



📢 转载信息
原文作者:Nick Biso, Vishwa Gupta, Madhunika Reddy Mikkili, Raechel Frick, Maria Masood, Seif Elharaki, and Shuai Cao
生成高质量的定制视频仍然是一个重大挑战,因为视频生成模型仅限于其预训练的知识。这种限制影响了广告、媒体制作、教育和游戏等行业,在这些行业中,视频生成的定制化和控制至关重要。
为了解决这个问题,我们开发了一个视频检索增强生成(VRAG)多模态管道,该管道使用图像库作为参考,将结构化文本转化为定制视频。该解决方案利用 Amazon Bedrock、Amazon Nova Reel、Amazon OpenSearch Service 矢量引擎 和 Amazon Simple Storage Service(Amazon S3),将图像检索、基于提示的视频生成和批量处理无缝集成到一个自动化的工作流程中。用户提供一个感兴趣的对象,解决方案从索引数据集中检索最相关的图像。然后,他们定义一个动作提示(例如,“相机顺时针旋转”),该提示与检索到的图像结合以生成视频。来自文本文件的结构化提示允许在一次执行中生成多个视频,从而为 AI 辅助媒体生成奠定了可扩展、可重用的基础。
在本博文中,我们将通过 VRAG 探索视频生成的方法,将自然语言文本提示和图像转化为基于事实的高质量视频。通过这个完全自动化的解决方案,您可以从结构化文本和图像输入生成逼真、由 AI 驱动的视频序列,从而简化视频创建过程。
解决方案概述
我们的解决方案旨在接收结构化文本提示,检索最相关的图像,并使用 Amazon Nova Reel 进行视频生成。该解决方案将多个组件集成到一个无缝的工作流程中:
- 图像检索和处理 – 用户提供一个感兴趣的对象(例如,“蓝天”),解决方案会查询 OpenSearch 矢量引擎,从包含预先索引的图像和描述的索引数据集中检索最相关的图像。最相关的图像会从 S3 存储桶中检索。
- 基于提示的视频生成 – 用户定义一个动作提示(例如,“相机向下平移”),该提示与检索到的图像结合,使用 Amazon Nova Reel 生成视频。
- 批量处理多个提示 – 该解决方案从
prompts.txt文件中读取一系列文本模板,这些模板包含占位符,以便能够对具有结构化变体的多个视频生成请求进行批量处理:- <object_prompt> – 动态替换为查询的对象。
- <action_prompt> – 动态替换为相机移动或场景动作。
- 监控和存储 – 视频生成是异步的,因此该解决方案会监控作业状态。完成后,视频将存储在 S3 存储桶中并自动下载以供预览。生成的视频会显示在笔记本中,并附带相应的提示作为标题。
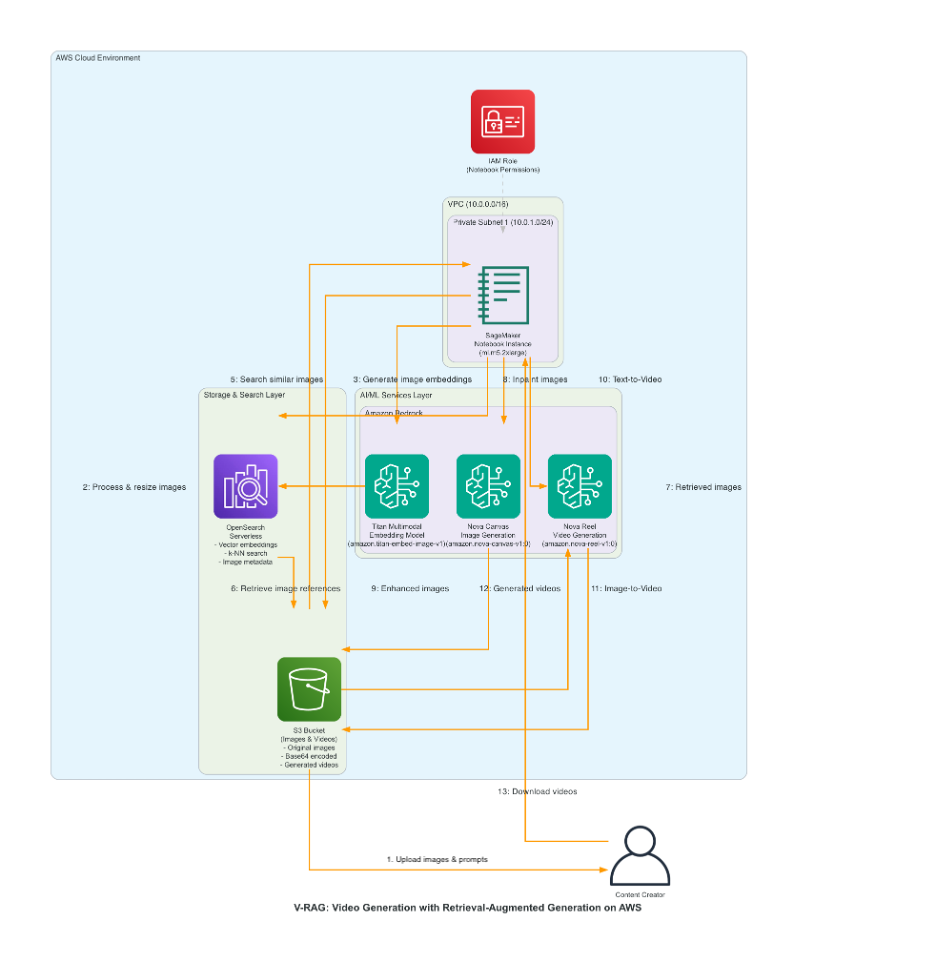
下图说明了解决方案架构。
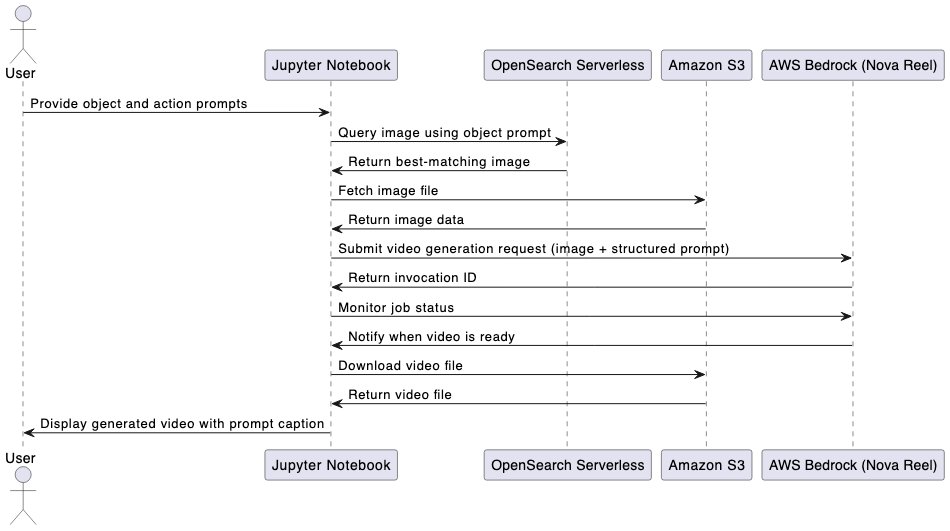
下图说明了使用 Jupyter Notebook 的端到端工作流程。
该解决方案可用于以下用例:
- 教育视频 – 通过从主题知识库中提取相关图像来自动创建教学视频
- 营销视频 – 通过提取与特定人群或产品功能相符的图像来创建定向视频广告
- 个性化内容 – 通过根据用户特定兴趣检索图像来定制视频内容
在接下来的几节中,我们将详细介绍每个组件,说明其工作原理,以及如何为其定制自己的 AI 驱动视频工作流。
示例输入
在本节中,我们将通过两种不同的输入方法:纯文本和文本与图像输入,来演示 Amazon Nova Reel 的视频生成功能。这些示例说明了如何通过包含输入图像来进一步定制视频生成,在本场景中用于广告。在我们的示例中,一家旅行社希望创建一则广告,展示某个特定地点的美丽海滩景象,然后将其镜头切换到皮划艇,以吸引潜在的度假预订。我们将比较使用纯文本输入方法与使用静态图像进行 VRAG 以实现此目标的结果。
纯文本输入
对于纯文本示例,我们使用输入“从蓝天缓慢向下平移到漂浮在绿松石水面上的彩色皮划艇。”我们获得了以下结果。

文本和图像输入
使用相同的文本提示,旅行社现在可以使用他们在当地拍摄的特定镜头。在此示例中,我们使用以下图像。

旅行社现在可以使用 VRAG 将内容添加到他们现有的镜头中。他们使用相同的提示:“从蓝天缓慢向下平移到漂浮在绿松石水面上的彩色皮划艇。”这会生成以下视频。

先决条件
在部署此解决方案之前,请确保已满足以下先决条件:
- 访问有效的 AWS 账户
- 熟悉 Amazon SageMaker 笔记本实例
部署解决方案
在本博文中,我们使用 AWS CloudFormation 模板在 US East (N. Virginia) AWS 区域部署该解决方案。有关支持 Amazon Nova Reel 的区域列表,请参阅 Amazon Bedrock 中的模型支持按 AWS 区域。完成以下步骤:
- 选择 Launch Stack 来部署堆栈:

- 输入堆栈名称,例如
vrag-blogpost,然后按照步骤进行部署。 - 在 CloudFormation 控制台中,找到
vrag-blogpost堆栈并确认其状态为 CREATE_COMPLETE。 - 在 SageMaker AI 控制台中,选择导航窗格中的 Notebooks。
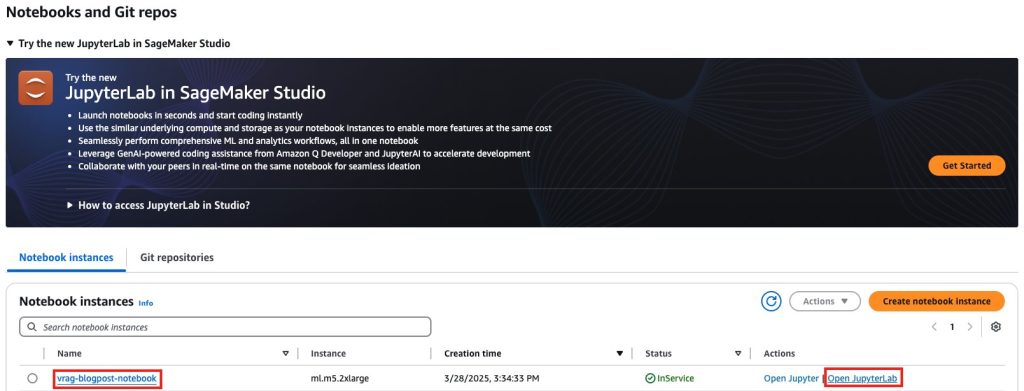
- 在 Notebook instances 选项卡上,找到为此博文配置的笔记本实例
vrag-blogpost-notebook,然后选择 Open JupyterLab。
- 打开
sample-video-rag文件夹以查看本博文所需的笔记本。
运行笔记本
我们提供了七个连续的笔记本,编号从 _00 到 _06,并附有分步说明和目标,以帮助您建立对 VRAG 解决方案的理解。您的输出可能与本博文中的示例有所不同。
图像处理(笔记本 _00)
在 _00_image_processing 中,您将使用 Amazon Bedrock、Amazon S3 和 SageMaker AI 来执行以下操作:
- 处理和调整图像大小
- 生成 Base64 编码
- 将数据存储在 Amazon S3 中
- 使用 Amazon Nova 生成图像描述
- 创建结果的可视化
此笔记本说明了以下功能:
- 自动化处理管道:
- 批量图像处理
- 智能调整大小和优化
- 用于 API 兼容性的 Base64 编码
- Amazon S3 图像存储
- AI 驱动的分析:
- 高级图像描述生成
- 基于内容的图像理解
- 多模态 AI 集成
- 强大的数据管理:
- 高效的存储组织
- 元数据提取和索引
在此示例中,我们使用以下输入图像。

我们收到以下生成的图像标题作为输出:“图像展示了一个带有白色花卉图案的棕色手袋、一条带蓝色缎带的草帽和一瓶香水。手袋放在一个表面上,草帽放在旁边。手袋上有一个带子和一个链条,草帽上系着一条蓝色缎带。香水瓶放在手袋旁边。”
图像注入(笔记本 _01)
在 _01_oss_ingestion.ipynb 中,您将使用 Amazon Bedrock(带有 Amazon Titan Embeddings 来生成嵌入)、Amazon S3、OpenSearch Serverless(用于矢量存储和搜索)和 SageMaker AI(用于笔记本托管)来执行以下操作:
- 处理和调整图像大小
- 生成 base64 编码
- 将数据存储在 Amazon S3 中
- 使用 Amazon Nova 生成图像描述
- 创建结果的可视化
此笔记本说明了以下功能:
- 矢量数据库管理:
- 索引创建和配置
- 批量数据注入
- 高效的矢量存储
- 嵌入生成:
- 多模态嵌入创建
- 维度优化
- 批量处理支持
- 语义搜索功能:
- k-NN 搜索实现
- 查询矢量生成
- 结果可视化
对于我们的输入,我们使用查询“Building”(建筑)并收到以下图像作为结果。

该图像附带的标题作为输出:“该图像描绘了一个现代建筑场景,其中有几座玻璃幕墙的高层建筑。这些建筑采用玻璃和钢的组合建造,外观时尚现代。玻璃面板反射着周围的环境,包括天空和其他建筑物,形成了光影的动态互动。上面的天空部分多云,可见一些蓝色区域,表明是晴朗有云的一天。建筑物高而窄,垂直线条通过玻璃面板和钢框架的结构得到强调。玻璃表面的反射显示了周围的建筑物和天空,增加了图像的深度。整体印象是现代、高效和城市化的精致。”
纯文本视频生成(笔记本 _02)
在 _02_video_gen_text_only.ipynb 中,您将使用 Amazon Bedrock(访问 Amazon Nova Reel)和 SageMaker AI(笔记本托管)来执行以下操作:
- 构建带有文本作为提示的视频生成请求负载
- 使用 Amazon Bedrock 启动异步作业
- 跟踪进度并等待其完成
- 从 Amazon S3 检索生成的视频并将其渲染到笔记本中
此笔记本说明了以下功能:
- 以文本作为输入自动处理视频生成
- 可观察性下的视频批量生成
我们使用以下输入提示:“近景拍摄沙滩上的一个大贝壳,轻柔的海浪围绕着贝壳流动。相机放大。”我们收到以下生成的视频作为输出。

从文本和图像提示生成视频(笔记本 _03)
在 _03_video_gen_text_image.ipynb 中,您将使用 Amazon Bedrock(访问 Amazon Nova Reel)和 SageMaker AI(笔记本托管)来执行以下操作:
- 构建带有文本和图像作为提示的视频生成请求负载
- 使用 Amazon Bedrock 启动异步作业
- 跟踪进度并等待其完成
- 从 Amazon S3 检索生成的视频并将其渲染到笔记本中
此笔记本说明了以下功能:
- 以文本和图像作为输入自动处理视频生成
- 可观察性下的视频批量生成
我们使用提示“相机从道路向上倾斜到天空”和以下图像作为输入。

我们收到以下生成的视频作为输出。

从多模态输入生成视频(笔记本 _04)
在 _04_video_gen_multi.ipynb 中,您将使用 Amazon Bedrock(访问 Amazon Nova Reel)和 SageMaker AI(笔记本托管)来执行以下操作:
- 为输入提示生成嵌入并搜索 OpenSearch Serverless 矢量集合索引
- 结合文本和检索到的图像来生成视频
此笔记本说明了以下功能:
- VRAG 流程
- 可观察性下的视频批量生成
我们使用以下提示作为输入:“一个干净的电影镜头,红鞋放在飘落的雪下,同时环境保持寂静和静止。”我们收到以下视频作为输出。

使用内容填充更新图像(笔记本 _05)
在 _05_inpainting.ipynb 中,您将使用 Amazon Bedrock(访问 Amazon Nova Reel)和 SageMaker AI(笔记本托管)来执行以下操作:
- 读取 base64 图像
- 使用内容填充生成图像
此笔记本说明了以下功能:
- 根据周围上下文和提示替换和选择图像区域
- 移除不需要的对象并修复图像部分,或创造性地修改图像的特定区域
使用增强图像生成视频(笔记本 _06)
在 _06_video_gen_inpainting.ipynb 中,您将使用 Amazon Bedrock(访问 Amazon Nova Reel)和 SageMaker AI(笔记本托管)来执行以下操作:
- 使用自然语言查询在 OpenSearch Service 中搜索相关图像
- 使用显式图像蒙版定义内容填充的区域
- 使用增强图像生成视频
此笔记本说明了以下功能:
- 使用内容填充生成图像
- 使用增强图像生成视频
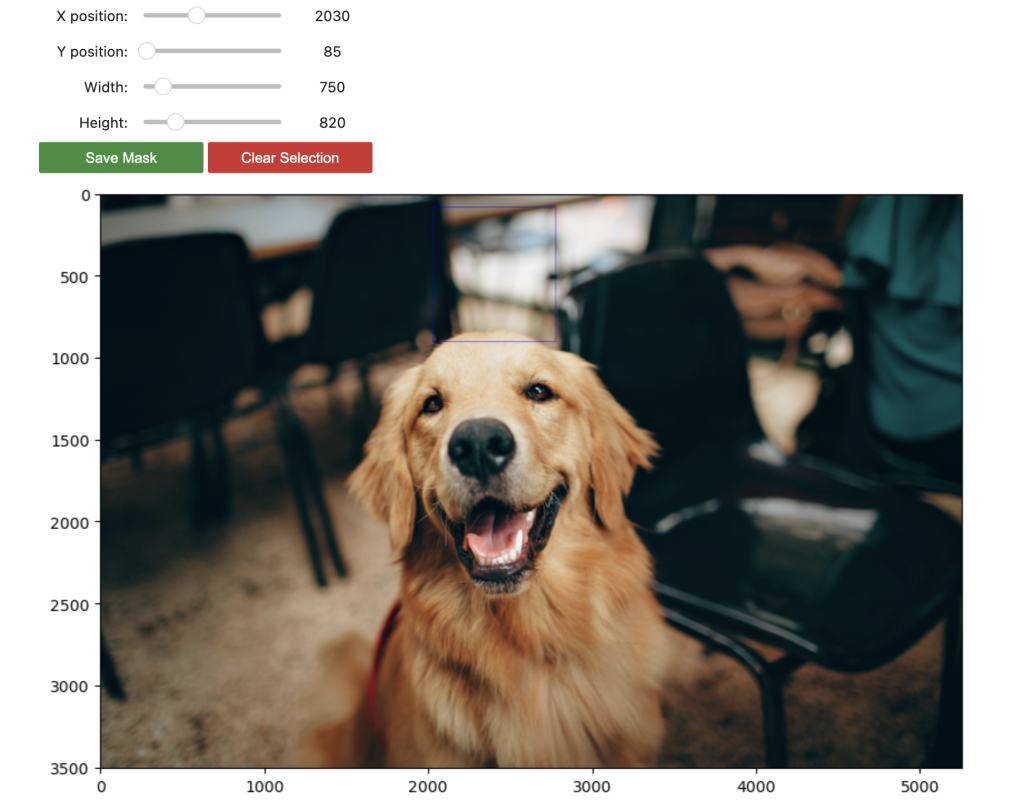
以下屏幕截图显示了我们用于内容填充的图像和蒙版。
以下屏幕截图显示了我们收到的生成图像(少样本)作为输出。

从生成的图像中,我们收到以下视频作为输出。

最佳实践
高效的 AI 视频生成流程需要数据管理、搜索优化和合规措施的无缝集成。该流程必须处理高质量的输入数据,同时保持优化的 OpenSearch 查询和 Amazon Bedrock 集成以实现可靠的处理。适当的 Amazon S3 管理和增强的用户体验功能有助于顺利运行,严格遵守 欧盟人工智能法案指南 可确保合规性。
为了在生产环境中实现最佳实施,请考虑以下关键因素:
- 数据质量 – 生成视频的质量在很大程度上取决于 RAG 中使用的图像数据库的质量和相关性
- 图像字幕 – 为了获得最佳效果,请考虑添加图像字幕或元数据,为 RAG 解决方案提供额外上下文
- 视频编辑 – 尽管 RAG 可以提供核心视觉元素,但可能需要额外的视频编辑技术来创建精美的最终产品
清理
为避免产生后续费用,请清理在此博文中创建的资源。
- 清空 CloudFormation 堆栈创建的 S3 存储桶。在 Amazon S3 控制台中,选择存储桶,选择 Empty,然后确认删除。
- 在 AWS CloudFormation 控制台中,选择 vrag-blogpost 堆栈,选择 Delete,然后确认。这将删除所有配置的资源,包括 SageMaker 笔记本实例、OpenSearch Serverless 集合和 IAM 角色。
结论
VRAG 代表了 AI 驱动视频创作的重大进步,它将现有的图像数据库与用户提示无缝集成,以生成与上下文相关的视频内容。该解决方案展示了在教育、营销、娱乐等领域的强大应用。随着视频生成技术的不断发展,VRAG 为大规模创建引人入胜、上下文感知的视频内容提供了坚实的基础。通过遵循这些最佳实践并专注于数据质量,组织可以利用这项技术来转变其视频内容创作流程,同时生成一致、高质量的输出。请通过本博文中提供的笔记本尝试 VRAG,并在评论部分分享您的反馈。
关于作者
 Nick Biso 是 AWS 专业服务部的一名机器学习工程师。他利用数据科学和工程技术解决复杂的组织和技术挑战。此外,他还负责在 AWS 云上构建和部署 AI/ML 模型。他对旅行和多元文化体验的热情延伸了他的职业兴趣。
Nick Biso 是 AWS 专业服务部的一名机器学习工程师。他利用数据科学和工程技术解决复杂的组织和技术挑战。此外,他还负责在 AWS 云上构建和部署 AI/ML 模型。他对旅行和多元文化体验的热情延伸了他的职业兴趣。
 Madhunika Mikkili 是 AWS 的一名数据与机器学习工程师。她热衷于帮助客户利用数据分析和机器学习实现目标。
Madhunika Mikkili 是 AWS 的一名数据与机器学习工程师。她热衷于帮助客户利用数据分析和机器学习实现目标。
 Shuai Cao 是亚马逊网络服务(AWS)生成式人工智能领域的首席应用科学家经理。他领导数据科学家、机器学习工程师和应用架构师团队,为客户交付 AI/ML 解决方案。工作之余,他喜欢作曲和编曲。
Shuai Cao 是亚马逊网络服务(AWS)生成式人工智能领域的首席应用科学家经理。他领导数据科学家、机器学习工程师和应用架构师团队,为客户交付 AI/ML 解决方案。工作之余,他喜欢作曲和编曲。
 Seif Elharaki 是一名首席云应用程序架构师,专注于为制造业构建 AI/ML 应用程序。他结合了自己在云技术方面的专业知识以及对工业流程的深刻理解,以创建创新解决方案。工作之余,Seif 是一位热情的业余游戏开发者,喜欢使用虚幻引擎和 Unity 等工具编写有趣的游戏。
Seif Elharaki 是一名首席云应用程序架构师,专注于为制造业构建 AI/ML 应用程序。他结合了自己在云技术方面的专业知识以及对工业流程的深刻理解,以创建创新解决方案。工作之余,Seif 是一位热情的业余游戏开发者,喜欢使用虚幻引擎和 Unity 等工具编写有趣的游戏。
 Vishwa Gupta 是 AWS 专业服务部的首席顾问。他帮助客户实施生成式 AI、机器学习和分析解决方案。工作之余,他喜欢与家人共度时光、旅行和品尝新食物。
Vishwa Gupta 是 AWS 专业服务部的首席顾问。他帮助客户实施生成式 AI、机器学习和分析解决方案。工作之余,他喜欢与家人共度时光、旅行和品尝新食物。
 Raechel Frick 是 Amazon Nova 的高级产品营销经理。她拥有超过 20 年的技术行业经验,在构建综合营销计划时,她秉持客户至上的方法和增长思维。Raechel 居住在西雅图地区,她在专业生活中平衡着作为足球妈妈和啦啦队教练的身份。
Raechel Frick 是 Amazon Nova 的高级产品营销经理。她拥有超过 20 年的技术行业经验,在构建综合营销计划时,她秉持客户至上的方法和增长思维。Raechel 居住在西雅图地区,她在专业生活中平衡着作为足球妈妈和啦啦队教练的身份。
 Maria Masood 专注于代理 AI、强化微调和多轮代理训练。她在机器学习领域拥有专业知识,涵盖大型语言模型定制、奖励建模和为 AI 代理构建端到端训练管道。作为一名热衷于可持续发展的实践者,Maria 喜欢园艺和制作拿铁咖啡。
Maria Masood 专注于代理 AI、强化微调和多轮代理训练。她在机器学习领域拥有专业知识,涵盖大型语言模型定制、奖励建模和为 AI 代理构建端到端训练管道。作为一名热衷于可持续发展的实践者,Maria 喜欢园艺和制作拿铁咖啡。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区