



📢 转载信息
原文作者:Jia Li, Xi Wan, Bao Cao, Hanyi Zhang, Xiaowei Zhu, and Zepei Yu
游戏公司在管理其广告创意资产方面面临前所未有的挑战。现代游戏公司为 A/B 测试活动制作了数千个视频广告,一些组织维护着包含超过 100,000 个视频资产的库,并且每月以数千个资产的速度增长。这些资产对用户获取活动至关重要,在这些活动中,找到正确的创意资产可能决定了一次成功的发布还是一次代价高昂的失败。
在本文中,我们将介绍如何使用 Amazon Nova 多模态嵌入来检索特定的视频片段。我们还将回顾一个真实用例,在该用例中,Nova 多模态嵌入在针对 170 个游戏创意资产库进行测试时,实现了 96.7% 的召回成功率和 73.3% 的高精度召回(即在前两个结果中返回目标内容)。该模型在多种语言中也展示出强大的跨语言能力,性能下降极小。
用于分类、存储和搜索创意资产的传统方法无法满足创意团队的动态需求。传统上,创意资产需要手动标记以启用基于关键词的搜索,然后组织在文件夹层次结构中,供人工搜索所需资产。基于关键词的搜索系统需要耗费大量人力且不一致的手动标记。虽然像基于 LLM 的自动标记这样的大语言模型(LLM)解决方案提供了强大的多模态理解能力,但它们无法扩展以满足创意团队跨海量资产库执行多样化、实时搜索的需求。
核心挑战在于创意资产发现的语义搜索。搜索需要支持不可预测的搜索需求,这些需求无法用固定的提示词或预定义标签预先组织。当创意专业人员搜索 the character is pinched away by hand(角色被手捏走)或 A finger taps a card in the game(一根手指点击游戏中的一张牌)时,系统必须理解的不仅是关键词,还有跨不同媒体类型的语义含义。
这就是 Nova 多模态嵌入改变现状的地方。Nova 多模态嵌入是一种最先进的多模态嵌入模型,适用于 Agentic 检索增强生成(RAG)和语义搜索应用,它在 Amazon Bedrock 中提供,并采用统一的向量空间架构。更重要的是,该模型直接从视频资产生成嵌入,无需中间转换步骤或手动标记。
Nova 多模态嵌入的视频嵌入生成实现了对视频内容的真正语义理解。Nova 多模态嵌入可以分析视频中的视觉场景、动作、对象和上下文,以创建丰富的语义表示。当您搜索 the character is pinched away by hand 时,模型理解所描述的具体动作、视觉元素和上下文,而不仅仅是关键词匹配。这种语义能力避免了基于关键词的搜索系统的根本限制,因此创意团队可以使用自然语言描述找到相关的视频内容,而这些描述是传统方法无法预先标记或组织的。
解决方案概述
在本节中,您将了解 Nova 多模态嵌入及其关键功能、优势,以及与 AWS 服务的集成,以创建全面的多模态搜索架构。本文描述的多模态搜索架构提供以下功能:
- 输入灵活性:接受文本查询、上传的图像、视频和音频文件作为搜索输入
- 跨模态检索:用户可以使用文本描述查找视频、图像和音频内容,或使用上传的图像发现跨多种媒体类型的相似视觉内容
- 输出精度:返回带有相似度得分、视频片段精确时间戳和详细元数据的排序结果
- 同步搜索和检索:通过预计算的嵌入和高效的向量相似度匹配,提供即时搜索结果
- 统一异步架构:搜索查询异步处理,以处理不同的处理时间并提供一致的用户体验
Nova 多模态嵌入
Nova 多模态嵌入是第一个支持文本、文档、图像、视频和音频的统一嵌入模型,通过单一模型实现具有行业领先准确性的跨模态检索。它提供以下关键功能和优势:
- 统一向量空间架构:与需要不同向量空间之间复杂映射的传统基于标签的系统或多模态到文本转换管道不同,Nova 多模态嵌入生成的嵌入存在于相同的语义空间中,而与输入模态无关。这意味着对
racing car(赛车)的文本描述将在空间上靠近包含赛车的图像和视频,从而实现直观的跨模态搜索。 - 灵活的嵌入维度:Nova 多模态嵌入提供四种嵌入维度选项(256、384、1024 和 3072),使用 Matryoshka 表示学习(MRL)进行训练,能够在不同维度上以最小的精度损失实现低延迟检索。1024 维度的选项为大多数企业应用提供了最佳平衡,而 3072 维度则为关键用例提供了最大的精度。
- 同步和异步 API:该模型支持对较小内容的实时嵌入生成和对大型文件的异步处理(带有自动分段)。这种灵活性使系统能够处理从快速文本查询检索到对数小时视频内容进行索引的所有内容。
- 高级视频理解:对于视频内容,Nova 多模态嵌入提供了复杂的分段功能,将长视频分解为有意义的片段(1-30 秒),并为每个片段生成嵌入。对于广告创意管理,这种分段方法与典型的制作工作流程完美契合,即创意团队需要管理和检索特定的视频片段而不是整个视频。
与 AWS 服务的集成
Nova 多模态嵌入与其他 AWS 服务无缝集成,以创建可投入生产的多模态搜索架构:
- Amazon Bedrock:提供具有企业级安全和可扩展性的基础模型访问权限
- Amazon OpenSearch Service:作为存储和搜索嵌入的向量数据库,提供毫秒级的查询响应时间
- AWS Lambda:处理嵌入生成和搜索操作的无服务器处理
- Amazon Simple Storage Service (Amazon S3):以无限的可扩展性存储原始媒体文件和处理结果
- Amazon API Gateway:为前端集成提供 RESTful API
技术实现
系统架构
系统通过内容摄取和搜索检索两个主要工作流运行,如下图所示,并在以下部分进行描述。
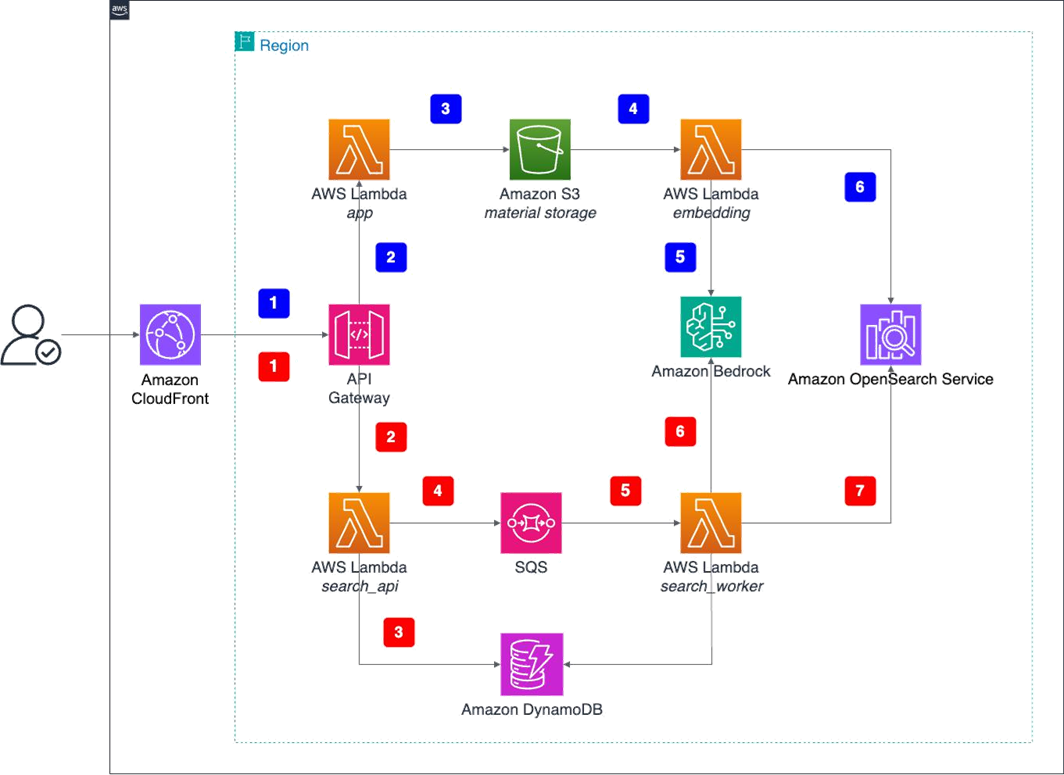
系统执行流程
内容摄取工作流通过一系列自动化步骤将原始媒体文件转换为可搜索的向量嵌入。此过程始于用户上传内容,最终以将嵌入存储在向量数据库中而告终,从而使内容可通过语义搜索发现。
- 用户交互:用户通过 Amazon CloudFront 访问 Web 界面,使用拖放或文件选择上传媒体文件(图像、视频和音频)。
- API 处理:文件被转换为 base64 格式,并通过 API Gateway 发送到主 Lambda 函数,以进行文件类型和大小限制验证(最大文件大小为 10 MB)。
- Amazon S3 存储:Lambda 解码 base64 数据并将原始文件上传到 Amazon S3 进行持久化存储。
- Amazon S3 事件触发:当上传新文件时,Amazon S3 会自动触发专用的嵌入 Lambda 函数,启动嵌入生成过程。
- Amazon Bedrock 调用:嵌入 Lambda 函数异步调用 Amazon Bedrock Nova 多模态嵌入模型,为多种媒体类型生成统一的嵌入向量。
- 向量存储:嵌入 Lambda 函数将生成的嵌入向量以及元数据存储在 OpenSearch Service 中,创建可搜索的向量数据库。
搜索和检索工作流
通过搜索和检索工作流,用户可以使用多模态查询查找相关内容。此过程将用户查询转换为嵌入,并针对预先构建的向量数据库执行相似性搜索,根据跨不同媒体类型的语义相似性返回排序结果。
- 搜索请求:用户通过 Web 界面使用上传的文件或文本查询发起搜索,可以选择不同的搜索模式(视觉、语义或音频)。
- API 处理:搜索请求通过 API Gateway 发送到搜索 API Lambda 函数进行初始处理。
- 任务创建:搜索 API Lambda 函数在 Amazon DynamoDB 中创建搜索任务记录,并向 Amazon Simple Queue Service (Amazon SQS) 队列发送消息以进行异步处理。
- 队列处理:搜索 API Lambda 函数向 Amazon SQS 队列发送消息以进行异步处理。这种统一的异步架构处理 Nova 多模态嵌入的 API 要求(视频分段的异步调用),防止 API Gateway 超时,并有助于确保多种查询类型的可扩展处理。
- 工作进程激活:搜索工作进程 Lambda 函数由 Amazon SQS 消息触发,提取搜索参数并准备进行嵌入生成。
- 查询嵌入:工作进程 Lambda 函数调用 Amazon Bedrock Nova 多模态嵌入模型为搜索查询(文本或上传文件)生成嵌入向量。
- 向量搜索:工作进程 Lambda 函数在 OpenSearch Service 中使用余弦相似度执行相似性搜索,然后更新 DynamoDB 中的结果以供前端轮询。
工作流集成
前一节中描述的两个工作流共享公共的基础设施组件,但服务于不同的目的:
- 上传工作流 (1-6):专注于摄取和处理媒体文件,以构建可搜索的向量数据库
- 搜索工作流 (A-G):处理用户查询并从预构建的向量数据库中检索相关结果
- 共享组件:两个工作流都使用相同的 Amazon Bedrock 模型、OpenSearch Service 索引和核心 AWS 服务
关键技术特性
- 统一向量空间:所有媒体类型(图像、视频、音频和文本)都被嵌入到相同的维度空间中,实现了真正的跨模态搜索。
- 异步处理:统一的异步架构通过 Amazon SQS 队列和工作进程 Lambda 函数处理 Amazon Nova 多模态嵌入 API 要求,并有助于确保可扩展的处理。
- 多模态搜索:支持文本到图像、文本到视频、文本到音频和文件到文件之间的相似性搜索。
- 可扩展架构:无服务器设计根据需求自动扩展。
- 状态跟踪:轮询机制提供异步处理状态和搜索结果的更新。
使用 Nova 多模态嵌入进行核心嵌入生成
request_body = { "schemaVersion": "amazon.nova-embedding-v1:0", "taskType": "SEGMENTED_EMBEDDING", "segmentedEmbeddingParams": { "embeddingPurpose": "GENERIC_INDEX", "embeddingDimension": self.dimension, "video": { "format": self._get_video_format(s3_uri), "source": { "s3Location": { "uri": s3_uri } }, "embeddingMode": "AUDIO_VIDEO_COMBINED", "segmentationConfig": { "durationSeconds": 5 # Default 5 second segmentation } } } } output_config = { "s3OutputDataConfig": { "s3Uri": output_s3_uri } } print(f"Nova async embedding request: {json.dumps(request_body, indent=2)}") # Start an asynchronous call response = self.bedrock_client.start_async_invoke( modelId=self.model_id, modelInput=request_body, outputDataConfig=output_config ) invocation_arn = response['invocationArn'] print(f"Started Nova async embedding job: {invocation_arn}")跨模态搜索实现
该系统的核心在于使用 OpenSearch k-近邻 (KNN) 搜索来实现智能的跨模态搜索能力,如下面的代码所示:
def search_similar(self, query_vector: List[float], embedding_field: str, top_k: int = 20, filters: Dict[str, Any] = None) -> List[Dict[str, Any]]: """Search for similar vectors using OpenSearch KNN""" query = { "size": top_k, "query": { "knn": { embedding_field: { "vector": query_vector, "k": top_k } } }, "_source": [ "s3_uri", "file_type", "timestamp", "media_type", "segment_index", "start_time", "end_time", "duration" ] } # Add filters for media type or other criteria if filters: query["query"] = { "bool": { "must": [query["query"]], "filter": [{"terms": {k: v}} for k, v in filters.items()] } } response = self.client.search(index=self.index, body=query) # Process and return results with metadata results = [] for hit in response['hits']['hits']: source = hit['_source'] results.append({ 'score': hit['_score'], 's3_uri': source['s3_uri'], 'file_type': source['file_type'], 'media_type': source.get('media_type', 'unknown'), 'segment_info': { 'segment_index': source.get('segment_index'), 'start_time': source.get('start_time'), 'end_time': source.get('end_time') } }) return results向量存储和检索
系统使用 OpenSearch Service 作为其向量数据库,针对不同嵌入类型优化索引,如下面的代码所示:
def create_index_if_not_exists(self): """Create OpenSearch index with optimized schema""" if not self.client.indices.exists(self.index): index_body = { 'settings': { 'index': { 'knn': True, "mapping.total_fields.limit": 5000 } }, 'mappings': { 'properties': { # Vector fields for different modalities with HNSW configuration 'visual_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, 'text_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, 'audio_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, # Metadata fields 's3_uri': {'type': 'keyword'}, 'media_type': {'type': 'keyword'}, 'file_type': {'type': 'keyword'}, 'timestamp': {'type': 'date'}, 'segment_index': {'type': 'integer'}, 'start_time': {'type': 'float'}, 'end_time': {'type': 'float'}, 'duration': {'type': 'float'}, # Amazon Nova Multimodal Embeddings support audio_video_combined fields 'audio_video_combined_embedding': { 'type': 'knn_vector', 'dimension': VECTOR_DIMENSION, 'method': { 'name': 'hnsw', 'space_type': 'cosinesimil', 'engine': 'faiss' } }, # model fields 'model_type': {'type': 'keyword'}, 'model_version': {'type': 'keyword'}, 'vector_dimension': {'type': 'integer'}, # document fields 'document_type': {'type': 'keyword'}, 'source_file': {'type': 'keyword'}, 'page_number': {'type': 'integer'}, 'total_pages': {'type': 'integer'} } } } self.client.indices.create(self.index, body=index_body) print(f"Created index: {self.index}")此架构支持多种模态(视觉、文本和音频)以及 KNN 索引,从而实现灵活的跨模态搜索,同时保留有关视频片段和模型来源的详细元数据。
真实应用与性能
以游戏行业用例为例,想象一位创意专业人士需要为新活动找到显示 characters celebrating victory with bright visual effects(角色用绚丽的视觉效果庆祝胜利)的视频片段。
传统方法需要:
- 手动标记数千个视频,这既耗时又可能不一致
- 基于关键词的搜索,忽略语义细微差别
- LLM 分析速度太慢且成本太高,无法进行实时查询
有了 Nova 多模态嵌入,同样的查询就变成了一个简单的文本搜索,它:
- 生成查询的语义嵌入
- 在统一向量空间中的所有视频片段中搜索
- 根据语义相似度返回排序结果
- 为相关的视频片段提供精确的时间戳
性能指标和验证
基于与游戏行业合作伙伴在包含 170 个资产(130 个视频和 40 个图像)的库上进行的全面测试,Nova 多模态嵌入在 30 个测试用例中展现出卓越的性能:
- 召回成功率:96.7% 的测试用例成功检索到目标内容
- 高精度召回:73.3% 的测试用例在前两个结果中返回了目标内容
- 跨模态准确性:与传统方法相比,文本到视频检索的准确性更高
主要发现
从我们的测试结果中学到的如下:
- 分段策略:对于广告创意工作流程,我们建议使用
SEGMENTED_EMBEDDING并采用 5 秒的视频分段,因为它符合典型的制作要求。创意团队通常需要在管理和检索特定剪辑时对原始广告材料进行分段,这使得 Nova 多模态嵌入的分段功能对这些用例特别有价值。 - 评估框架:为了评估 Nova 多模态嵌入对您用例的有效性,请专注于测试以下核心功能:
- 对象和实体检测:测试查询,例如
red sports car(红色跑车)或character with sword(带剑的角色),以评估跨模态的对象识别能力 - 场景和上下文理解:评估上下文搜索,例如
outdoor celebration scene(户外庆祝场景)或indoor meeting environment(室内会议环境) - 活动和动作:验证基于动作的查询,例如
running character(奔跑的角色)或clicking interface elements(点击界面元素) - 视觉属性:测试特定于属性的搜索,包括颜色、样式和视觉特征
- 抽象语义:评估概念理解,例如
victory celebration(胜利庆祝)或tense atmosphere(紧张气氛) - 测试方法:构建一个来自内容库的代表性测试数据集,创建匹配真实用户需求的多种查询类型,并同时衡量召回成功率(找到相关内容)和精度(排名质量)。重点关注反映团队实际搜索模式的查询,而不是通用测试用例。
- 多语言性能:Nova 多模态嵌入展示出强大的跨语言能力,尤其是在中文查询方面表现出色(得分为 78.2),而英文查询得分为 89.3(3072 维度)。这代表的语言差距仅为 11.1,明显优于另一种领先的多模态模型在不同语言之间出现的大幅性能下降。
可扩展性和成本效益
无服务器架构在优化成本的同时提供了自动扩展能力。在设计多模态资产发现系统时,请牢记以下维度性能详情和成本优化策略。
维度性能:
- 3072 维度:最高精度(英文 89.3,中文 78.2)和较高的存储成本
- 1024 维度:平衡的性能(英文 85.7,中文 68.3);推荐用于大多数用例
- 384/256 维度:面向大规模部署的成本优化选项
成本优化策略:
- 根据精度要求与存储成本选择维度
- 使用异步处理来处理大文件,避免超时成本
- 使用预计算的嵌入来减少经常性的 LLM 推理成本
- 使用无服务器架构和按需付费定价,以在低使用期间降低成本
入门
本节提供了部署和运行 Nova 多模态嵌入多模态搜索系统的基本要求和步骤。
- 拥有 Amazon Bedrock 访问权限和 Nova 多模态嵌入模型可用性的 AWS 帐户
- 已配置适当资源创建权限的 AWS Command Line Interface (AWS CLI) v2
- 安装了 Node.js 18+ 和 AWS CDK v2
- 用于基础设施部署的 Python 3.11
- 用于克隆演示存储库的 Git
快速部署
可以使用以下自动化脚本部署完整系统:
# Clone the demonstration repository git clone https://github.com/aws-samples/sample-multimodal-embedding-models cd sample-multimodal-embedding-models # Configure service prefix (optional) # Edit config/settings.py to customize SERVICE_PREFIX # Deploy Amazon Nova Multimodal Embeddings system ./deploy_model.sh nova-segmented部署脚本自动执行以下操作:
- 安装所需的依赖项
- 配置 AWS 资源(Lambda、OpenSearch、Amazon S3 和 API Gateway)
- 构建并部署前端界面
- 配置 API 端点和 CloudFront 分配
访问系统
成功部署后,系统会提供用于测试的 Web 界面:
- 上传界面:用于向系统添加媒体文件
- 搜索界面:用于执行多模态查询
- 管理界面:用于监控处理状态
多模态输入支持(可选)
此可选小节使系统除了文本查询外,还能接受图像和视频输入,以实现全面的多模态搜索功能。
def search_by_image(self, image_s3_uri: str) -> Dict: """Find similar content using image as query""" query_embedding = self.nova_service.get_image_embedding(image_s3_uri) # Search across all media types using visual similarity return self.opensearch_manager.search_similar( query_embedding=query_embedding, embedding_field='visual_embedding', size=10 )清理
为避免持续产生费用,请使用以下命令删除部署期间创建的 AWS 资源:
# Remove all system resources ./destroy_model.sh nova-segmented结论
Amazon Nova 多模态嵌入代表了组织如何大规模管理和发现多模态内容的根本性转变。通过提供一个无缝集成文本、图像和视频内容的统一向量空间,Nova 多模态嵌入消除了传统上限制跨模态搜索能力的障碍。完整的源代码和部署脚本可在 演示存储库中获取。
关于作者
 Jia Li 是亚马逊云科技(Amazon Web Services)的行业解决方案架构师,专注于推动游戏行业的技术创新和业务增长。拥有 20 年的全栈游戏开发经验,曾就职于联众、人人、饥饿工作室等公司,担任游戏制作人和大型研发中心总监。对行业动态和商业模式有深入见解。
Jia Li 是亚马逊云科技(Amazon Web Services)的行业解决方案架构师,专注于推动游戏行业的技术创新和业务增长。拥有 20 年的全栈游戏开发经验,曾就职于联众、人人、饥饿工作室等公司,担任游戏制作人和大型研发中心总监。对行业动态和商业模式有深入见解。
 Xiaowei Zhu 是亚马逊云科技(AWS)的行业解决方案构建师。拥有超过 10 年的移动应用开发经验,他在嵌入搜索、自动化测试和 Vibe Coding 方面也有深入的专业知识。目前,他负责构建 AWS 游戏行业资产并领导开源应用程序 SwiftChat 的开发。
Xiaowei Zhu 是亚马逊云科技(AWS)的行业解决方案构建师。拥有超过 10 年的移动应用开发经验,他在嵌入搜索、自动化测试和 Vibe Coding 方面也有深入的专业知识。目前,他负责构建 AWS 游戏行业资产并领导开源应用程序 SwiftChat 的开发。
 Hanyi Zhang 是 AWS 的解决方案架构师,专注于云架构... [内容被截断]
Hanyi Zhang 是 AWS 的解决方案架构师,专注于云架构... [内容被截断]
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区