



📢 转载信息
原文作者:Daniel Wirjo, Faisal Masood, Iman Abbasnejad, Nicola Smyth, Curt Lockhart, Francesco Ciannella, and Tim Ma
本文由 AWS、NVIDIA 和 Heidi 合作完成。
自动语音识别(ASR),通常称为语音转文本(STT),在医疗保健、客户服务和媒体制作等行业中变得越来越重要。虽然预训练模型为通用语音提供了强大的功能,但针对特定领域和用例进行微调可以提高准确性和性能。
在本文中,我们将探讨如何微调一个排行榜领先的 NVIDIA Nemotron Speech 自动语音识别(ASR)模型;Parakeet TDT 0.6B V2。利用合成语音数据以实现专业化应用的卓越转录结果,我们将介绍一个端到端的完整工作流程,该工作流程结合了 AWS 基础设施和以下流行的开源框架:
- Amazon Elastic Compute Cloud (Amazon EC2) GPU 实例(p4d.24xlarge 配备 NVIDIA A100 GPU),用于大规模分布式训练
- NVIDIA NeMo 框架,用于 ASR 模型微调和优化
- DeepSpeed,用于跨多个节点的内存高效分布式训练
- MLflow 和 TensorBoard,用于全面的实验跟踪
- Amazon Elastic Kubernetes Services (Amazon EKS),用于可扩展的模型服务
- Amazon FSx for Lustre,用于高性能模型权重存储
- AI Gateway 和 Langfuse,用于生产级 API 管理和可观察性
- Docker,用于跨训练和推理的一致、可重现的环境
该架构展示了如何使用 AWS 的托管服务以及一流的开源 AI 工具来构建生产级、领域自适应的 ASR 系统,从而在从初始微调到弹性、可观察性部署的整个过程中实现可衡量的业务价值。
解决方案概述:Heidi 的 AI Care Partner
Heidi 是一个 AI Care Partner,它消除了护理工作——处理文档、临床证据和患者沟通,使临床医生能够专注于患者。该平台支持每周在 190 个国家/地区以 110 种语言进行的超过 240 万次会诊。Heidi 被广泛应用于急诊科、全科和专科诊所,帮助临床医生每天节省数小时的工作时间,同时保持临床记录的准确性和完整性。
开箱即用的 ASR 模型在处理医学术语、地区口音以及临床语言和对话语言之间的代码切换时存在困难。这些限制导致转录错误、信息丢失和认知负荷增加,迫使临床医生花费时间纠正本应为他们节省时间的内容。 对于临床医生来说,准确的文档记录不仅仅是便利。它关乎临床安全、责任保护和对工具的信任。一份有错误的记录会破坏所有这三点。
为了解决这个问题,Heidi 与 AWS Generative AI Innovation Center (GenAIIC) 合作,对模型进行了微调和自适应,以适应真实临床环境中独特的语言、声学和上下文细微差别——从而实现大规模的准确可靠的性能。利用文本转语音(TTS)模型的最新进展,Heidi 生成了高质量、多语言的合成语音,并与通过大型语言模型(LLM)模拟的真实对话噪声交织在一起。这种方法使团队能够扩展到各种口音和医疗背景的训练,而不会损害患者隐私。使用合成数据还实现了有针对性的增强,重点关注开放数据集中表示不足的低资源语言和罕见医学术语。
微调使用 Amazon EC2 GPU 实例进行,这些实例针对深度学习工作负载进行了优化。通过使用预先配置的 AWS Deep Learning AMIs,团队能够加速实验和模型迭代,同时保持对性能和安全的控制。可扩展的计算能力与紧密集成的 AWS 服务相结合,使得在高度监管的环境中能够进行快速、经济高效的开发。
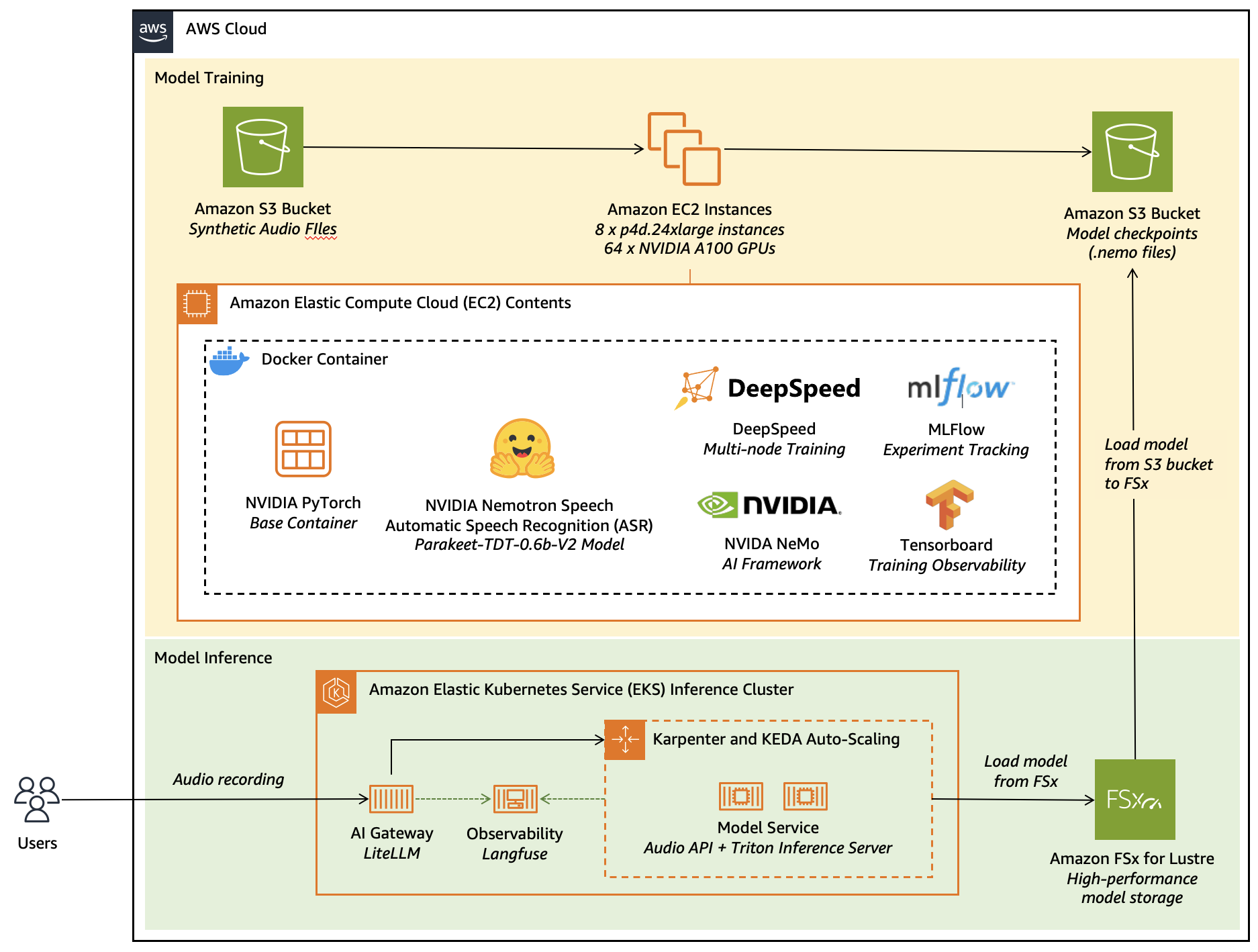
图 1:此图显示了在 AWS 服务上微调和部署 NVIDIA Parakeet TDT 0.6B V2 模型的架构图。
合成领域特定的数据
为了帮助提高 NVIDIA Parakeet TDT 0.6B V2 在医学专业术语上的性能,我们开发了一个集成了大型语言模型(LLM)、神经文本转语音(TTS)合成和噪声增强的定向合成数据生成管道。该过程首先编译了一个医学术语词汇表,主要包括在先前的评估运行中召回率较低的药品名称、解剖实体和程序短语。这些术语被用作领域自适应 LLM 的条件输入,LLM 生成了与真实临床听写相似的语义连贯且在上下文上多样化的转录。提示被设计用于引发在医学语音中常见的各种语言结构和自然的语码转换模式。例如,混合使用缩写、拉丁语源单词和口语化短语。
然后使用神经 TTS 系统将生成的转录转换为语音,该系统配置为具有特定的口音和自然的韵律。为了增加数据的多样性和真实性,我们采用了多阶段音频增强管道。这包括叠加医院和诊所的环境声音记录,例如背景对话、机器警报和从开放声学数据集中采样的医院环境声音。我们还应用了受控扰动,包括随机增益调整、混响滤波器和加性高斯噪声,以模拟真实的麦克风和环境条件。每个合成的语音片段都被分配一个在 10-25 dB 之间的随机信噪比(SNR),以平衡清晰度和真实性。
NVIDIA Parakeet TDT 0.6B V2 模型介绍
NVIDIA Parakeet TDT 0.6B V2 是一个拥有 6 亿个参数的自动语音识别(ASR)模型,专为高质量英语转录而设计。该模型基于 NVIDIA NeMo 的 FastConformer 架构,并配有 Token-and-Duration Transducer (TDT) 解码器,可在提供卓越语音识别能力的同时,还具备以下宝贵功能:
- 自动标点符号和大小写
- 词级别的时间戳预测
- 对口语数字和歌词的稳健性能
- 支持一次性处理长达 24 分钟的音频片段
该开放模型在 Hugging Face Open-ASR 排行榜的各种基准数据集上实现了令人印象深刻的 6.05% 平均词错误率(WER),证明了其在通用英语语音识别方面的有效性。
为什么要微调模型?
尽管 NVIDIA Parakeet TDT 0.6B V2 模型开箱即用性能优异,但针对特定领域进行微调也提供了几个显著的优势:
- 领域特定术语 – 增强对专业词汇和行话的识别能力,这些词汇和行话在通用训练数据集中可能很少见
- 口音和方言自适应 – 提高对特定地区语音模式或语言变体的性能
- 噪声鲁棒性 – 更好地处理领域特定的背景噪声和声学环境
- 成本效益 – 通过您自己的优化模型,减少对昂贵第三方 API 调用的需求
- 定制化优化 – 在准确性和推理速度之间取得平衡,以满足您特定的应用需求
模型架构
NVIDIA Parakeet TDT 0.6B V2 模型采用 Token-and-Duration Transducer (TDT) 架构,包含以下关键组件:
编码器架构
编码器通过多个处理阶段将输入的音频特征转换为上下文表示:
- Conformer 编码器:24 个 Conformer 层,1024 个隐藏维度
- 卷积子采样:初始特征提取,包含四个卷积层
- 3×3 卷积,步长为 2,用于渐进式下采样
- 在整个卷积堆栈中,通道维度为 256
- 位置编码:带有 dropout(0.1)的相对位置编码
Conformer 层
每个 Conformer 层包含:
- 前馈网络模块:两个 FFN 块,内部维度为 4096
- 卷积模块:9×1 的深度卷积,带因果填充、批量归一化和 Swish 激活
- 多头注意力:具有相对位置编码的自注意力机制
- 归一化:组件之间的层归一化
- Dropout:0.1 的 dropout 率用于正则化
解码器和联合网络
解码器和联合网络将编码器输出与预测的 token 结合起来生成最终的转录:
RNN 解码器:
- 嵌入层(1025 个词汇量,640 个嵌入维度)
- 2 层 LSTM,具有 640 个隐藏单元和 0.2 的 dropout
联合网络:
- 编码器和解码器的线性变换
- ReLU 激活,带 0.2 dropout
- 输出投影到 1030 维度
音频处理和损失函数
模型采用专门的预处理和训练目标来帮助优化转录准确性:
- Mel 频谱图预处理:将原始音频转换为 mel 尺度频谱图
- 频谱增强:时间频率掩码,以帮助增强鲁棒性
- TDT 损失:Token-and-Duration Transducer 损失,用于同时预测 token 及其持续时间
- 词错误率(WER):转录质量的主要评估指标
为微调设置环境
我们的微调方法利用 Amazon EC2 实例上的分布式训练,并为部署到 Amazon SageMaker AI 提供了路径。环境封装在 Docker 容器中,以促进一致性和可重现性。
基于 Docker 的环境设置
Docker 容器包含微调所需的依赖项,如下面的代码片段所示。您可以在关联的 GitHub 存储库 中找到完整的文件:
FROM nvcr.io/nvidia/pytorch:24.01-py3
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=UTC
# Set the working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
libsox-fmt-mp3 \
gnupg \
&& rm -rf /var/lib/apt/lists/*
# Install Cython (needed for NeMo)
RUN pip install Cython
# Clone the specified branch of the pytorch-lightning repository and install it
RUN git clone -b bug_fix https://github.com/athitten/pytorch-lightning.git && \
cd pytorch-lightning && \
PACKAGE_NAME=pytorch pip install -e .
# Install TransformerEngine for optimization
RUN git clone https://github.com/NVIDIA/TransformerEngine.git && \
cd TransformerEngine && \
git fetch origin 8c9abbb80dba196f086b8b602a7cf1bce0040a6a && \
git checkout FETCH_HEAD && \
git submodule init && git submodule update && \
此容器提供:
- NVIDIA 优化的 PyTorch 容器作为基础
- NeMo 框架用于 ASR 模型处理
- DeepSpeed 用于高效的分布式训练
- MLflow 和 TensorBoard 用于实验跟踪
资源要求
为了高效微调,我们建议:
- EC2 实例类型:p4d.24xlarge(每个实例 8 个 NVIDIA A100 GPU)– A100 GPU 为每个 GPU 提供 80GB 高带宽内存,对于处理 Parakeet TDT 0.6B V2 模型 6 亿个参数的大批量大小至关重要。A100 Tensor Core 加速混合精度训练,与上一代 GPU 相比缩短了训练时间。请注意,有更新、更强大的 EC2 实例,例如 P5,也可用于满足更苛刻的要求。
- 集群大小:8 个节点(共 64 个 GPU)用于全规模训练 – 跨多个节点的分布式训练通过并行化实现更大的批次大小和更快的收敛,支持在大规模音频数据集上进行高效训练。拥有 64 个 GPU,您可以在数小时内(而不是数天)处理海量数据集(100+ 小时音频),从而为生产时间线实现快速实验。
- 存储: 每个节点至少 500 GB 用于模型检查点和数据。此容量可容纳频繁的检查点保存、中间训练状态以及预处理音频特征的本地缓存。足够的存储可防止 I/O 瓶颈,这些瓶颈可能在训练期间导致昂贵的 GPU 资源闲置。
对于较小的数据集或预算限制,训练可以缩减到更少的节点或 GPU 实例,例如 g6e.2xlarge。
用于微调的数据准备
Parakeet TDT 0.6B V2 模型需要 NeMo 的 JSONL manifest 格式的音频数据和相应的转录。这些文件中的每一行都指向合成的音频和从中合成的相应转录。
{
"audio_filepath": "/path/to/audio.wav",
"duration": 5.2,
"text": "The transcription with punctuation and capitalization."
}
创建训练 manifest
我们的微调方法使用三个独立的 manifest 文件:
- 训练 manifest:包含用于模型训练的大部分数据
- 验证 manifest:用于在训练期间评估模型性能
- 测试 manifest:用于对微调后的模型进行最终评估
为了提高性能,数据集应包含与您的领域相关的多样化说话人、口音和声学条件。
微调配置深入解析
我们的微调配置全面且精心定制,适用于 Parakeet TDT 0.6B V2 模型:
模型配置
配置指定了具有 17 个 Conformer 块的 Parakeet TDT 0.6B V2 架构:
model:
sample_rate: 16000
normalize_text: true
symbols_to_keep: ["'"]
encoder:
_target_: nemo.collections.asr.modules.ConformerEncoder
feat_in: "${model.preprocessor.features}"
n_layers: 17
d_model: 512
subsampling:
dw_striding
subsampling_factor: 8
subsampling_conv_channels: 256
Token-and-Duration Transducer (TDT) 设置
TDT 架构配置了特定的持续时间值,以预测 token 发射时序:
model:
model_defaults:
tdt_durations: [0, 1, 2, 3, 4]
num_tdt_durations: 5
loss:
loss_name: "tdt"
tdt_kwargs:
durations: "${model.max_duration}"
sigma: 0.02
omega: 0.1
音频预处理
音频预处理配置为最佳特征提取:
preprocessor:
_target_: nemo.collections.asr.modules.AudioToMelSpectrogramPreprocessor
sample_rate: "${model.sample_rate}"
normalize: "per_feature"
window_size: 0.025
window_stride: 0.01
features: 128
n_fft: 512
dither: 0.00001
数据增强
为了帮助提高模型鲁棒性,应用了多种增强技术,例如频谱图增强:
train_ds:
augmentor:
speed:
prob: 0.4
min_speed_rate: 0.9
max_speed_rate: 1.1
spec_augment:
_target_: nemo.collections.asr.modules.SpectrogramAugmentation
freq_masks: 2
time_masks: 10
freq_width: 27
time_width: 0.05
配置文件中还有注释选项,可用于其他增强策略,如噪声增强和移位扰动。
分布式训练策略
训练被配置为在多个 GPU 和节点之间进行高效分布式:
trainer:
devices: 8
num_nodes: 8
strategy:
_target_: "lightning.pytorch.strategies.DeepSpeedStrategy"
stage: 2
offload_optimizer: true
partition_activations: true
gradient_as_bucket_view: true
cpu_checkpointing: true
contiguous_gradients: true
overlap_comm: true
此 DeepSpeed 配置提高了内存使用率和 GPU 之间的通信效率,从而最大化训练效率。
实现微调过程
我们的实现采用模块化方法,包含一个专用的 ASRTrainer 类:
模型初始化和解冻
def get_base_model(self, trainer):
"""Get the base model to start training from based on config settings."""
pretrained_name = self.config.init_from_pretrained_model
# Handle multi-GPU download efficiently
num_ranks = trainer.num_devices * trainer.num_nodes
if num_ranks > 1 and is_global_rank_zero():
logging.info(f"Downloading pretrained model '{pretrained_name}' on main process")
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
else:
# Wait for model download to complete on main process
wait_time = 1 if is_global_rank_zero() else 60
logging.info(f"Waiting {wait_time}s for model download")
time.sleep(wait_time)
asr_model = ASRModel.from_pretrained(model_name=pretrained_name)
asr_model.to(f"cuda:{int(os.environ.get('LOCAL_RANK', 0))}")
# Unfreezing encoders to update the parameters
asr_model.encoder.unfreeze()
logging.info("Model encoder has been un-frozen")
return asr_model
这种方法在分布式训练环境中提供了高效的模型加载,只有主进程下载模型,其他进程等待以避免重复下载。
训练执行
def train(self, model_path):
"""Train the ASR model."""
# Create trainer with experiment manager for logging
trainer = self.create_trainer()
# Initialize model based on config settings
asr_model = self.get_base_model(trainer)
# Setup dataloaders
asr_model = self.setup_dataloaders(asr_model)
# Setup optimization
asr_model.setup_optimization(self.config.model.optim)
# Setup SpecAug if available
if hasattr(self.config.model, 'spec_augment'):
asr_model.spec_augment = ASRModel.from_config_dict(self.config.model.spec_augment)
# Train the model
trainer.fit(asr_model)
# Save the trained model
asr_model.save_to(model_path)
return model_path
此训练函数:
- 使用适当的日志记录创建 PyTorch Lightning 训练器
- 加载并准备预训练模型
- 为训练、验证和测试设置数据加载器
- 配置优化参数和数据增强
- 执行训练过程
- 保存最终模型
- 在 MLflow 中记录训练和评估的工件
性能监控和优化
监控训练进度对于确保模型有效学习至关重要:
使用 MLflow 进行实验跟踪
MLflow 提供全面的跟踪:
- 训练和验证损失曲线
- WER 进展
- 最佳性能迭代的模型检查点
- 不同数据集和条件下的性能
exp_manager:
create_mlflow_logger: true
mlflow_logger_kwargs: {"tracking_uri": "mlruns"}
checkpoint_callback_params:
monitor: "val_wer"
mode: "min"
save_top_k: 10
此配置根据验证 WER 保存 10 个最佳性能的模型检查点。
使用 DeepSpeed 进行内存优化
DeepSpeed 的内存优化技术允许在有限的硬件上训练大型模型:
- Stage 2 优化:优化器状态被卸载到 CPU
- 梯度累积:实现有效的更大批次大小
- 内存高效注意力:减少注意力计算的内存需求
- 梯度检查点:通过计算换取内存使用量的减少
trainer:
devices: 8 # Number of GPUs to use (-1 would use all available)
num_nodes: 8 # Number of compute nodes (servers) for distributed training
max_epochs: 2 # Maximum number of training epochs
max_steps: -1 # Maximum number of training steps (-1 means compute from epochs)
val_check_interval: 1.0 # Validation frequency: 1.0 = once per epoch, 0.25 = 4 times per epoch
accelerator: auto # Hardware accelerator: auto, gpu, cpu
strategy: "lightning.pytorch.strategies.DeepSpeedStrategy" # "lightning.pytorch.strategies.DeepSpeedStrategy" or "lightning.pytorch.strategies.DDPStrategy"
# Distributed training strategy
stage: 2
offload_optimizer: true # Offload optimizer states to CPU to save GPU memory
offload_parameters: false # Don't offload model parameters to CPU
partition_activations: true # Partition activations across GPUs to save memory
gradient_as_bucket_view: true # Use bucket view for gradients to save memory
cpu_checkpointing: true # Store activations on CPU during backward pass
contiguous_gradients: true # Ensure contiguous memory for gradients
overlap_comm: true # Overlap communication and computation
allgather_bucket_size: 2e8 # Bucket size for all-gather operations
reduce_bucket_size: 2e8 # Bucket size for reduce operations
zero_force_ds_cpu_optimizer: false # Don't force CPU optimizer with ZeRO
在优化和微调模型后,让我们看看如何部署该模型以实现高效推理。
模型推理
采用合适的工具来部署模型可以成就或毁掉我们的服务。设想一下我们模型的实用性,如果它运行得太慢或太昂贵,就会降低其对企业的投资回报率。我们必须考虑模型的延迟、成本、安全性、可观察性和弹性,以使我们的模型有用。
因此,部署将是我们微调的模型、合适的硬件和一个能够快速扩展和缩小的弹性系统的组合。让我们看看 AWS 如何帮助我们在这些维度上进行构建。
模型打包
首先要考虑的是用户如何访问我们的模型。通过构建在标准 API 之上,我们可以为我们的模型使用现有的安全和可观察性组件。OpenAI REST API 已成为服务现代模型的标准。对于我们的用例,OpenAI 音频转录 API 提供了合适的解决方案。
我们确实使用 Torch 作为推理引擎;但是,我们编写了一个覆盖层,允许我们将模型公开为 OpenAI API。您可以在关联的存储库 中找到此文件:
from fastapi import FastAPI, UploadFile, File, BackgroundTasks
from typing import Optional, List
app = FastAPI(
title="Optimized NeMo ASR OpenAI-Compatible API"
)
@app.post("/v1/audio/transcriptions")
async def create_transcription(
background_tasks: BackgroundTasks,
file: UploadFile = File(..., description="Audio file to transcribe"),
model: Optional[str] = "nemo-parakeet-rnnt-1.1b",
language: Optional[str] = "en",
prompt: Optional[str] = None,
response_format: Optional[str] = "json",
temperature: Optional[float] = 0.0,
timestamp_granularities: Optional[List[str]] = None
):
接下来是将我们的模型、其依赖项和覆盖代码打包到一个一致且可移植的包中。可移植的包还能够响应不断增长的用户工作负载,轻松扩展到新机器。我们推荐使用容器来满足这些要求。
我们从一个受信任的基础镜像(Amazon Linux 2023)开始,然后安装 Python 运行时环境。然后我们安装 FFMpeg 库,您可能需要使用它来预处理音频(例如更改音频信号的比特率)。然后,我们安装所需的 FastAPI 库来公开音频 API 和 nemo-toolkit 库来加载和提供模型。
您可以在关联的存储库 中找到此文件:
FROM amazonlinux:2023
# Install Python and essential tools
RUN dnf update -y && \
dnf install -y shadow-utils python3.11 python3.11-pip python3.11-devel gcc gcc-c++ wget tar gzip xz && \
dnf clean all && \
ln -sf /usr/bin/python3.11 /usr/bin/python && \
ln -sf /usr/bin/pip3.11 /usr/bin/pip
# Install ffmpeg from static build (recommended for AL2023)
RUN wget -q https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz && \
tar -xf ffmpeg-release-amd64-static.tar.xz && \
mv ffmpeg-*-amd64-static/ffmpeg /usr/local/bin/ && \
mv ffmpeg-*-amd64-static/ffprobe /usr/local/bin/ && \
rm -rf ffmpeg-* && \
chmod +x /usr/local/bin/ffmpeg /usr/local/bin/ffprobe
# Some parts od Dockerfile is skipped in here. Refer to repo for a full file
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir fastapi uvicorn python-multipart soundfile uvloop prometheus-fastapi-instrumentator
RUN pip install -v --no-cache-dir nemo_toolkit[asr] torch cuda-python>=12.3
您可能已经注意到,我们没有将模型打包到此容器中。我们希望在运行时加载模型以提高部署敏捷性并减少 Docker 容器的维护。让我们看看 Amazon Elastic Kubernetes Service (Amazon EKS) 如何将这一切整合到我们的容器中。
模型服务
Amazon...
评论区