



📢 转载信息
原文作者:Adrian Tam
有些语言模型大到无法在一块GPU上进行训练。除了像流水线并行(Pipeline Parallelism)那样将模型创建为阶段管道外,您还可以使用全分片数据并行(Fully Sharded Data Parallelism, FSDP)将模型分割到多个GPU上。在本文中,您将学习如何使用FSDP来分割模型进行训练。具体来说,您将了解到:
- 分片(sharding)的概念以及FSDP的工作原理
- 如何在PyTorch中使用FSDP
让我们开始吧!

使用全分片数据并行(FSDP)在多GPU上训练您的超大型模型。
图片来源:Ferenc Horvath。部分权利保留。
概述
本文分为五个部分:
- 全分片数据并行的介绍
- 为FSDP训练准备模型
- 带FSDP的训练循环
- 微调FSDP行为
- FSDP模型的检查点保存
全分片数据并行的介绍
分片(Sharding)一词最初用于数据库管理系统,指将数据库划分为更小的单元(称为分片)以提高性能。在机器学习中,分片指的是将模型参数分散到多个设备上。与流水线并行不同,分片只包含完整操作的一部分。例如,nn.Linear模块本质上是矩阵乘法。其分片版本只包含矩阵的一部分。当一个分片模块需要处理数据时,必须临时收集这些分片以创建完整的矩阵并执行操作。操作完成后,该矩阵会被丢弃以回收内存。
当使用FSDP时,所有模型参数都会被分片,并且每个进程恰好持有一个分片。与数据并行(Data Parallelism, DP)不同,在DP中,每个GPU都拥有模型的完整副本,只有数据和梯度更新会在GPU之间同步,FSDP不会在每个GPU上保留模型的完整副本;相反,模型和数据在每一步都会同步。因此,FSDP以更低的内存使用量为代价,换取了更高的通信开销。
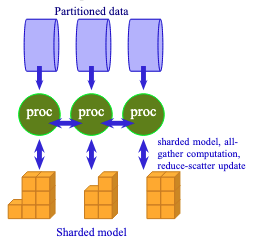
FSDP要求进程交换数据以解分片模型。
FSDP的工作流程如下:
将有多个进程协同运行,可能在跨网络的多个机器上。每个进程(或等效地,每个GPU)只持有一个模型的分片。当模型被分片时,每个模块的权重存储为DTensor(分布式张量,跨多个GPU分片),而不是普通的Tensor。因此,任何进程都无法独立运行任何模块。在执行每个操作之前,FSDP会发出一个all-gather(全收集)请求,使所有进程能够相互交换模块的分片。这会创建一个临时的未分片(unsharded)模块,每个进程使用其微批次(micro-batch)数据在此模块上运行前向传播。之后,随着进程进入模型的下一个模块,该未分片模块即被丢弃。
类似的操作也发生在反向传播中。FSDP发出all-gather请求时,每个模块都必须被解分片。然后反向传播根据前向传播的结果计算梯度。请注意,每个进程操作的是不同的数据微批次,因此每个进程计算出的梯度也不同。因此,FSDP会发出一个reduce-scatter(规约-分散)请求,导致所有进程交换梯度,从而对整个批次的梯度进行平均。然后使用这个最终的批次梯度来更新每个分片上的模型参数。
如上图所示,FSDP需要比纯数据并行更多的通信和更复杂的工作流程。由于模型分布在多个GPU上,您不需要像以往那样多的VRAM来容纳一个非常大的模型。这就是使用FSDP进行训练的动机。
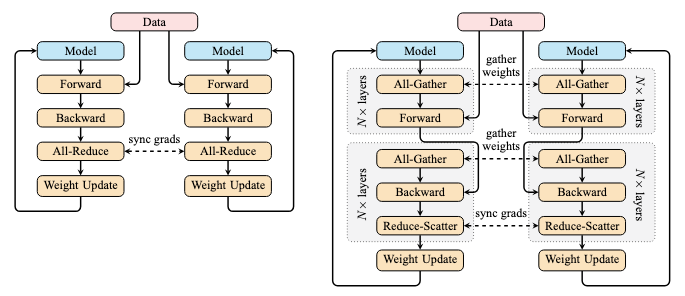
比较DP(左)和FSDP(右)。插图改编自Ott等人的博客文章。
为了提高FSDP的效率,PyTorch使用预取(prefetching)来重叠通信和计算。当您的GPU正在计算第一个模块时,进程会交换第二个模块的分片,这样第二个模块在第一个模块完成后即可投入使用。这使得GPU和网络都能保持忙碌,从而减少了每个训练步骤的延迟。对FSDP进行一些调整可以帮助您最大化这种重叠并提高训练吞吐量,尽管这通常会增加内存使用量。
为FSDP训练准备模型
当您需要FSDP时,通常意味着您的模型太大而无法放入单个GPU中。启用如此大型模型的一种方法是先在“meta”(元)虚拟设备上训练它,然后将其分片并将分片分布到多个GPU上。
在PyTorch中,您需要使用torchrun命令来启动一个包含多个进程的FSDP训练脚本。在torchrun下,每个进程将看到世界大小(总进程数)、其进程ID(当前进程的索引)和其本地进程ID(当前机器上GPU设备的索引)。在脚本中,您需要像这样初始化进程组:
|
1
2
3
4
5
6
7
8
9
|
import torch.distributed as dist
# Initialize the distributed environment
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
device = torch.device(f"cuda:{local_rank}")
rank = dist.get_rank()
world_size = dist.get_world_size()
print(f"World size {world_size}, rank {rank}, local rank {local_rank}. Using {device}")
|
接下来,您应该创建模型,然后对其进行分片。以下代码基于上一篇文章中描述的模型架构:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
...
from torch.distributed.fsdp import FSDPModule, fully_shard
with torch.device("meta"):
model_config = LlamaConfig()
model = LlamaForPretraining(model_config)
for layer in model.base_model.layers:
fully_shard(layer)
fully_shard(model.base_model)
fully_shard(model)
model.to_empty(device=device)
model.reset_parameters()
assert isinstance(model, FSDPModule), f"Expected FSDPModule, got {type(model)}"
|
在PyTorch中,您使用fully_shard()函数来创建一个分片模型。此函数会就地将类型为Tensor的参数替换为DTensor。它还会修改模型,以便在实际计算之前执行all-gather操作。
您应该注意到,在上面代码中,fully_shard()不仅在model上调用,还在model.base_model以及基模型中的每个Transformer块上调用。这需要仔细考虑。
通常情况下,您不希望只分片顶级模型,还希望分片其下的一些子模块。当您这样做时,必须从下至上应用fully_shard(),最后再分片顶级模型。每个分片模块将成为一次all-gather操作的单元。在所示的设计中,当您将张量传递给model时,除了那些被单独分片的组件外,顶级模型组件将被解分片。由于这是一个仅解码器的Transformer模型,输入应首先由基模型处理,然后由顶层模型的预测头处理。FSDP将解分片基模型,但每个重复的Transformer块除外。这也包括输入嵌入层,它是应用于输入张量的第一个操作。
经过嵌入层后,输入张量应由一系列Transformer块处理。每个块都会单独分片,因此每个块都会触发一次all-gather操作。该块转换输入并将其传递给下一个Transformer块。在最后一个Transformer块之后,基模型中已经处于未分片状态的RMSNorm层处理输出,然后返回给顶层模型进行预测。
这就是为什么您不希望分片顶级模型的原因:如果您这样做了,all-gather操作将在每个GPU上创建一个完整的模型,这违反了每个GPU内存不足以支持完整模型的假设。在这种情况下,您应该使用纯数据并行而不是FSDP。
在此设计中,每个GPU需要一个完整的Transformer块以及顶部模型和基模型中的其他模块,例如嵌入层、基模型中的最终RMSNorm层和顶层模型中的预测头。您可以修改此设计(例如,通过进一步分片model.base_model.embed_tokens并将每个Transformer块分解为注意力子层和前馈子层)以进一步减少内存需求。
获得分片模型后,您可以使用model.to_empty(device=device)将其从meta设备传输到本地GPU。您还需要重置新创建的模型的权重(除非您想从检查点初始化它们)。您可以借用上一篇文章中用于重置权重的reset_all_weights()函数。这里是另一种使用model.reset_parameters()的方法。这要求您在每个模块中实现相应的成员函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
lass LlamaAttention(nn.Module):
"""Grouped-query attention with rotary embeddings."""
def __init__(self, config: LlamaConfig) -> None:
super().__init__()
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_kv_heads = config.num_key_value_heads # GQA: H_kv < H_q
# Linear layers for Q, K, V projections
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
def reset_parameters(self):
self.q_proj.reset_parameters()
self.k_proj.reset_parameters()
self.v_proj.reset_parameters()
self.o_proj.reset_parameters()
def forward(self, hidden_states: Tensor, rope: RotaryPositionEncoding, attn_mask: Tensor) -> Tensor:
...
class LlamaMLP(nn.Module):
"""Feed-forward network with SwiGLU activation."""
def __init__(self, config: LlamaConfig) -> None:
super().__init__()
# Two parallel projections for SwiGLU
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.act_fn = F.silu # SwiGLU activation function
# Project back to hidden size
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
def reset_parameters(self):
self.gate_proj.reset_parameters()
self.up_proj.reset_parameters()
self.down_proj.reset_parameters()
def forward(self, x: Tensor) -> Tensor:
...
class LlamaDecoderLayer(nn.Module):
"""Single transformer layer for a Llama model."""
def __init__(self, config: LlamaConfig) -> None:
s... [内容被截断]
|
评论区