



📢 转载信息
原文作者:Akarsha Sehwag 等 AWS 团队
您的 AI 智能体在演示中表现出色,令利益相关者印象深刻,通过了测试场景,看起来已准备好投入生产。然而,一旦部署,情况便发生了变化。真实用户遇到了错误的工具调用、不一致的响应以及测试中未曾预料到的故障模式。
这导致了智能体预期行为与实际用户体验之间的脱节。智能体评估引入了传统软件测试无法处理的挑战。由于大语言模型(LLM)具有非确定性,相同的用户查询在多次运行中可能产生不同的工具选择、推理路径和输出。这意味着您必须反复测试每个场景,以了解智能体的真实行为模式。没有这种系统性的衡量,团队就会陷入手动测试和被动调试的循环中。
Amazon Bedrock AgentCore Evaluations 简介
在本文中,我们推出了 Amazon Bedrock AgentCore Evaluations,这是一项用于评估 AI 智能体在整个开发生命周期中性能的全托管服务。它处理评估模型、推理基础设施、数据管道和扩展,让团队能够专注于提高智能体质量,而不是构建和维护评估系统。
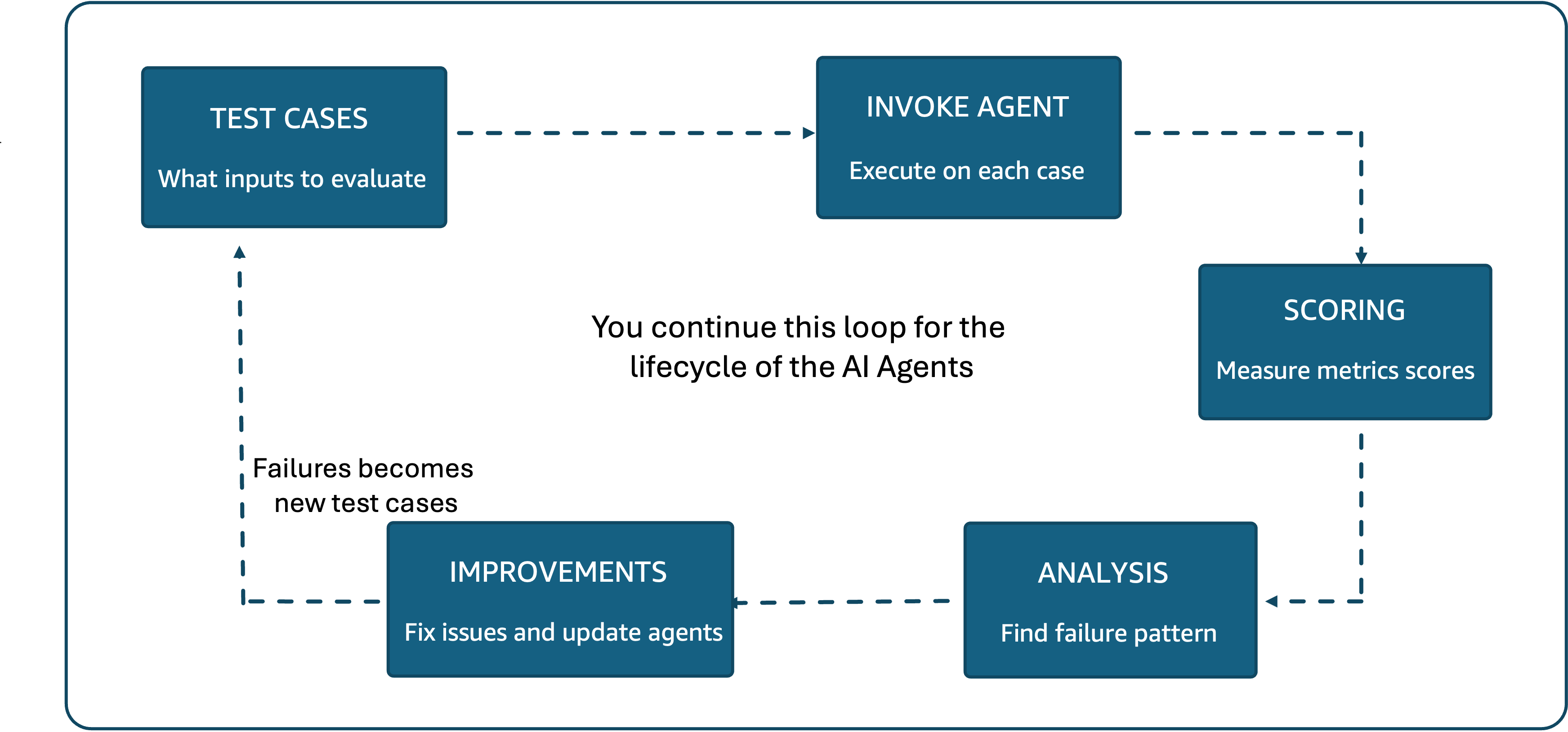
图 1:智能体评估过程遵循测试用例、智能体执行、评分、分析和改进的持续循环。
为什么智能体评估需要新方法
当用户向智能体发送请求时,会发生一系列决策。智能体决定调用哪些工具,执行这些调用,并根据结果生成响应。每个步骤都引入了潜在的故障点。与测试单一函数输出的传统应用程序不同,智能体评估需要跨整个交互流来衡量质量。
这可以通过以下方式解决:
- 定义关于什么是正确的工具选择、有效的参数和有帮助的用户体验的评估标准。
- 构建代表真实用户请求和预期行为的测试数据集。
- 选择能够在重复运行中一致评估质量的评分方法。
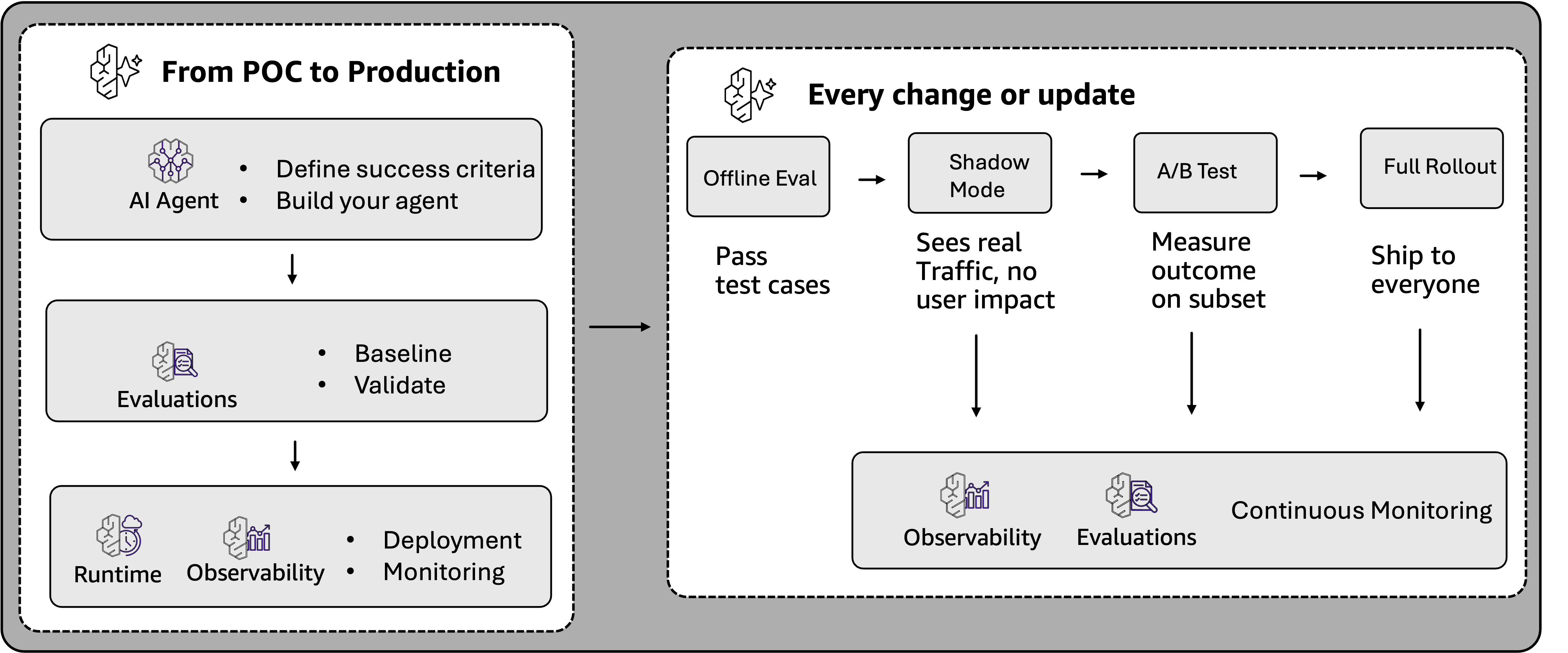
评估生命周期
智能体从原型到生产的过程产生了两种不同的评估需求。在开发阶段,团队需要受控环境来比较替代方案并在发布前验证变更。在生产阶段,挑战转变为大规模监控真实世界的交互。
AgentCore Evaluations 为此提供了两种互补的方法:
- 按需评估(On-demand Evaluation):用于开发阶段的受控测试、CI/CD 工作流及基准测试。
- 在线评估(Online Evaluation):用于生产环境的持续监控,实时捕捉质量下降。
核心评估维度
AgentCore 提供了 13 种内置评估器,涵盖会话(Session)、轨迹(Trace)和工具(Tool)三个层级:
- 会话级:评估目标成功率。
- 轨迹级:评估帮助性、准确性、连贯性、简洁性、忠实度及安全性。
- 工具级:评估工具选择的准确性和参数提取的精确度。
通过这种分层评估,团队可以精确诊断问题是源于工具选择、响应生成还是会话规划。
🚀 想要体验更好更全面的AI调用?
欢迎使用青云聚合API,约为官网价格的十分之一,支持300+全球最新模型,以及全球各种生图生视频模型,无需翻墙高速稳定,文档丰富,小白也可以简单操作。
评论区