



📢 转载信息
原文作者:Siddharth Gupta, Ishneet Kaur, Mohan Gandhi, Navneet Srivastava, Shubham Mehta, Amit Sinha, Subrat Das, and Vikramank Singh
在海量的临床数据上进行研究和临床分析是极具挑战性的。医疗保健数据科学家和流行病学家在患者护理、疾病模式和临床结果方面拥有深厚的专业知识,但他们往往需要花费数周时间来导航复杂的Amazon SageMaker数据基础设施、编写样板代码并应对技术障碍,才能回答一个临床问题。这减缓了研究进度,并延迟了基于证据的决策,而这些决策可能会影响患者护理。
2025年11月21日,Amazon SageMaker 在 Amazon SageMaker Unified Studio 中引入了一个内置的数据智能体(data agent),彻底改变了大规模数据分析。Amazon SageMaker Data Agent 具有情境感知功能,可以节省跨临床数据库、患者队列和组织元数据连接临床数据的时间,并自主地将复杂的分析请求分解为结构化的、可执行的计划。例如,当您提出一个临床问题:“比较糖尿病和高血压患者队列的合并症模式”时,数据智能体会系统地思考这个问题。它会创建一个多步骤的分析计划,识别相关的临床表,确定适当的统计方法,以最佳语言(SQL、Python 或 PySpark)生成经验证的代码,并对每一步执行进行内置检查,以便进行人工监督。SageMaker Data Agent 旨在遵守现有的客户安全控制和治理策略,通过在客户的组织数据框架内运行,帮助支持客户的合规性要求。
在本文中,我们通过一个流行病学家进行临床队列分析的详细案例研究,展示了 SageMaker Data Agent 如何帮助将数周的数据准备工作缩短为数天,并将数天的分析开发工作缩短为数小时——最终加速从临床问题到研究结论的路径。
加速医疗保健数据分析的关键挑战
实验室、临床环境、学术医疗中心、政府和商业机构中的医疗保健研究会产生大量的临床数据。主要挑战包括:
- 导航复杂的临床数据 – 临床数据目录使用专业的医疗术语和编码系统,需要领域专业知识才能理解。在分析开始之前,查找包含相关患者队列的表以及理解不同分类系统之间的条件代码如何映射,会带来重大的发现挑战。
- 为分析准备技术数据 – 找到数据后,医疗保健分析师会花费大量时间进行密集的编码工作,编写 Python 或 PySpark 脚本来提取患者队列、计算临床指标并执行统计分析。这种技术负担尤为突出,因为临床研究人员通常是流行病学或生物统计学专家,而不是软件工程师。
SageMaker Data Agent 如何加速医疗保健分析
SageMaker Data Agent 为医疗保健专业人员提供了一个基于自然语言的接口来与临床数据交互。它不仅仅是生成代码片段,而是作为一个智能研究助手,努力理解您的特定数据环境和临床目标。它直接解决了上述关键挑战:
- 导航复杂的临床数据 – SageMaker Data Agent 与 AWS Glue Data Catalog 集成,以映射您的整个医疗保健数据环境。该智能体能够识别您的实际临床表——患者人口统计信息、诊断、就诊、状况、药物、免疫接种、程序——根据它们的真实名称和关系来识别,而不是使用通用占位符。它能识别就诊之间的时序关系,理解诊断代码的结构,并在不需要您记住数据库模式的情况下导航复杂的临床数据层次结构。
- 为分析准备技术数据 – 该智能体将自然语言的临床问题转化为生产就绪的分析代码,减少了代码开发时间。它生成优化的代码:用于高效患者队列提取的 SQL、用于统计分析的 Python 以及用于大规模数据处理的 PySpark,并帮助临床研究人员在不需要他们精通每种语言的情况下使用正确的工具。它还会创建一个结构化的、多步骤的分析计划,该计划模仿经验丰富的临床研究人员处理问题的方式:队列定义,然后是基线特征,然后是统计比较,最后是可视化。每一步都包含用户审查数据智能体过程的验证点,这将有助于临床有效性、缺失数据的正确处理以及统计上适当方法的的使用。这种智能体式(agentic)方法将您的时间从技术准备转移到临床解释上。
解决方案概述
在本文中,我们通过一个虚构的示例探讨了 SageMaker Data Agent 如何协助临床研究和分析。在此用例中,一名学术医疗中心的流行病学家通过队列比较和生存分析,对鼻窦炎、糖尿病和高血压等临床状况进行详细分析。他们的传统工作流程涉及在多个不相连的系统中查找数据集、等待访问批准、理解复杂的数据模式以及编写大量的 Python 和 PySpark 代码——这是一个耗时数周的过程,他们的大部分时间都花在了数据准备上,而不是实际的临床分析上。这一瓶颈限制了他们每季度只能进行 2-3 次全面的研究,直接延迟了分析洞察的获取。
借助由 AI 驱动的 SageMaker Data Agent,您可以在登录时看到可访问的数据集,通过快速预览验证数据质量,并使用它通过自然语言提示执行分析——从而减少手动编码工作。SageMaker Data Agent 旨在加速您的研究能力,有助于更早地识别治疗模式。通过将绝大部分时间从数据准备转移到实际分析上,SageMaker Data Agent 帮助您更高效地提供研究结果,同时降低基础设施成本。SageMaker Data Agent 有两种交互模式来帮助您的分析:
- 用于全面临床分析的智能体面板 – 非常适合端到端的研究项目。此模式将复杂的医疗保健问题分解为结构化的分析步骤,并带有中间审查点,在整个过程中保持人工监督。
- 用于重点任务的行内辅助 – 非常适合希望在保持对工作流程的动手控制的同时,获得针对特定编码挑战、错误修复或代码增强的有针对性的帮助的经验丰富的研究人员。
在两种模式下,SageMaker Data Agent 都在您的 AWS 环境内安全运行,遵守 AWS 身份和访问管理 (IAM) 策略和组织数据边界,帮助您在加速临床分析的同时维护安全控制。
在接下来的章节中,我们将介绍使用 SageMaker Data Agent 的过程。
先决条件
我们选择 Synthea 作为工具,用于生成 CSV 格式的合成患者数据,其中包含有关患者、状况、免疫接种、过敏、就诊和程序的数据。Synthea 是一个开源的合成患者生成器(在 Apache 2.0 许可证下分发和使用),它模拟合成患者的病史。本文中不使用任何真实人类数据。
作为 SageMaker 设置的一部分,打开 SageMaker 控制台并选择 开始使用 (Get started) 以创建基于 IAM 的域和名为 ClinicalDataProject 的项目。有关设置基于 IAM 的域和创建项目的说明,请参阅基于 IAM 的域和项目。
使用 SQL 预览临床数据
要使用 SQL 预览数据,请完成以下步骤:
- 在 SageMaker 控制台上,选择 打开 (Open),然后选择您创建的项目(
ClinicalDataProject)。

您将被重定向到 SageMaker Unified Studio 的概览页面。
- 在导航窗格中选择 数据 (Data)。
- 展开
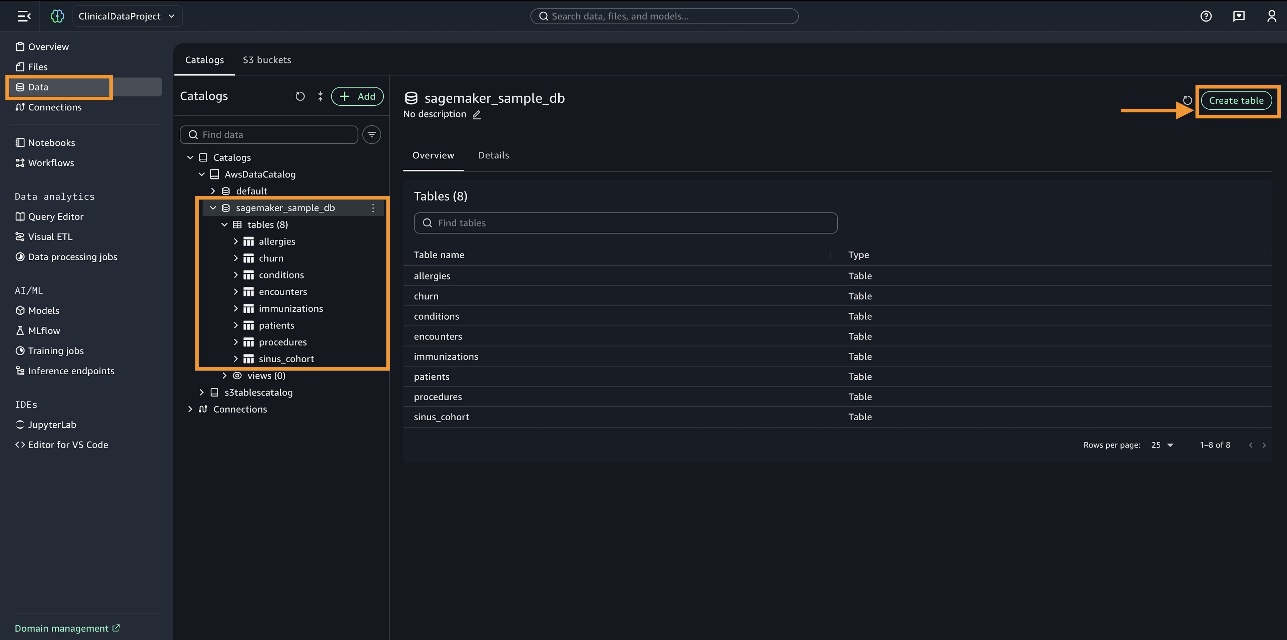
AWSDataCatalog以查看您在帐户中可以访问的预加载和已编目的数据。
对于此用例,通过选择 创建表 (Create table)(如下所示),使用先前生成的 CSV 文件,在 sagemaker_sample_db 下为每个表(patients, conditions, immunizations, allergies, encounters 和 procedures)创建表。
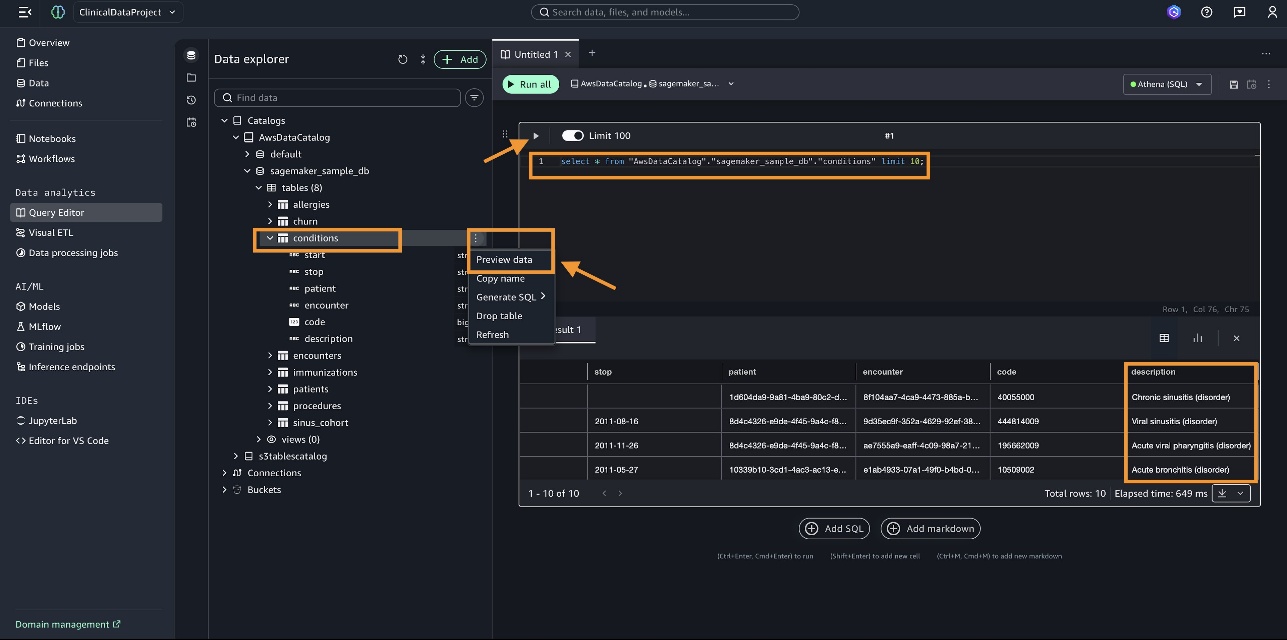
在执行复杂的临床分析之前,让我们对 conditions 表运行一个基本查询。
- 选择
conditions表,然后在选项菜单上选择 预览数据 (Preview data)。 - 执行一个 SQL 操作,例如:
select * from "AwsDataCatalog"."sagemaker_sample_db"."conditions" limit 10
创建笔记本
要执行详细分析,您应该创建一个笔记本。完成以下步骤:
- 在导航窗格中选择 笔记本 (Notebooks)。
- 选择 创建笔记本 (Create notebook)。
与数据交互
创建笔记本后,您可以通过两种方式与数据进行交互:
- 通过使用行内提示界面直接在笔记本单元格中编写代码。例如,输入“Code to find patient records in conditions table who suffer from Sinusitis”(查找
conditions表中患有鼻窦炎的患者记录的代码),选择 生成代码 (Generate code),然后运行单元格以显示结果。 - 使用数据智能体面板,它通过将复杂分析任务分解为结构化步骤来支持全面的分析任务,每个步骤都基于先前结果构建生成的代码。
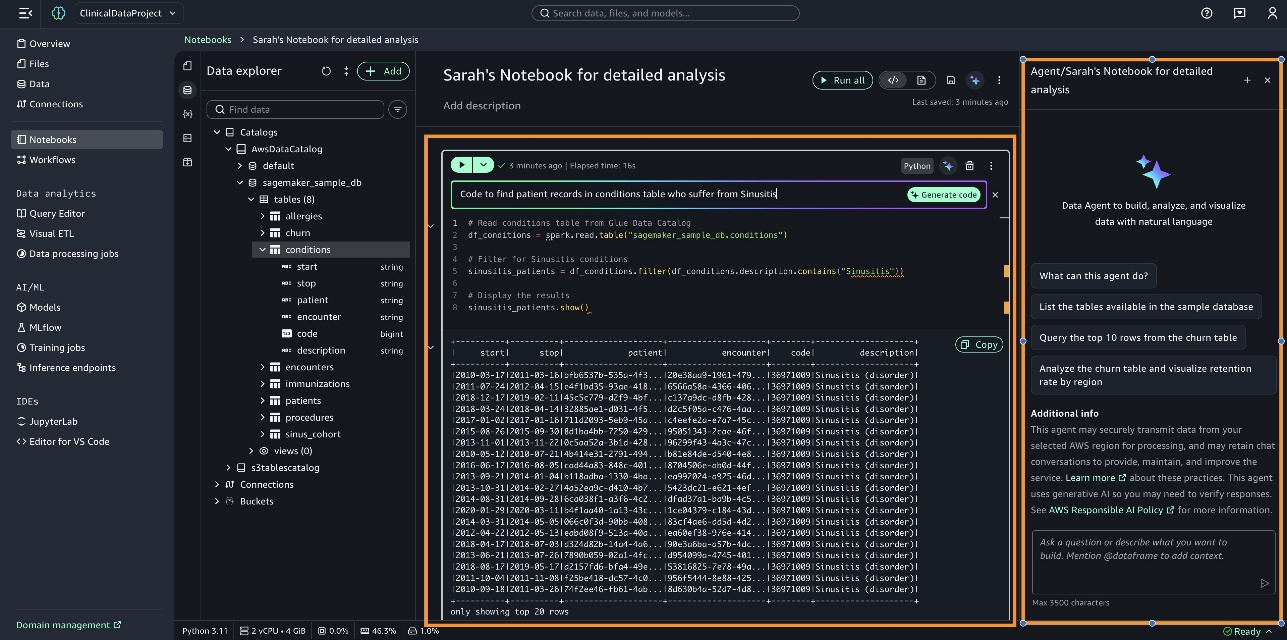
在接下来的部分中,我们提供了使用数据智能体面板的示例。
使用 SageMaker Data Agent 对临床数据进行详细分析
在数据智能体面板中,我们输入查询“查找前 20 大状况,并对患有这些状况并接受过免疫接种的患者进行详细分析”,然后生成代码。
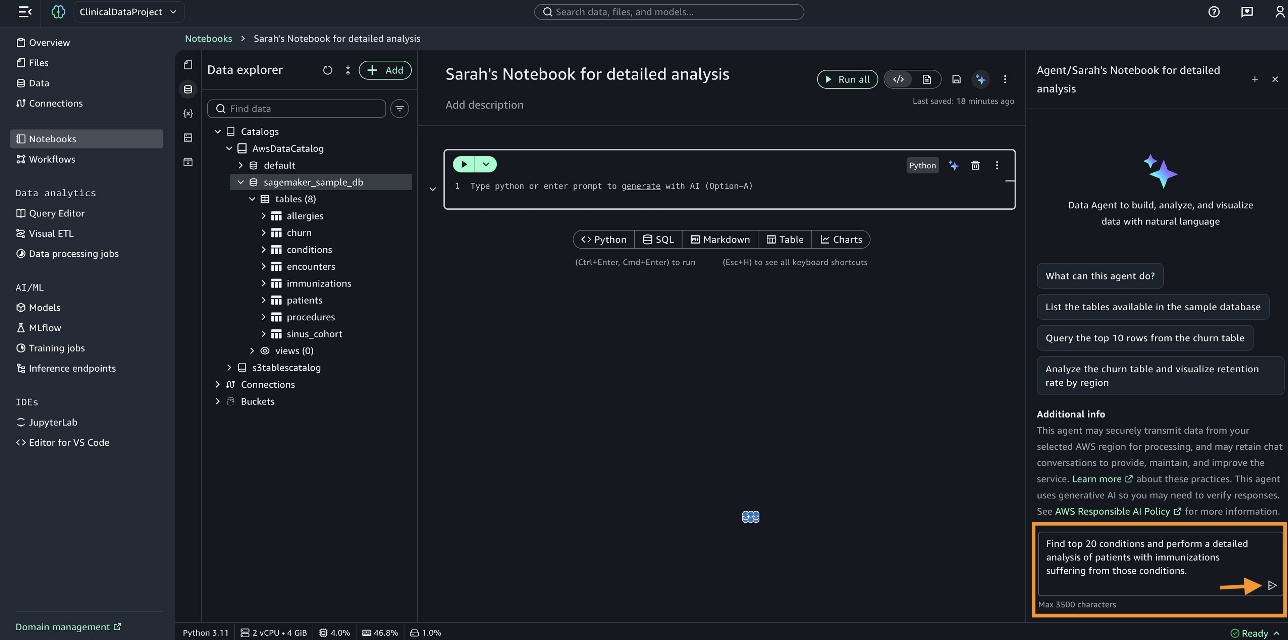
SageMaker Data Agent 会检查笔记本的当前状态以了解我们正在处理的数据。它在 sagemaker_sample_db 数据库中识别出 conditions、immunizations 和 patients 表。它会准备一个全面的计划并列出供您审查。您可以审查计划,如有需要进行必要的更改,然后选择 分步运行 (Run step-by-step)。
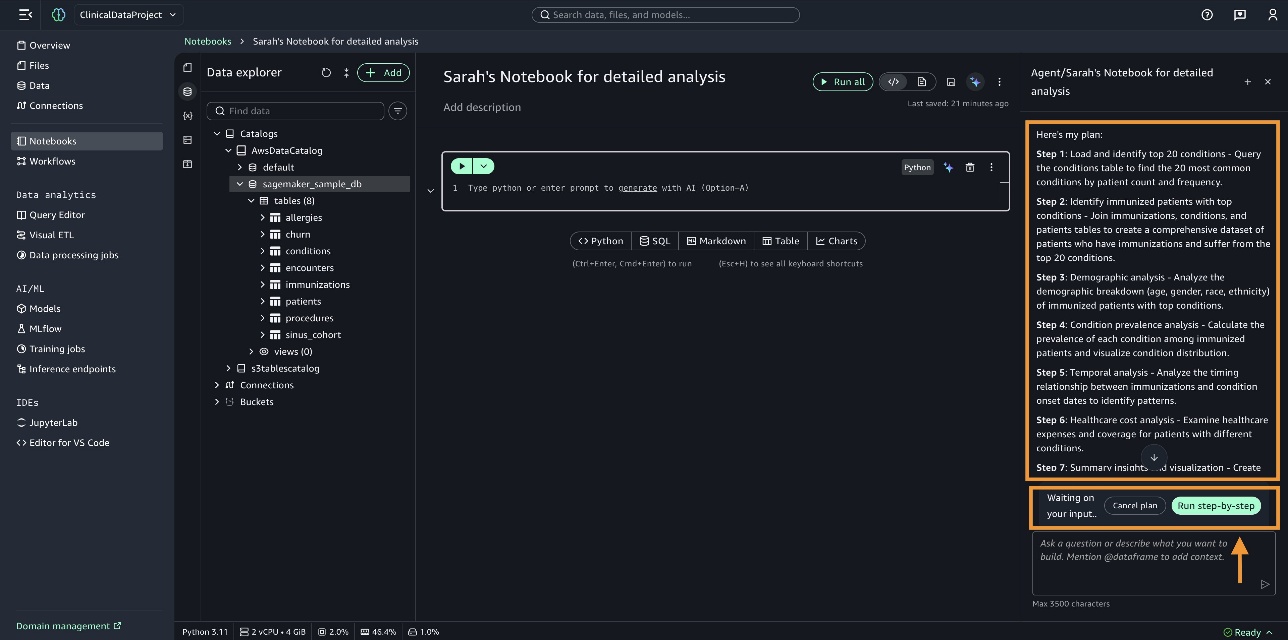
SageMaker Data Agent 将代码写入笔记本单元格中。您可以审查代码,然后选择 接受并运行 (Accept and run)。
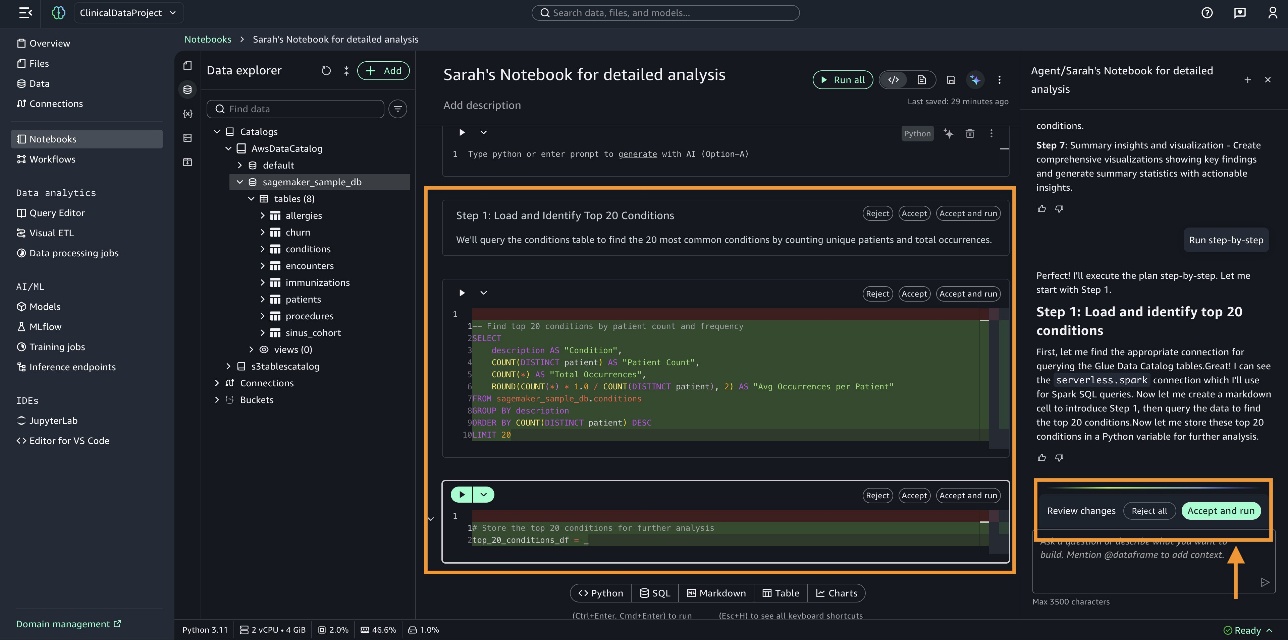
某些步骤可能会执行失败。在这种情况下,您可以选择 用 AI 修复 (Fix with AI) 以继续操作。
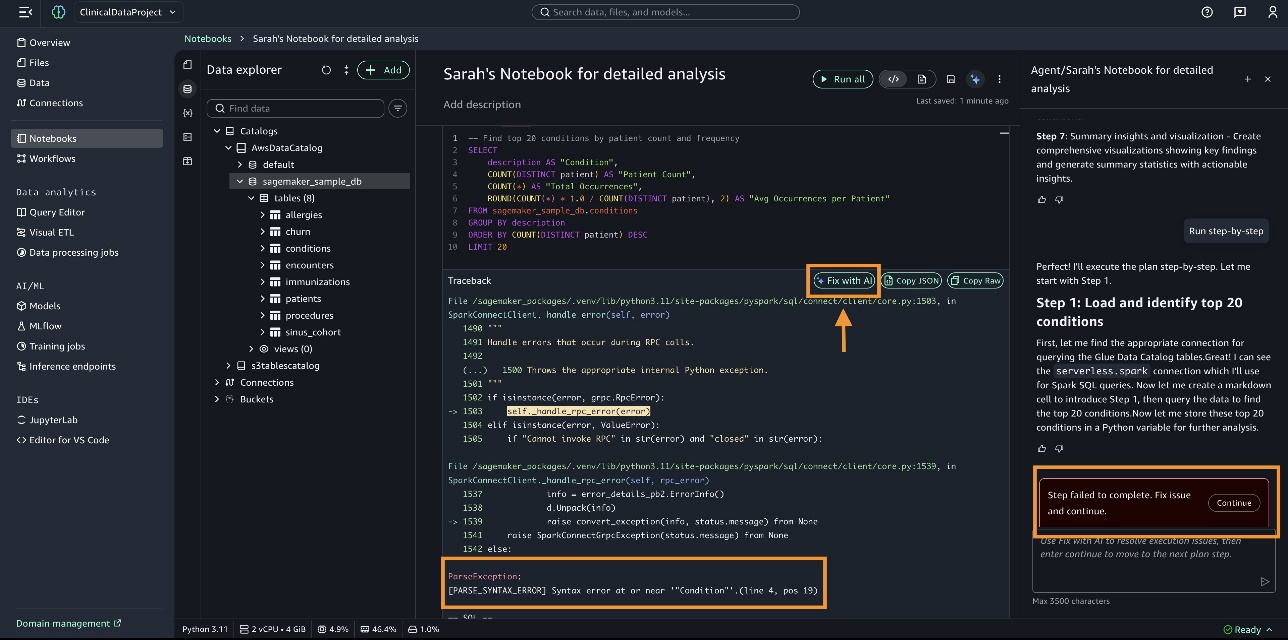
查询完成后,结果将显示出来,如下图所示。
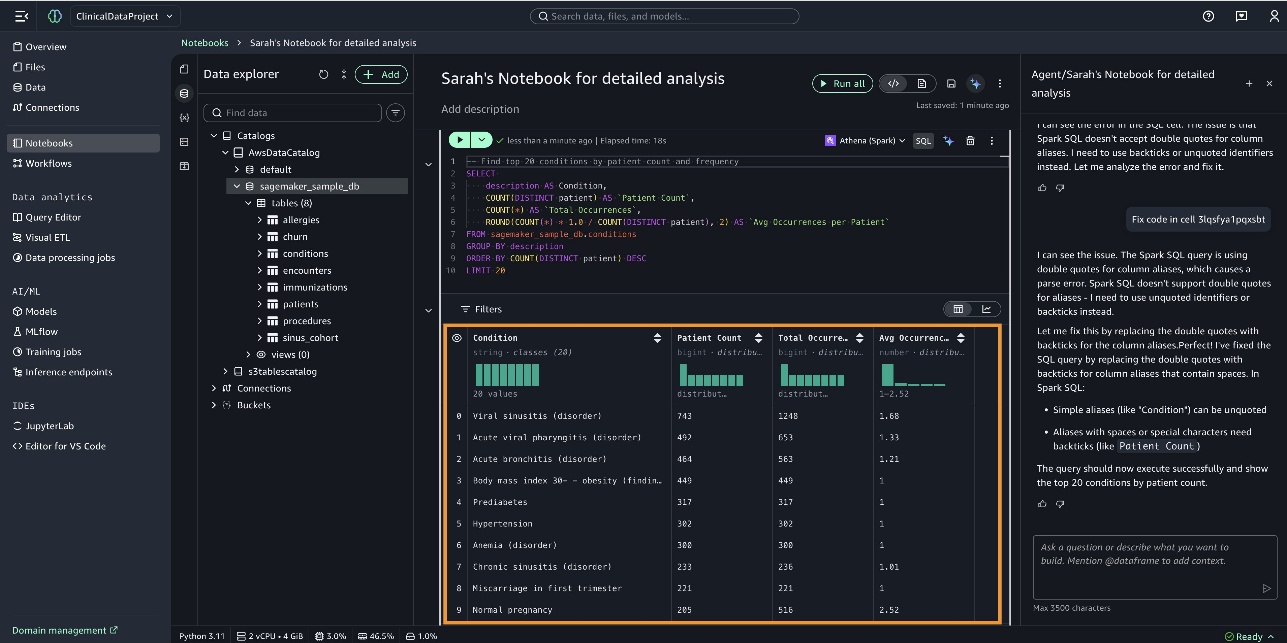
您可以在标题为 患有前 20 种疾病的已免疫患者的人口统计分析 (Demographics Analysis of Immunized Patients with Top 20 Conditions) 的笔记本中,看到 SageMaker Data Agent 创建的条形图,如下一屏幕截图所示。
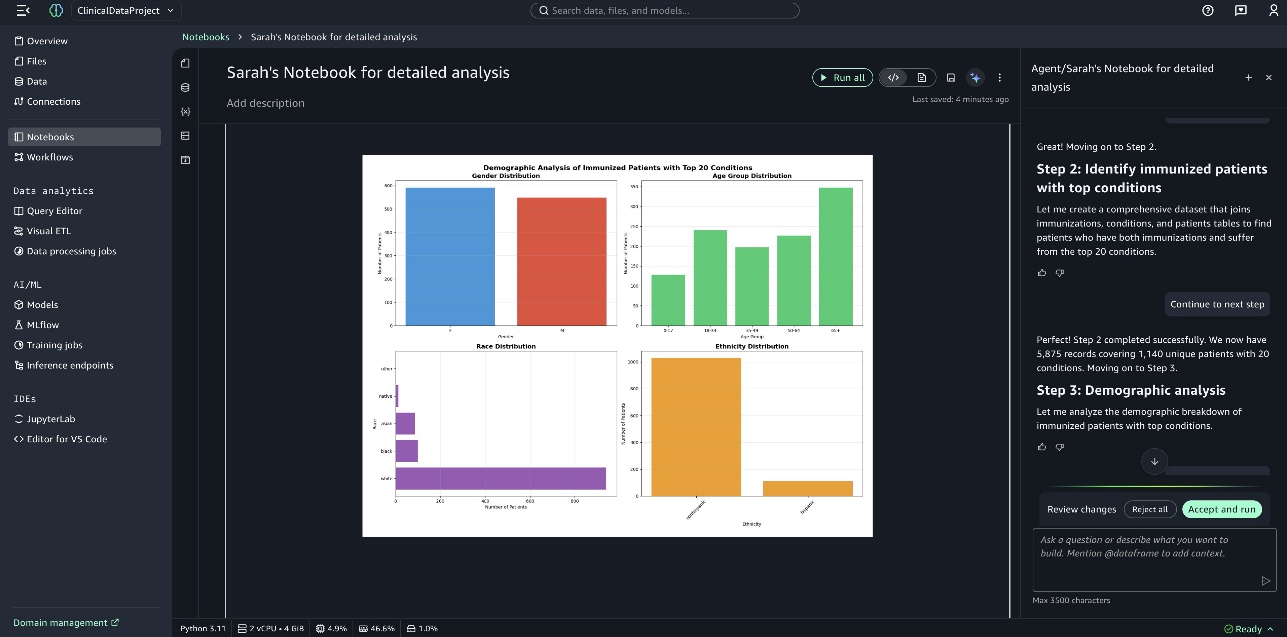
下一张截图显示了 患有前 20 种疾病的已免疫患者的状况患病率分析 (Condition Prevalence Analysis of Immunized Patients with Top 20 Conditions) 图表。
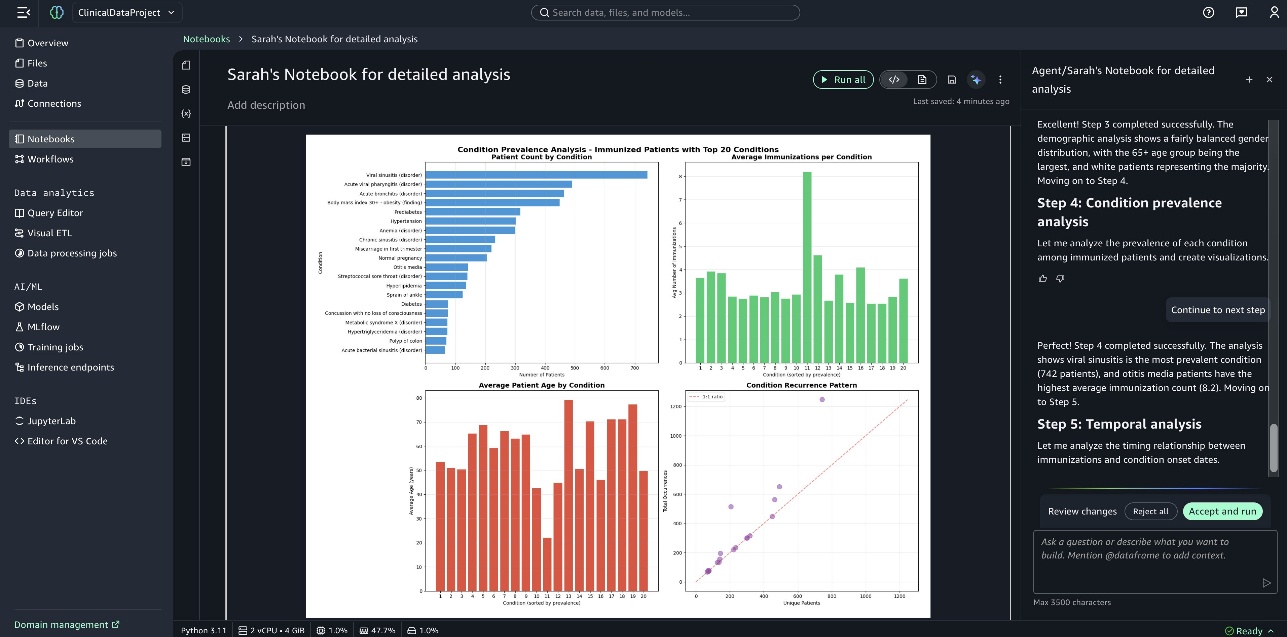
下一张截图显示了 疾病发作时间分析 (Temporal Analysis of Condition Onset)。
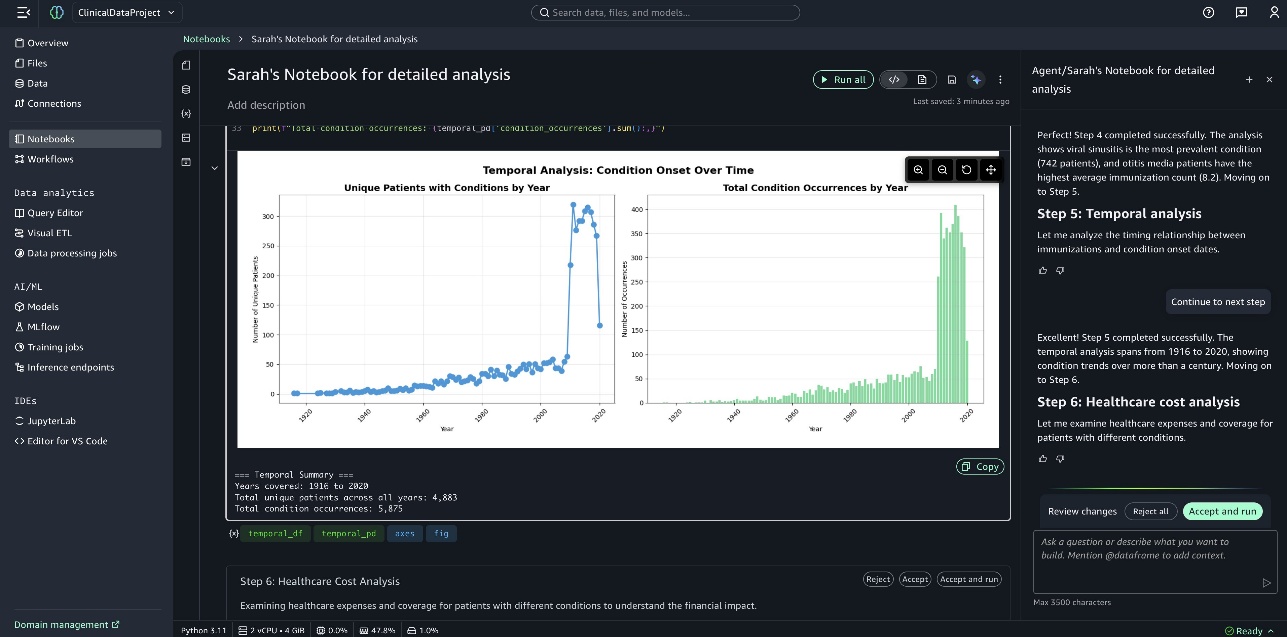
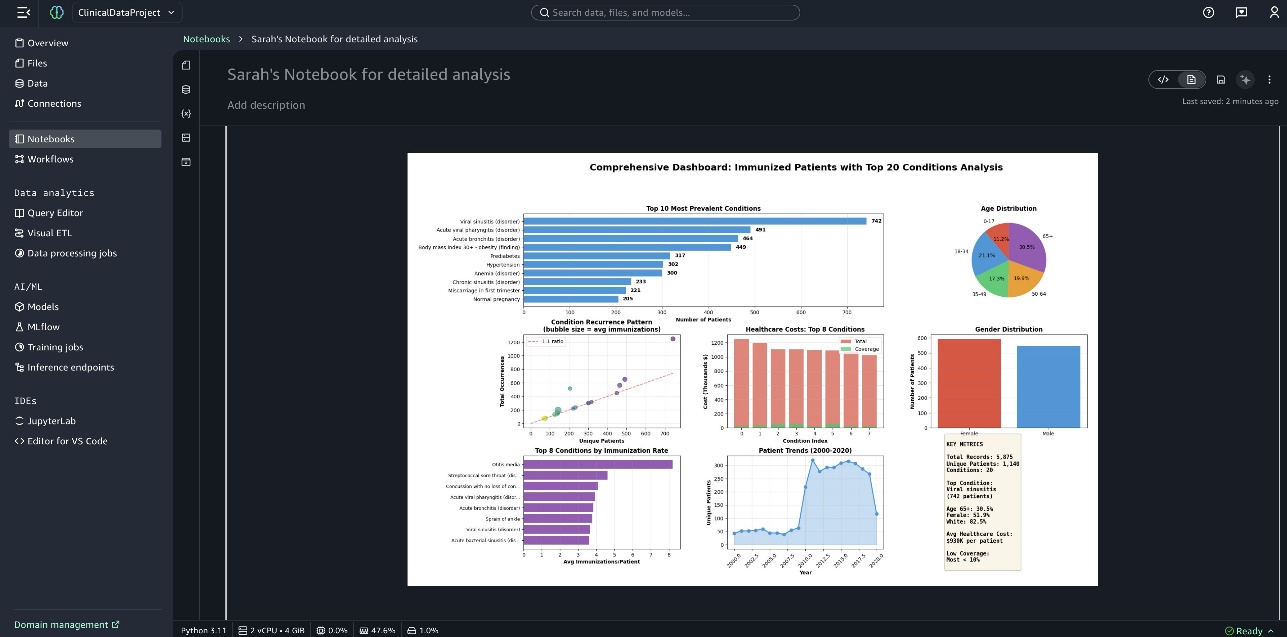
笔记本末尾会显示一个综合仪表板。
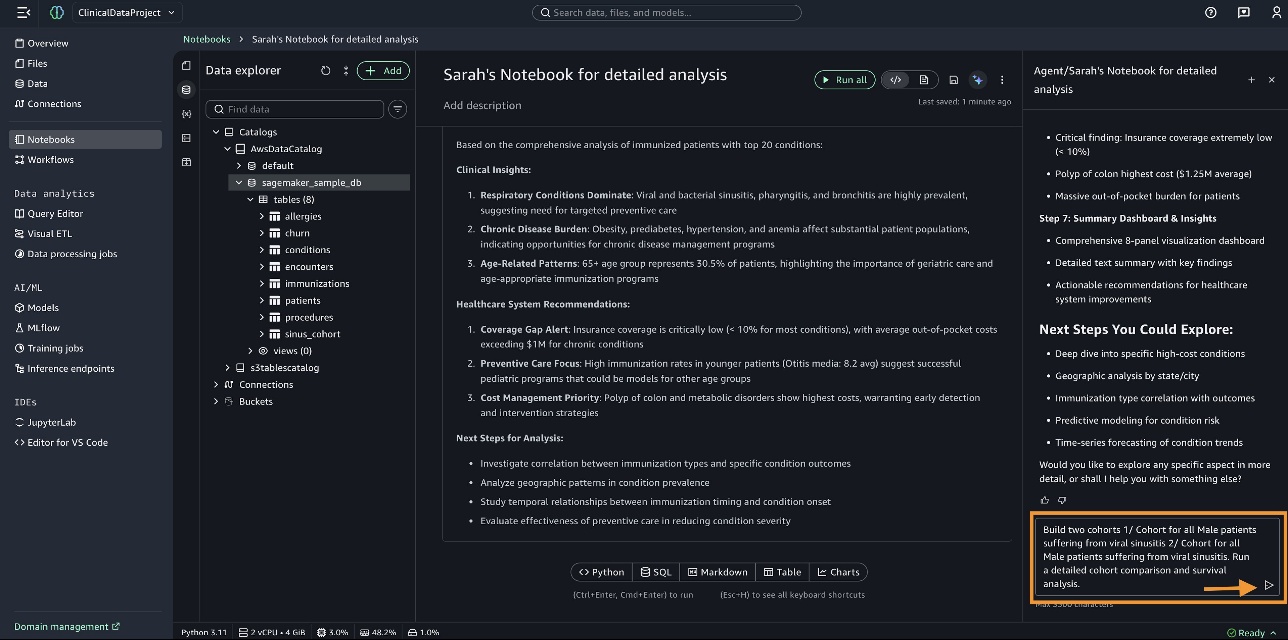
使用 SageMaker Data Agent 进行队列比较和生存分析
病毒性鼻窦炎是患者的头号疾病。为了进行队列比较和生存分析,我们在数据智能体面板中输入以下查询:“构建两个队列:1/ 男性患者患有病毒性鼻窦炎的队列;2/ 女性患者患有病毒性鼻窦炎的队列。运行详细的队列比较和生存分析。”
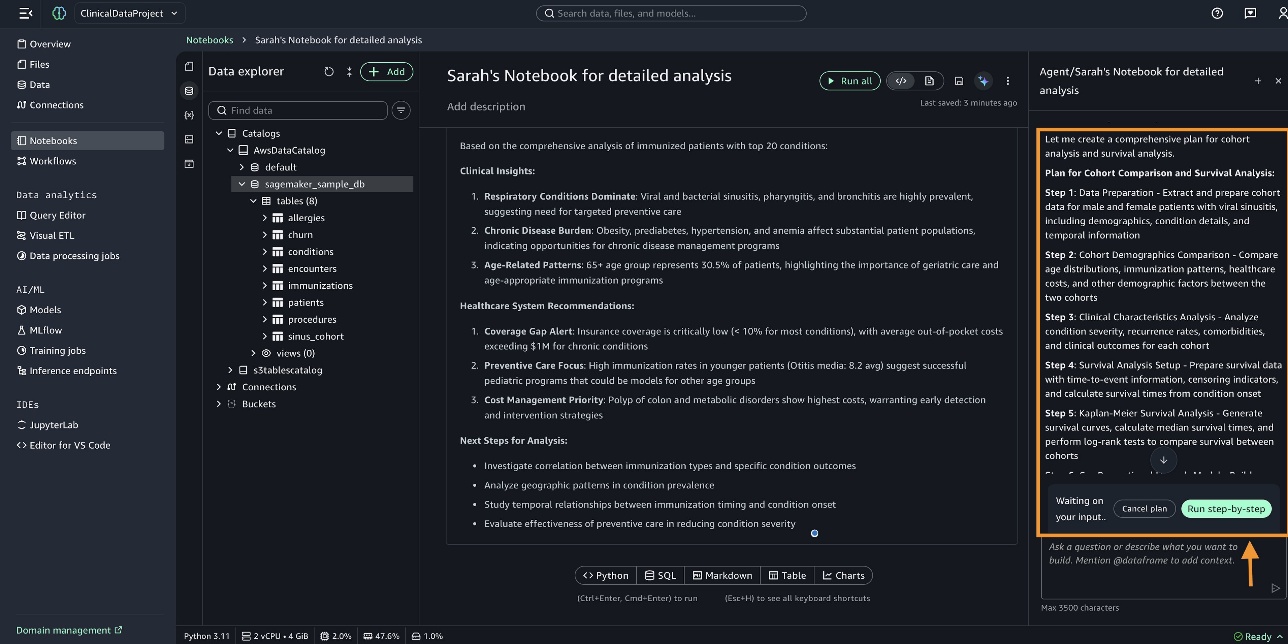
SageMaker Data Agent 为队列创建、队列比较分析和生存分析准备了一个全面的计划。您可以审查计划,然后选择 分步运行 (Run step-by-step)。
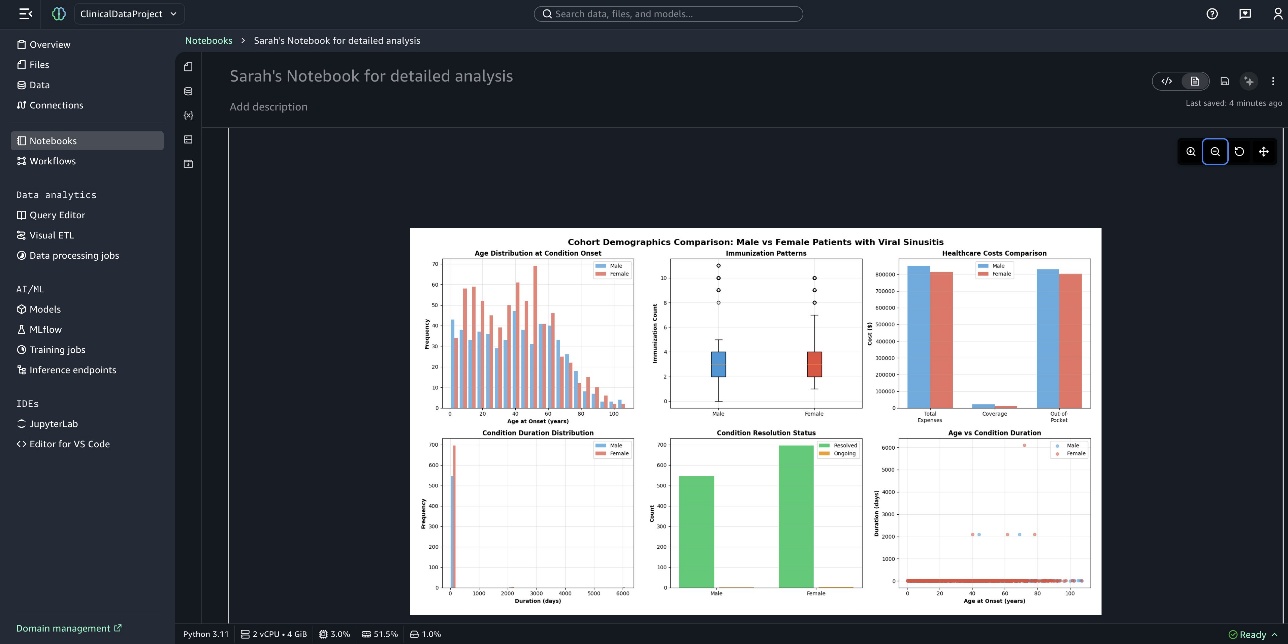
下一张截图显示了图表 队列人口统计学比较:患有病毒性鼻窦炎的男性与女性患者 (Cohort Demographics Comparison: Male vs Female Patients with Viral Sinusitis)。
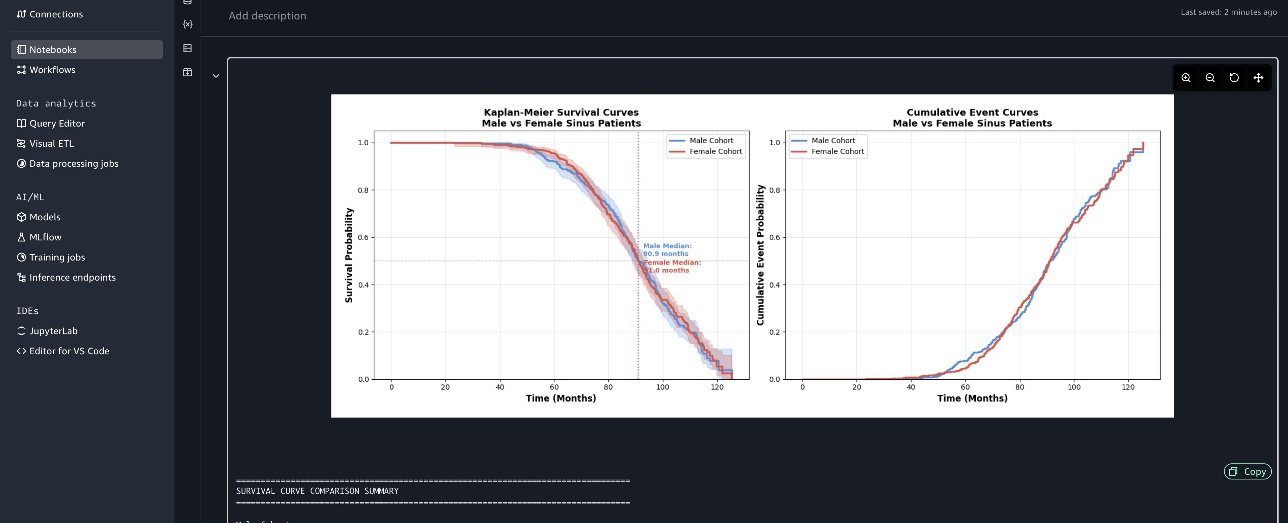
下一张截图显示了 Kaplan-Meier 生存曲线和累积事件曲线。
清理资源
要删除本演练中创建的 AWS 资源,请完成以下步骤。首先,通过导航到 Amazon SageMaker Unified Studio 控制台,从项目列表中选择您的项目,选择 删除 (Delete) 并确认删除,来删除 SageMaker Unified Studio 项目。这将删除所有相关的笔记本、数据连接和项目资源。其次,通过打开 AWS Glue 控制台,导航到“数据库”并删除本演练创建的示例数据库,来移除 AWS Glue Data Catalog 资源。第三,通过打开 Amazon S3 控制台,找到存储医疗保健数据的位置,清空存储桶内容,然后删除该存储桶,来删除 S3 存储桶和数据。
结论
在本文中,我们演示了 SageMaker Data Agent 如何提高数据分析工作速度,帮助您提取有影响力的数据见解。SageMaker Data Agent 有助于减少花在数据管理上的时间,以便您可以将更多时间用于识别治疗模式和提供循证建议。通过通过自然语言交互简化对复杂数据分析的访问,SageMaker Data Agent 可以帮助您在降低基础设施成本的同时提高研究能力。分析记录在可重现的笔记本中,这些笔记本可以由临床利益相关者进行验证和审计,从而支持透明度,同时加速从数据到有影响力的分析的路径。
作者简介
 Siddharth 领导 SageMaker 统一体验中的生成式 AI 工作。他的重点是推动智能体式体验,即 AI 系统自主代表用户执行复杂任务。他毕业于伊利诺伊大学厄巴纳-香槟分校,曾在雅虎、Glassdoor 和 Twitch 等公司担任职务,拥有丰富的经验。
Siddharth 领导 SageMaker 统一体验中的生成式 AI 工作。他的重点是推动智能体式体验,即 AI 系统自主代表用户执行复杂任务。他毕业于伊利诺伊大学厄巴纳-香槟分校,曾在雅虎、Glassdoor 和 Twitch 等公司担任职务,拥有丰富的经验。
 Navneet Srivastava 是一位首席专家和分析策略负责人,致力于为大型生物制药、医疗保健和生命科学组织构建端到端分析战略的战略计划。他的专业知识涵盖数据分析、数据治理、AI、ML、大数据和医疗保健相关技术。
Navneet Srivastava 是一位首席专家和分析策略负责人,致力于为大型生物制药、医疗保健和生命科学组织构建端到端分析战略的战略计划。他的专业知识涵盖数据分析、数据治理、AI、ML、大数据和医疗保健相关技术。
 Subrat Das 是一位首席解决方案架构师,隶属于 AWS 全球医疗保健和生命科学行业部门。他对现代化和架构复杂的客户工作负载充满热情。当他不从事技术解决方案工作时,他喜欢长途徒步旅行和环游世界。
Subrat Das 是一位首席解决方案架构师,隶属于 AWS 全球医疗保健和生命科学行业部门。他对现代化和架构复杂的客户工作负载充满热情。当他不从事技术解决方案工作时,他喜欢长途徒步旅行和环游世界。
 Ishneet Kaur 是 Amazon SageMaker 统一 Studio 团队的软件开发经理。她领导工程团队设计和构建 SageMaker 统一 Studio 中的生成式 AI 功能。
Ishneet Kaur 是 Amazon SageMaker 统一 Studio 团队的软件开发经理。她领导工程团队设计和构建 SageMaker 统一 Studio 中的生成式 AI 功能。
 Mohan Gandhi 是 AWS 的一位首席软件工程师。他已在 AWS 工作了 10 年,曾参与 Amazon EMR、Amazon EFA 和 Amazon RDS 等各种 AWS 服务。目前,他专注于改进 Amazon SageMaker 推理体验。在业余时间,他喜欢徒步旅行和马拉松。
Mohan Gandhi 是 AWS 的一位首席软件工程师。他已在 AWS 工作了 10 年,曾参与 Amazon EMR、Amazon EFA 和 Amazon RDS 等各种 AWS 服务。目前,他专注于改进 Amazon SageMaker 推理体验。在业余时间,他喜欢徒步旅行和马拉松。
 Vikramank Singh 是 AWS 智能体式 AI 组织的高级应用科学家,从事 Amazon SageMaker 统一 Studio、Amazon RDS 和 Amazon Redshift 等产品的工作。他的研究兴趣在于 AI、控制系统和 RL 的交叉点,特别是在利用它们构建能够自主感知环境、对其进行建模并在规模上做出最优决策的系统方面。
Vikramank Singh 是 AWS 智能体式 AI 组织的高级应用科学家,从事 Amazon SageMaker 统一 Studio、Amazon RDS 和 Amazon Redshift 等产品的工作。他的研究兴趣在于 AI、控制系统和 RL 的交叉点,特别是在利用它们构建能够自主感知环境、对其进行建模并在规模上做出最优决策的系统方面。
 Shubham Mehta 是 AWS 分析部门的高级产品经理。他领导 AWS Glue、Amazon EMR 和 Amazon MWAA 等服务中的生成式 AI 功能开发,利用 AI/ML 简化和增强在 AWS 上构建数据应用程序的数据从业者的体验。
Shubham Mehta 是 AWS 分析部门的高级产品经理。他领导 AWS Glue、Amazon EMR 和 Amazon MWAA 等服务中的生成式 AI 功能开发,利用 AI/ML 简化和增强在 AWS 上构建数据应用程序的数据从业者的体验。
 Amit Sinha 是领导 SageMaker 统一 Studio GenAI 和 ML 产品套件的高级经理。他在 AI/ML 产品、基础设施管理和 AWS 大数据处理服务方面拥有十多年的经验。作为哥伦比亚大学的校友,他在业余时间喜欢徒步旅行和连续观看美国历史纪录片。
Amit Sinha 是领导 SageMaker 统一 Studio GenAI 和 ML 产品套件的高级经理。他在 AI/ML 产品、基础设施管理和 AWS 大数据处理服务方面拥有十多年的经验。作为哥伦比亚大学的校友,他在业余时间喜欢徒步旅行和连续观看美国历史纪录片。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区