



📢 转载信息
原文链接:https://machinelearningmastery.com/training-a-model-on-multiple-gpus-with-data-parallelism/
原文作者:Adrian Tam
训练一个大型语言模型(LLM)是很慢的。如果你有多块GPU,可以通过在它们之间分配工作负载并行运行来加速训练。在本文中,你将了解到数据并行技术。特别是,你将学习到:
- 什么是数据并行
- PyTorch中
DataParallel和DistributedDataParallel之间的区别 - 如何使用数据并行训练模型
让我们开始吧!

使用数据并行在多GPU上训练模型
图片来源:Ilse Orsel。保留部分权利。
概述
本文分为两部分:
- 数据并行(Data Parallelism)
- 分布式数据并行(Distributed Data Parallelism)
数据并行
如果你有多块GPU,可以将它们组合起来,当作一个具有更大内存容量的单一GPU来操作。这项技术被称为数据并行。本质上,你将模型复制到每块GPU上,但每块GPU处理不同的数据子集。然后你聚合结果以进行梯度更新。
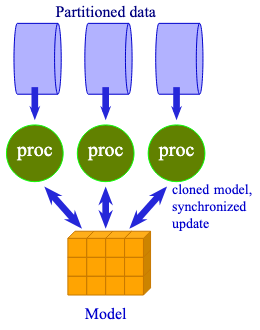
数据并行是将相同的模型共享给多个处理器来处理不同数据。
数据并行并不侧重于速度。事实上,由于额外的通信开销,切换到数据并行可能会减慢训练速度。
当模型仍然可以装入单个GPU,但由于内存限制无法使用较大的批次大小时,数据并行很有用。在这种情况下,你可以使用梯度累积。这等效于在多GPU上运行小批量数据,然后像数据并行中那样聚合梯度。
运行PyTorch模型的数据并行很容易。你只需要使用nn.DataParallel包装模型即可。结果是一个新的模型,它可以跨所有本地GPU分发和聚合数据。
考虑前一篇文章中的训练循环,你只需要在创建模型后立即包装它:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
...
model_config = LlamaConfig()
model = LlamaForPretraining(model_config)
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
model = nn.DataParallel(model) # wrap the model for DataParallel
model.train()
...
# start training
for epoch in range(epochs):
pbar = tqdm.tqdm(dataloader, desc=f"Epoch {epoch+1}/{epochs}")
for batch_id, batch in enumerate(pbar):
# get batched data
input_ids, target_ids = batch
# create attention mask: causal mask + padding mask
attn_mask = create_causal_mask(input_ids.shape[1], device) + \
create_padding_mask(input_ids, PAD_TOKEN_ID, device)
# extract output from model
logits = model(input_ids, attn_mask)
# compute loss: cross-entropy between logits and target, ignoring padding tokens
loss = loss_fn(logits.view(-1, logits.size(-1)), target_ids.view(-1))
# backward with loss and gradient clipping
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
pbar.set_postfix(loss=loss.item())
pbar.update(1)
pbar.close()
torch.save(
model.module.state_dict() if isinstance(model, nn.DataParallel) else model.state_dict(),
"model.pth"
)
|
你可以看到,训练循环中没有任何变化。但在创建模型时,你用nn.DataParallel包装了它。包装后的模型是原始模型的一个代理,但它将数据分发到多个GPU上。每个GPU都有一个相同的模型副本。当你用一个批处理张量运行模型时,该张量被分割到各个GPU上,每个GPU处理一个微批次。然后结果被聚合以产生输出张量。
同样,对于反向传播,每个GPU计算其微批次的梯度,然后将最终梯度聚合到所有GPU上以更新模型参数。
从用户的角度来看,使用数据并行训练的模型与单GPU模型没有区别。但是,当你保存模型时,你应该保存底层模型,可以通过model.module访问。加载模型时,应先加载原始模型,然后再次用nn.DataParallel包装它。
请注意,当你按上述方式运行训练循环时,第一个GPU将消耗大部分内存,因为它保存着模型参数和梯度的主副本,以及优化器和调度器的状态。如果你需要精确控制,可以指定要使用的GPU列表以及存储模型参数主副本的设备。
|
1
2
3
|
if torch.cuda.device_count() > 1:
print(f"Using {torch.cuda.device_count()} GPUs")
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3], output_device=0)
|
分布式数据并行
PyTorch DataParallel作为多线程程序运行。这可能会出现问题,因为Python多线程性能受到限制。
因此,PyTorch建议使用分布式数据并行(DDP),即使在单机多GPU上运行时也是如此。DDP使用多进程模型,其中每个GPU作为一个单独的进程运行,从而避免了多线程的性能瓶颈。
使用分布式数据并行更为复杂。首先,你需要使用torchrun命令启动程序而不是python命令,以便正确设置通信基础设施。其次,你的代码需要修改:需要创建一个进程组,需要包装你的模型,并且DataLoader需要一个采样器来在进程间分配数据。最后,由于存在多个进程,模型检查点(checkpointing)应仅在主进程中执行。
考虑前一篇文章中的训练脚本,你需要修改几个部分:
在创建模型之前,你应该初始化进程组。分布式数据并行是PyTorch分布式框架。工作进程的总数称为世界大小(world size)。每个工作进程都有一个唯一的秩(rank),通常从0开始,递增到世界大小减1。一个工作进程应映射到一个不同的GPU设备。由于工作进程可能跨越多台机器,每台机器上的GPU设备ID与秩不对应。因此,本地秩(local rank)用于识别当前机器上的GPU设备。
要初始化进程组,你需要在创建模型之前添加几行代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
...
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# Initialize the distributed environment
dist.init_process_group(backend="nccl")
rank = dist.get_rank()
local_rank = int(os.environ["LOCAL_RANK"])
world_size = dist.get_world_size()
device = torch.device(f"cuda:{local_rank}")
print(f"World size: {world_size}, Rank: {rank}, Local rank: {local_rank}. Using device: {device}")
# Create pretraining model with default config, then wrap it in DDP
model_config = LlamaConfig()
model = LlamaForPretraining(model_config).to(rank)
model = DDP(model, device_ids=[local_rank]) # , output_device=local_rank)
model.train()
|
rank、local_rank和world_size是整数,你稍后会用到它们。你只有在调用init_process_group()后才能获得这些值,并且它们对每个启动的进程都不同。你不需要GPU来运行分布式数据并行,因为PyTorch也支持CPU后端(称为gloo)。然而,只有在GPU上才能看到LLM训练的合理性能。对于Nvidia GPU,应该使用NCCL后端(Nvidia Collective Communication Library)。
请注意,您不应该使用torch.set_default_device()来显式设置默认设备。这是DDP的工作,您不应干预。
当你创建一个模型时,你应该将其发送到你所在的特定秩(rank),然后用DDP包装它。包装后的模型是你应该使用的模型,这样进程间的通信就会在后台发生。
在DDP中,相同的模型被复制到多个GPU上,每个GPU处理不同数据子集。你需要确保你的进程看到正确的数据子集:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
...
from torch.utils.data.distributed import DistributedSampler
# Generator function to create padded sequences of fixed length
class PretrainingDataset(torch.utils.data.Dataset):
def __init__(self, dataset: datasets.Dataset, tokenizer: tokenizers.Tokenizer, seq_length: int):
self.dataset = dataset
self.tokenizer = tokenizer
self.seq_length = seq_length
self.bot = tokenizer.token_to_id("[BOT]")
self.eot = tokenizer.token_to_id("[EOT]")
self.pad = tokenizer.token_to_id("[PAD]")
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
"""Get a sequence of token ids from the dataset. [BOT] and [EOT] tokens
are added. Clipped and padded to the sequence length.
"""
seq = self.dataset[index]["text"]
tokens: list[int] = [self.bot] + self.tokenizer.encode(seq).ids + [self.eot]
# pad to target sequence length
toklen = len(tokens)
if toklen < self.seq_length+1:
pad_length = self.seq_length+1 - toklen
tokens += [self.pad] * pad_length
# return the sequence
x = torch.tensor(tokens[:self.seq_length], dtype=torch.int64)
y = torch.tensor(tokens[1:self.seq_length+1], dtype=torch.int64)
return x, y
batch_size =... [内容被截断]
|
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区