



📢 转载信息
原文链接:http://bair.berkeley.edu/blog/2024/07/20/visual-haystacks/
原文作者:Berkeley AI Research (BAIR)
人类在处理海量的视觉信息方面表现出色,这项技能对于实现人工智能通用智能(AGI)至关重要。几十年来,人工智能研究人员开发了视觉问答(VQA)系统,用于解释单个图像中的场景并回答相关问题。虽然基础模型(foundation models)的最新进展显著缩小了人与机器视觉处理之间的差距,但传统的VQA仅限于一次只推理单个图像,而不是整个视觉数据集合。
这种局限性在更复杂的场景中带来了挑战。例如,辨别医学图像集合中的模式、通过卫星图像监测森林砍伐、使用自主导航数据绘制城市变化地图、分析大型艺术收藏品的主题元素,或从零售监控录像中理解消费者行为。每一个这样的场景不仅需要在数百或数千张图像中进行视觉处理,还需要对这些发现进行跨图像处理。为了解决这一差距,本项目专注于“多图像问答”(MIQA)任务,这超出了传统VQA系统的能力范围。

Visual Haystacks: 第一个“以视觉为中心”的“大海捞针”(NIAH)基准,旨在严格评估大型多模态模型(LMM)处理长上下文视觉信息的能力。
如何对MIQA中的VQA模型进行基准测试?
“大海捞针”(NIAH)挑战最近成为基准测试LLM处理包含“长上下文”的海量输入数据(如长文档、视频或数百张图像)能力的最流行范式之一。在此任务中,包含特定问题答案的关键信息(“针”)被嵌入到大量数据(“干草堆”)中。系统随后必须检索相关信息并正确回答问题。
第一个用于视觉推理的NIAH基准是由谷歌在其Gemini-v1.5 技术报告中引入的。在该报告中,他们要求模型从大型视频的单个帧中检索叠加的文本。事实证明,现有模型在此任务上表现良好——主要是因为它们强大的光学字符识别(OCR)检索能力。但如果我们问更多关于视觉的问题呢?模型仍然能表现得一样好吗?
什么是视觉草垛(VHs)基准?
为了评估“以视觉为中心”的长上下文推理能力,我们引入了“视觉草垛”(VHs)基准。这个新基准旨在评估大型多模态模型(LMM)在大型不相关图像集上的视觉检索和推理能力。VHs包含大约1K个二元问答对,每组包含1到10K张图像。与以前专注于文本检索和推理的基准不同,VHs的问题集中在识别特定视觉内容(例如物体)的存在,利用来自COCO数据集的图像和注释。
VHs基准分为两个主要挑战,每个挑战旨在测试模型在响应查询之前准确定位和分析相关图像的能力。我们精心设计了数据集,以确保仅凭猜测或依赖常识推理而无需查看图像无法获得任何优势(即在二元QA任务上产生50%的准确率)。
-
单针挑战(Single-Needle Challenge):在图像“干草堆”中只存在一根“针”图像。问题的措辞是:“对于带有锚定对象的图像,是否存在目标对象?”
-
多针挑战(Multi-Needle Challenge):在图像“干草堆”中存在两到五根“针”图像。问题的措辞是:“对于所有带有锚定对象的图像,它们是否都包含目标对象?”或“对于所有带有锚定对象的图像,是否有任何一个包含目标对象?”
来自VHs的三个重要发现
视觉草垛(VHs)基准揭示了当前大型多模态模型(LMM)在处理大量视觉输入时面临的重大挑战。在我们的实验1中,涵盖单针和多针模式,我们评估了多种开源和专有方法,包括LLaVA-v1.5、GPT-4o、Claude-3 Opus和Gemini-v1.5-pro。此外,我们还包含了一个“字幕”(Captioning)基线,采用两阶段方法,首先使用LLaVA为图像生成字幕,然后使用Llama3根据字幕文本回答问题。以下是三个关键见解:
-
视觉干扰物的困境
在单针设置中,尽管保持了很高的神谕准确率(oracle accuracy),但随着图像数量的增加,性能出现了明显的下降,这种情况在先前的基于文本的Gemini式基准测试中并未出现。这表明现有模型主要在视觉检索方面遇到困难,特别是在存在具有挑战性的视觉干扰物时。此外,必须强调开源LMM(如LLaVA)的限制,由于2K的上下文长度限制,它们最多只能处理三张图像。另一方面,像Gemini-v1.5和GPT-4o这样的专有模型,尽管声称具有扩展的上下文能力,但由于使用API调用时的载荷大小限制,当图像数量超过1K时,经常无法处理请求。
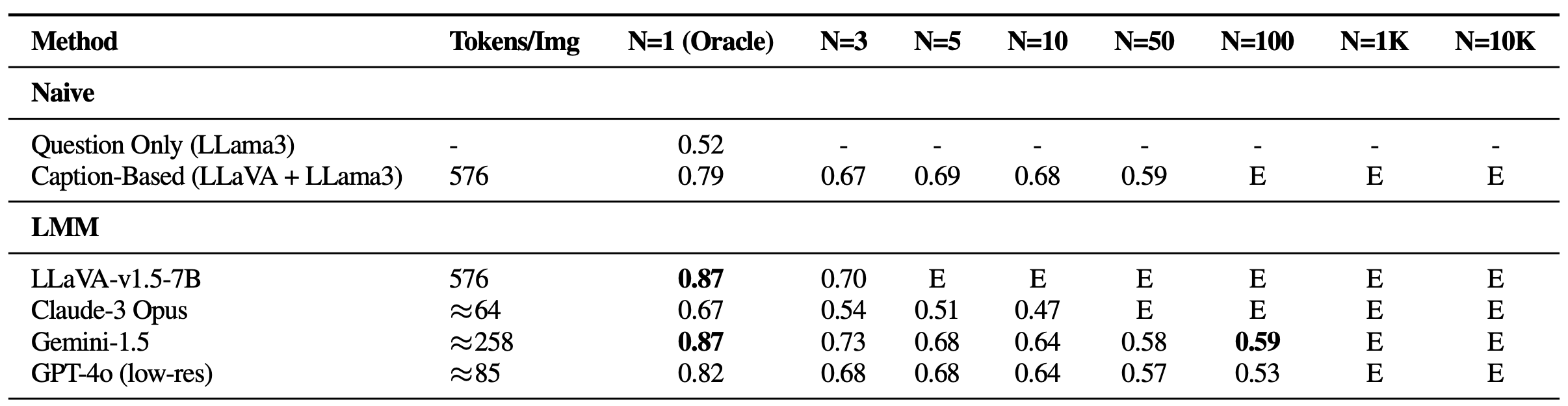
单针问题在VHs上的性能。随着“干草堆”大小(N)的增加,所有模型的性能都急剧下降,表明它们对视觉干扰物都没有鲁棒性。E:超过上下文长度。 -
跨多图像推理的困难
有趣的是,与使用字幕模型(LLaVA)与LLM聚合器(Llama3)链接的基本方法相比,所有基于LMM的方法在单图像QA和所有多针设置中,当图像数量超过5张时,性能都表现较弱。这种差异表明,虽然LLM能够有效地整合长上下文字幕,但现有的基于LMM的解决方案不足以处理和整合跨多个图像的信息。值得注意的是,在多图像场景中性能急剧恶化,Claude-3 Opus在仅使用神谕图像时表现较弱,而Gemini-1.5/GPT-4o在更大的50张图像集合上准确率下降到50%(如同随机猜测)。

多针问题在VHs上的结果。所有具有视觉感知能力的模型表现都不佳,表明模型在隐式整合视觉信息方面存在挑战。 -
视觉领域的现象
最后,我们发现LMM的准确性在很大程度上受到“针”图像在输入序列中位置的影响。例如,当“针”图像紧接着问题放置时,LLaVA表现更好,而在其他情况下,性能下降高达26.5%。相比之下,专有模型在图像位于开头时通常表现更好,而在不位于开头时,性能下降高达28.5%。这种模式与自然语言处理(NLP)领域中出现的“失居中”(lost-in-the-middle)现象相呼应,即位于上下文开头或结尾的关键信息会影响模型性能。这在以前仅要求文本检索和推理的Gemini式NIAH评估中并不明显,凸显了我们的VHs基准带来的独特挑战。
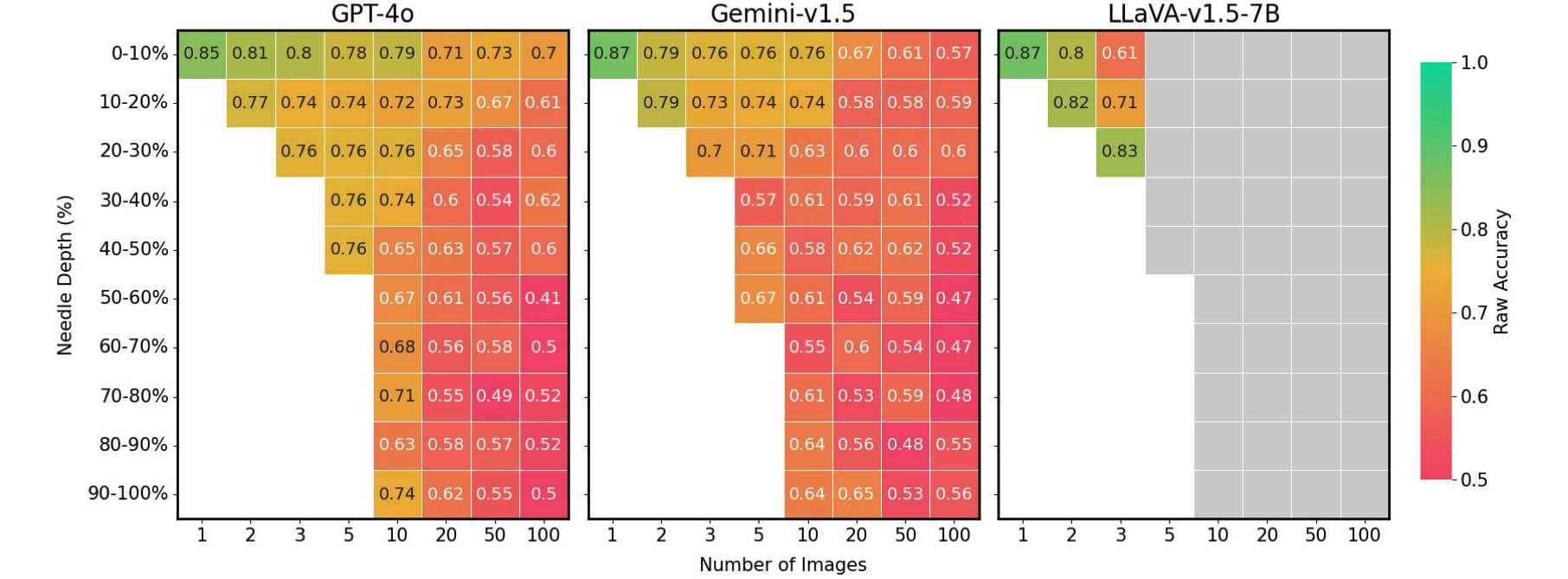
不同图像设置下“针”位置与VHs性能的比较。当“针”没有理想放置时,现有的LMMs显示出高达41%的性能下降。灰色框:超过上下文长度。
MIRAGE:一种基于RAG的改进VHs性能的解决方案
基于上述实验结果,很明显,现有MIQA解决方案的核心挑战在于(1)在不带位置偏差的情况下,能从海量的、可能不相关的图像中准确地检索相关图像的能力,以及(2)整合这些图像中的相关视觉信息以正确回答问题的能力。为了解决这些问题,我们引入了一种开源、简单的单阶段训练范式——“MIRAGE”(多图像检索增强生成),它扩展了LLaVA模型以处理MIQA任务。下图展示了我们的模型架构。
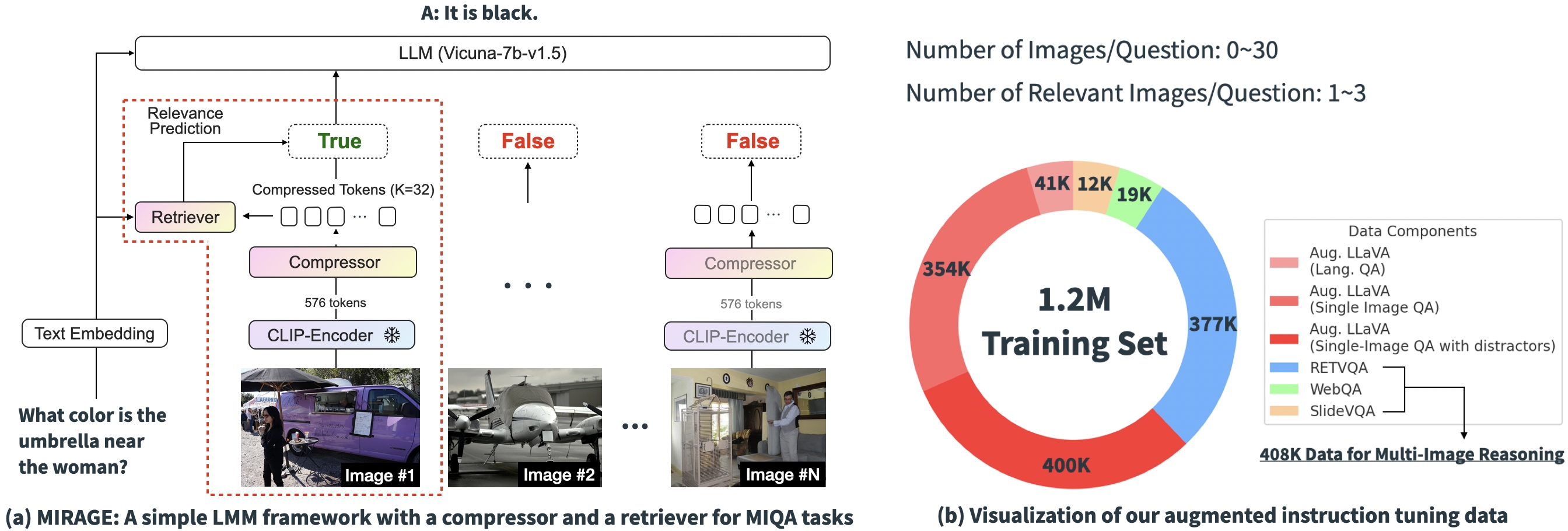
我们提出的范式包含几个组件,每个组件都旨在缓解MIQA任务中的关键问题:
-
压缩现有编码:MIRAGE范式利用一个查询感知压缩模型,将视觉编码器的Token减少到更小的子集(小10倍),从而在相同的上下文长度内容纳更多的图像。
-
采用检索器以过滤掉不相关信息:MIRAGE使用一个与LLM微调联调的检索器,来预测图像是否相关,并动态地丢弃不相关的图像。
-
多图像训练数据:MIRAGE使用多图像推理数据和合成多图像推理数据来增强现有的单图像指令微调数据。
结果
我们使用MIRAGE重新审视VHs基准。除了能够处理1K或10K图像外,MIRAGE在大多数单针任务上实现了最先进的性能,尽管其单图像QA骨干较弱,每个图像只有32个Token!
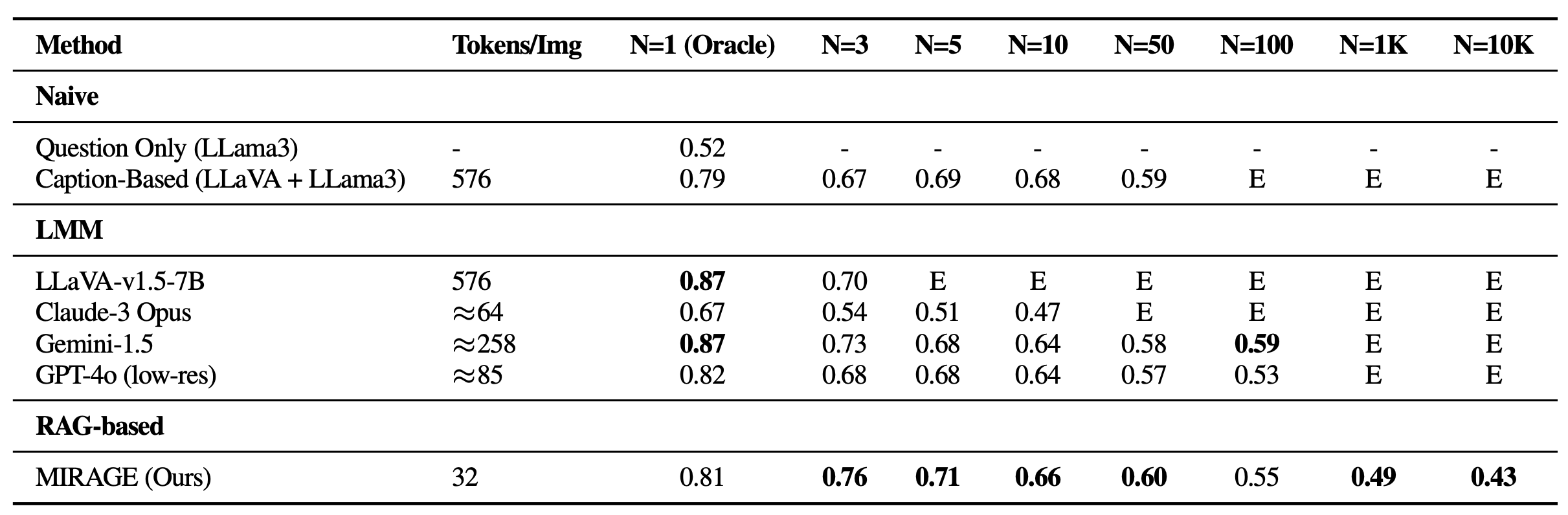
我们还在各种VQA任务上对MIRAGE和其他LMM模型进行了基准测试。在多图像任务上,MIRAGE展示了强大的召回率和准确率能力,显著优于GPT-4、Gemini-v1.5和大型世界模型(LWM)等强劲竞争对手。此外,它在单图像QA性能上也表现出竞争力。
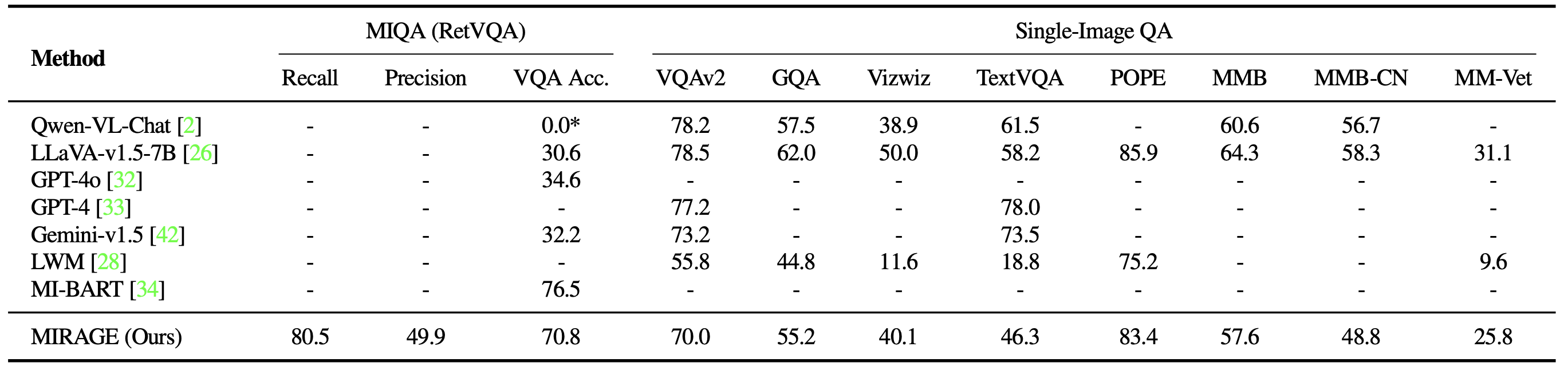
最后,我们将MIRAGE的共同训练检索器与CLIP进行了比较。我们的检索器在不损失效率的情况下,性能明显优于CLIP。这表明,虽然CLIP模型可以作为开放词汇图像检索的良好检索器,但它们在处理类文本的查询时可能效果不佳!
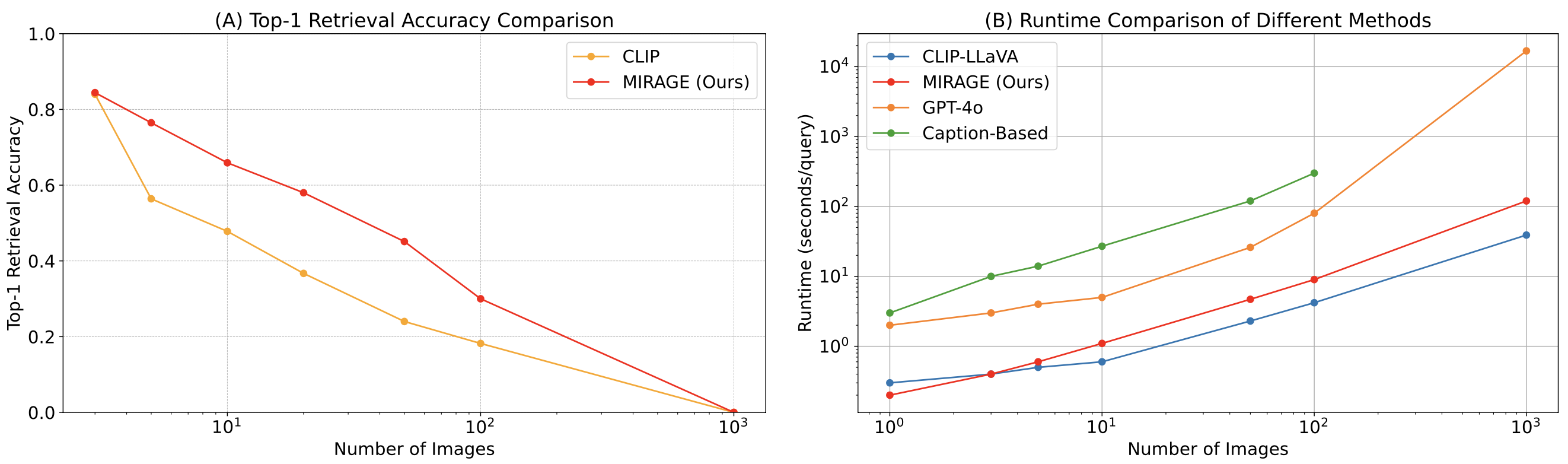
最后总结
在这项工作中,我们开发了视觉草垛(VHs)基准,并确定了现有大型多模态模型(LMM)中存在的三个普遍缺陷:
-
视觉干扰物的困境:在单针任务中,随着图像数量的增加,LMM的性能急剧下降,表明在过滤掉不相关的视觉信息方面存在重大挑战。
-
跨多图像推理的困难:在多针设置中,像先字幕后基于语言的QA这样的简化方法,优于所有现有的LMM,凸显了LMM在处理跨多个图像信息方面的能力不足。
-
视觉领域的现象:专有模型和开源模型都对“针”信息在图像序列中的位置敏感,在视觉领域表现出“失居中”现象。
作为回应,我们提出了MIRAGE,一个开创性的视觉检索增强生成器(visual-RAG)框架。MIRAGE通过创新的视觉Token压缩器、共同训练的检索器以及增强的多图像指令调优数据来解决这些挑战。
在探讨完这篇博客文章后,我们鼓励所有未来的LMM项目使用视觉草垛框架对模型进行基准测试,以便在部署前识别和纠正潜在的缺陷。我们还敦促社区探索多图像问答,以此作为推进真正人工智能通用智能(AGI)前沿的一种手段。
最后,请查看我们的项目页面、arXiv论文,并点击我们的GitHub仓库上的星标按钮!
@article{wu2024visual, title={Visual Haystacks: Answering Harder Questions About Sets of Images}, author={Wu, Tsung-Han and Biamby, Giscard and and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E and Darrell, Trevor and Chan, David M}, journal={arXiv preprint arXiv:2407.13766}, year={2024} } 🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区