



📢 转载信息
原文作者:James Yi, Scott Juang, Thomas Capelle, and Ray Strickland
本文由 Weights & Biases (W&B) 的 Thomas Capelle 和 Ray Strickland 共同撰写。
生成式人工智能 (AI) 在企业中的采用速度正在加快,已经从简单的基础模型交互发展到复杂的代理工作流 (agentic workflows)。随着组织从概念验证转向规模化生产部署,他们需要强大的工具来开发、评估和监控 AI 应用。
在本文中,我们将演示如何使用来自 Amazon Bedrock 的基础模型 (FMs) 和新发布的 Amazon Bedrock AgentCore,结合 W&B Weave,来帮助构建、评估和监控企业级 AI 解决方案。我们将涵盖完整的开发生命周期,从跟踪单个 FM 调用到在生产环境中监控复杂的代理工作流。
W&B Weave 概述
Weights & Biases (W&B) 是一个 AI 开发者系统,为所有规模的企业提供全面的工具,用于模型训练、微调以及利用基础模型。
W&B Weave 提供了一个统一的开发者工具集,以支持您代理式 AI 工作流的每个阶段。它实现了以下功能:
- 跟踪与监控: 跟踪大语言模型 (LLM) 调用和应用逻辑,以便调试和分析生产系统。
- 系统化迭代: 精炼和迭代提示词 (prompts)、数据集和模型。
- 实验: 在 LLM Playground 中试验不同的模型和提示词。
- 评估: 使用内置或自定义评分器以及我们的比较工具,系统地评估和增强应用性能。收集用户和专家的反馈以进行真实世界的测试和评估。
- 护栏 (Guardrails): 通过内容适中性、提示词安全性等方面提供保护。可以使用自定义或第三方护栏(包括 Amazon Bedrock Guardrails)或 W&B Weave 的原生护栏。
W&B Weave 可以由 Weights & Biases 在多租户或单租户环境中完全托管,也可以直接部署在客户的 Amazon Virtual Private Cloud (VPC) 中。此外,W&B Weave 集成到 W&B 开发平台中,为组织在模型训练/微调工作流和代理式 AI 工作流之间提供无缝集成的体验。
要开始使用,请通过 AWS Marketplace 订阅 Weights & Biases AI Development Platform。个人和学术团队可以免费订阅 W&B。
使用 W&B Weave SDK 跟踪 Amazon Bedrock FM
W&B Weave 通过 Python 和 TypeScript SDK 与 Amazon Bedrock 无缝集成。安装库并修补 (patch) 您的 Bedrock 客户端后,W&B Weave 会自动跟踪 LLM 调用:
!pip install weave
import weave
import boto3
import json
from weave.integrations.bedrock.bedrock_sdk import patch_client
weave.init("my_bedrock_app") # 创建并修补 Bedrock 客户端
client = boto3.client("bedrock-runtime")
patch_client(client) # 像往常一样使用客户端
response = client.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{"role": "user", "content": "What is the capital of France?"}
]
}),
contentType='application/json',
accept='application/json'
)
response_dict = json.loads(response.get('body').read())
print(response_dict["content"][0]["text"])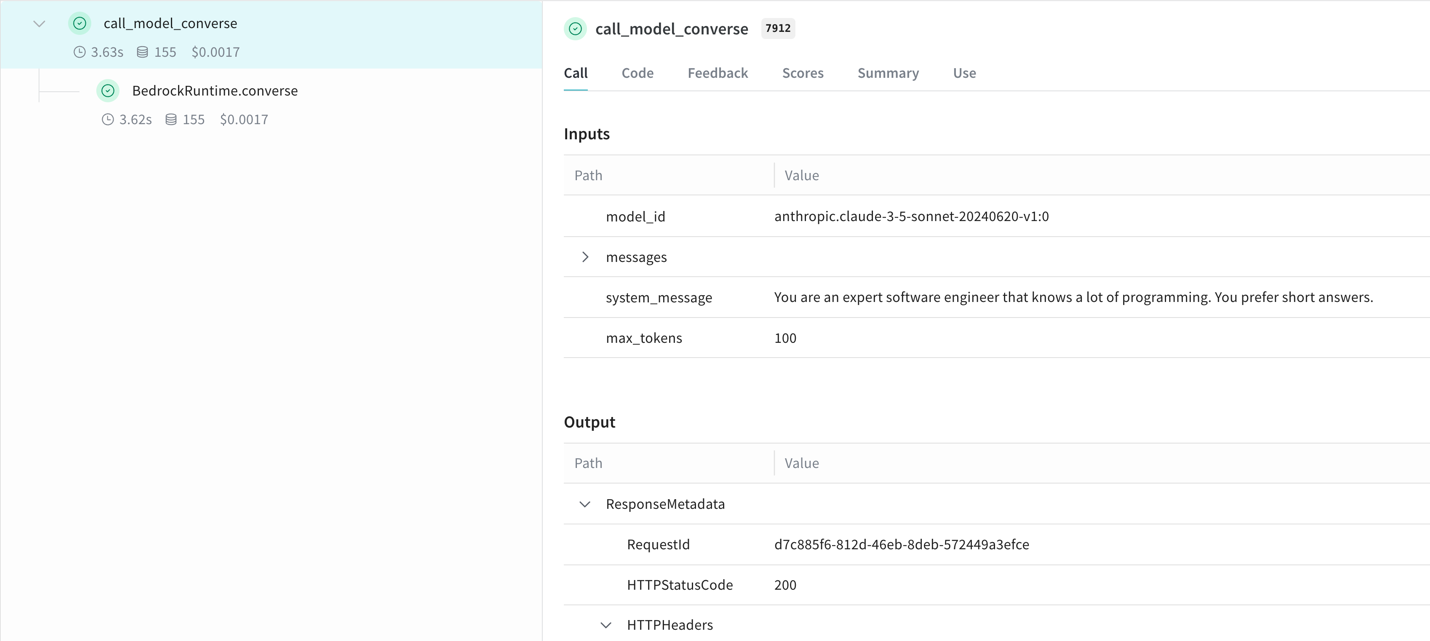
此集成自动对实验进行版本控制并跟踪配置,无需修改核心逻辑即可为您的 Amazon Bedrock 应用提供完整的可见性。
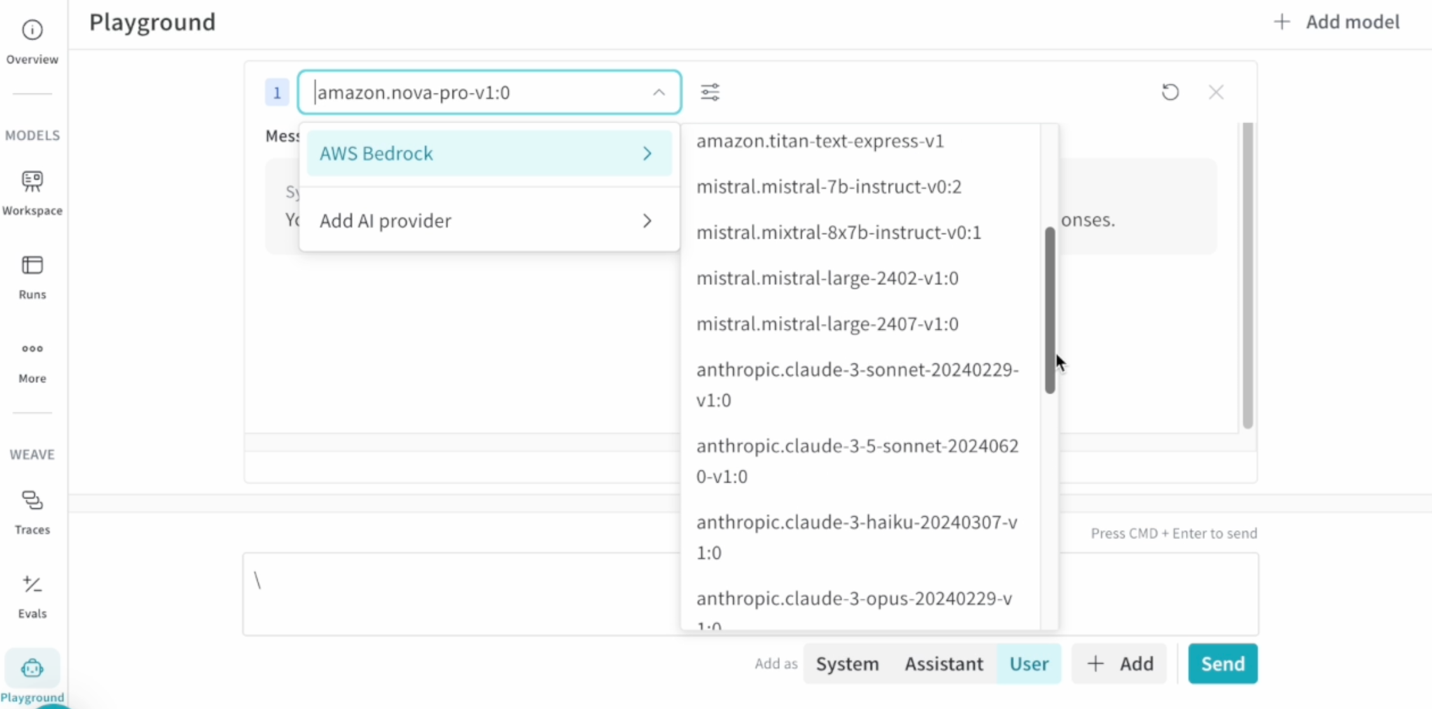
在 W&B Weave Playground 中试验 Amazon Bedrock FM
W&B Weave Playground 提供了一个直观的界面,用于测试和比较 Bedrock 模型,从而加速提示词工程。主要功能包括:
- 直接编辑提示词和重试消息
- 并排模型比较
- 从跟踪视图访问以快速迭代
要开始,请在 Playground 设置中添加您的 AWS 凭证,选择您首选的 Amazon Bedrock FM,然后开始试验。该界面支持快速迭代提示词,同时保持实验跟踪的完整性。
使用 W&B Weave Evaluations 评估 Amazon Bedrock FM
W&B Weave Evaluations 提供了用于有效评估生成式 AI 模型的专用工具。通过将 W&B Weave Evaluations 与 Amazon Bedrock 结合使用,用户可以高效地评估这些模型,分析输出,并根据关键指标可视化性能。用户可以使用 W&B Weave 内置的评分器、第三方或自定义评分器以及人工/专家反馈。这种组合有助于更深入地了解模型之间的权衡,例如成本、准确性、速度和输出质量的差异。
W&B Weave 有一种一流的方式来使用 Model 和 Evaluation 类来跟踪评估。要设置评估作业,客户可以:
- 定义一个 数据集 或字典列表,其中包含要评估的示例集合
- 创建一个评分函数列表。每个函数应接受模型输出和一个可选的示例输入,并返回一个包含分数的字典
- 使用 Model 类定义一个 Amazon Bedrock 模型
- 通过调用 Evaluation 来评估此模型
以下是设置评估作业的示例:
import weave
from weave import Evaluation
import asyncio
# 收集您的示例
examples = [
{"question": "What is the capital of France?", "expected": "Paris"},
{"question": "Who wrote 'To Kill a Mockingbird'?", "expected": "Harper Lee"},
{"question": "What is the square root of 64?", "expected": "8"},
]
# 定义任何自定义评分函数
@weave.op()
def match_score1(expected: str, output: dict) -> dict:
# 在这里定义对模型输出进行评分的逻辑
return {'match': expected == model_output['generated_text']}
@weave.op()
def function_to_evaluate(question: str):
# 在这里添加您的 LLM 调用并返回输出
return {'generated_text': 'Paris'}
# 使用评分函数对您的示例进行评分
evaluation = Evaluation(
dataset=examples,
scorers=[match_score1]
)
# 开始跟踪评估
weave.init('intro-example')
# 运行评估
asyncio.run(evaluation.evaluate(function_to_evaluate))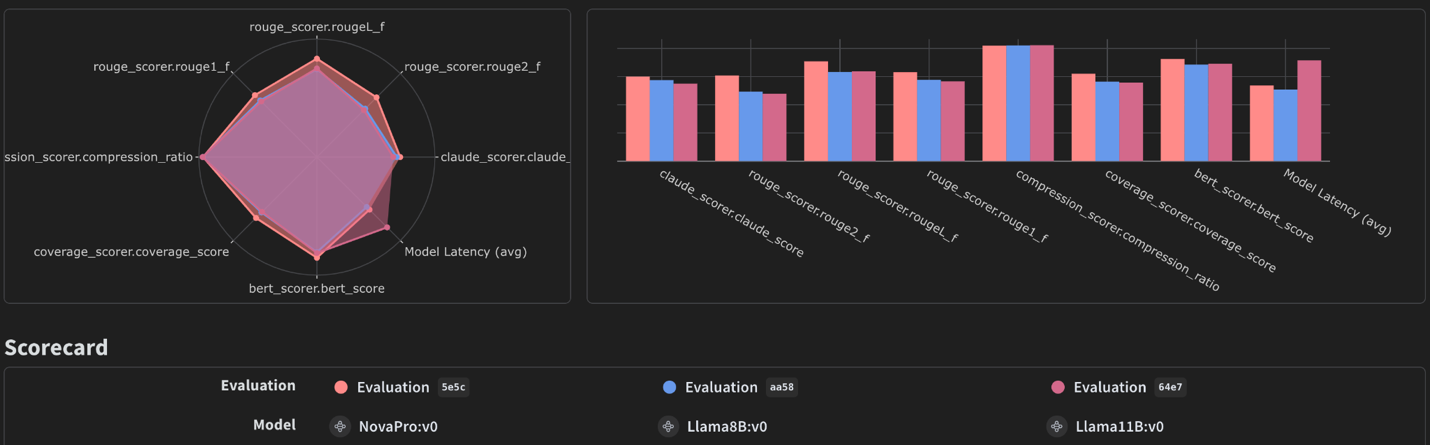
评估仪表板可视化了性能指标,有助于对模型选择和配置做出明智的决定。有关详细指南,请参阅我们关于使用 W&B Weave 评估 Amazon Bedrock 上的 LLM 进行文本摘要的先前帖子:evaluating LLM summarization with Amazon Bedrock and Weave。
使用 W&B Weave 增强 Amazon Bedrock AgentCore 的可观察性
Amazon Bedrock AgentCore 是一套完整的服务,用于在企业规模上更安全地部署和运行高能力的代理。它提供更安全的工作环境、工作流执行工具和操作控制,这些工具与 Strands Agents、CrewAI、LangGraph 和 LlamaIndex 等流行框架以及许多 LLM 模型(无论来自 Amazon Bedrock 还是外部来源)协同工作。
AgentCore 通过 Amazon CloudWatch 仪表板提供内置的可观察性,用于跟踪令牌使用量、延迟、会话持续时间和错误率等关键指标。它还跟踪工作流步骤,显示调用了哪些工具以及模型的响应方式,为生产中的调试和质量保证提供了必要的可见性。
当 AgentCore 和 W&B Weave 协同工作时,团队可以在使用 AgentCore 的内置操作监控和安全基础的同时,如果符合其现有开发工作流,也可以使用 W&B Weave。已经投入到 W&B 环境中的组织可能会选择将 W&B Weave 的可视化工具与 AgentCore 的原生功能相结合。这种方法为团队提供了灵活性,可以在开发链接多个工具和推理步骤的复杂代理时,采用最适合其既定流程和偏好的可观察性解决方案。
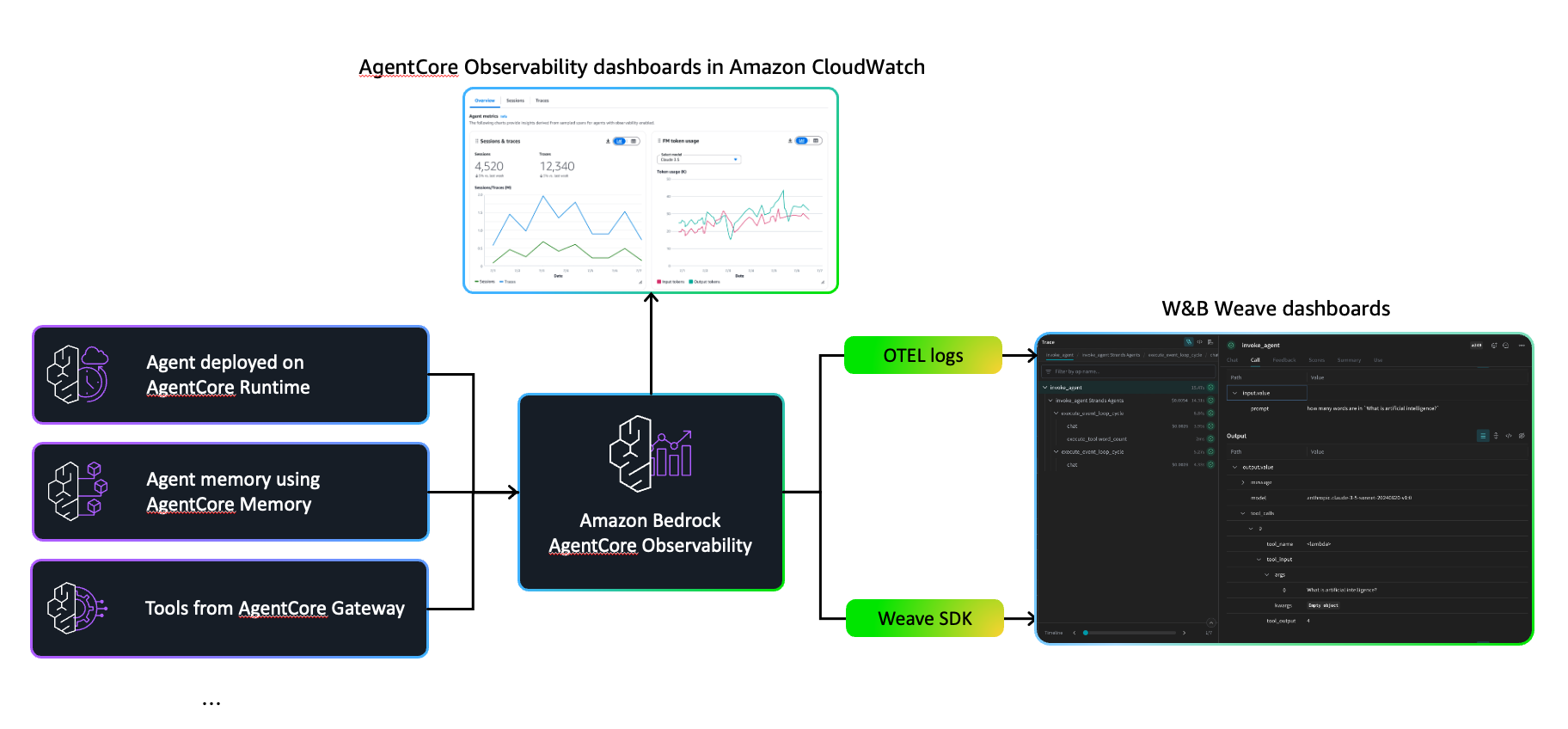
将 W&B Weave 可观察性添加到 AgentCore 代理有两种主要方法:使用原生的 W&B Weave SDK 或通过 OpenTelemetry 集成。
原生 W&B Weave SDK
最简单的方法是使用 W&B Weave 的 @weave.op 装饰器来自动跟踪函数调用。使用您的项目名称初始化 W&B Weave 并包装您想要监控的函数:
import weave
import os
os.environ["WANDB_API_KEY"] = "your_api_key"
weave.init("your_project_name")
@weave.op()
def word_count_op(text: str) -> int:
return len(text.split())
@weave.op()
def run_agent(agent: Agent, user_message: str) -> Dict[str, Any]:
result = agent(user_message)
return {"message": result.message, "model": agent.model.config["model_id"]}
由于 AgentCore 运行在 Docker 容器中,请将 W&B Weave 添加到您的依赖项中(例如,使用 uv add weave),以便将其包含在容器镜像中。
OpenTelemetry 集成
对于已经使用 OpenTelemetry 或希望使用厂商中立的检测的团队,W&B Weave 直接支持 OTLP(OpenTelemetry 协议):
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
auth_b64 = base64.b64encode(f"api:{WANDB_API_KEY}".encode()).decode()
exporter = OTLPSpanExporter(
endpoint="https://trace.wandb.ai/otel/v1/traces",
headers={
"Authorization": f"Basic {auth_b64}",
"project_id": WEAVE_PROJECT
}
)
# 创建跨度以跟踪执行
with tracer.start_as_current_span("invoke_agent") as span:
span.set_attribute("input.value", json.dumps({"prompt": user_message}))
result = agent(user_message)
span.set_attribute("output.value", json.dumps({"message": result.message}))
这种方法保持了与 AgentCore 现有 OpenTelemetry 基础设施的兼容性,同时将跟踪路由到 W&B Weave 进行可视化。当同时使用 AgentCore 和 W&B Weave 时,团队在可观察性方面有多种选择。AgentCore 的 CloudWatch 集成监控系统运行状况、资源利用率和错误率,同时为代理推理和工具选择提供跟踪。W&B Weave 提供可视化功能,以团队熟悉的格式展示执行数据。这两种解决方案都提供了代理如何处理信息和做出决策的可见性,使组织能够选择最符合其现有工作流程和偏好的可观察性方法。这种双层方法意味着用户可以:
- 通过 CloudWatch 警报监控生产服务级别协议 (SLA)
- 在 W&B Weave 的跟踪浏览器中调试复杂的代理行为
- 通过详细的执行细分优化令牌使用和延迟
- 跨不同提示词和配置比较代理性能
集成所需的代码更改最少,保留了您现有的 AgentCore 部署,并随着代理复杂性的增加而扩展。无论您是构建简单的工具调用代理还是编排多步工作流,此可观察性堆栈都能提供快速迭代和自信部署所需的洞察力。
有关实施细节和完整的代码示例,请参阅我们 先前的帖子。
结论
在本文中,我们演示了如何通过将 Amazon Bedrock 的 FM 和 AgentCore 与 W&B Weave 的全面可观察性工具包相结合,来构建和优化企业级的代理式 AI 解决方案。我们探讨了 W&B Weave 如何增强 LLM 开发生命周期的每个阶段——从 Playground 中的初始实验到对模型性能的系统评估,再到复杂代理工作流的生产监控。
Amazon Bedrock 和 W&B Weave 之间的集成提供了几项关键功能:
- 使用 W&B Weave SDK,通过最少的代码更改自动跟踪 Amazon Bedrock FM 调用
- 通过 W&B Weave Playground 直观的界面,快速试验提示词和比较模型
- 使用自定义评分函数系统地评估不同的 Amazon Bedrock 模型
- AgentCore 部署的全面可观察性,CloudWatch 指标提供更强大的操作监控,并辅以详细的执行跟踪
要开始使用:
- 通过 AWS Marketplace 申请免费试用或订阅 Weights &Biases AI Development Platform
- 安装 W&B Weave SDK,并遵循我们的代码示例开始跟踪您的 Bedrock FM 调用
- 通过添加您的 AWS 凭证并在 W&B Weave Playground 中测试各种 Amazon Bedrock FM 来试验不同的模型
- 使用 W&B Weave Evaluation 框架设置评估,以系统地比较模型在您特定用例中的性能
- 使用原生 SDK 或 OpenTelemetry 集成,增强您的 AgentCore 代理,添加 W&B Weave 可观察性
从简单的集成开始跟踪您的 Amazon Bedrock 调用,然后随着 AI 应用复杂性的增加,逐步采用更高级的功能。Amazon Bedrock 与 W&B Weave 全面开发工具的结合,为构建、评估和维护规模化的生产级 AI 解决方案奠定了基础。
关于作者
 James Yi 是 AWS 的高级 AI/ML 合作伙伴解决方案架构师。他负责领导 AWS 在新兴技术领域的战略合作伙伴关系,指导工程团队设计和开发生成式 AI 领域的前沿联合解决方案。他使现场和技术团队能够在 AWS 上无缝部署、操作、保护和集成合作伙伴解决方案。James 与业务领导密切合作,定义和执行联合上市 (Go-To-Market) 策略,推动云业务增长。工作之余,他喜欢踢足球、旅行和与家人共度时光。
James Yi 是 AWS 的高级 AI/ML 合作伙伴解决方案架构师。他负责领导 AWS 在新兴技术领域的战略合作伙伴关系,指导工程团队设计和开发生成式 AI 领域的前沿联合解决方案。他使现场和技术团队能够在 AWS 上无缝部署、操作、保护和集成合作伙伴解决方案。James 与业务领导密切合作,定义和执行联合上市 (Go-To-Market) 策略,推动云业务增长。工作之余,他喜欢踢足球、旅行和与家人共度时光。
 Ray Strickland 是 AWS 的高级合作伙伴解决方案架构师,专注于 AI/ML、代理式 AI 和智能文档处理。他通过 AWS 最佳实践帮助合作伙伴部署可扩展的生成式 AI 解决方案,并通过战略合作伙伴赋能计划推动创新。Ray 与多个 AWS 团队合作,加速 AI 采用,并在合作伙伴评估和赋能方面拥有丰富的经验。
Ray Strickland 是 AWS 的高级合作伙伴解决方案架构师,专注于 AI/ML、代理式 AI 和智能文档处理。他通过 AWS 最佳实践帮助合作伙伴部署可扩展的生成式 AI 解决方案,并通过战略合作伙伴赋能计划推动创新。Ray 与多个 AWS 团队合作,加速 AI 采用,并在合作伙伴评估和赋能方面拥有丰富的经验。
 Thomas Capelle 是 Weights & Biases 的机器学习工程师。他负责维护 www.github.com/wandb/examples 仓库的实时更新。他还专注于 MLOPS、W&B 在各个行业的应用以及有趣的深度学习内容。此前,他曾利用深度学习解决太阳能的短期预测问题。他的背景涵盖城市规划、组合优化、交通经济学和应用数学。
Thomas Capelle 是 Weights & Biases 的机器学习工程师。他负责维护 www.github.com/wandb/examples 仓库的实时更新。他还专注于 MLOPS、W&B 在各个行业的应用以及有趣的深度学习内容。此前,他曾利用深度学习解决太阳能的短期预测问题。他的背景涵盖城市规划、组合优化、交通经济学和应用数学。
 Scott Juang 是 Weights & Biases 的联盟总监。在加入 W&B 之前,他曾在 AWS 和 Cloudera 领导多个战略联盟。Scott 学习材料工程,对可再生能源充满热情。
Scott Juang 是 Weights & Biases 的联盟总监。在加入 W&B 之前,他曾在 AWS 和 Cloudera 领导多个战略联盟。Scott 学习材料工程,对可再生能源充满热情。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区