



📢 转载信息
原文链接:https://machinelearningmastery.com/train-your-large-model-on-multiple-gpus-with-tensor-parallelism/
原文作者:Adrian Tam
张量并行(Tensor parallelism)是一种模型并行技术,它沿着特定维度对张量进行分片,并将计算分布到多个设备上,同时将通信开销降至最低。这项技术适用于参数张量非常大的模型,即使是单个矩阵乘法也无法装入单个GPU。在本文中,您将学习如何使用张量并行。具体来说,您将了解到:
- 什么是张量并行
- 如何设计张量并行方案
- 如何在PyTorch中应用张量并行
让我们开始吧!

使用张量并行在多个GPU上训练您的超大模型。
照片作者:Seth kane。保留部分权利。
概述
本文分为五个部分:
- 张量并行的示例
- 设置张量并行
- 准备模型以进行张量并行
- 使用张量并行训练模型
- 将张量并行与FSDP结合使用
张量并行的示例
张量并行起源于Megatron-LM论文。此技术并非适用于所有操作;然而,某些操作(如矩阵乘法)是通过分片计算来实现的。
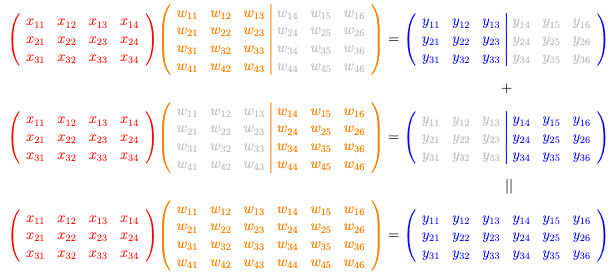
列式并行(Column-wise parallel):您将权重 $\mathbf{W}$ 分成多列,并应用矩阵乘法 $\mathbf{XW}=\mathbf{Y}$ 来产生需要拼接的分片输出。
让我们考虑一个简单的矩阵-矩阵乘法运算,如下所示:
这是一个 $3\times 4$ 矩阵 $\mathbf{X}$ 乘以一个 $4\times 6$ 矩阵 $\mathbf{W}$ 以产生一个 $3 imes 6$ 矩阵 $\mathbf{Y}$。您确实可以将其分解为两次矩阵乘法:一次是 $\mathbf{X}$ 乘以一个 $4\times 3$ 矩阵 $\mathbf{W}_1$ 产生一个 $3 imes 3$ 矩阵 $\mathbf{Y}_1$,另一次是 $\mathbf{X}$ 乘以另一个 $3\times 2$ 矩阵 $\mathbf{W}_2$ 产生一个 $3 imes 3$ 矩阵 $\mathbf{Y}_2$。然后最终的 $\mathbf{Y}$ 是 $\mathbf{Y}_1$ 和 $\mathbf{Y}_2$ 的拼接。
您可以看到,在这种情况下,您无需在内存中容纳大型矩阵 $\mathbf{W}$,而是处理其较小的分片。这节省了内存。每个分片的输出更小,因此与其他设备的通信也更快。
上述情况称为列式并行。您可以将其推广,沿列维度对矩阵 $\mathbf{W}$ 进行两个以上的切分。
另一种变体是行式并行,如图所示:
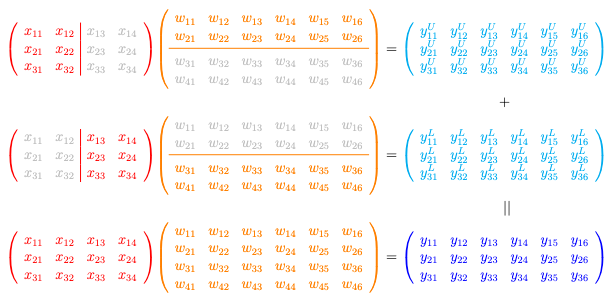
行式并行(Row-wise tensor parallel):您将权重 $\mathbf{W}$ 分成多行,并应用矩阵乘法 $\mathbf{XW}=\mathbf{Y}$ 来产生需要逐元素相加的部分输出。
对于相同的 $\mathbf{XW}=\mathbf{Y}$ 矩阵乘法,您现在将 $\mathbf{X}$ 分成列,将 $\mathbf{W}$ 分成行。在上面的插图中,来自 $\mathbf{X}$ 左半部分的 $3\times 2$ 矩阵乘以来自 $\mathbf{W}$ 上半部分的 $2\times 6$ 矩阵以产生一个 $3\times 6$ 矩阵。输出形状与完整方程相同,但数值仅对应于 $\mathbf{W}$ 的上半部分。对 $\mathbf{X}$ 的右半部分和 $\mathbf{W}$ 的下半部分重复相同的操作,然后将两个结果相加,即可得到最终输出 $\mathbf{Y}$。
在行式并行中,您处理 $\mathbf{X}$ 和 $\mathbf{W}$ 的分片。工作负载比执行完整的矩阵乘法要轻。输出比列式并行大,需要更多的带宽将结果与其他设备通信。
您深度学习模型中的并非所有操作都是矩阵乘法。因此,张量并行不适用于模型中的每个元素。某些操作,例如激活函数或归一化层,可以以不同的方式并行化。对于无法并行化的操作,您的模型必须以其原始形式计算它们。
张量并行带来的好处不仅限于内存节省,它还为计算和通信模式提供了细粒度的控制。由于矩阵乘法是分片的,您可以控制是否取消分片结果,从而在直接使用分片的 DTensor 对象时避免通信开销。
设置张量并行
PyTorch中的张量并行是分布式框架的一部分。因此,脚本使用 torchrun 命令启动,正如分布式数据并行、管道并行和完全分片数据并行那样。您需要像往常一样初始化分布式环境,但还需要设置设备网格(device mesh):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import os
import torch
import torch.distributed as dist
# Initialize the distributed environment
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
device = torch.device(f"cuda:{local_rank}")
rank = dist.get_rank()
world_size = dist.get_world_size()
# Initialize the mesh for tensor parallelism
mesh = dist.device_mesh.init_device_mesh(
"cuda",
(world_size,),
)
|
设备网格是进程组的高级抽象。您将在后面的部分中看到它为何需要存在。它很有必要,因为您使用该网格将模型包装成一个张量并行模型,语法如下:
|
1
2
3
|
from torch.distributed.tensor.parallel import parallelize_module
model = parallelize_module(model, mesh, tp_plan)
|
此后,模型的一些权重将被替换为 DTensor 对象,使得操作可以并行运行。分布式集合操作(如 all-gather、all-reduce 和 reduce-scatter)可能会在内部执行,以使模型像在单个设备上运行时一样工作。这些细节对您来说是透明的。
准备模型以进行张量并行
让我们看看如何使用张量并行来运行前一篇文章中介绍的训练脚本。
将模型转换为使用张量并行不需要更改模型架构。相反,您需要知道模型中每个模块和子模块的完全限定名称。这些名称与模型 state_dict() 中的键相同,或者您可以回顾您的模型架构代码以查找模块名称。
您需要识别这些名称来创建并行化方案。它是一个将模块名称映射到 ParallelStyle 对象的 Python 字典。示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
tp_plan = {
"input_layernorm": SequenceParallel(),
"self_attn": PrepareModuleInput(
input_layouts=Shard(dim=1), # only one position arg will be used
desired_input_layouts=Replicate(),
),
# Q/K/V output will be used with GQA, prefer to be replicated
"self_attn.q_proj": ColwiseParallel(output_layouts=Replicate()),
"self_attn.k_proj": ColwiseParallel(output_layouts=Replicate()),
"self_attn.v_proj": ColwiseParallel(output_layouts=Replicate()),
"self_attn.o_proj": RowwiseParallel(input_layouts=Replicate(), output_layouts=Shard(1)),
"post_attention_layernorm": SequenceParallel(),
"mlp": PrepareModuleInput(
input_layouts=Shard(dim=1),
desired_input_layouts=Replicate(),
),
"mlp.gate_proj": ColwiseParallel(),
"mlp.up_proj": ColwiseParallel(),
"mlp.down_proj": RowwiseParallel(output_layouts=Shard(1)),
}
with torch.device("meta"):
model_config = LlamaConfig()
model = LlamaForPretraining(model_config)
for layer in model.base_model.layers:
parallelize_module(layer, mesh, tp_plan)
|
模型架构代码与前一篇文章中的完全相同。tp_plan 字典是从 Transformer 块的角度创建的。请注意,每个块的声明如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class LlamaAttention(nn.Module):
def __init__(self, config: LlamaConfig) -> None:
super().__init__()
...
# Linear layers for Q, K, V projections
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
...
class LlamaMLP(nn.Module):
def __init__(self, config: LlamaConfig) -> None:
super().__init__()
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.act_fn = F.silu # SwiGLU activation function
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
...
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig) -> None:
super().__init__()
self.input_layernorm = nn.RMSNorm(config.hidden_size, eps=1e-5)
self.self_attn = LlamaAttention(config)
self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, eps=1e-5)
self.mlp = LlamaMLP(config)
...
|
从 LlamaDecoderLayer 类的角度来看,您可以找到一个 nn.Linear 层,如 layer.mlp.gate_proj,因此您在 tp_plan 字典中使用键 mlp.gate_proj 来引用它。
当您使用张量并行时,应该意识到 PyTorch 不知道如何并行化任意模块,例如您定义的自定义模块。但是,少数标准模块具有张量并行的具体实现:
nn.Linear和nn.Embedding:您可以使用ColwiseParallel和RowwiseParallel来并行化它们。操作如上所述。nn.LayerNorm、nn.RMSNorm和nn.Dropout:您可以使用SequenceParallel来并行化它们。
随着 PyTorch 的发展,请参阅官方文档以获取张量并行的最新覆盖范围。
设置好 tp_plan 后,您可以使用 parallelize_module() 函数将其应用于模型。这将用 DTensor 对象替换模块的参数,并使模块像在单个设备上运行时一样执行分片计算。上面的 for 循环为了方便将 parallelize_module() 应用于每个 Transformer 块。您也可以将其应用于整个基础模型,但由于 Transformer 块在基础模型中重复多次,您需要用大量的重复来更新 tp_plan。
Transformer 块包含两个 RMS norm 层。您使用 SequenceParallel 标记它们,以表明它们应在序列维度(输入张量的第 1 维)上分片。
Transformer 块包含几个 nn.Linear 层:前馈子层中有三个,注意力子层中有四个。您可以使用 ColwiseParallel 或 RowwiseParallel 来标记它们以实现并行化,但需要考虑一些因素:
ColwiseParallel默认期望一个完整的张量作为输入,输出将在最后一维上分片,使输出张量更小。RowwiseParallel默认期望一个在最后一维上分片的张量作为输入,输出是一个完整大小的张量,与未并行化时的大小相同。
这就是您指定以下内容的原因:
|
1
2
3
4
5
6
|
{ ... "mlp.gate_proj": ColwiseParallel(),
"mlp.up_proj": ColwiseParallel(),
"m... [内容被截断]
|
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区