account"),
("shipping", "My order has not arrived yet"),
("refund", "I want to request a refund"),
]
tones = ["Please help", "This is urgent", "Can you check this", "I need support"]
records = []
for _ in range(100):
label, message = random.choice(issues)
tone = random.choice(tones)
text = f"{tone}. {message}."
records.append({
"text": text,
"label": label
})
with open("support_tickets.jsonl", "w", encoding="utf-8") as f:
for item in records:
f.write(json.dumps(item) + "\n")
print("Saved support_tickets.jsonl")
输出:
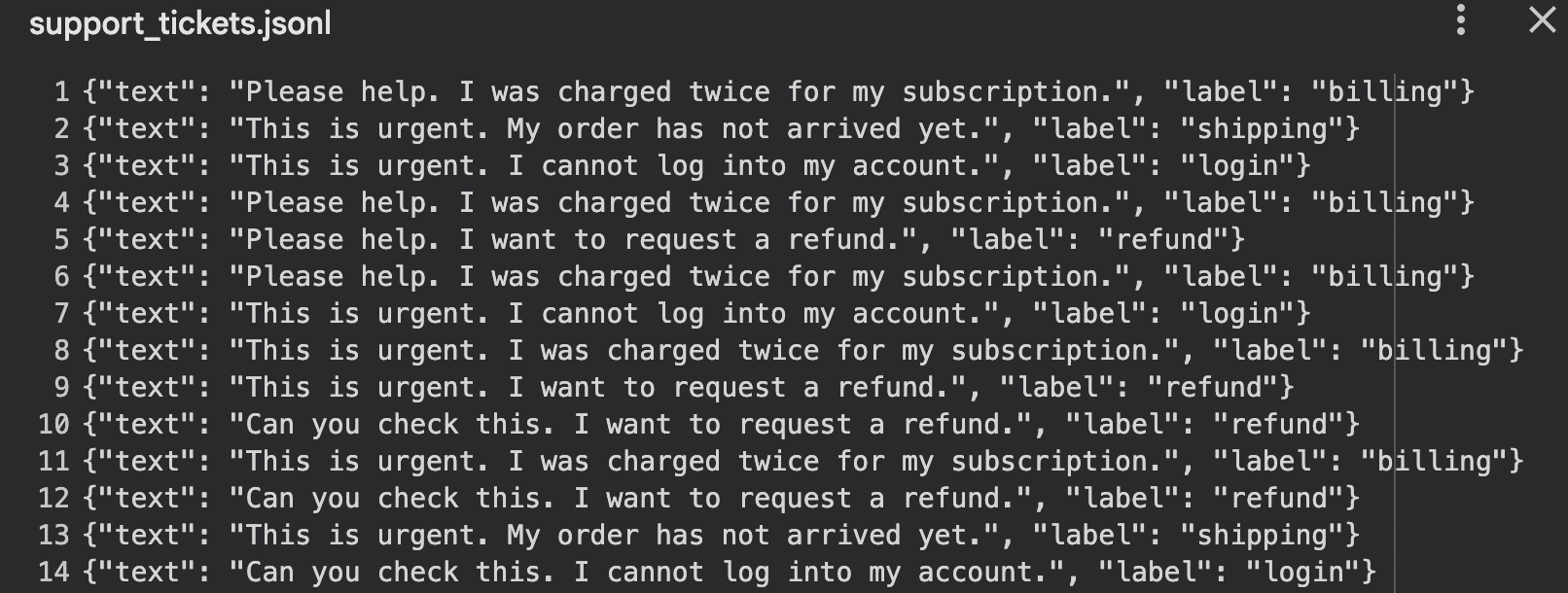
这种方法适用于:
- 文本分类演示
- 意图检测
- 聊天机器人测试
- 提示评估
# 最终思考
合成数据脚本是强大的工具,但可能被错误地实现。请务必避免这些常见错误:
- 所有值都均匀随机
- 忘记字段之间的依赖关系
- 生成违反业务逻辑的值
- 假设合成数据默认是安全的
- 创建过于“干净”而无法用于测试现实世界边缘情况的数据
- 过于频繁地使用相同的模式,导致数据集变得可预测且不真实
隐私仍然是最重要的考虑因素。虽然合成数据减少了暴露于真实记录的风险,但它并非没有风险。如果生成器与原始敏感数据联系过于紧密,仍然可能发生泄露。这就是为什么像差分隐私合成数据这样的隐私保护方法至关重要。
Kanwal Mehreen 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交叉领域充满热情。她是电子书《Maximizing Productivity with ChatGPT》的合著者。作为 2022 年 APAC 谷歌生成学者,她倡导多元化和学术卓越。她还被评为 Teradata Diversity in Tech Scholar、Mitacs Globalink Research Scholar 和 Harvard WeCode Scholar。Kanwal 是变革的坚定倡导者,她创立了 FEMCodes,以赋能 STEM 领域的女性。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区