



📢 转载信息
原文作者:Ishan Singh, Abhishek Kumar, Jonathan Buck, and Vinayak Arannil
评估单轮智能体交互遵循着大多数团队都非常熟悉的模式:提供输入、收集输出并评价结果。Strands Evaluation SDK 等框架通过评估器来衡量智能体的有用性、忠实度和工具使用情况,使这一过程系统化。然而,生产环境中的对话很少会止步于一轮。
真实用户进行的交流往往涉及多轮互动。当回答不完整时,他们会提出后续问题;当出现新信息时,他们会调整方向;当需求未得到满足时,他们会表达挫败感。仅仅通过静态测试用例来评估这种动态模式显然是不够的。
为什么多轮评估从根本上更困难

在多轮交互中,每一条消息都取决于之前发生的一切。用户的第二个问题受到智能体对第一个问题回答的影响。这种自适应行为创造了无法在测试设计时预见的对话路径。静态的输入/输出数据集无法捕捉这种动态质量,因为“正确”的下一个用户消息完全取决于智能体刚刚说了什么。
人工测试在理论上可以填补这一空白,但在实践中却难以持续。随着智能体能力的增强,对话路径的数量呈组合式增长,远超团队手动探索的极限。
什么构成了优秀的模拟用户
对于 AI 智能体评估,一个有用的模拟用户应该具备一致的角色设定(Persona)和目标驱动的行为。模拟用户必须能够根据智能体的反馈进行自适应调整,而不是遵循预设的脚本。Strands Evals 中的 ActorSimulator 正是基于这些原则设计的。
ActorSimulator 的工作原理
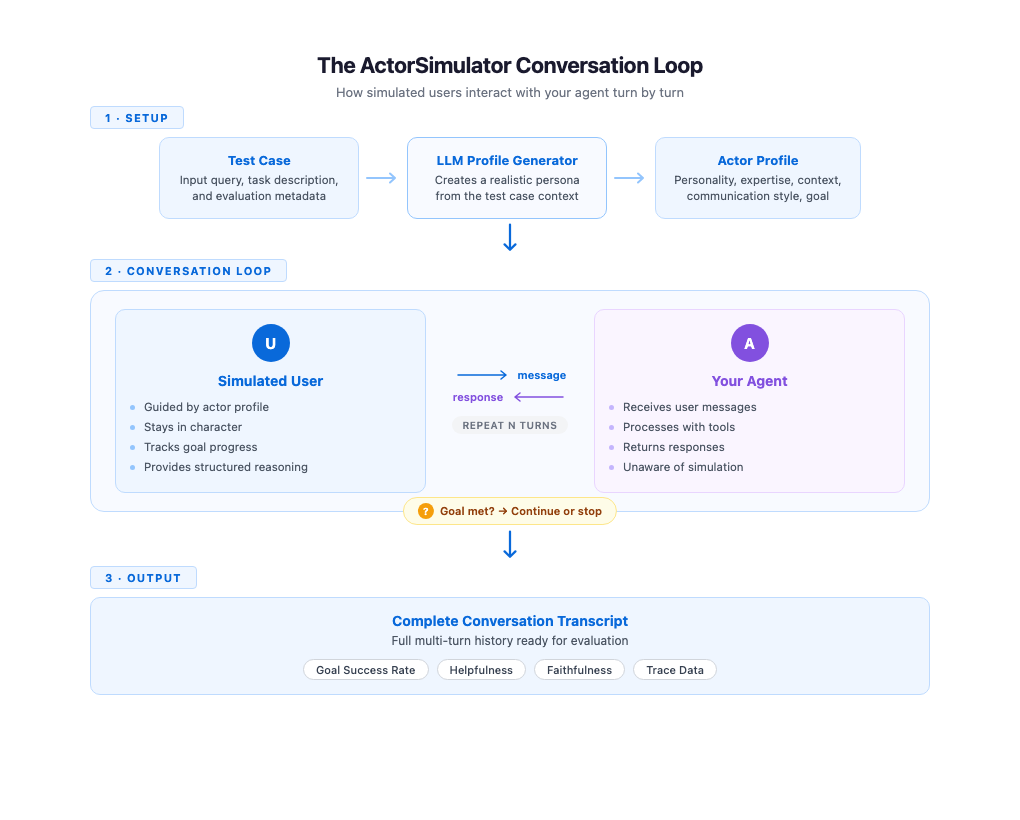
ActorSimulator 通过包装一个配置为模拟真实用户角色的 Strands 智能体来实现上述特性。该系统不仅管理对话上下文,还内置了目标完成评估工具,能够判断用户的原始目标是否达成。如果目标满足或模拟用户判断智能体无法完成请求,系统会自动终止对话,避免无限循环。
入门指南
要开始使用,您可以通过 pip install strands-agents-evals 安装 SDK。以下是一个评估旅行助手智能体的多轮对话示例:
from strands import Agent
from strands_evals import ActorSimulator, Case
# 定义测试用例
case = Case(input="我想计划一次带酒店和活动的东京旅行", metadata={"task_description": "完成旅行套餐安排"})
# 创建要评估的智能体
agent = Agent(system_prompt="你是一个有用的旅行助手。", callback_handler=None)
# 创建模拟用户
user_sim = ActorSimulator.from_case_for_user_simulator(case=case, max_turns=5)
# 运行多轮对话循环...
总结
我们展示了 ActorSimulator 如何通过真实的用户模拟实现对对话式 AI 智能体的系统性、多轮评估。通过定义明确的目标和角色,您可以让模拟用户与您的智能体进行自然、自适应的交流。所得的对话记录可直接接入评估管道,为您提供详尽的指标分析。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区