



📢 转载信息
原文作者:Hazim Qudah
去年,AWS 宣布了 Amazon SageMaker Unified Studio 与 Amazon S3 通用存储桶之间的集成。这一功能使得团队能够轻松利用存储在 Amazon S3 中的非结构化数据进行机器学习 (ML) 和数据分析。
在本文中,我们将演示如何通过 Amazon SageMaker Unified Studio 将 S3 存储桶与 Amazon SageMaker Catalog 集成,并微调 Llama 3.2 11B Vision Instruct 模型以实现视觉问答 (VQA)。例如,通过向模型提供票据图像并询问交易日期来获取信息:
我们使用 Amazon SageMaker JumpStart 来调用模型。基础模型在 DocVQA 数据集上表现出的平均归一化编辑距离相似度 (ANLS) 为 85.3%。虽然这是一个不错的基础性能,但针对高精度任务,我们通过微调进行进一步优化。我们将使用 1,000、5,000 和 10,000 张图像的不同规模数据集进行微调,并利用 Amazon SageMaker 无服务器 MLflow 来跟踪实验结果。
架构流程
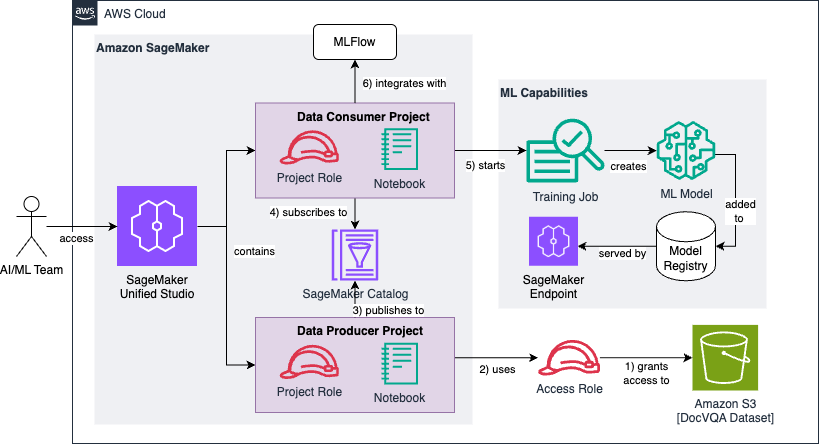
整个流程包含以下六个关键步骤:
- 配置 IAM 角色,授予对存储 DocVQA 数据集的 S3 存储桶的读取权限。
- 数据生产者项目发现并向目录添加数据集。
- 丰富元数据并发布至 SageMaker Catalog。
- 数据消费者项目订阅该数据集。
- 预处理数据并进行多规模模型微调。
- 使用 MLflow 跟踪 ANLS 指标并评估模型。
解决方案指南
首先,我们需要获取数据并同步至 S3。在 SageMaker Unified Studio 的数据生产者项目中,通过“添加 S3 位置”将存储桶挂载到项目目录中。一旦数据可用,即可将其发布到 Catalog,供消费方项目订阅并使用。
在 ML 开发阶段,我们会在 JupyterLab IDE 中加载样本笔记本,通过 AWS CLI 结合 S3 Access Grants 获取临时凭证,并将数据同步到本地环境。转换数据格式后,我们调用 JumpStart 对模型进行训练:
def train(name, instance_type, training_data_path, experiment_name, run):
# 使用 JumpStartEstimator 进行参数化训练
estimator = JumpStartEstimator(
model_id=model_id,
model_version=model_version,
instance_type=instance_type,
# ...
)训练完成后,我们利用 ANLS 指标对结果进行评估,并将所有指标记录在 MLflow 中,从而直观对比不同训练集规模对模型性能的影响。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区