



📢 转载信息
原文链接:https://aws.amazon.com/blogs/machine-learning/responsible-ai-design-in-healthcare-and-life-sciences/
原文作者:Tonny Ouma and Simon Handley
生成式AI已成为医疗保健领域的一项变革性技术,推动了患者参与和护理管理等关键领域的数字化转型。它在通过提供及时、个性化建议的自动化系统来改进临床医生提供护理的方式方面展现出潜力,这些系统具备诊断支持工具,最终可带来更好的健康结果。例如,《BMC医学教育》上发表的一项研究报告称,在模拟患者互动中接受大语言模型(LLM)生成反馈的医学生,其临床决策能力与未接受反馈的学生相比有了显著提高。
大多数生成式AI系统的核心是能够生成非常自然对话的LLM,这使得医疗保健客户能够在计费、诊断、治疗和研究等领域构建产品,这些产品可以执行任务并独立运行,并有人工监督。然而,生成式AI的实用性要求了解其对医疗服务交付的潜在风险和影响,因此需要仔细规划、定义和执行系统级方法来构建安全且负责任的生成式AI注入式应用程序。
在本文中,我们重点关注构建医疗保健生成式AI应用程序的设计阶段,包括定义决定输入和输出的系统级策略。可以将这些策略视为指南,遵循这些指南有助于构建负责任的AI系统。
负责任地设计
LLM可以通过减少对质量和可靠性等方面的考虑所需的时间和成本来改变医疗保健。如以下图表所示,通过考虑所有人的质量、可靠性、信任和公平性,可以将负责任的AI考量成功地集成到由LLM驱动的医疗保健应用程序中。目标是促进和鼓励AI系统的某些负责任的AI功能。示例如下:
- 确保每个组件的输入和输出与临床优先级保持一致,以维持一致性和促进可控性
- 实施安全措施(如护栏),以提高AI系统的安全性和可靠性
- 对整个端到端系统进行全面的AI红队测试和评估,以评估影响安全和隐私的输入和输出
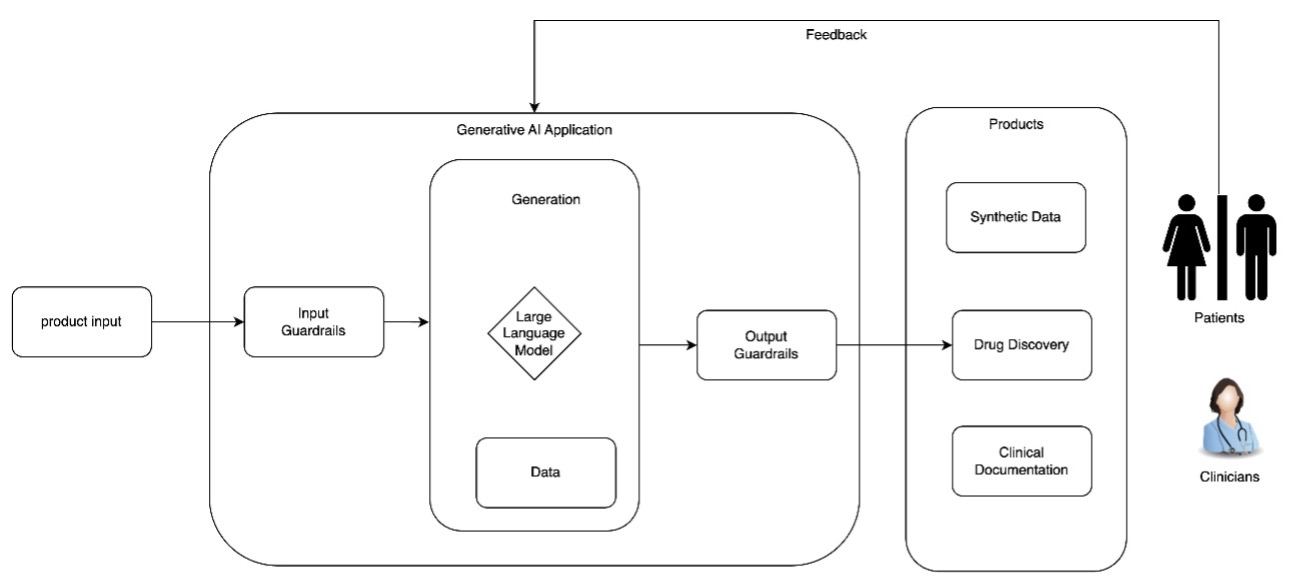
概念架构
下图显示了具有LLM的生成式AI应用程序的概念架构。输入(直接来自最终用户)通过输入护栏进行中介。输入被接受后,LLM可以使用内部数据源处理用户的请求。LLM的输出再次通过护栏进行中介,然后可以与最终用户共享。
建立治理机制
在医疗保健领域构建生成式AI应用程序时,必须考虑单个模型或系统级别,以及应用程序或实施级别的各种风险。生成式AI相关的风险可能不同于或甚至放大了现有的AI风险。两个最重要的风险是失实陈述和偏见:
- 失实陈述(Confabulation)——模型生成自信但有误的输出,有时也称为幻觉。这可能会误导患者或临床医生。
- 偏见(Bias)——这指的是由于训练数据不具代表性而加剧不同亚群之间历史社会偏见的风险。
为减轻这些风险,请考虑建立内容策略,明确定义应用程序应避免生成的内容类型。这些策略还应指导如何微调模型以及实施哪些适当的护栏。至关重要的是,策略和指南必须针对预期的用例进行定制和具体化。例如,专为临床文档设计的生成式AI应用程序应具有禁止其诊断疾病或提供个性化治疗方案的策略。
此外,定义清晰详细且针对特定用例的策略是负责任构建的基础。这种方法有助于建立信任,并帮助开发人员和医疗保健组织仔细考虑与特定应用程序中每个LLM相关的风险、益处、局限性和社会影响。
以下是您可以为医疗保健特定应用考虑使用的一些示例策略。第一张表总结了人机配置的角色和职责。
| 行动 ID | 建议的行动 | 生成式AI风险 |
| GV-3.2-001 | 制定策略,通过对生成式AI模型或系统进行独立评估或审查来加强对生成式AI系统的监督,其中评估的类型和稳健性与已识别的风险成正比。 | CBRN信息或能力;有害偏见和同质化 |
| GV-3.2-002 | 考虑在大型或复杂的生成式AI系统的整个生命周期阶段调整组织角色和组件,包括:生成式AI系统的测试和评估、验证和红队测试;生成式AI内容适度;生成式AI系统开发和工程;生成式AI工具、接口和系统的可访问性增强;以及事件响应和遏制。 | 人机配置;信息安全;有害偏见和同质化 |
| GV-3.2-003 | 为生成式AI接口、模态和人机配置(例如,用于AI助手和决策任务)定义可接受的使用策略,包括生成式AI应用程序应拒绝响应的查询类型标准。 | 人机配置 |
| GV-3.2-004 | 为生成式AI系统的用户反馈机制建立策略,包括详细说明和任何追索机制。 | 人机配置 |
| GV-3.2-005 | 参与威胁建模,以预期生成式AI系统的潜在风险。 | CBRN信息或能力;信息安全 |
下表总结了AI系统设计中风险管理的策略。
| 行动 ID | 建议的行动 | 生成式AI风险 |
| GV-4.1-001 | 制定解决生成式AI风险测量的持续改进过程的策略和程序。通过使用充足的文档和技术(如梯度基础归因的应用、遮挡或术语减少、反事实提示和提示工程以及嵌入分析)来解决生成式AI系统缺乏可解释性和透明度带来的一般风险。定期评估和更新风险测量方法。 | 失实陈述 |
| GV-4.1-002 | 制定详细说明使用场景中风险测量的策略、程序和流程,采用标准化的测量协议和结构化的公开反馈练习(如AI红队测试或独立的外部评估)。 | CBRN信息和能力;价值链和组件集成 |
透明度工件
在整个AI生命周期中促进透明度和问责制有助于建立信任、促进调试和监控,并实现审计。这包括通过模型卡等工具记录数据源、设计决策和限制,并就实验功能进行清晰沟通。纳入用户反馈机制进一步支持持续改进,并增强对AI驱动的医疗保健解决方案的信心。
AI开发人员和DevOps工程师应通过提供底层数据源和设计决策的清晰文档,对所有输出的证据和原因保持透明,以便最终用户可以就系统使用情况做出明智的决定。透明度有助于跟踪潜在问题,并促进内部和外部团队对AI系统的评估。透明度工件指导AI研究人员和开发人员负责任地使用模型,促进信任,并帮助最终用户就系统使用情况做出明智的决定。
以下是一些实施建议:
- 在使用实验模型或服务构建AI功能时,必须突出意外模型行为的可能性,以便医疗专业人员能够准确评估是否使用该AI系统。
- 考虑发布 Amazon SageMaker 模型卡或 AWS 系统卡等工件。此外,在 AWS,我们通过 AWS AI 服务卡提供有关我们AI系统的详细信息,其中列出了预期的用例和限制、负责任的AI设计选择以及某些 AI 服务的部署和性能优化最佳实践。AWS 还建议制定透明度策略和流程,用于记录训练数据的来源和历史记录,同时平衡训练方法的专有性质。考虑到您的应用程序可能使用基础模型 (FM) 但提供特定服务,建议创建一个结合了模型卡和服务卡元素的混合文档。
- 提供反馈用户机制。从医疗专业人员那里收集定期和计划的反馈可以帮助开发人员进行必要的改进,以提高系统性能。还要考虑制定策略,以帮助开发人员为AI系统提供用户反馈机制。这些应包括详细说明并考虑为任何追索机制制定政策。
设计即安全
在开发AI系统时,应考虑应用程序每个层次结构中的安全最佳实践。生成式AI系统可能容易受到对抗性攻击,例如提示注入,它通过操纵大型语言模型的输入或提示来利用其漏洞。这类攻击可能导致数据泄露、未经授权的访问或其他安全漏洞。为解决这些问题,进行 风险评估 并为应用程序的输入和输出层实施护栏会很有帮助。通常,您的操作模型应设计用于执行以下操作:
- 通过实施个人身份信息 (PII) 检测、配置检查提示攻击的护栏,来保护患者隐私和数据安全
- 持续评估所有生成式AI功能和工具的益处和风险,并通过 Amazon CloudWatch 或其他警报定期监控其性能
- 在部署前彻底评估所有基于AI的工具的质量、安全性和公平性
开发人员资源
以下资源在架构和构建生成式AI应用程序时非常有用:
- Amazon Bedrock 护栏 有助于您根据用例和负责任的AI策略为生成式AI应用程序实施安全措施。您可以为不同的用例创建多个定制的护栏,并将它们应用于多个FM,从而在整个生成式AI应用程序中提供一致的用户体验并标准化安全和隐私控制。
- AWS 负责任的AI白皮书 是为在关键护理环境(其中错误可能导致危及生命后果)中开发AI应用程序的医疗专业人员和其他开发人员提供的宝贵资源。
- AWS AI 服务卡 解释了该服务的预期用途、服务使用机器学习 (ML) 的方式以及负责任地设计和使用该服务的关键注意事项。
结论
通过负责任的实施,生成式AI有潜力通过提高护理质量、患者体验、临床安全和行政安全来改善医疗保健的几乎每一个方面。在设计、开发或操作AI应用程序时,应通过建立以维护用户期望的安全、隐私和信任为基础的治理和评估框架,来系统地考虑潜在的限制。
有关负责任的AI的更多信息,请参阅以下资源:
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区